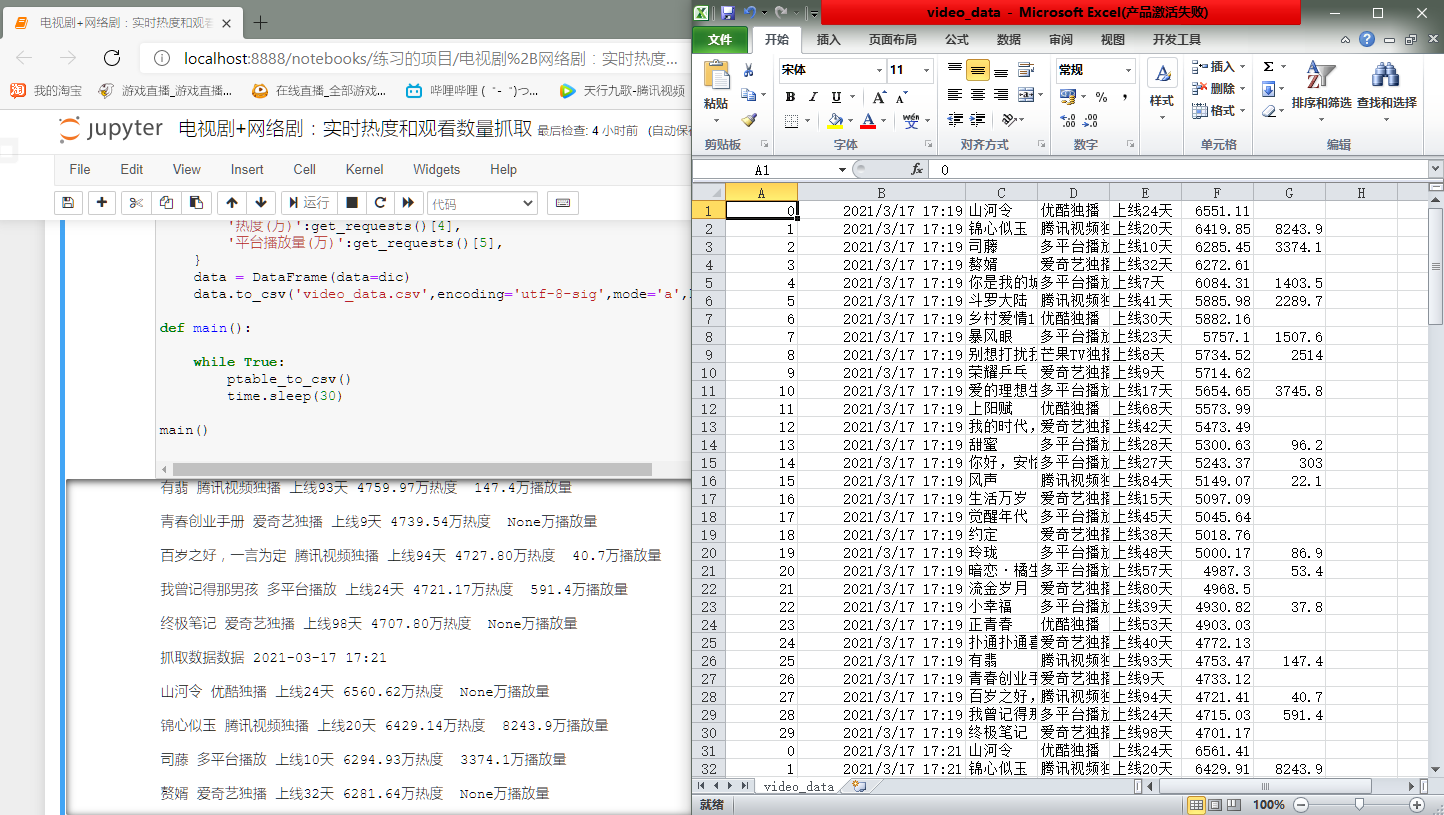
抓取电视剧+网络剧的信息:电视剧+网络剧实时热度和实时播放量数据!!!
