

selenium爬虫 :使用selenium爬取淘宝某口红店铺的用户对商品的评价
本作品不可用于任何商业途径,仅供学习交流!!!
分析:
打开淘宝某个口红商品店铺的网页,打开抓包工具,刷新网页进行抓包

使用浏览器打开淘宝某个口红商品店铺的网页,初始进入网页如图:
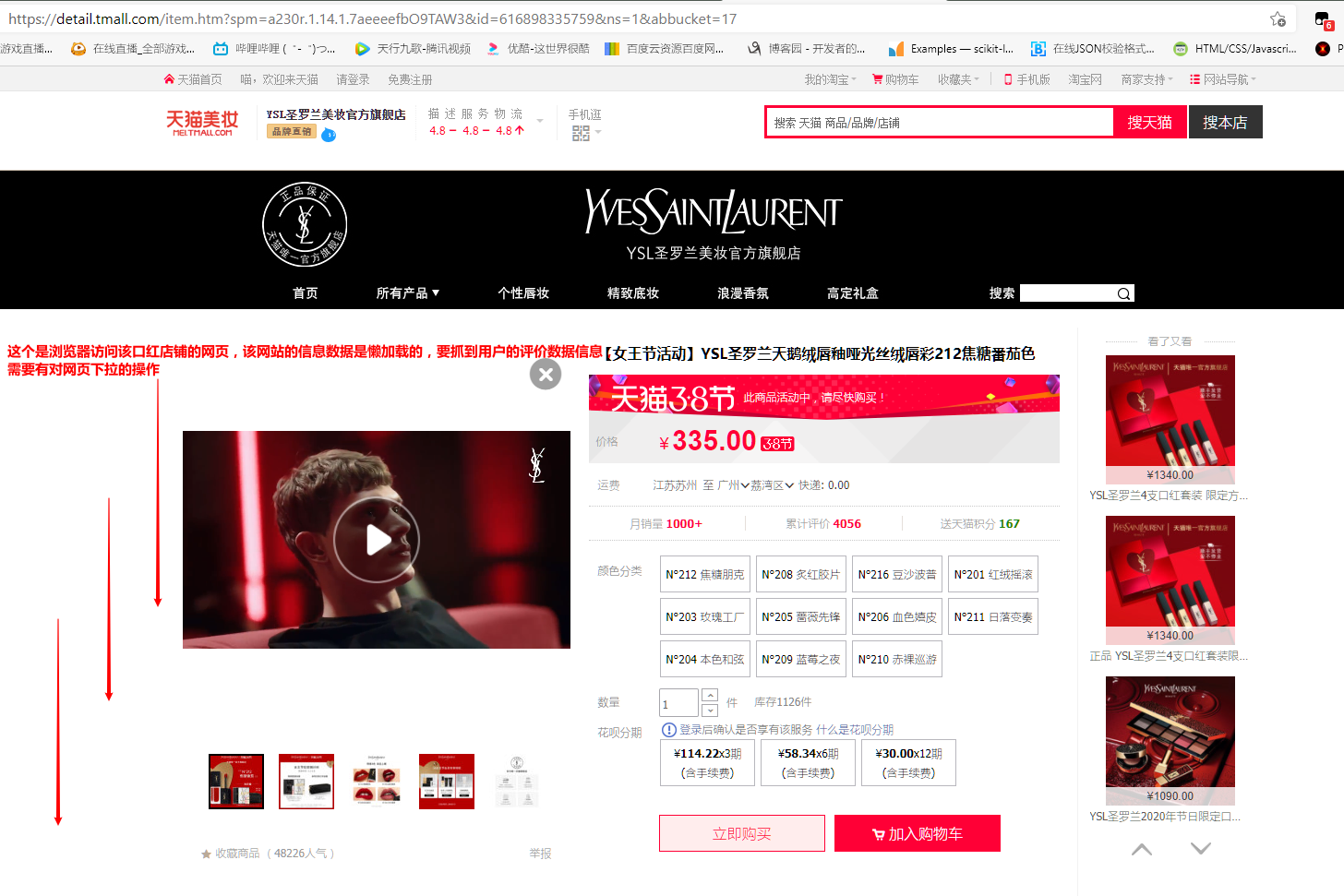
下拉(滚动)如下:
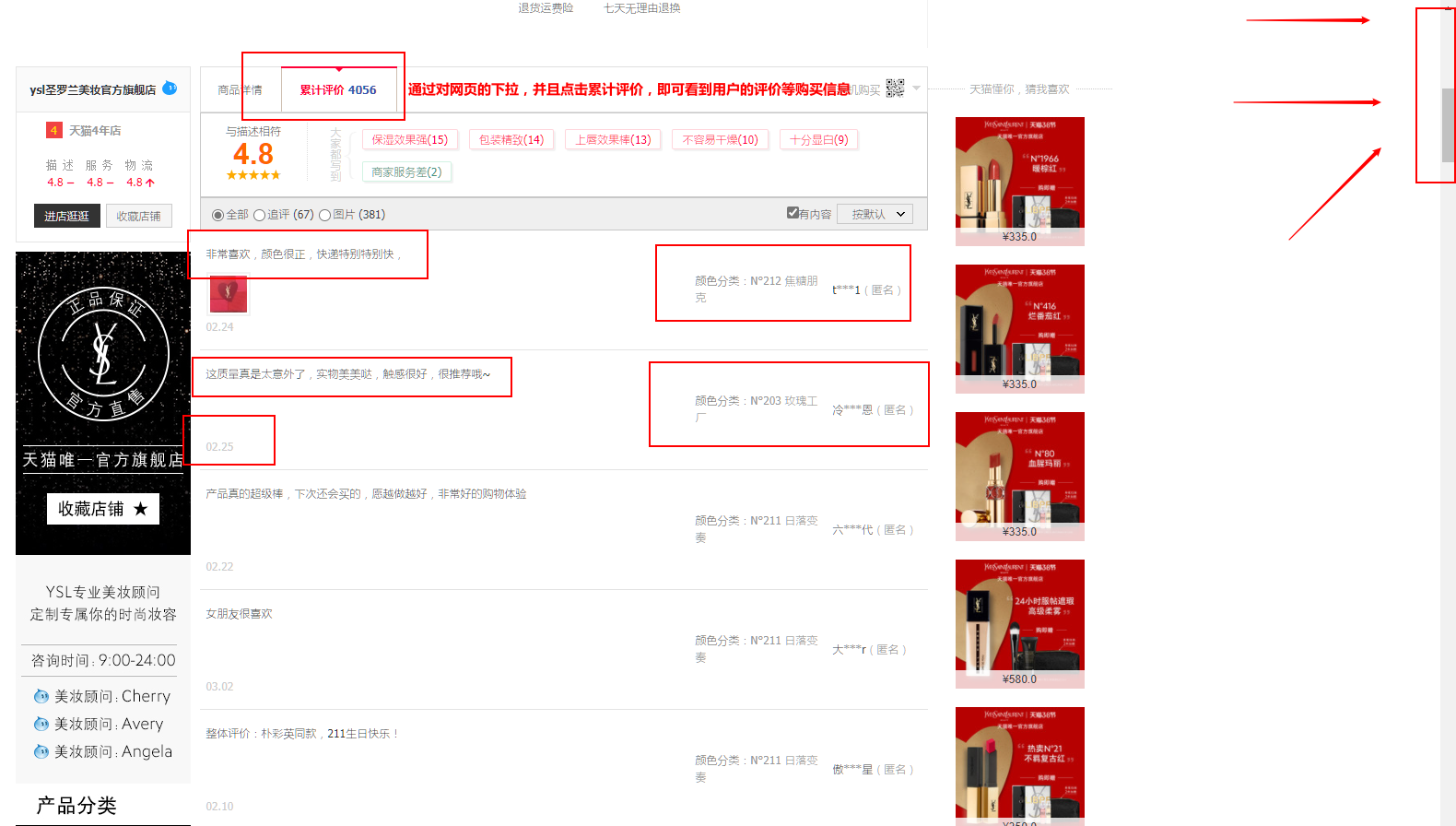
分析结论:
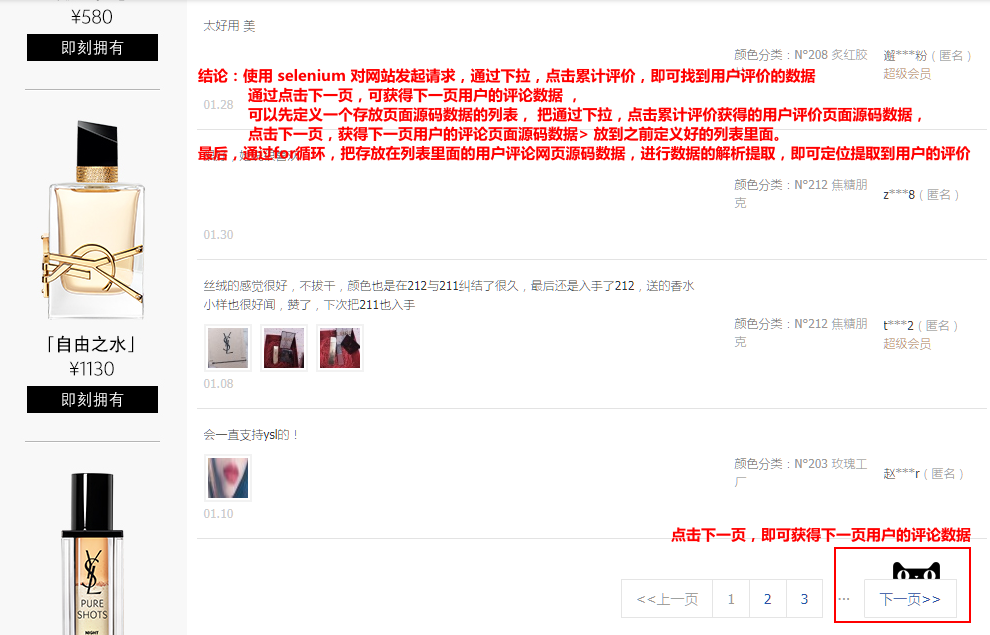
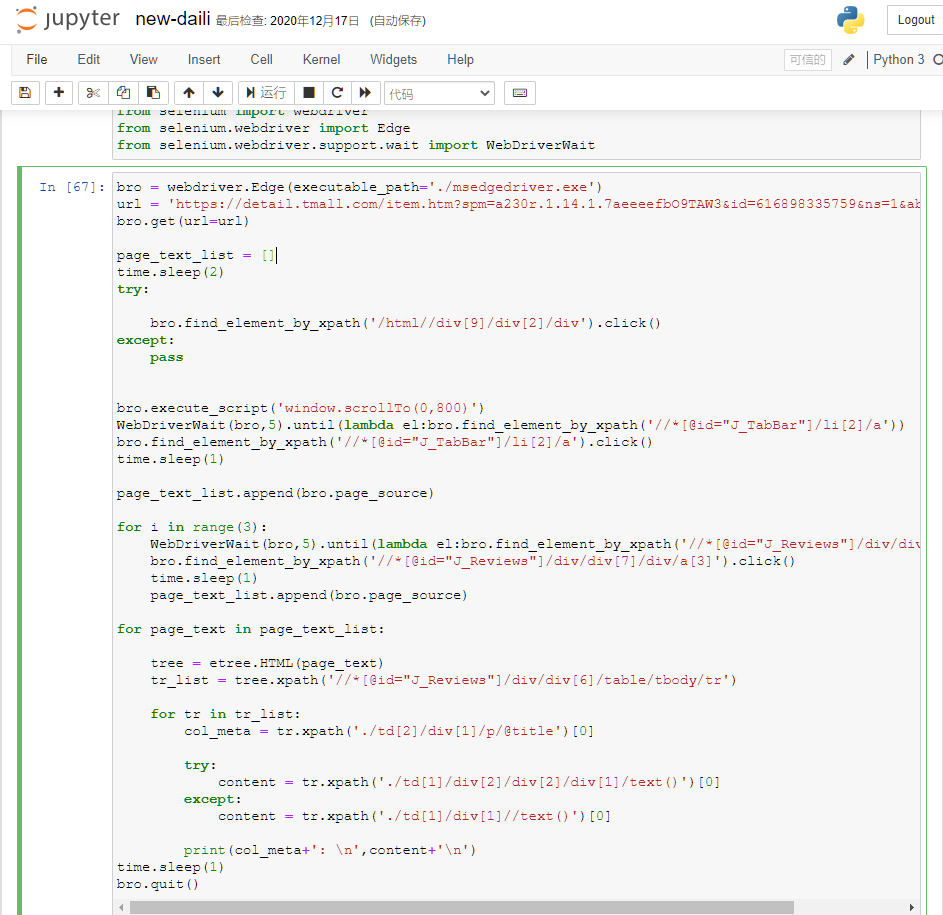
代码部分:
在 jupyter 编码如图:
导入的包
数据提取解析的代码:
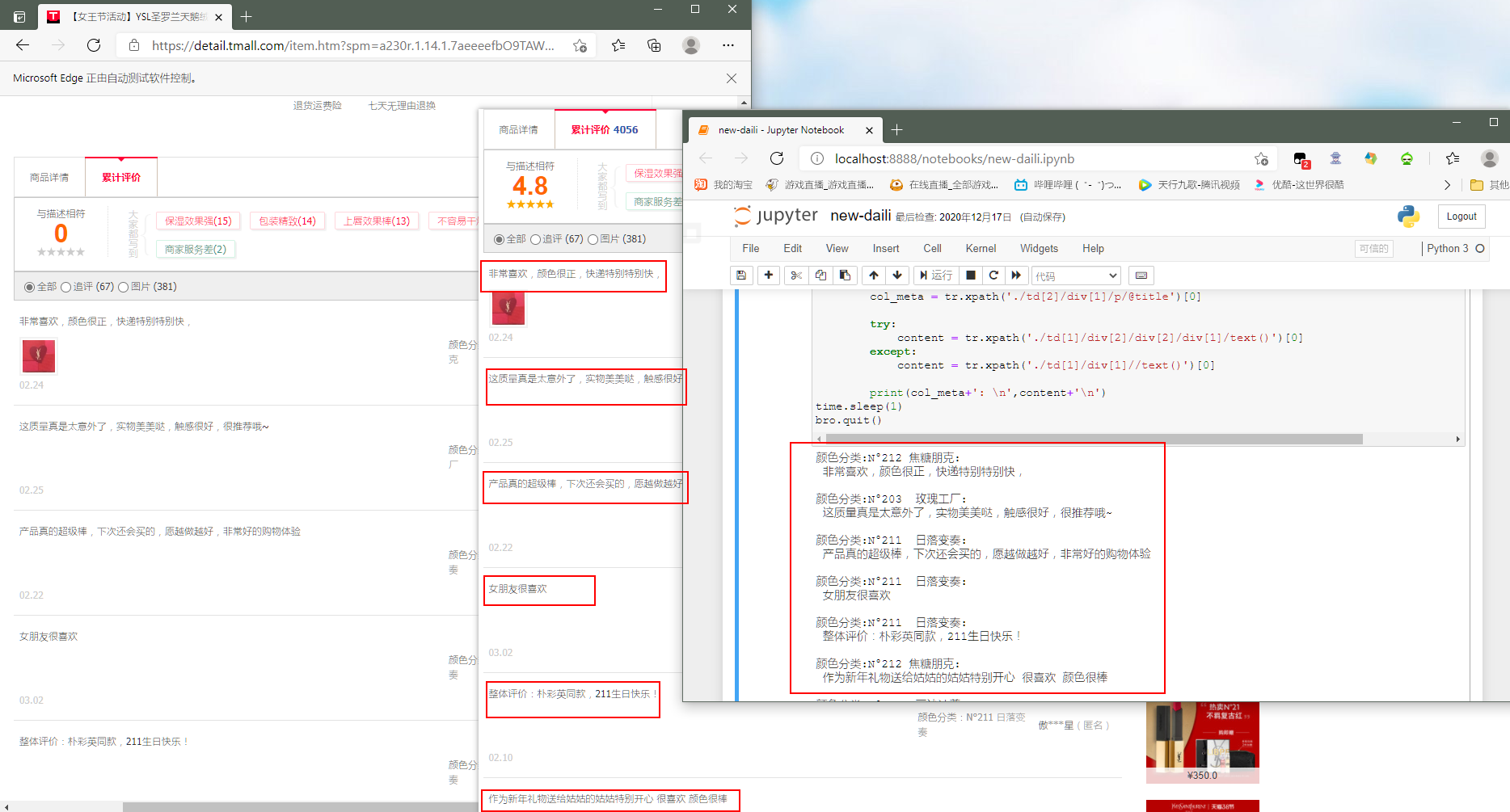
ok,下面是跑该项目的效果图:
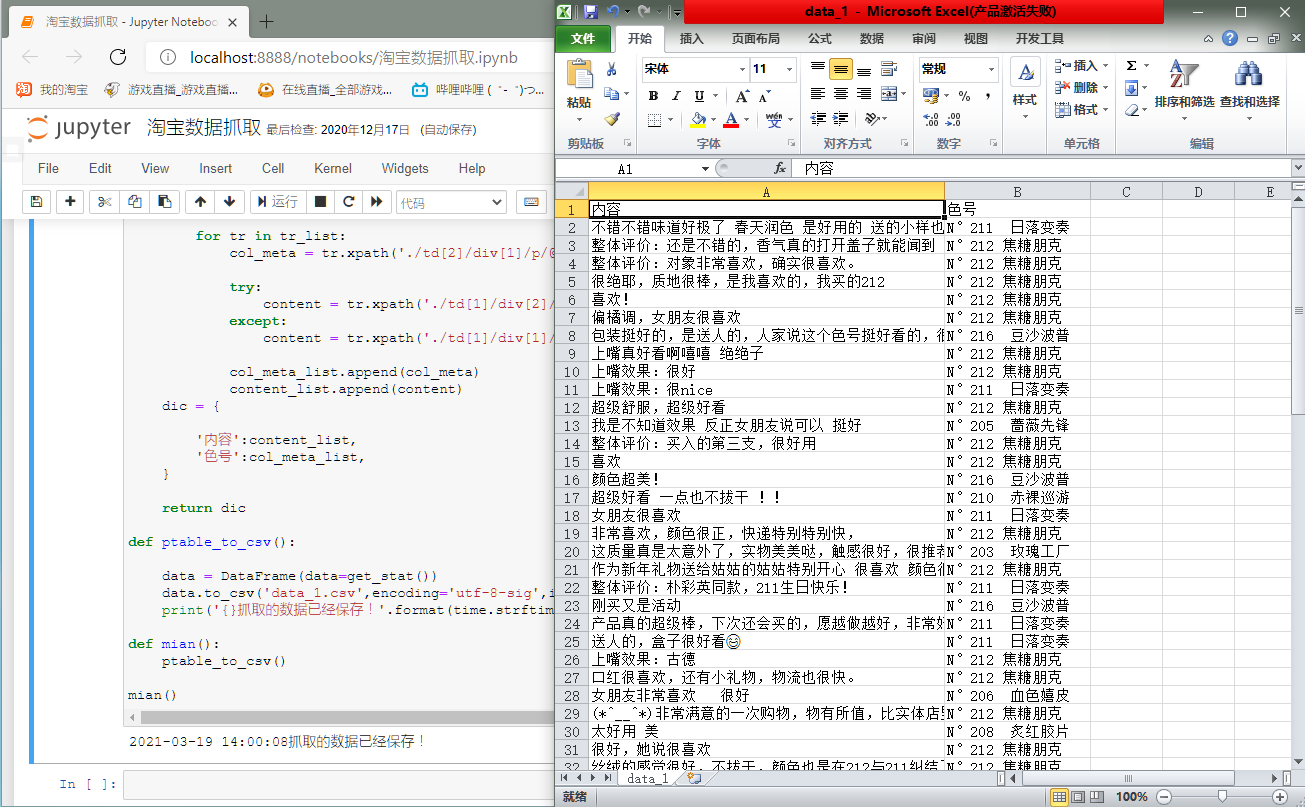
