

短视频数据监控
声明:本作品不可用于任何商业途径,仅供学习交流!!!
分析:
进入短视频创作者信息的网页>打开浏览器的抓包工具>向下滑动,进行抓包、分析:
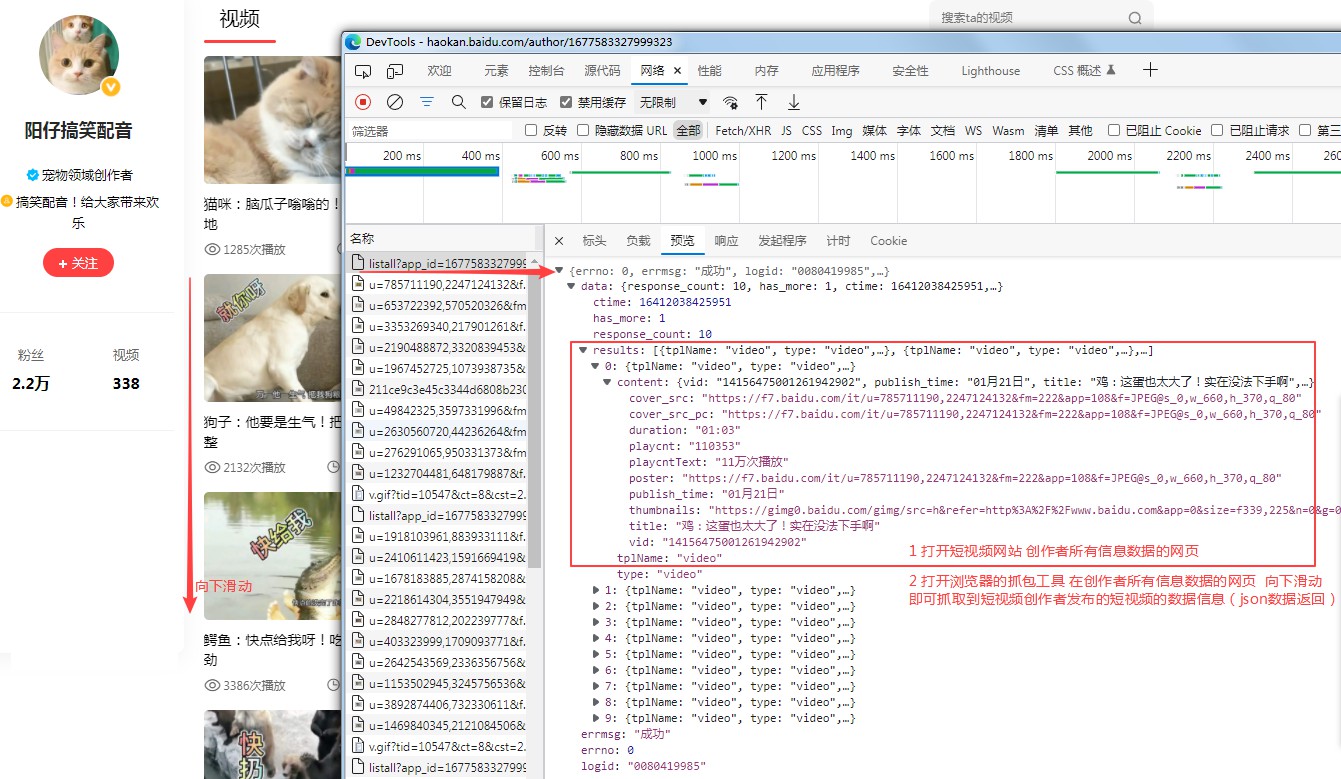
查看json请求的url参数 分析如图:
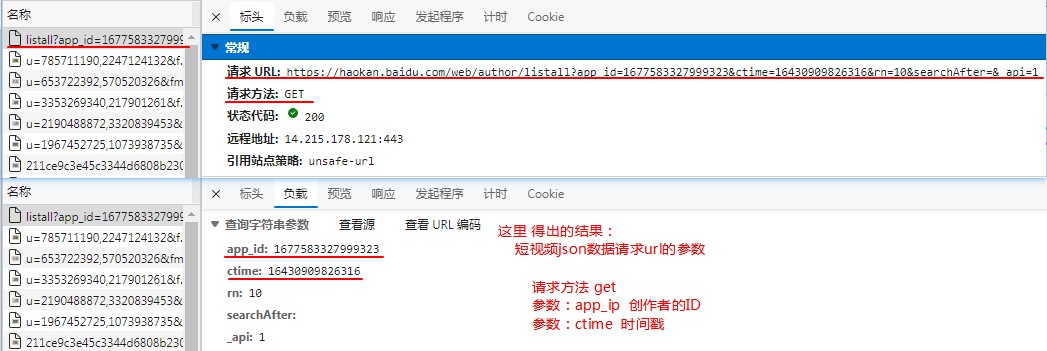
通过浏览器的抓包工具 抓取到的多个json数据包 通过json url的请求参数(ctime) 对比 json返回数据的(ctime) 得出抓取下一页短视频数据的json请求的ctime参数 分析如图:
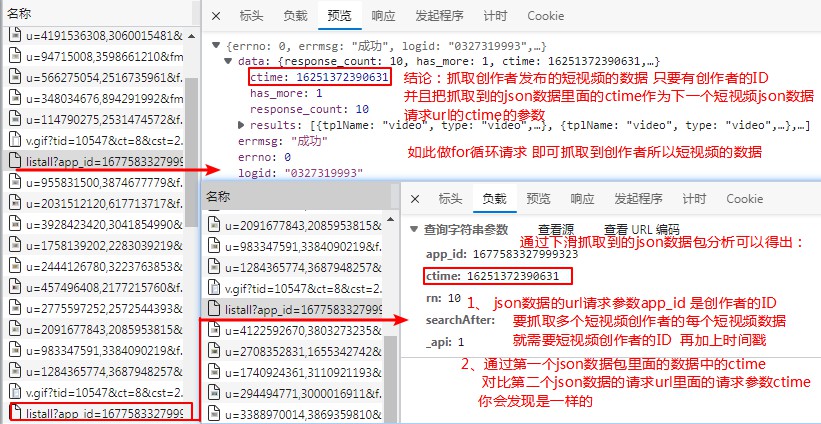
通过搜索创作者昵称的数据抓包 分析如图:
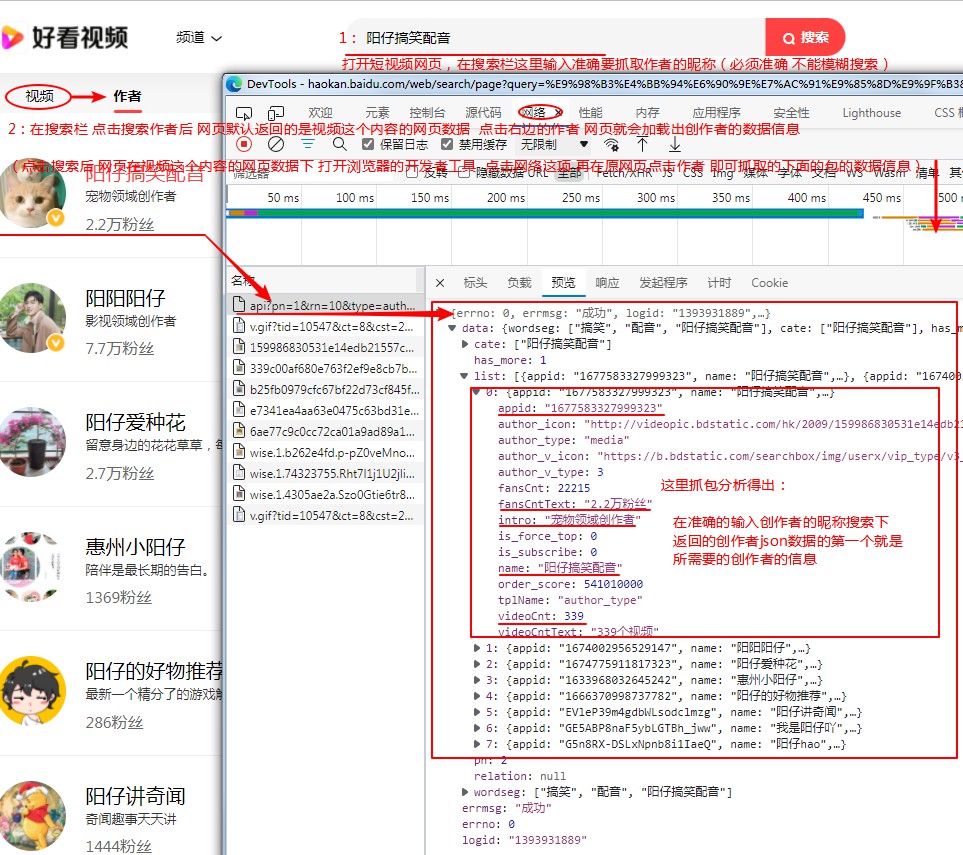
通过以上抓包分析 分析得出结果如图:
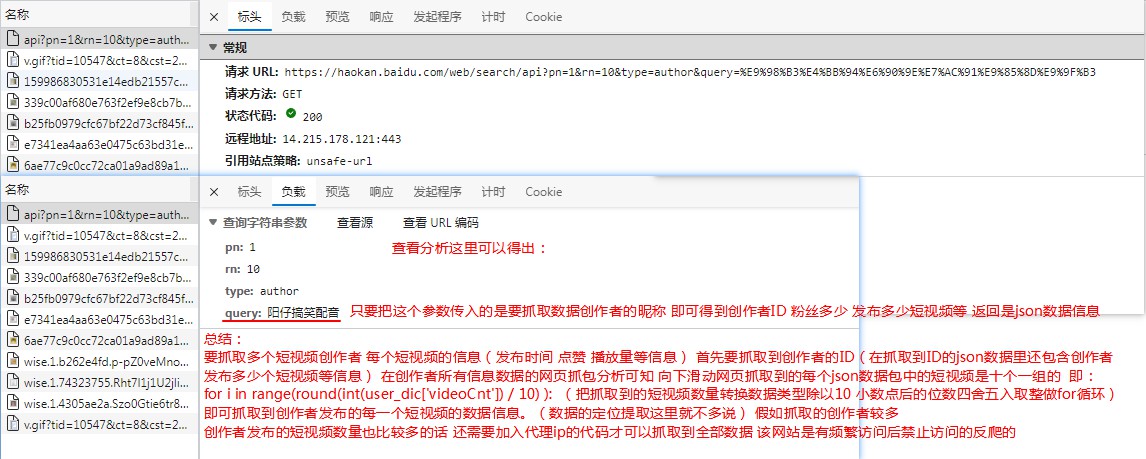
json数据的提取这里就不说了!
部分代码如下:
def main():
'''控制台'''
data_table = PrettyTable(['视频标题','播放次数','视频点赞','发布时间','视频链接','数据抓取时间:{}'.format(time.strftime('%Y-%m-%d %H:%M:%S'))])
n = 0
conn = redis
col = cli.haokan_data.user
col_user = cli.haokan_data.haokan_user
while True:
