爬虫大作业(对电影的爬取)
一.实现过程: 1.我爬取的是对电影的分析:我爬取的方式是以浏览器来代理的。首先我对电影的计数设置了一个变量num=1;然后用All_txt=[]来存储全部电影的全部信息,我使用的是一个列表;用headers变量来使用浏览器获取。
导入词云:
from wordcloud import WordCloud,ImageColorGenerator
生成词云代码:
def getWordColod(wc): image = Image.open('./movie.png') graph = np.array(image) font = r'C:\Windows\Fonts\simhei.TTF' wc = WordCloud(font_path=font, background_color='White', max_words=80, mask=graph) wc.generate_from_frequencies(wc) image_color = ImageColorGenerator(graph) plt.imshow(wc) plt.axis("off") plt.show()
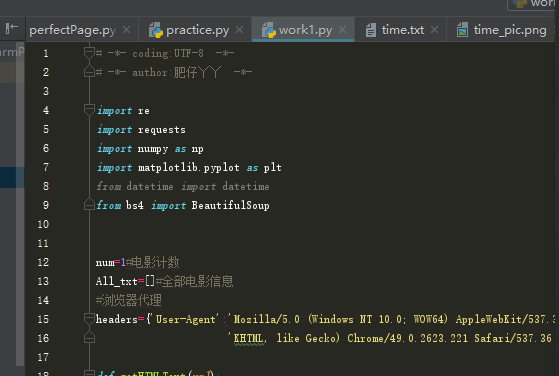

使用到的库
2.使用def getHTMLText(url)函数来调试页面文本的错误。

3.使用get_all_information(url,page)函数来对每一部电影的页面中获取全部的电影信息。在该函数中调用了getHTMLText(url),如果txt!="错误",那么就会连续输出第几页+NO+第几部电影+Get it!,如果电影数量等于247,那么就输出完成(finished!!!!)。当然在获取每部电影的全部信息时,我使用正则表达式和find_all来获取页面的所有信息,并且在此函数中我还使用了BeautifulSoup库来获取每部电影的标题、导演、播放时长、中英文电影名,评分、主演等等。获取完第每一部电影后num+1。
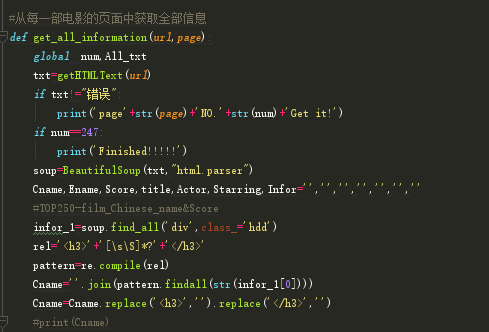

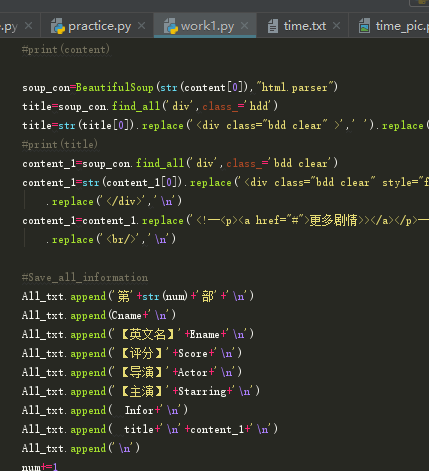
4.使用Analyze_some_infor函数来将所有电影的年份统计并声明条形图。使用了matplotlib库来来设置字体以及大小,使用file来保存成time.txt。而且横坐标是时间,最终用matplotlib库来保存成time_pic图片,该图片可编辑横纵坐标的大小。
5.在主方法main可将All_infor.txt文件清空或者写进一些新数据。
6.所有实现的结果还有文档内容:work1为我本次的项目名称,生成247部电影的全部信息All_infor.txt,还有使用time_pic条形图来生成电影年份的分析。




二.遇到的问题: 1,因为对matplotlib库的不熟悉,所以在使用该库来生成条形图时出现了数量上的偏差; 2.还有就是对BeautifulSoup库的不熟悉,在获取电影全部信息的时候,对信息提取不完整。 三.解决方法: 主要是通过网上菜鸟教程上学习寻找这两个库的知识点,还有就是百度和在知乎上问有经验的人。 四.数据分析以及结论。 在刚开始接触python代码是很激动的,因为这语言不但简单,而且代码还特别少,并容易懂,实现的功能比较有趣。又因为我比较喜欢看电影和追剧,所以我就爬取了关于“电影”方面的分析。在分析电影时,我是有按照老师所教给我们的知识点来慢慢爬取的。在课堂上老师教了怎样爬取网页的内容,标题、作者等等,还讲述了关于文件的存储。所以我是按照这些知识点来爬取电影的所有信息,我总共爬取了247部

 浙公网安备 33010602011771号
浙公网安备 33010602011771号