现在更新(把抓取到的数据保存在csv里面):
import time
from lxml import etree
from pandas import DataFrame
from selenium import webdriver
from selenium.webdriver import Edge
from selenium.webdriver.support.wait import WebDriverWait
def get_request():
bro = webdriver.Edge(executable_path='./msedgedriver.exe')
url = 'https://detail.tmall.com/item.htm?spm=a230r.1.14.1.7aeeeefbO9TAW3&id=616898335759&ns=1&abbucket=17'
bro.get(url=url)
page_text_list = []
time.sleep(2)
try:
bro.find_element_by_xpath('/html//div[9]/div[2]/div').click()
except:
pass
bro.execute_script('window.scrollTo(0,800)')
WebDriverWait(bro,5).until(lambda el:bro.find_element_by_xpath('//*[@id="J_TabBar"]/li[2]/a'))
bro.find_element_by_xpath('//*[@id="J_TabBar"]/li[2]/a').click()
time.sleep(1)
page_text_list.append(bro.page_source)
for i in range(3):
WebDriverWait(bro,5).until(lambda el:bro.find_element_by_xpath('//*[@id="J_Reviews"]/div/div[7]/div/a[3]'))
bro.find_element_by_xpath('//*[@id="J_Reviews"]/div/div[7]/div/a[3]').click()
time.sleep(1)
page_text_list.append(bro.page_source)
bro.quit()
return page_text_list
def get_stat():
col_meta_list = []
content_list = []
for page_text in get_request():
tree = etree.HTML(page_text)
tr_list = tree.xpath('//*[@id="J_Reviews"]/div/div[6]/table/tbody/tr')
for tr in tr_list:
col_meta = tr.xpath('./td[2]/div[1]/p/@title')[0][5:]
try:
content = tr.xpath('./td[1]/div[2]/div[2]/div[1]/text()')[0]
except:
content = tr.xpath('./td[1]/div[1]//text()')[0]
col_meta_list.append(col_meta)
content_list.append(content)
dic = {
'内容':content_list,
'色号':col_meta_list,
}
return dic
def ptable_to_csv():
data = DataFrame(data=get_stat())
data.to_csv('data_1.csv',encoding='utf-8-sig',index=False)
print('{}抓取的数据已经保存!'.format(time.strftime("%Y-%m-%d %H:%M:%S")))
def mian():
ptable_to_csv()
mian()
本作品不可用于任何商业途径,仅供学习交流!!!
