
某音数据监控
声明:本作品不可用于任何商业途径,仅供学习交流!!!
爬取某音平台创作者用户的数据: 抖音号主页地址(url)、关注、粉丝、获赞、作品 短视频作品的 点赞 评论 收藏 播放地址 等等,
而要抓每个短视频的数据 这部分的数据 需要先获取抖音号下每个视频的url地址 (由于某音平台的js逆向难度 我现在的水平突破不了 这里使用selenium 来获取)
基于selenium 获取抖音号下每个短视频的url地址 在使用requests.Session() 获取到cookie (selenium 获得到的cookie 传给requests的session) 对每个短视频的url地址发起请求 再数据提取解析即可
分析:
某音平台基于selenium抓取数据遇到的反爬策略 滑动验证拼图:
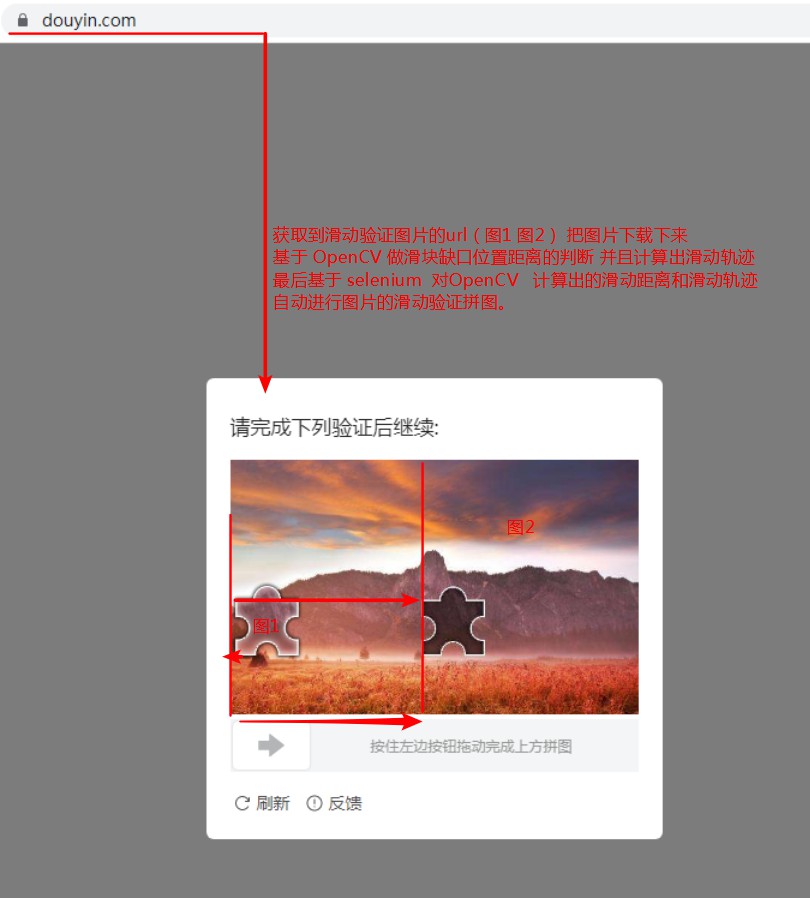
总结: 1、使用OpenCV(或者其他的方式) 对滑动拼图验证的图片做滑动距离和滑动轨迹做计算处理 2、手动滑动验证图片拼图
** 设置全局变量来验证是否突破滑动拼图验证 失败则重新进行验证 成功则把selenium成功进入的cookie给requests的session(后面抓短视频数据需要) **
def douyin_selenium_login():
"""解决selenium进入抖音网页的验证滑块"""
global login
try:
web.get('https://www.douyin.com')
WebDriverWait(web, 10).until(lambda el: web.find_element(By.XPATH, '//*[@id="captcha_container"]/div/div[2]/img[2]'))
slider_ele = web.find_element(By.XPATH, '//*[@id="captcha_container"]/div/div[2]/img[2]')
background_ele = web.find_element(By.XPATH, '//*[@id="captcha-verify-image"]')
distanca = sli.get_element_slide_distance(slider_ele, background_ele)
# print('滑动的距离:',distanca)
distanca = distanca * 340 / 552 - 3
btn = web.find_element(By.XPATH, '//*[@id="secsdk-captcha-drag-wrapper"]/div[2]')
sli.slide_verification(web, btn, distanca)
except:
pass
try:
WebDriverWait(web, 10).until(lambda el: web.find_element(By.XPATH, '//div[@class="R0xtz8q0"]'))
if web.find_element(By.XPATH,'//div[@class="R0xtz8q0"]').text =='登录':
login = True
except:
print('滑动验证失败 重新验证中...')
def selenium_login_btn():
"""判断是否滑动验证成功 失败则继续执行douyin_selenium_login"""
global session
while True:
if login:
print('滑动验证成功!')
for cookie in web.get_cookies():
session.cookies.set(cookie['name'], cookie['value'])
sleep(1)
return
else:
douyin_selenium_login()
突破图片拼图验证后 搜索要爬取数据的抖音号 并且点击进入抖音号的主页:
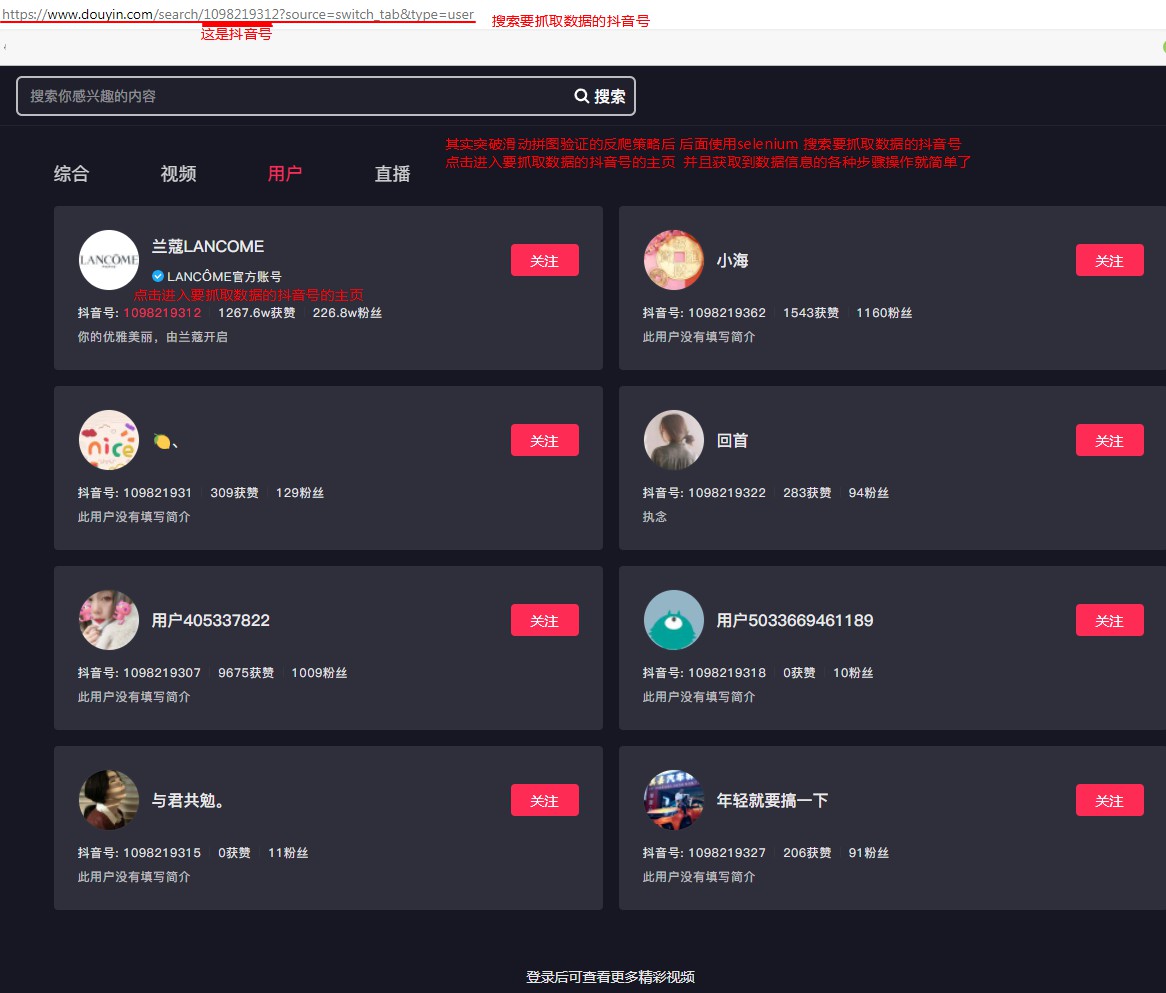
抖音号主页的数据抓包分析:
分析图1:
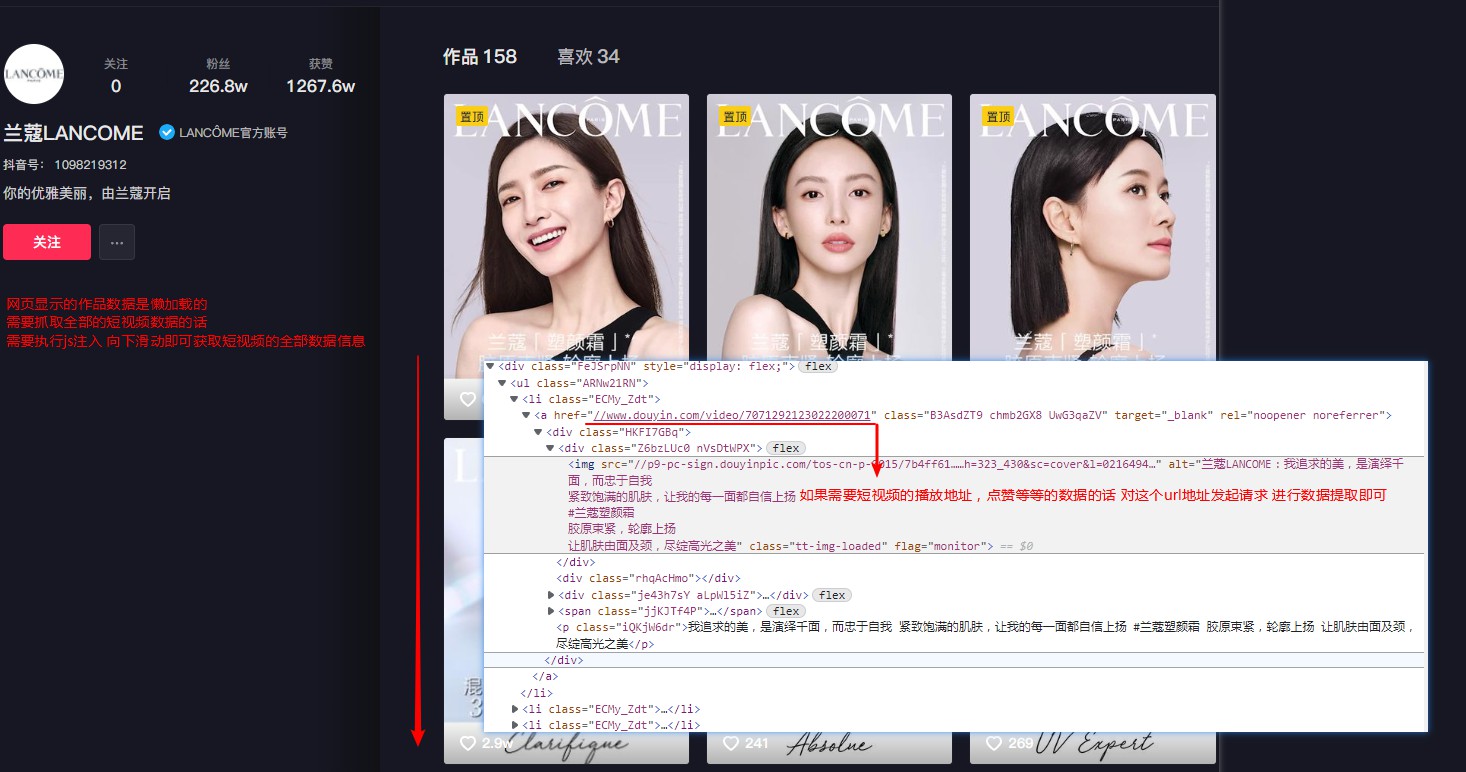
分析图2:
def drop_down():
"""抖音创作者信息主页 发布的视频数据的懒加载的(需要执行页面滚动的操作后 才可以得到数据信息)"""
"""执行页面滚动的操作""" # javascript
for i in range(1,100,4): # 1 3 5 7 9 在网页不断下拉的过程中 页面的高度也会改变
try:
j = i / 9 # 1/9 3/9 5/9 9/9
# document.documentElement.scrollTop 知道滚动条的位置
# document.documentElement.scrollHeight 获取浏览器页面的最大高度
js = 'document.documentElement.scrollTop = document.documentElement.scrollHeight * %f' % j
web.execute_script(js)
sleep(1)
if web.find_element(By.XPATH, '//div[@class="FeJSrpNN"]/div[1]/div[1]').text == '暂时没有更多了':
web.execute_script('window.scrollTo(0, document.body.scrollHeight)') # 抓到text==暂时没有更多了 再滑动一下 进可能的确保抓到全部数据
sleep(2) # 给网页点加载时间
break # 停止滑动
except:
pass
在mongodb数据库里面 设置要抓取数据的抖音号:
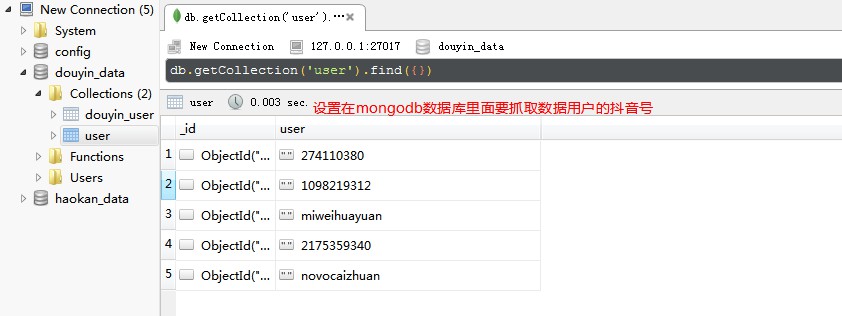
部分代码如下:
def data_while(user):
"""
通过redis 去重 数据是否抓取过(抖音号),没有抓取过的 直接抓取并且保存在mongodb数据库
抓取过的数据,通过之前抓取到的创作者主页url 进入创作者主页 抓取其作品数据和获赞数据和之前抓取到的作品和获赞做对比
要是2者一致 重新抓取信息 反正 更新信息保存在mongodb数据库
mongodb 保存数据
:param user:
:return:
"""
conn = redis
col = cli.douyin_data.douyin_user
ex = conn.sadd('douyin_user',user)
if ex == 1:
selenium_click(user)
print(time.strftime('%Y-%m-%d %H:%M:%S'),f'正在抓取抖音号:{user} 的数据...')
data = user_data(user)
col.insert_one(data)
print(time.strftime('%Y-%m-%d %H:%M:%S'),'数据已经保存!')
# col.insert_many([data])
else: #以抖音号判断本次抓取的数据 上次是否抓取过
db_item = col.find_one({'抖音号':user})
web.get(db_item['user_url'])
WebDriverWait(web, 10).until(lambda el: web.find_element(By.XPATH, '//span[@class="MhR7TL6q"]'))
zp = web.find_element(By.XPATH, '//span[@class="MhR7TL6q"]').text
item = web.find_elements(By.XPATH, '//div[@class="ojricq5F"]')
for i in item:
zan = i.find_element(By.XPATH, './div[3]/div[2]').text
if zp == db_item['作品'] and zan == db_item['获赞']:
#假如上次抓取的数据(赞和作品)和本次抓取的一样 不抓取数据
print(f'抖音号 {user} 没有数据更新 时间:', time.strftime('%Y-%m-%d %H:%M:%S'))
return
else:
print(f'抖音号: {user} ',' 有数据更新...')
