
Spark机器学习库
https://spark.rstudio.com/guides/mlib.html
Spark机器学习库
sparklyr提供了Spark分布式机器学习库的绑定。特别是,允许你访问 spark.ml 包提供的机器学习例程。结合 sparklyr的 dplyr 接口,您可以轻松地在 Spark 上创建和调整机器学习工作流,这些工作流完全在 R 中编排。
sparklyr提供了三个可与 Spark 机器学习一起使用的函数系列:
- 用于分析数据的机器学习算法 (ml_*)
- 用于操作单个特征的特征转换器 (ft_*)
- 用于操作 Spark 数据帧的函数 (sdf_*)
sparklyr的分析工作流可能由以下阶段组成。
通过 sparklyr dplyr 接口执行 SQL 查询
使用 sdf_*和 ft_*系列函数生成新列,或对数据集进行分区从函数ml_*系列中选择适当的机器学习算法来对数据进行建模
检查模型拟合的质量,并使用它来使用新数据进行预测。
收集结果,以便在 R 中进行可视化和进一步分析
公式
这些函数采用参数和 ,但也可以是具有主效应的公式(它目前不接受交互作用项),可以使用 ml_*responsefeaturesfeatures-1省略截距项。
以下两个语句是等效的:
1 2 3 | ml_linear_regression(z ~ -1 + x + y)ml_linear_regression(intercept = FALSE, response = "z", features = c("x", "y")) |
选项
可以使用函数中的参数修改 Spark 模型输出。这是一个专家专用界面,用于调整模型输出。例如ml_optionsml_*ml_optionsmodel.transform,可用于在执行拟合之前改变 Spark 模型对象。
转换
模型通常不适合于数据集,而是适合该数据集的某些转换。Spark 提供了功能转换器,促进了 Spark DataFrame 中数据的许多常见转换,并在函数系列中公开了这些转换。这些例程通常采用一个或多个输入列,并生成作为这些列的转换而形成的新输出列。
例子
我们将使用数据集来检查一些学习算法和转换器。Iris数据集测量 3 种不同鸢尾花中 150 朵花的属性。
1 2 3 4 5 6 7 8 9 10 11 | library(sparklyr)library(ggplot2)library(dplyr)sc <- spark_connect(master = "local")iris_tbl <- copy_to(sc, iris, "iris", overwrite = TRUE)iris_tbl |
(1)K 均值聚类
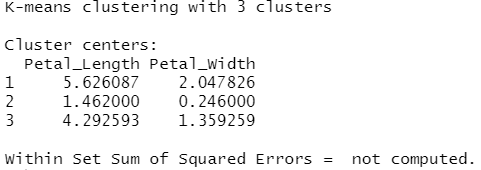
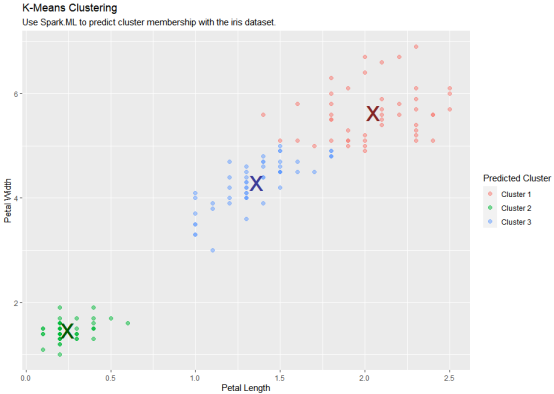
使用 Spark 的 K 均值聚类将数据集划分为多个组。K 均值将点聚类划分为组K,以便将点到指定聚类中心的平方和最小化。
1 2 3 4 5 | kmeans_model <- iris_tbl %>% ml_kmeans(k = 3, features = c("Petal_Length", "Petal_Width"))kmeans_model |
在 R 中运行并收集预测:
1 2 3 4 5 | predicted <- ml_predict(kmeans_model, iris_tbl) %>% collect()table(predicted$Species, predicted$prediction) |

使用收集的数据绘制结果:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 | predicted %>% ggplot(aes(Petal_Length, Petal_Width)) + geom_point(aes(Petal_Width, Petal_Length, col = factor(prediction + 1)), size = 2, alpha = 0.5 ) + geom_point( data = kmeans_model$centers, aes(Petal_Width, Petal_Length), col = scales::muted(c("red", "green", "blue")), pch = "x", size = 12 ) + scale_color_discrete( name = "Predicted Cluster", labels = paste("Cluster", 1:3) ) + labs( x = "Petal Length", y = "Petal Width", title = "K-Means Clustering", subtitle = "Use Spark.ML to predict cluster membership with the iris dataset." ) |
(2)线性回归
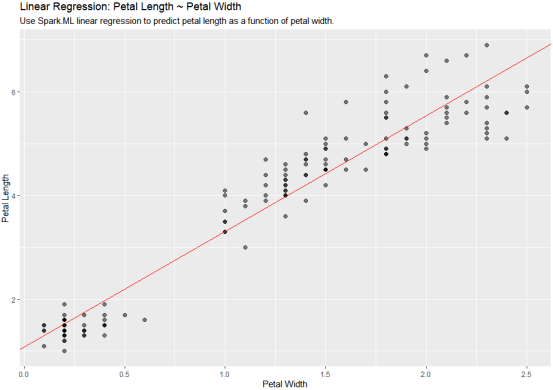
使用 Spark 的线性回归对响应变量与一个或多个解释变量之间的线性关系进行建模。
1 2 3 | lm_model <- iris_tbl %>% ml_linear_regression(Petal_Length ~ Petal_Width) |
将斜率和截距提取到离散 R 变量中。我们将使用它们来绘制:
1 2 3 | spark_slope <- coef(lm_model)[["Petal_Width"]]spark_intercept <- coef(lm_model)[["(Intercept)"]] |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 | iris_tbl %>% select(Petal_Width, Petal_Length) %>% collect() %>% ggplot(aes(Petal_Length, Petal_Width)) + geom_point(aes(Petal_Width, Petal_Length), size = 2, alpha = 0.5) + geom_abline(aes( slope = spark_slope, intercept = spark_intercept ), color = "red" ) + labs( x = "Petal Width", y = "Petal Length", title = "Linear Regression: Petal Length ~ Petal Width", subtitle = "Use Spark.ML linear regression to predict petal length as a function of petal width." ) |
(3)逻辑回归
使用 Spark 的逻辑回归来执行逻辑回归,将二进制结果建模为一个或多个解释变量的函数。
1 2 3 4 5 6 7 | glm_model <- iris_tbl %>% mutate(is_setosa = ifelse(Species == "setosa", 1, 0)) %>% select_if(is.numeric) %>% ml_logistic_regression(is_setosa ~.) |
1 | summary(glm_model) |

1 2 3 | ml_predict(glm_model, iris_tbl) %>% count(Species, prediction) |

(4)PCA
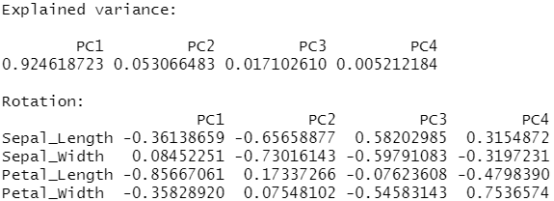
使用 Spark 的主成分分析 (PCA) 执行降维。PCA 是一种统计方法,用于查找旋转,使得第一个坐标具有可能的最大方差,而每个后续坐标又具有可能的最大方差。
1 2 3 4 5 | pca_model <- tbl(sc, "iris") %>% select(-Species) %>% ml_pca() |
1 | pca_model |
(5)随机森林
使用 Spark 的随机森林执行回归或多类分类。
1 2 3 4 5 6 7 8 9 10 | rf_model <- iris_tbl %>% ml_random_forest( Species ~ Petal_Length + Petal_Width, type = "classification") |
用于使用将新模型应用会数据。ml_predict()
1 | rf_predict <- ml_predict(rf_model, iris_tbl) |
1 | glimpse(rf_predict) |
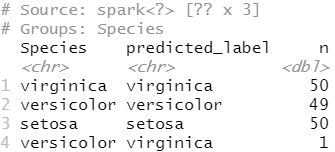
要了解模型的有效性,请使用将物种与预测进行比较。
rf_predict %>%
count(Species, predicted_label)
(6)FT 字符串索引
使用 和 将字符列转换为数字列,然后再转换回来。ft_string_indexer()ft_index_to_string()
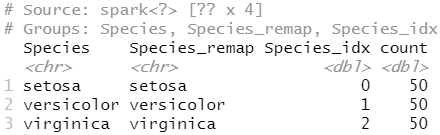
1 2 3 4 5 6 7 | ft_string2idx <- iris_tbl %>% ft_string_indexer("Species", "Species_idx") %>% ft_index_to_string("Species_idx", "Species_remap") %>% select(Species, Species_remap, Species_idx) |
要查看 中分配给每个值的值,我们可以提取所有物种的聚合,重新映射的物种和索引组合:Species
1 2 3 4 5 | ft_string2idx %>% group_by_all() %>% summarise(count = n(), .groups = "keep") |
(7)断开与 Spark 的连接
最后,通过断开 Spark 连接来清理会话:
1 | spark_disconnect(sc) |
#决策树
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | sc <- spark_connect(master = "local")iris_tbl <- sdf_copy_to(sc, iris, name = "iris_tbl", overwrite = TRUE) partitions <- iris_tbl %>% sdf_random_split(training = 0.7, test = 0.3, seed = 1111) iris_training <- partitions$trainingiris_test <- partitions$test dt_model <- iris_training %>% ml_decision_tree(Species ~ .)pred <- ml_predict(dt_model, iris_test)ml_multiclass_classification_evaluator(pred) |
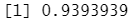
#梯度提升树
1 2 3 4 5 6 7 8 | gbt_model <- iris_training %>% ml_gradient_boosted_trees(Sepal_Length ~ Petal_Length + Petal_Width) pred <- ml_predict(gbt_model, iris_test) ml_regression_evaluator(pred, label_col = "Sepal_Length") |