"""
循环读取在csv表格里面 要抓取短视频创作者的昵称 进行数据抓取
user_list = []
user_all = pd.read_csv('./UserData/Ex.csv',header=None)
for i in range(len(user_all)):
item_dic = get_userID(user_all.iloc[i,0])
user_list.append(item_dic) #获取抓取数据用户的ID等 user_list_dic
for item_dic in user_list:
print('现在正在抓取的用户数据是:{}'.format(item_dic['user']))
UserData(item_dic,data_table)
filename = './haokan/{}'.format(user_all.iloc[i,0]) +'.xlsx'
content_to_csv(data_table,filename,headers=True)#抓取的用户数据并且保存
这块的代码是要抓取的创作者是在csv表格里 进行循环读取来抓取数据并且保存在csv表格里面
"""
'''在mongodb数据库里面 循环读取要抓取短视频创作者的昵称 进行数据更新抓取并且保存在mongodb数据库'''
item_dic = col.find()
for item in item_dic:
ex = conn.sadd('haokan_user',item['user'])
if ex == 1:
print('现在正在抓取的用户数据是:{}'.format(item['user']))
user_dic = get_userID(item['user'])
dic_user = UserData(user_dic,data_table)
col_user.insert_one(dic_user[1])
print('{}数据已经保存在mongodb数据库 抓取完成!'.format(item['user']))
filename = './haokan/{}'.format(item['user']) +'.xlsx'
content_to_csv(data_table,filename,headers=True)#抓取的用户数据并且保存csv
else:
db_item = col_user.find_one({'user':item['user']})
headers = {
'User-Agent':ua,
}
response = requests.get('https://haokan.baidu.com/author/{}'.format(db_item['user_id']),headers=headers)
videoCnt = re.findall(r'</h3><p>(.*?)</p></li>',response.text)[1]
if db_item['videoCnt'] == videoCnt:
print(item['user'],'的数据没有更新 时间:', time.strftime('%Y-%m-%d %H:%M:%S'))
else:
print(item['user'],' 有数据更新...')
