逻辑回归(Logistic)及案例分析、线性判别分析(LDA)、二次判别分析(QDA)
逻辑回归:股票市场数据
library(ISLR) names(Smarket)
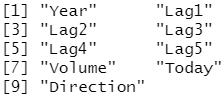
dim(Smarket)
summary(Smarket) pairs(Smarket) #pairs()函数用于返回一个绘图矩阵,由每个 DataFrame 对应的散点图组成。
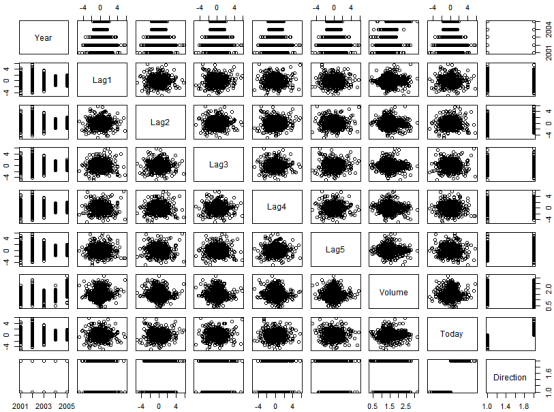
cor(Smarket[,-9]) #cor ()函数可以计算所有预测变最两两之间相关系数的矩阵。

解释:相关的是 Year和Volume ,通过画图可以观察到 Volume 随时间一直增长,也就是说从 2001 年至 2005 年平均每日股票成交盘在增长。
attach(Smarket) plot(Volume)

逻辑回归
glm.fits=glm(Direction~Lag1+Lag2+Lag3+Lag4+Lag5+Volume,data=Smarket,family=binomial)#设置family=binomial是请求R执行逻辑斯蒂回归 summary(glm.fits)
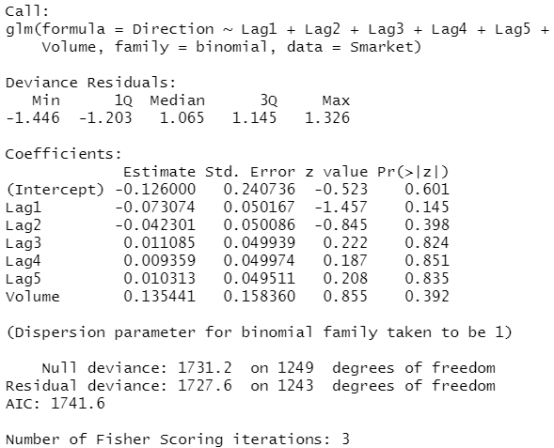
结果分析:这里最小的 值是Lag1的系数。预测变量负的系数表明如果市场昨天的投资回报率是正的,那么今日市场可能不会上涨。
coef(glm.fits) #调用coef ()函数可获取拟合模型的系数

summary(glm.fits)$coef #查看详细信息 summary(glm.fits)$coef[,4] glm.probs=predict(glm.fits,type="response") #predict ()函数可用来预测在给定预测变盘值下市场上涨的概率。选项 type =" re~ sponse" 是明确告诉R输出概率 P(Y=1| X) ,而不必输出其他信息。 glm.probs[1:10]

contrasts(Direction) #contrasts ()函数表创建了一个哑变量,1 代表 Up (上涨)。

#为预测特定某一天市场上涨还是下跌,必须将预测的概率转化为类别,Up 或者Down,这里以预测市场上涨概率比0.5 大还是小为依据。
glm.pred=rep("Down",1250)
glm.pred[glm.probs>.5]="Up"
table(glm.pred,Direction)
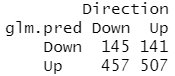
(507+145)/1250 #计算正确率
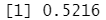
mean(glm.pred==Direction) #计算正确率
train=(Year<2005) #先建立一个向致表示2000年至 2004 年之间的观测,然后由这个向量
定义余下的 2005 年观测数据集。
解释:train 是一个布尔向量 (Boolean vector),train 是个有 1250 个元素的向量,对应数据集中的每条观测,该向量对数据集2005 年之前的数据设置为TRUE,对2005 年以后的数据标记为 FALSE" 。
Smarket.2005=Smarket[!train,] #2005年的观测数据 dim(Smarket.2005)
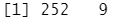
Direction.2005=Direction[!train] #因子型类别变量,Up 或者Down
glm.fits=glm(Direction~Lag1+Lag2+Lag3+Lag4+Lag5+Volume,data=Smarket,family=binomial,subset=train) #建立模型
glm.probs=predict(glm.fits,Smarket.2005,type="response") #预测
glm.pred=rep("Down",252)
glm.pred[glm.probs>.5]="Up"
table(glm.pred,Direction.2005)

mean(glm.pred==Direction.2005) #计算正确率
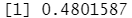
mean(glm.pred!=Direction.2005) #计算错误率
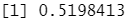
#加如与响应变量无关的预测变量会造成测试错误率的增大(因为这样的预测变量会增大模型方差,但不会相应地降低模型偏差) ,所以去除这样的预测变量可能会优化模型。所以重新拟合逻辑斯谛回归模型,只是用 Lag1和 Lag2 两个预测变量,因为它们在原逻辑斯谛因归模型中表现出了最佳的预测能力。
glm.fits=glm(Direction~Lag1+Lag2,data=Smarket,family=binomial,subset=train)
glm.probs=predict(glm.fits,Smarket.2005,type="response")
glm.pred=rep("Down",252)
glm.pred[glm.probs>.5]="Up"
table(glm.pred,Direction.2005)