分析:
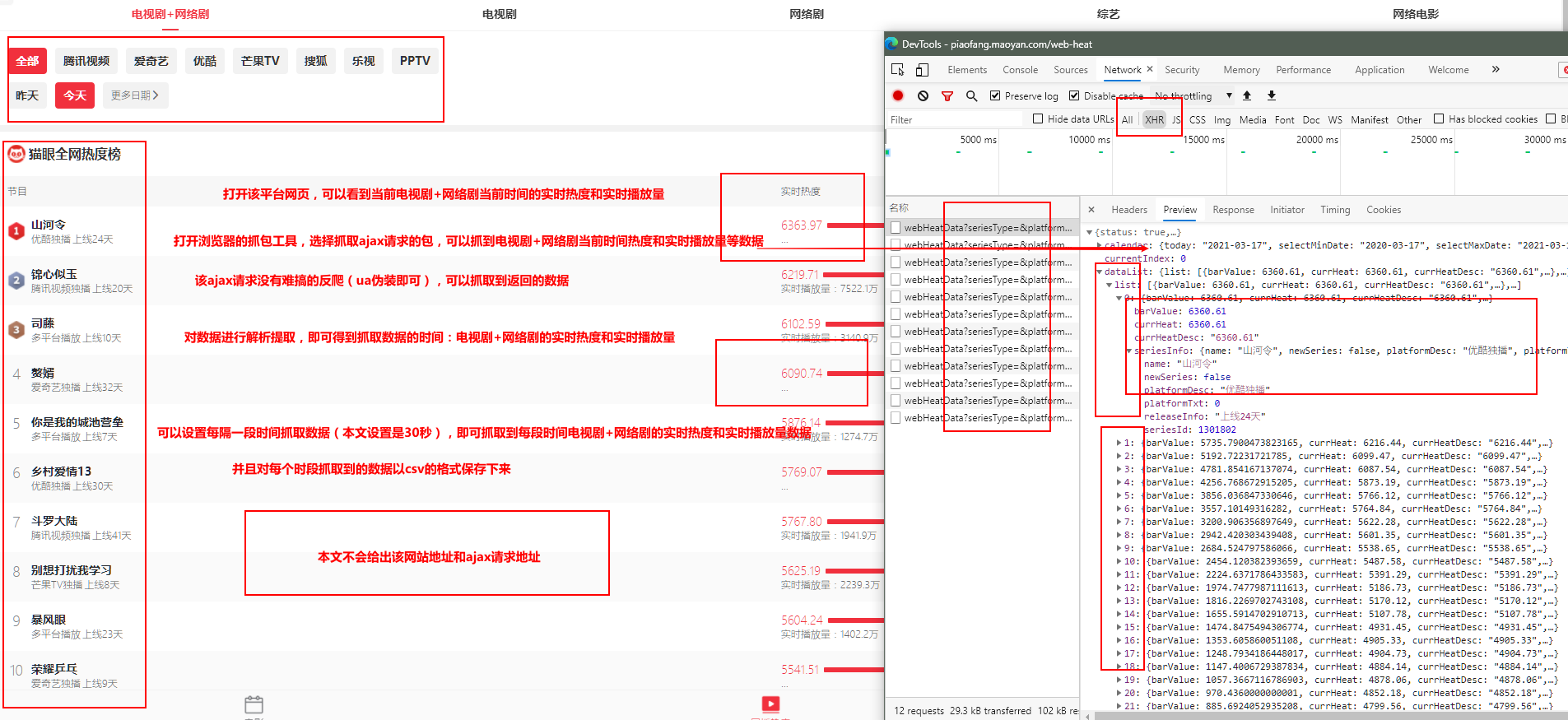
代码部分:
import requests,time
from pandas import DataFrame
from my_fake_useragent import UserAgent
def get_headers():
ua = UserAgent().random()
headers = {
'Connection':'close',
'Referer':'猫眼热度',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.67 Safari/537.36 Edg/87.0.664.47',
}#这是想使用动态User-Agent的,但是在持久化储存的时候,使用动态的User-Agent会报错,所以就不用了
return headers
def get_requests():
params = {
'seriesType':'',
'platformType':'',
'showDate':'2',
'dateType':'0',
'rankType':'0',
}
session = requests.Session()#处理cookie
session.get(url='猫眼热度',headers=get_headers())
my_url = '猫眼热度ajax请求'
response = session.get(url=my_url,headers=get_headers(),params=params)
response.encoding = 'utf-8'
data_list = response.json()['dataList']
dateTime = data_list['updateInfo']['updateTimestamp']
dateTime = time.strftime("%Y-%m-%d %H:%M",time.localtime(dateTime/1000))
print('抓取数据数据',dateTime,'\n')
name_list = []
platfor_list = []
releaseInfo_list = []
heat_list = []
play_list = []#把抓取到的数据放在列表里面
for dic in data_list['list']:
name = dic['seriesInfo']['name']
platfor = dic['seriesInfo']['platformDesc']
releaseInfo = dic['seriesInfo']['releaseInfo']
heat = dic['currHeatDesc']
try:
play = dic['playCountSplitUnit']['num']#这部分是数据的解析提取
except:
play = None
print(name,platfor,releaseInfo,'{}万热度 '.format(heat),'{}万播放量'.format(play),'\n')
name_list.append(name)
platfor_list.append(platfor)
releaseInfo_list.append(releaseInfo)
heat_list.append(heat)
play_list.append(play)
return dateTime,name_list,platfor_list,releaseInfo_list,heat_list,play_list
def ptable_to_csv():#数据的持久化储存
dic = {
'时间':get_requests()[0],
'剧名':get_requests()[1],
'平台':get_requests()[2],
'上线时间':get_requests()[3],
'热度(万)':get_requests()[4],
'平台播放量(万)':get_requests()[5],
}
data = DataFrame(data=dic)
data.to_csv('video_data.csv',encoding='utf-8-sig',mode='a',header=None)
def main():
while True:
ptable_to_csv()
time.sleep(30)#循环,实验效果,这里设置是30秒抓一次(可以设置30分钟等)
main()
ok,下面是抓取效果: