
爬取梨视频当前时间,在排行榜的视频!!!
本作品不可用于任何商业途径,仅供学习交流!!!
**** 分析:****
打开梨视频的排行榜网页,打开抓包工具,刷新网页抓包分析:
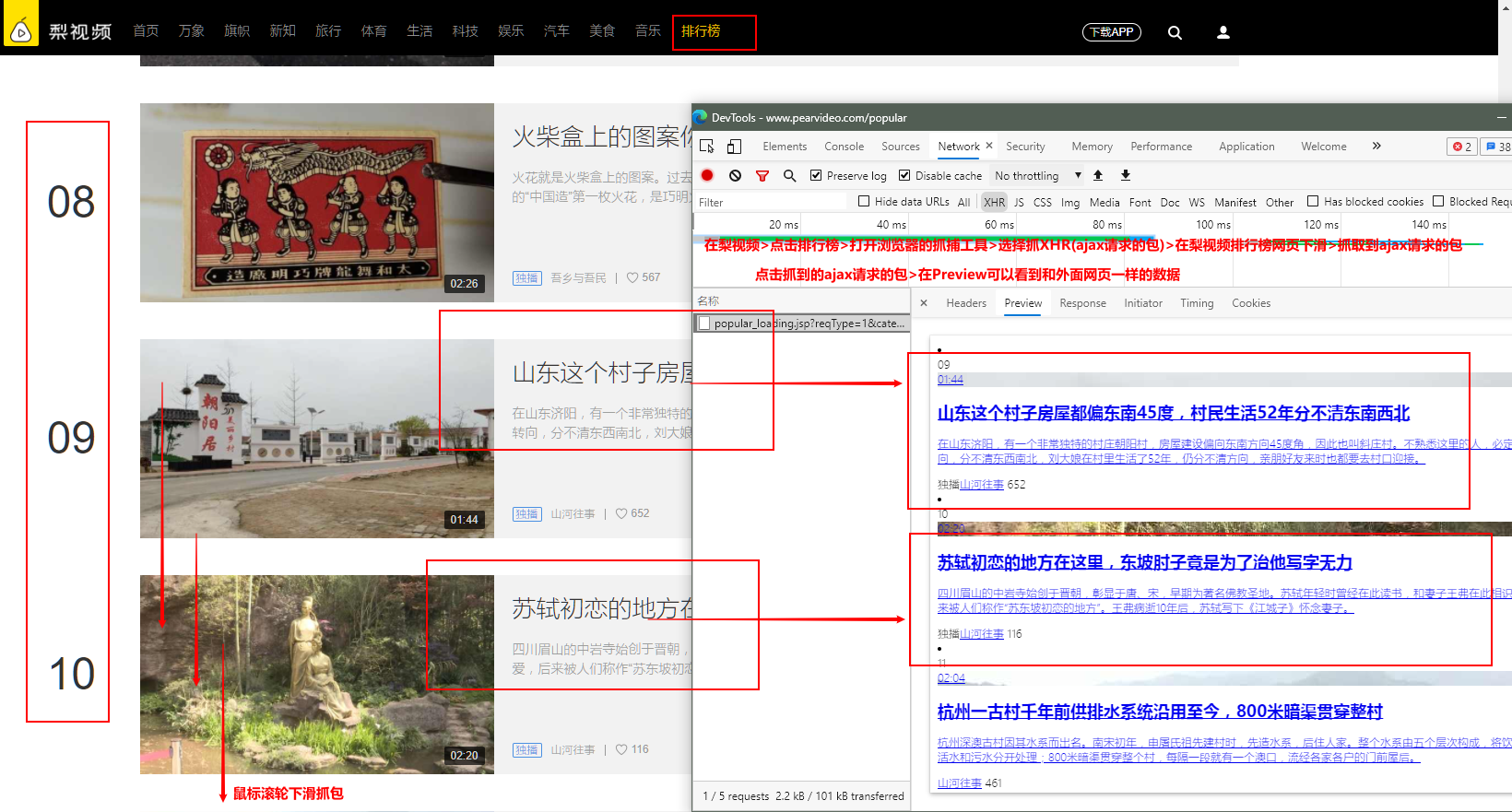
把上面的分析进一步分析,验证和测试:
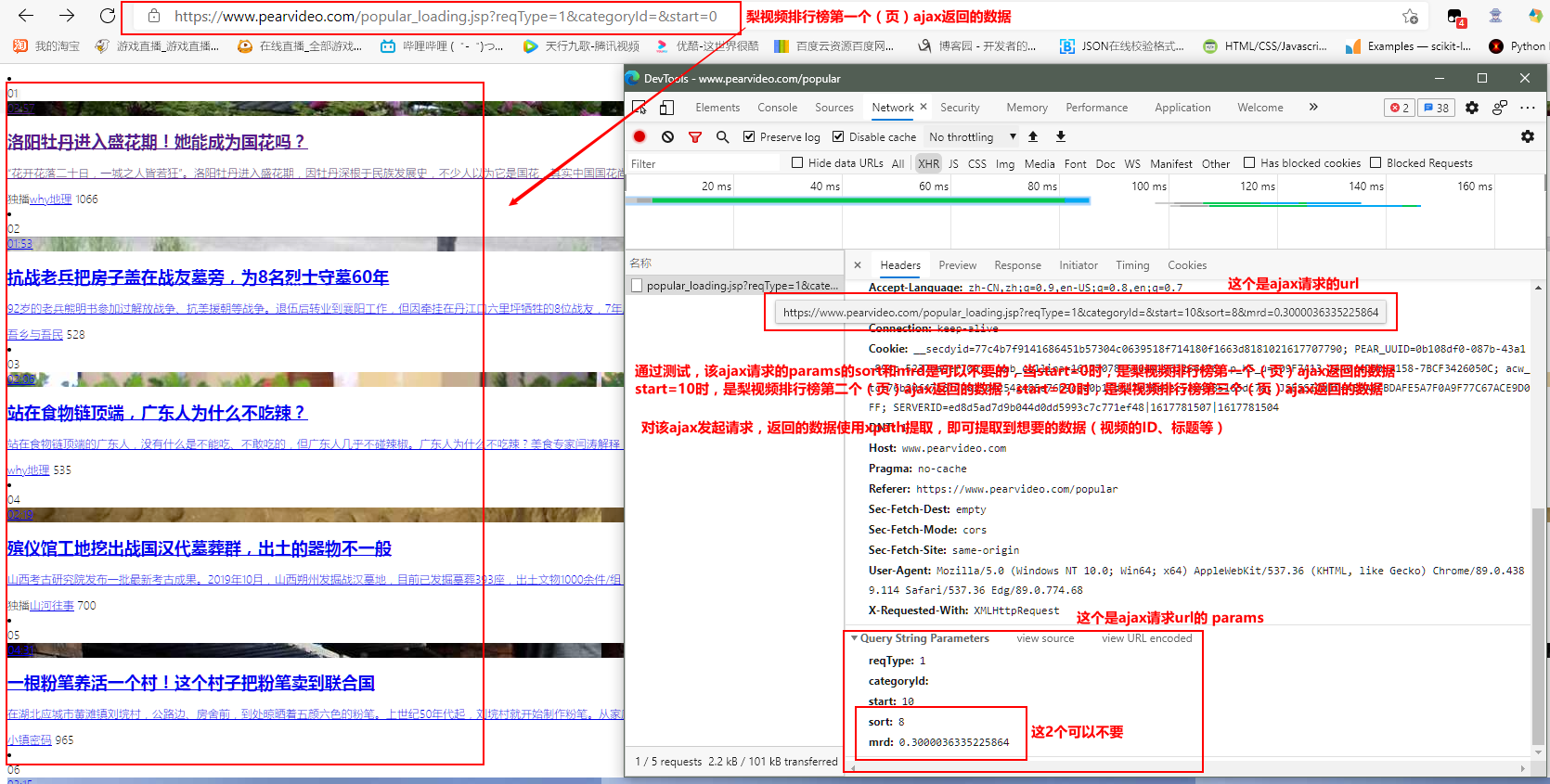
随便点击一个排行榜里面的视频进入视频的网页,打开抓包工具,刷新网页,对抓取到得数据包进行分析:

通过抓包工具,找到视频的真实播放地址:
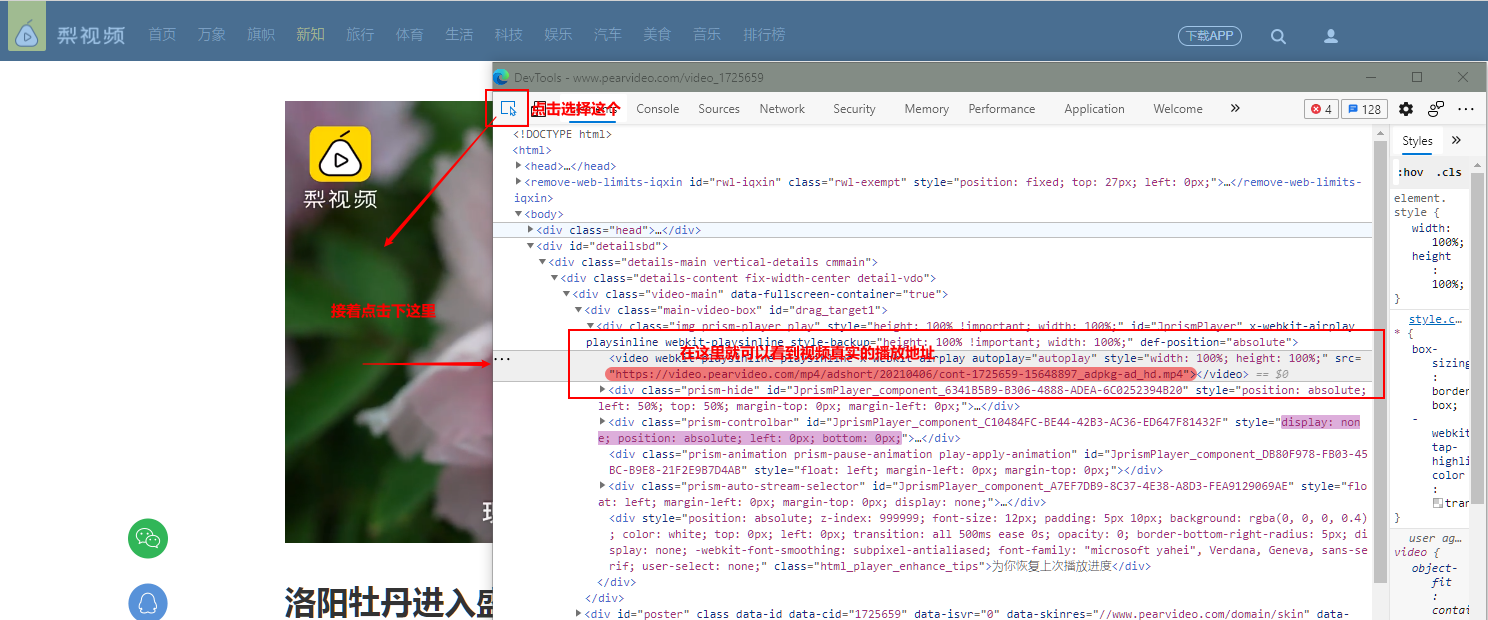
在浏览器打开视频的播放地址,进行验证和测试:

在浏览器打开得到 视频伪装播放地址的ajax请求地址,进行验证和测试(找是否有反爬策略):
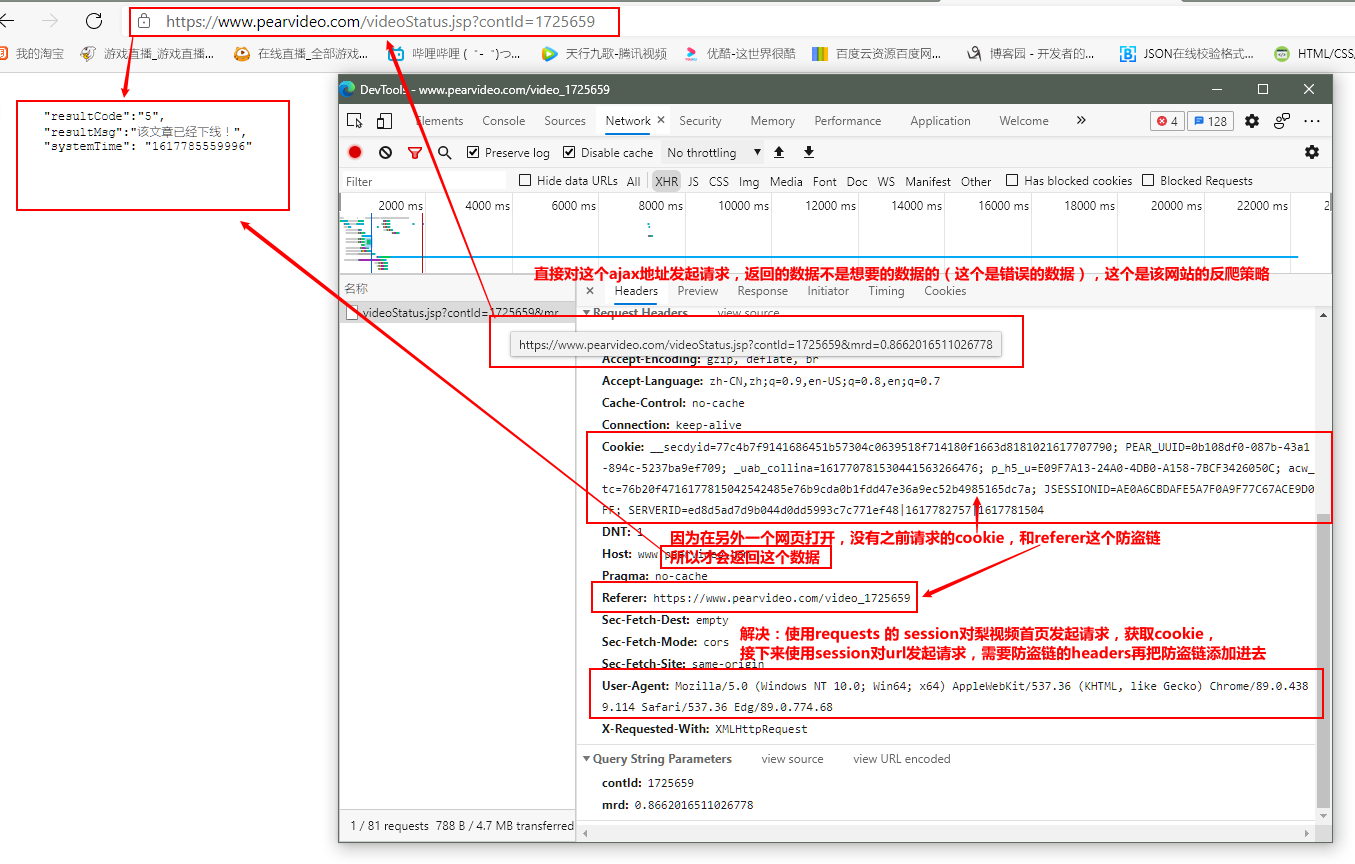
分析结果: 解决该网站的反爬策略,抓到视频的ID、视频的伪装播放地址。通过对比视频的真实播放地址和伪装播放地址(视频的ID),以此来拼接出排行榜里面每个视频的真实播放地址,然后对视频的真实播放地址发起请求,接着持久化保存真实播放地址的二进制数据,即可把视频爬取下来!!!
ok,下面是代码部分:
代码部分1:
def get_videoID():#获取视频ID
ua = UserAgent().random()#动态赋予ua
headers = {
'Connection':'close',
'User-Agent':ua,
}
session = requests.Session()#解决反爬策略
session.get(url='https://www.pearvideo.com',headers=headers)
for page in range(0,20,10):#抓取页数(2个ajax请求的视频)
params = {
'reqType': '1',
'categoryId':'',
'start':page,
}
url = 'https://www.pearvideo.com/popular_loading.jsp'
response = session.get(url=url,headers=headers,params=params)
response.encoding='utf-8'
page_text = response.text
html = etree.HTML(page_text)
item_list = html.xpath('/html/body/li')
for item in item_list:
item_id = item.xpath('./a/@href')[0][6:]
item_tag = item.xpath('./div[@class="popularem-ath"]/a/h2/text()')[0]
get_video_url(session,item_id,item_tag)
def get_video_url(session,item_id,item_tag):#得到视频的伪装播放地址,并且拼接出视频的真实播放地址
ua = UserAgent().random()
headers = {
'Connection':'close',
'Referer': 'https://www.pearvideo.com/video_%s' % item_id,#解决反爬策略
'User-Agent':ua,
}
url = 'https://www.pearvideo.com/videoStatus.jsp?contId=%s' % item_id
json_dic_text = session.get(url=url,headers=headers).json()
srcUrl = json_dic_text['videoInfo']['videos']['srcUrl']
cont = 'cont-' + item_id
new_url = srcUrl.replace(srcUrl.split('-')[0].split('/')[-1],cont)
get_video_content(session,new_url,item_tag)
def get_video_content(session,new_url,item_tag):#持久化保存真实播放地址的二进制数据
path = 'video'
if path not in os.listdir():
os.mkdir(path)
trans = item_tag.maketrans('\/:*?"<?|', ' ')
item_tag = item_tag.translate(trans).replace(' ', '')#这里保存视频的命名是视频的标题,这里做下保存视频命名的特殊字符处理,因为某些特殊字符,会导致无法保存视频数据
filepath = path + '/{}.mp4'.format(item_tag)
with open (filepath,'wb') as fp:
fp.write(session.get(new_url).content)
print('<{}> :下载成功!'.format(item_tag))
def main():
get_videoID()
main()
下面的代码是对上面的代码进一步的完善:
def get_videoID():
headers = {
'Connection':'close',
'User-Agent':ua,
}
for page in range(0,20,10):
params = {
'reqType': '1',
'categoryId':'',
'start':page,
}
url = 'https://www.pearvideo.com/popular_loading.jsp'
response = session.get(url=url,headers=headers,params=params)
response.encoding='utf-8'
page_text = response.text
html = etree.HTML(page_text)
item_list = html.xpath('/html/body/li')
for item in item_list:
info_dic = {
'id':item.xpath('./a/@href')[0][6:],
'tag':item.xpath('./div[@class="popularem-ath"]/a/h2/text()')[0],
}
queue_list.put(info_dic)
def get_video_url(dic):
headers = {
'Connection':'close',
'Referer': 'https://www.pearvideo.com/video_%s' % dic['id'],
'User-Agent':ua,
}
url = 'https://www.pearvideo.com/videoStatus.jsp?contId=%s' % dic['id']
json_dic_text = session.get(url=url,headers=headers).json()
srcUrl = json_dic_text['videoInfo']['videos']['srcUrl']
cont = 'cont-' + dic['id']
new_url = srcUrl.replace(srcUrl.split('-')[0].split('/')[-1],cont)
info_dic = {
'url':new_url,
'tag':dic['tag'],
}
return info_dic
def get_video_content(dic):
path = 'video'
if path not in os.listdir():
os.mkdir(path)
video_tag = dic['tag']
trans = video_tag.maketrans('\/:*?"<?|', ' ')
video_tag = video_tag.translate(trans).replace(' ', '')
filepath = path + '/{}.mp4'.format(video_tag)
with open (filepath,'wb') as fp:
fp.write(session.get(dic['url']).content)
print('<{}> :下载成功!'.format(video_tag))
queue_list = Queue()
ua = UserAgent().random()
session = requests.Session()
def main():
headers = {
'Connection':'close',
'User-Agent':ua,
}
session.get(url='https://www.pearvideo.com',headers=headers)
get_videoID()
while not queue_list.empty():
video_dic = get_video_url(queue_list.get())
get_video_content(video_dic)
main()
最后,跑该工程的成果图:
本作品不可用于任何商业途径,仅供学习交流!!!
