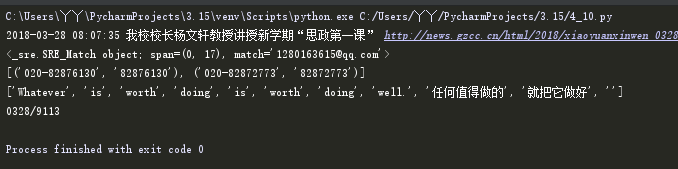
1. 用正则表达式判定邮箱是否输入正确。
q='^(\w)+(\.\w+)*@(\w)+((\.\w{2,3}){1,3})$'
qq='1280163615@qq.com'
if re.match(q,qq):
print(re.match(q,qq))
else:
print("您输入的邮箱号码是错误的,请重新输入!")
![]()
2. 用正则表达式识别出全部电话号码。
str='''版权所有:广州商学院 地址:广州市黄埔区九龙大道206号
学校办公室:020-82876130 招生电话:020-82872773
粤公网安备 44011602000060号 粤ICP备15103669号'''
p=re.findall('(\d{3,4}-(\d{6,8}))',str)
print(p)
![]()
3. 用正则表达式进行英文分词。re.split('',news)
news='''Whatever is worth doing is worth doing well.
任何值得做的,就把它做好。'''
word=re.split('[\s,。,]+',news)
print(word)
![]()
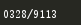
4. 使用正则表达式取得新闻编号
res=requests.get('http://news.gzcc.cn/html/2018/xiaoyuanxinwen_0328/9113.html')
res.encoding='utf-8'
url = 'http://news.gzcc.cn/html/2018/xiaoyuanxinwen_0328/9113.html'
t = re.match('http://news.gzcc.cn/html/2018/xiaoyuanxinwen_(.*).html',url).group(1).rstrip('/')
![]()
5. 生成点击次数的Request URL
def getClickCount(newsUrl):
newsId=re.search('\_(.*).html',newsUrl).group(1).split('/')[-1]
res = requests.get('http://oa.gzcc.cn/api.php?op=count&id=9113&modelid=80'.format(newsId))
![]()
6. 获取点击次数
return (int(res.text.split('.html')[-1].lstrip("(')").rstrip("');")))
![]()
7. 将456步骤定义成一个函数 def getClickCount(newsUrl):
def getClickCount(newsUrl):
newsId=re.search('\_(.*).html',newsUrl).group(1).split('/')[-1]
res = requests.get('http://oa.gzcc.cn/api.php?op=count&id=9113&modelid=80'.format(newsId))
return (int(res.text.split('.html')[-1].lstrip("(')").rstrip("');")))
8. 将获取新闻详情的代码定义成一个函数 def getNewDetail(newsUrl):
def getNewsDetail(newsUrl):
resd=requests.get(newsUrl)
resd.encoding='utf-8'
soupd=BeautifulSoup(resd.text,'html.parser')#打开新闻详情页
![]()





 浙公网安备 33010602011771号
浙公网安备 33010602011771号