


scrapy框架+redis增量式爬虫: 抓取某短视频里面发布的视频的观看次数、点赞等信息的项目工程!
本文仅供学习与交流,切勿用于非法用途!!!
第一部分 分析:
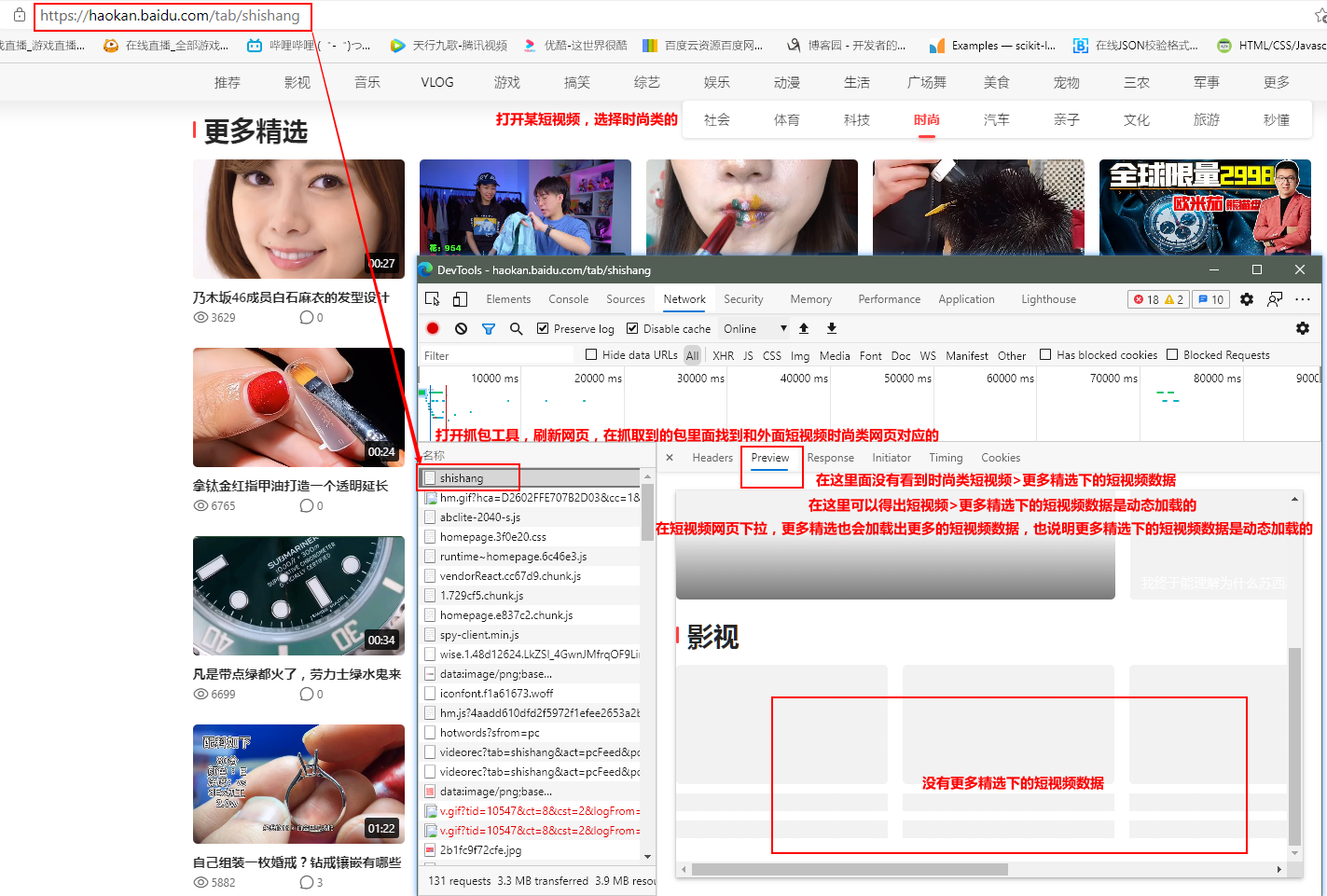
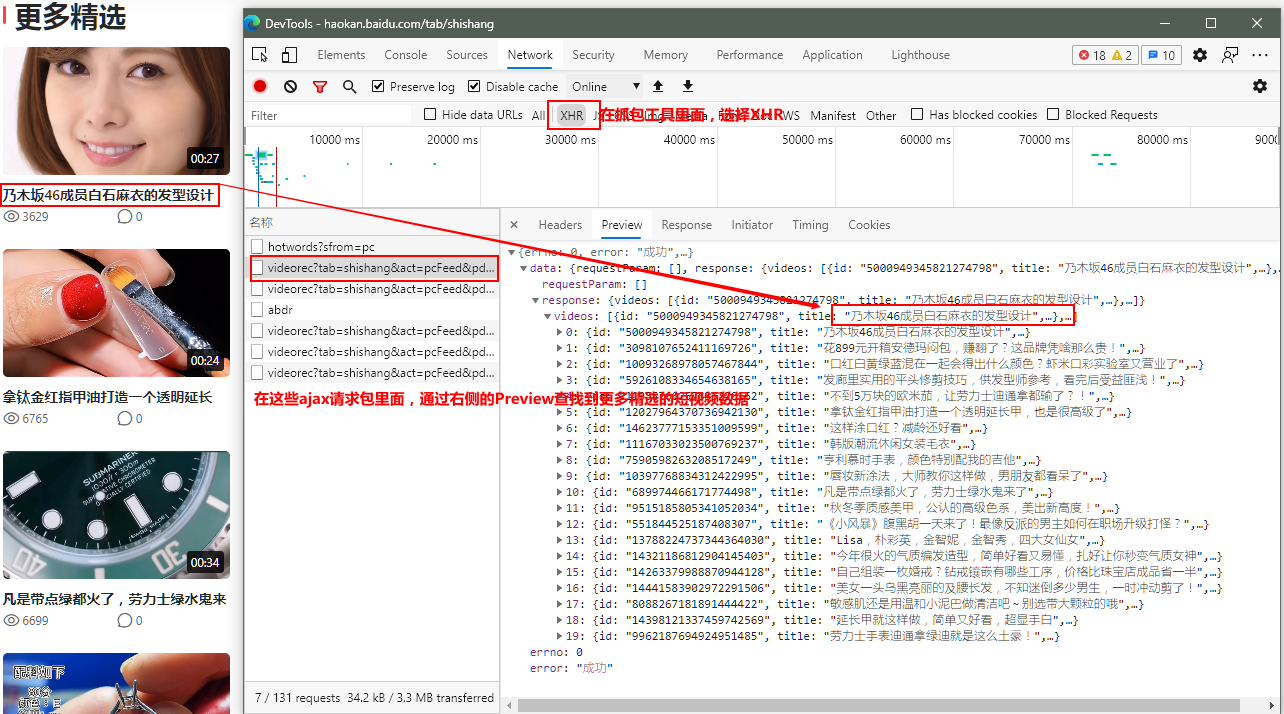
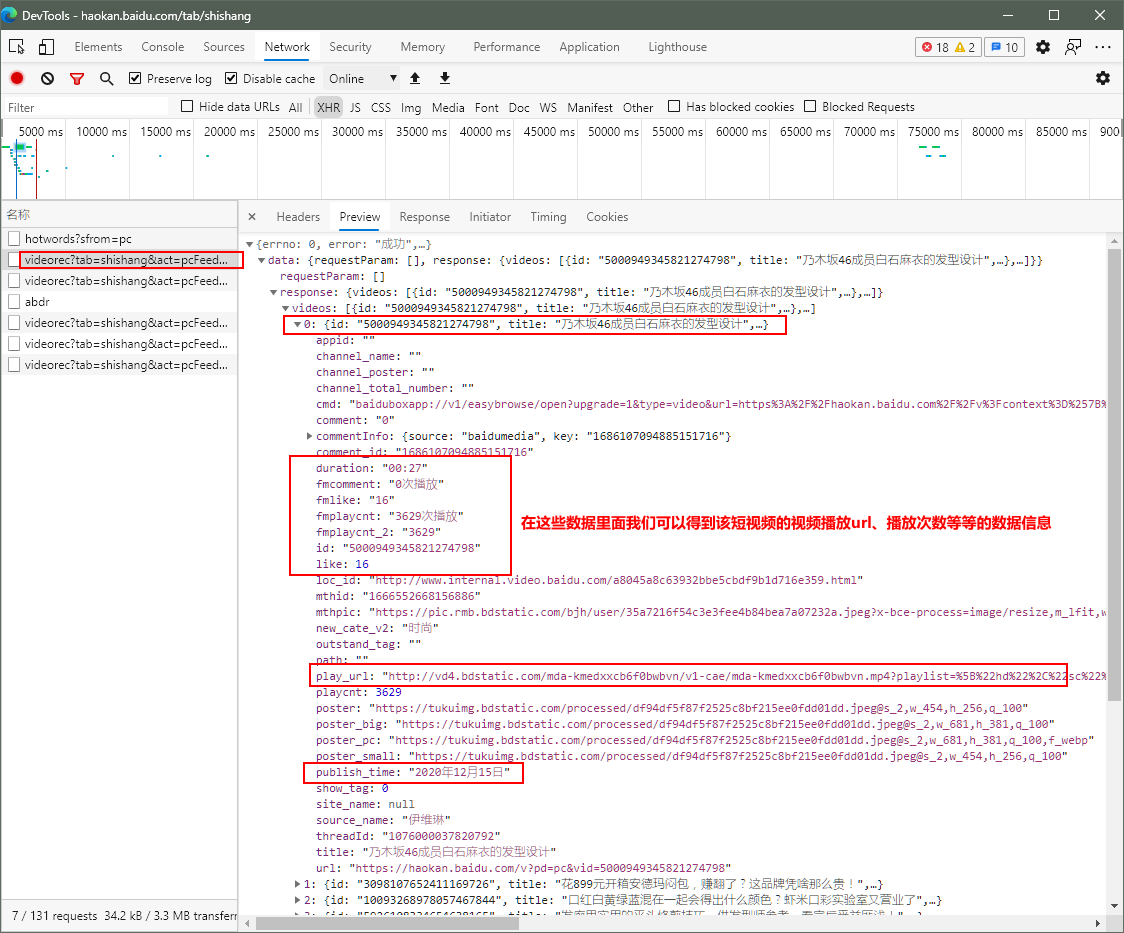

第二部分 实现该工程代码:
这里使用: scrapy startproject ProName > cd ProName > scrapy ganspider spiderName www.xxx.com 创建scrapy工程和爬虫文件.
创建好scrapy工程后,在配置文件settings.py里面设置USER_AGENT、日志级别和ROBOTSTXT_OBEY:
USER_AGENT = '自己设置User_Agent'
LOG_LEVEL = 'ERROR'#设置指定输出(报错的日志),减少CPU的使用率
ROBOTSTXT_OBEY = False #不遵从robots协议
spiderName.py 的代码:
import scrapy
import time
from haokanPro.items import HaokanproItem
class HaokanSpider(scrapy.Spider):
name = 'haokan'
# allowed_domains = ['www.xxx.com'] #把这个注释掉 用不到
start_urls = ['https://haokan.baidu.com/videoui/api/videorec?tab=shishang&act=pcFeed&pd=pc&num=20&shuaxin_id={}'.format(int(round(time.time()*1000)))] #工程起始请求该短视频的url
url = 'https://haokan.baidu.com/videoui/api/videorec?tab=shishang&act=pcFeed&pd=pc&num=20&shuaxin_id={}'.format(int(round(time.time() * 1000))) # 设置这个为刷新该短视频的url
sun = 0 #设置起始刷新的次数,用来做手动请求刷新
def parse(self, response):
page_dic = response.json()['data']['response']['videos'] #从之前的分析可以知道,短视频的ajax请求返回的是json,这里使用json对需要的数据信息进行解析提取
for dic in page_dic:
video_title = dic['title']
video_url = dic['play_url']
source_name = dic['source_name']
publish_time = dic['publish_time']
fmlike = dic['fmlike']
fmplaycnt = dic['fmplaycnt']
item = HaokanproItem() #实例化一个item对象,并且将解析到的数据储存到该对象中
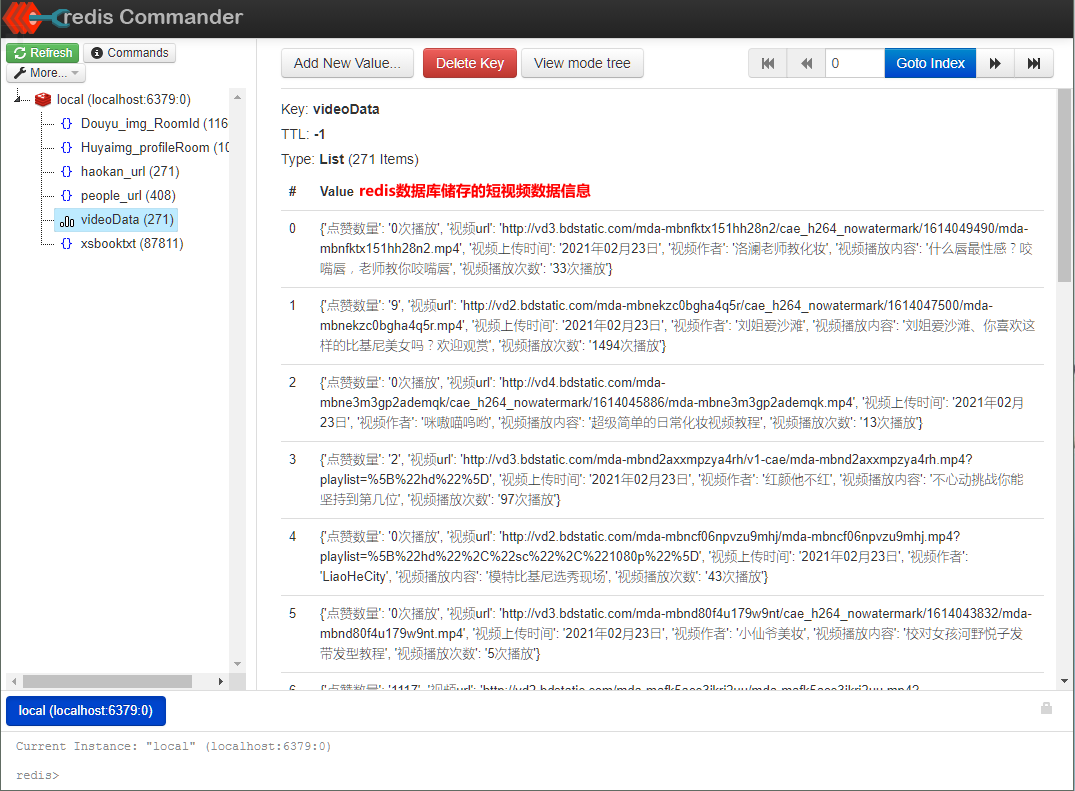
item['视频播放内容'] = video_title
item['视频url'] = video_url
item['视频作者'] = source_name
item['视频上传时间'] = publish_time
item['点赞数量'] = fmlike
item['视频播放次数'] = fmplaycnt
yield item #把提取的数据提交给管道
time.sleep(0.5)#设置个等待时间 防止ip被封
if self.sun < 11: #结束递归的条件
new_url = self.url
self.sun += 1
yield scrapy.Request(url=new_url, callback=self.parse)#通过多次刷新短视频url来获取短视频里面发布的视频的观看次数、点赞等信息,并且把返回的数据给函数parse解析提取数据
** items.py 的代码:**
class HaokanproItem(scrapy.Item):