user_dic = get_userID(item['user'])
dic_user = UserData(user_dic,data_table)
col_user.update_one(filter=({'user':item['user']}),update={"$set":dic_user[1]})
print('更新时间: ',time.strftime('%Y-%m-%d %H:%M:%S'))
filename = './haokan/{}'.format(item['user']) +'.xlsx'
content_to_csv(data_table,filename,headers=True)#抓取的用户数据并且保存csv
n += 1
writer = pd.ExcelWriter('./UserData/用户数据第{}次抓取.xlsx'.format(n))#创建一个表 把抓取到的多个短视频创作者的数据 合并在一个Excel表格的不同的sheet里面
for file_name in file_name_paths('./haokan'):
data_temp = pd.read_csv(file_name) #循环读取每个表格 delimiter='\t'
data_temp.to_excel(writer,os.path.splitext(os.path.basename(file_name))[0],index=False) #将每个表分别放到以名称命名的sheet中
writer.save() #保存d:/合并后表格2.xlsx 把抓取的数据合并在一个Excel表格的不同的sheet
print(time.strftime('%Y-%m-%d %H:%M:%S'))
print('数据抓取完成!')
time.sleep(60*60)
'''设置抓取时间'''
main()
数据抓取演示如下:
图1:
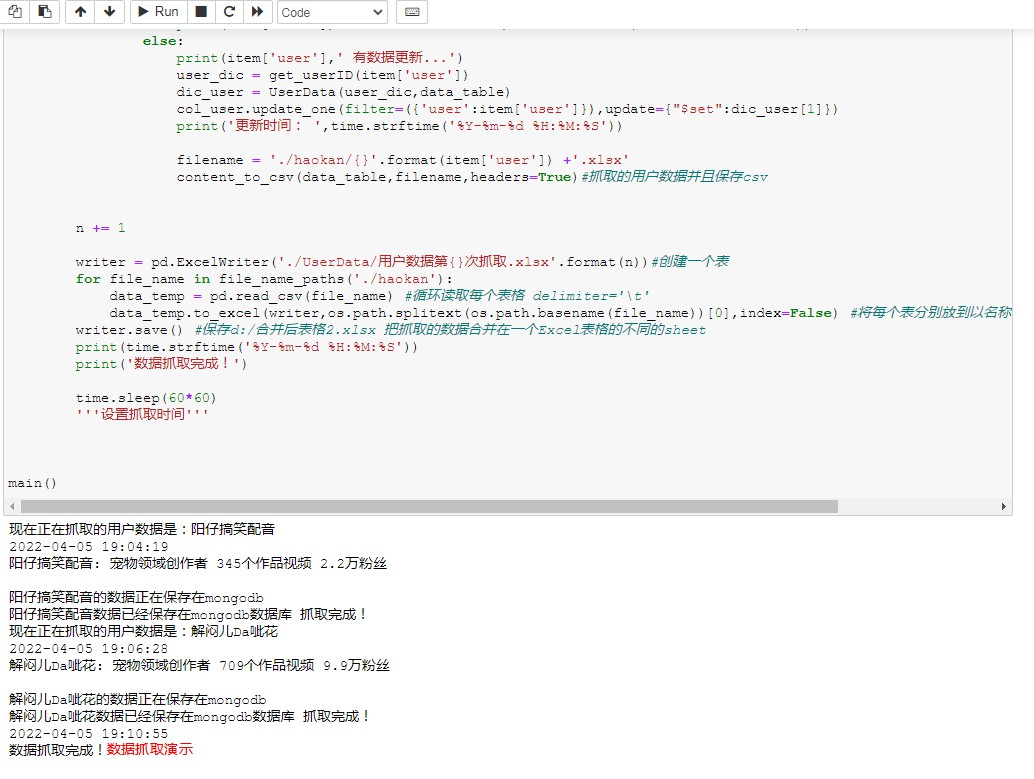
该短视频网站是有频繁访问禁止访问的反爬策略的 由于代理不是买的 自己去抓比较靠谱的免费代理网站的免费代理ip来使用的 所以这里只抓取2个创作者所发布的短视频的数据
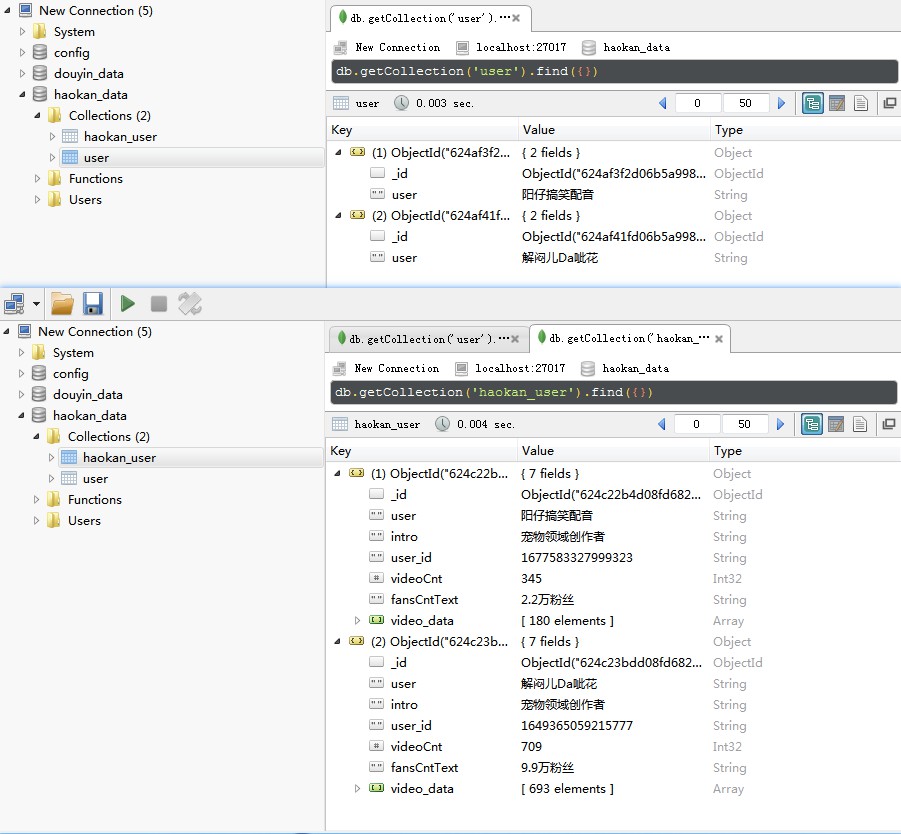
图2:
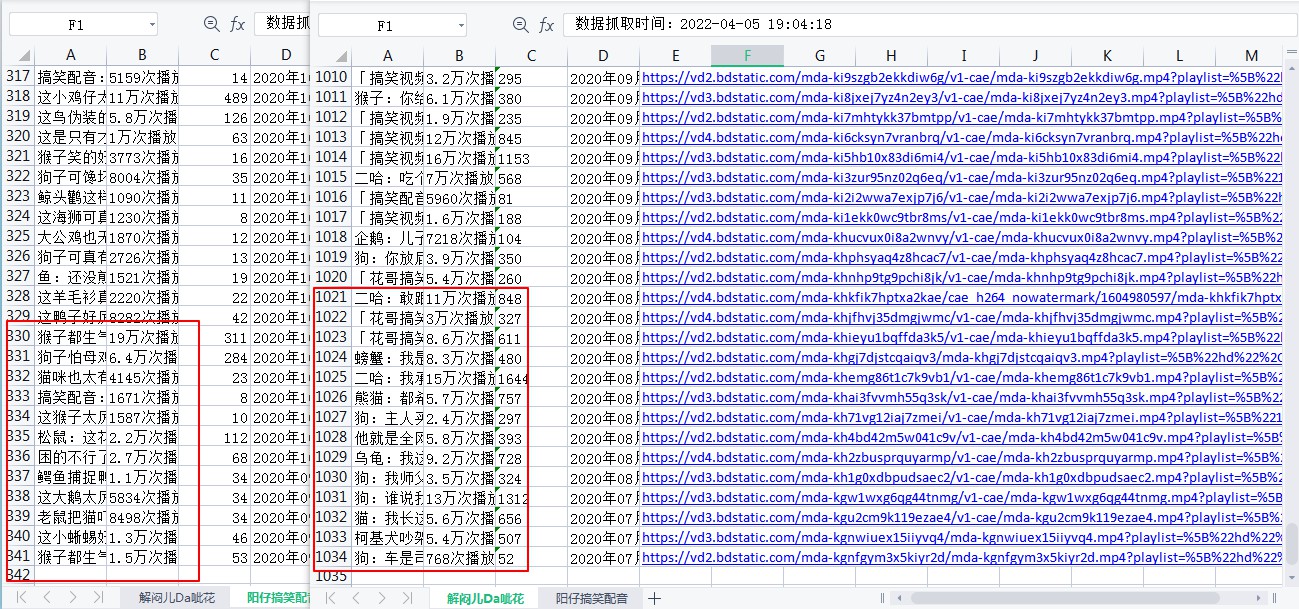
图3:
声明:本作品不可用于任何商业途径,仅供学习交流!!!