data = user_data(user)
col.update_one(filter=({'抖音号':user}),update={"$set":data})
print('更新时间: ',time.strftime('%Y-%m-%d %H:%M:%S'))
def main_douyin():
"""程序控制"""
col = cli.douyin_data.user
db_item = col.find()
selenium_login_btn()
while True:
for item in db_item:
data_while(item['user'])
sleep(60*30)#设置抓取数据间隔时间(这里设置30分钟抓一次)
main_douyin()
该工程使用redis来判断是否是抓取过数据的抖音号 没有抓取过 就正常抓取并且保存在mongodb数据库;
抓取过的抖音号 则通过抓取抖音号主页当前的获赞数据和发布的短视频作品数据 和之前抖音号抓取保存在mongodb数据库的这2个数据做对比(选其他的做对比也行) 要是数据对比一致 则不抓取数据 反正则是有数据更新 进行数据抓取。
** 完善一下 把定义抓取短视频数据的函数加入在线程池 加快抓取数据的速度 **
def data_to_mongodb(pool):
global dic_data
conn = redis
col_user = cli.douyin_data.user
col_data = cli.douyin_data.douyin_user
item_user = col_user.find()
for user in item_user:
ex = conn.sadd('douyin_user', user['user'])
if ex == 1:
selenium_click(user['user'])
get_data_url(user['user'])
print(time.strftime('%Y-%m-%d %H:%M:%S'), '正在抓取抖音号:{} 的数据...'.format(user['user']))
alist = pool.map_async(user_data, dic_data['video_data'])
dic_data['video_data'] = alist.get()
# dic_data['video_data'] = pool.map(user_data,dic_data['video_data'])
data = dic_data
print(data)
col_data.insert_one(data)
print(time.strftime('%Y-%m-%d %H:%M:%S'), '数据已经保存 !')
else: # 以抖音号判断本次抓取的数据 上次是否抓取过
db_item = col_data.find_one({'抖音号': user['user']})
web.get(db_item['user_url'])
WebDriverWait(web,20).until(lambda el: web.find_element(By.XPATH, '//span[@class="MhR7TL6q"]'))
zp = web.find_element(By.XPATH, '//span[@class="MhR7TL6q"]').text
item = web.find_elements(By.XPATH, '//div[@class="ojricq5F"]')
for i in item:
zan = i.find_element(By.XPATH, './div[3]/div[2]').text
if zp == db_item['作品'] and zan == db_item['获赞']:
# 假如上次抓取的数据(赞和作品)和本次抓取的一样 不抓取数据
print('抖音号 {} 没有数据更新 时间:'.format(user['user']), time.strftime('%Y-%m-%d %H:%M:%S'))
continue
else:
print('抖音号:{} '.format(user['user']), '有数据更新...')
get_data_url(user['user'])
print(time.strftime('%Y-%m-%d %H:%M:%S'), '正在抓取抖音号:{} 的数据...'.format(user['user']))
alist = pool.map_async(user_data, dic_data['video_data'])
dic_data['video_data'] = alist.get()
# dic_data['video_data'] = pool.map(user_data,dic_data['video_data'])
data = dic_data
print(data)
col_data.update_one(filter=({'抖音号': user['user']}), update={"$set": data})
print('数据更新时间: ', time.strftime('%Y-%m-%d %H:%M:%S'))
pool.close()
pool.join()
def main():
"""线程池"""
while True:
pool = Pool(10)
data_to_mongodb(pool)
print(time.strftime('%Y-%m-%d %H:%M:%S'), ':本次数据抓取完成!')