视频播放内容 = scrapy.Field()
视频url = scrapy.Field()
视频作者 = scrapy.Field()
视频上传时间 = scrapy.Field()
点赞数量 = scrapy.Field()
视频播放次数 = scrapy.Field()
通过多次刷新短视频url来获取短视频里面发布的视频的观看次数、点赞等信息,肯定会有重复的,这里使用redis数据库短视频的播放url进行记录表出重处理,在数据管道 pipelines.py 使用redis数据库做记录表出重处理:
from redis import Redis#导入Redis
class HaokanproPipeline:
conn = Redis(host='127.0.0.1', port=6379)#数据库链接对象
def process_item(self, item, spider):
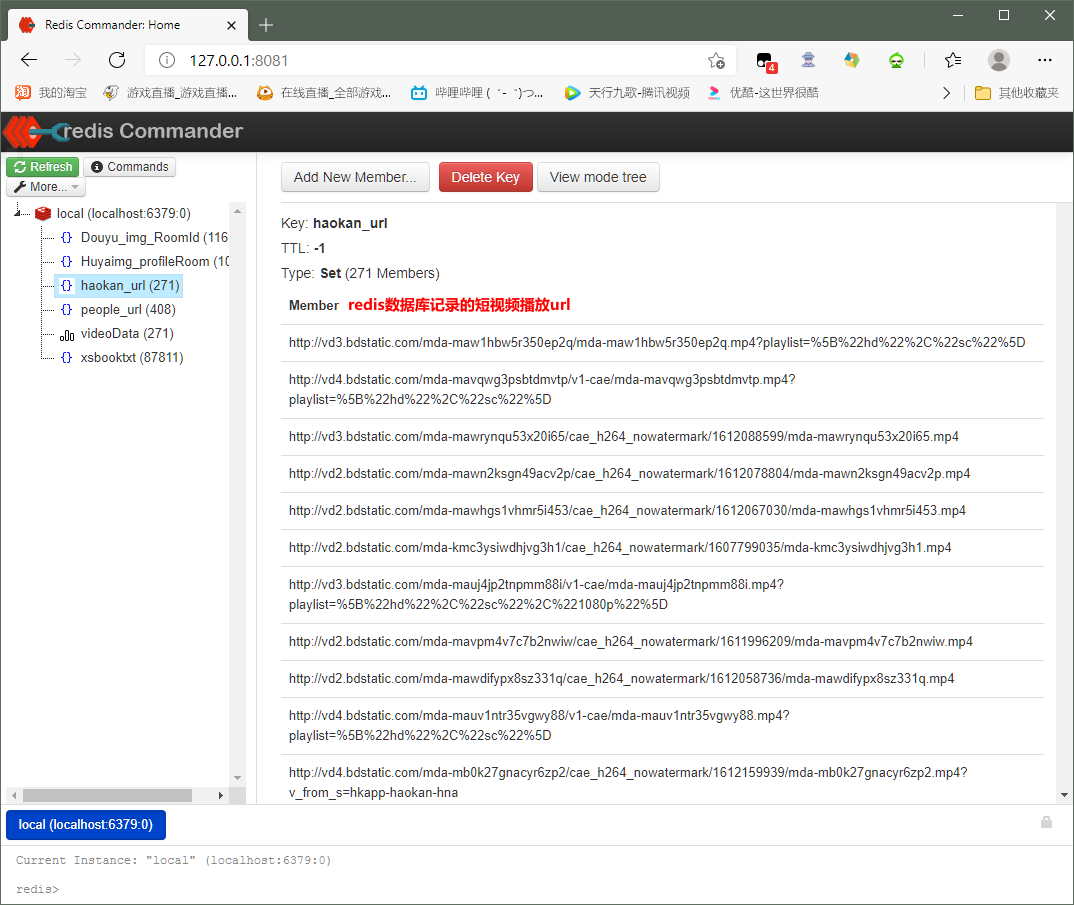