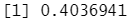
#高斯混合聚类
描述:此类对多元高斯混合模型 (GMM) 执行期望最大化。GMM 表示独立高斯分布的复合分布,具有相关的"混合"权重,指定每个权重对复合材料的贡献。给定一组采样点,此类将最大化 k 个高斯混合的对数似然,迭代直到对数似然数变化小于 ,或者直到达到最大迭代次数。虽然这个过程通常保证收敛,但不能保证找到全局最优。
1 2 3 4 5 | gmm_model <- ml_gaussian_mixture(iris_tbl, Species ~ .)pred <- sdf_predict(iris_tbl, gmm_model)ml_clustering_evaluator(pred) |
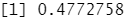
#一分为二的K均值聚类
描述:基于Steinbach, Karypis, and Kumar的论文 "A comparison of document clustering techniques "的一分为二的K-means算法,并进行了修改以适应Spark。该算法从一个包含所有点的单一集群开始。迭代地在底层找到可分割的聚类,并使用k-means对每个聚类进行二分,直到总共有k个叶子聚类或没有叶子聚类是可分割的。同一层次上的集群的平分步骤被分组,以增加并行性。如果对底层所有可分割的集群进行二分会导致超过k个叶子集群,则较大的集群会得到较高的优先权。
1 2 3 4 5 6 7 8 9 10 11 | library(dplyr)#sc <- spark_connect(master = "local")#iris_tbl <- sdf_copy_to(sc, iris, name = "iris_tbl", overwrite = TRUE)iris_tbl %>% select(-Species) %>% ml_bisecting_kmeans(k = 4, Species ~ .) |
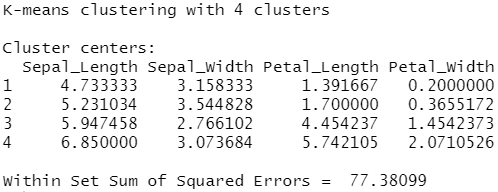
#K-means聚类
描述:Bahmani等人提出的支持k-means||初始化的K-means聚类,使用公式接口需要Spark 2.0+.ml_kmeans()。
1 2 3 4 5 6 7 8 9 10 11 12 | kmeans_model <- iris_tbl %>% ml_kmeans(k = 3, features = c("Petal_Length", "Petal_Width"))kmeans_model predicted <- ml_predict(kmeans_model, iris_tbl) %>% collect()table(predicted$Species, predicted$prediction) |
#在验证集上评估模型
1 2 3 | ml_gaussian_mixture(iris_tbl, Species ~ .) %>% #(高斯混合聚类) ml_evaluate(iris_tbl) |
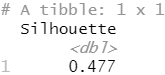
1 2 3 | ml_bisecting_kmeans(iris_tbl, Species ~ .) %>% #(一分为二的K均值聚类) ml_evaluate(iris_tbl) |
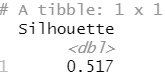
1 2 3 | ml_kmeans(iris_tbl, Species ~ .) %>% #(K均值聚类) ml_evaluate(iris_tbl) |
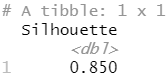
#聚类评估
描述:聚类结果的评估器。该指标使用欧氏距离的平方计算Silhouette措施。
Silhouette是一个用于验证聚类内一致性的措施。它的范围在1和-1之间,其中接近1的值意味着一个聚类中的点与同一聚类中的其他点接近,而与其他聚类的点远离。
1 | formula <- Species ~ . |
1 2 3 4 5 | kmeans_model <- ml_kmeans(iris_training, formula = formula)b_kmeans_model <- ml_bisecting_kmeans(iris_training, formula = formula)gmm_model <- ml_gaussian_mixture(iris_training, formula = formula) |
1 2 3 4 5 | pred_kmeans <- ml_predict(kmeans_model, iris_test)pred_b_kmeans <- ml_predict(b_kmeans_model, iris_test)pred_gmm <- ml_predict(gmm_model, iris_test) |
1 | ml_clustering_evaluator(pred_kmeans) #(K均值聚类) |
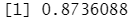
1 | ml_clustering_evaluator(pred_b_kmeans) #(一分为二的K均值聚类) |
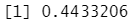
1 | ml_clustering_evaluator(pred_gmm) #(高斯混合聚类) |
本文来自博客园,作者:zhang-X,转载请注明原文链接:https://www.cnblogs.com/YY-zhang/p/16149770.html


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· 从HTTP原因短语缺失研究HTTP/2和HTTP/3的设计差异
· 三行代码完成国际化适配,妙~啊~