sleep(60 * 10)
if __name__ == '__main__':
main()
数据抓取演示如下:
图1:
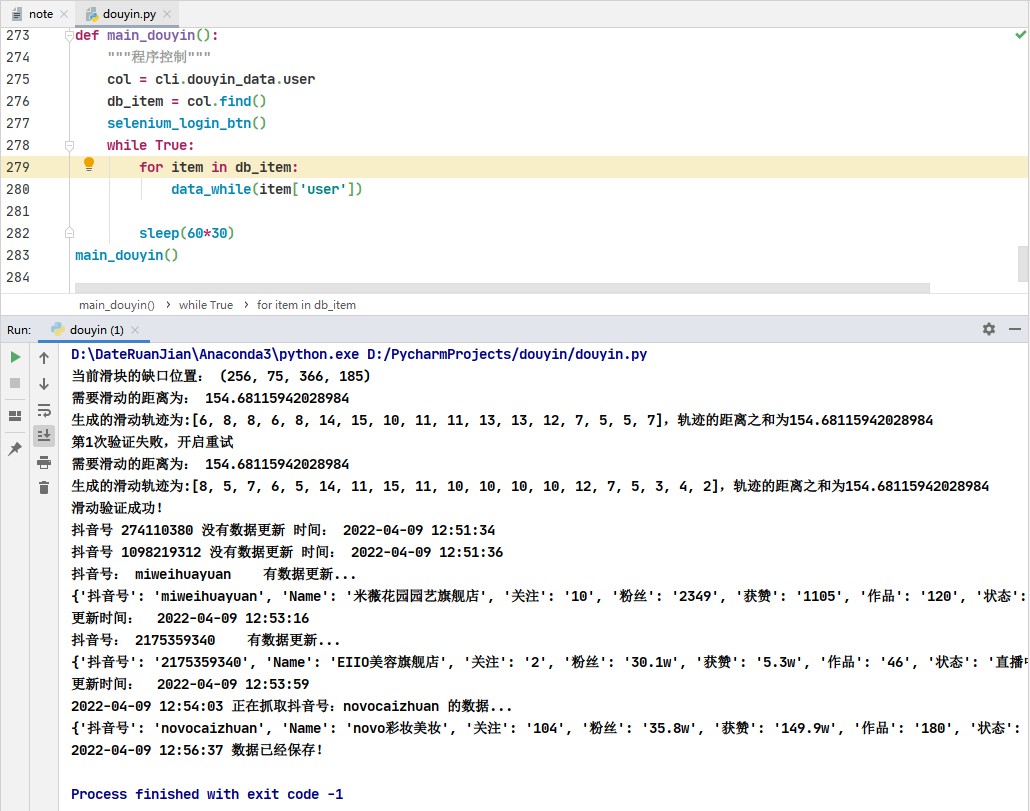
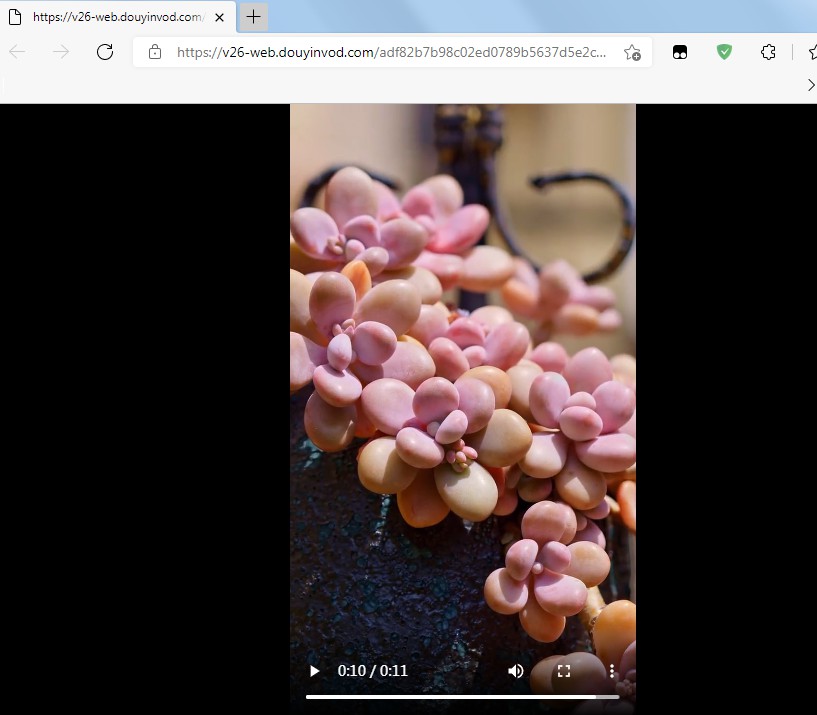
图2:

图3:
声明:本作品不可用于任何商业途径,仅供学习交流!!!

【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步