ex = self.conn.sadd('haokan_url',item['视频url'] )#把短视频的播放url储存在redis数据库里面,储存的文件夹命名为'haokan_url'
if ex == 1:#表示url没有记录在redis数据库里面
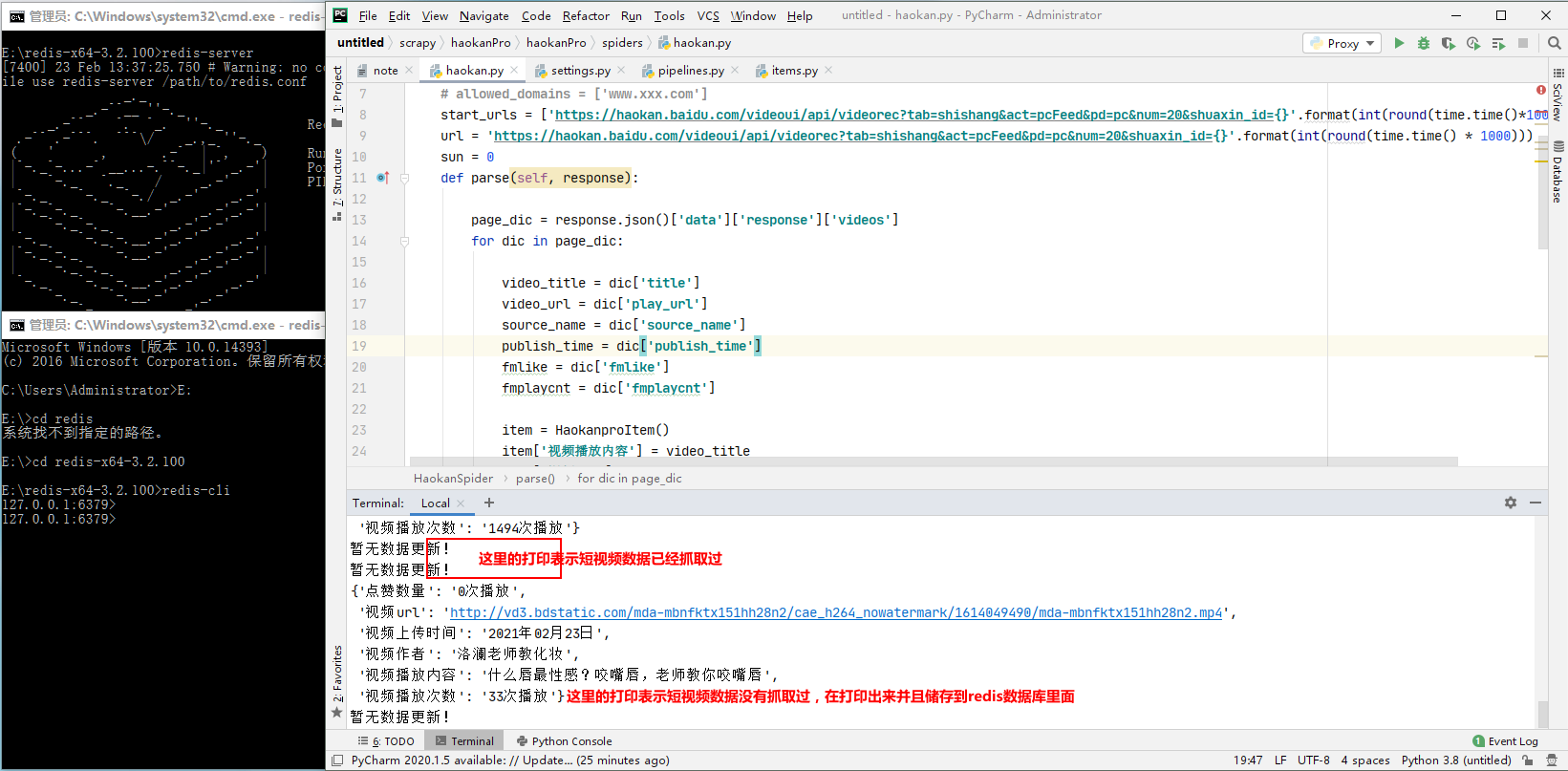
print(item)#打印下短视频的信息
self.conn.lpush('videoData',item)#把抓取到的短视频信息保存到redis数据库里面,储存的数据的文件夹命名为'videoData'
else:
print('暂无数据更新!')#表示url有记录在redis数据库haokan_url里面
return item
ok 然后在 配置文件 settings.py 里面开启数据管道:
ITEM_PIPELINES = {
'haokanPro.pipelines.HaokanproPipeline': 300,
}
最后开启redis数据库 跑下工程:

本文可以借鉴学习,切勿照搬,根据自己分析的实际情况实现项目!!!