mean(glm.pred==Direction.2005) #计算正确率
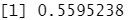
106/(106+76) #表明当预测市场上涨时,准确率有 58%
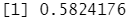
predict(glm.fits,newdata=data.frame(Lag1=c(1.2,1.5),Lag2=c(1.1,-0.8)),type="response") #特定的 Lagl1和Lag2 值下预测投资回报率。
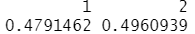
线性判别分析(Linear Discriminant Analysis,LDA)
#在对 Smarket 数据傲线性判别分析 (LDA) ,用 MASS 库中的 lda ()函数拟合一个 LDA 模型。lda ()函数与 lm() 函数语句是相彤的,也和glm ()类似,除了缺少family 选项。
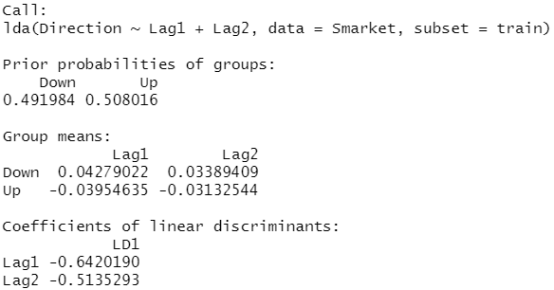
library(MASS) lda.fit=lda(Direction~Lag1+Lag2,data=Smarket,subset=train) #建立模型 lda.fit
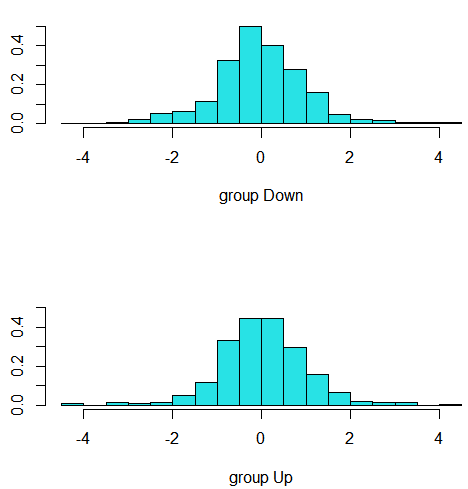
plot(lda.fit) #plot ()函数生成的线性判判别图像,可以通过对每个训练观测计算- 0.642 x Lag1-0.514 x Lag2 获得。
lda.pred=predict(lda.fit, Smarket.2005) #预测2005年的 names(lda.pred)

lda.class=lda.pred$class table(lda.class,Direction.2005)

mean(lda.class==Direction.2005) #LDA 和逻辑斯谛回归预测结果几乎一样。
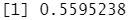
二次判别分析(quadratic discriminant analysis,QDA)
#现在对smarket数据拟告 QDA 模型,QDA 在民中可以调用 MASS 库中的 qda ()函数来实现,其语句与 lda ()一样。
qda.fit=qda(Direction~Lag1+Lag2,data=Smarket,subset=train) qda.fit
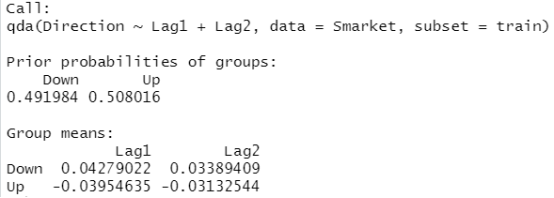
qda.class=predict(qda.fit,Smarket.2005)$class table(qda.class,Direction.2005)
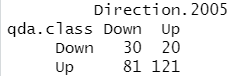
mean(qda.class==Direction.2005)
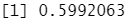
结果分析:即使没有用 2005 年始数据来拟合模型,在几乎 60% 的时间)里, QDA 预测也都是准确的,这表明 QDA假设的二次型比 LDA 和逻辑斯谛回归的线性假设更接近真实的关系。
逻辑回归案例:大篷车保险数据的一个应用
对 ISLR库中的 Caravan (大篷车)数据集运用 KNN 方法。该数据集包括 85 个预测变量,测量了 5822 人的人口特征。响应变最为 Purchase (购买状态) .表示一个人是否会购买大篷车保险险种。在该数据集中,只有 6% 的人购买了大篷车保险。
dim(Caravan)
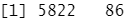
attach(Caravan) summary(Purchase)
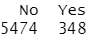
348/5822
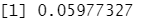
standardized.X=scale(Caravan[,-86]) #标准化数据,第86列为Purchase状态,不适合标准化 var(Caravan[,1])
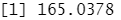
var(Caravan[,2])
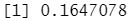
var(standardized.X[,1]) #命令 standardized.X 将每列均值为0,标准差置为 1 。
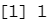
var(standardized.X[,2])
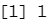
test=1:1000
train.X<-standardized.X[-test,] #训练集
test.X<-standardized.X[test,] #测试集,样本量为1000
train.Y<-Purchase[-test] #训练集标签
test.Y<-Purchase[test] #测试集标签
glm.fits<-glm(Purchase~.,data=Caravan,family=binomial,subset=-test)
glm.probs<-predict(glm.fits,Caravan[test,],type="response")
glm.pred<-rep("No",1000)
glm.pred[glm.probs>.5]="Yes"
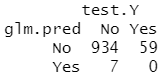
table(glm.pred,test.Y)
glm.pred<-rep("No",1000)
glm.pred[glm.probs>.25]="Yes"
table(glm.pred,test.Y)
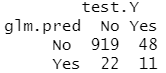
11/(22+11)
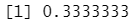
结果分析:作为比较,对数据拟合一个逻辑斯谛回归模型。如果用 0.5 作为分类器的预测概率的阈值,则出现一个问题:只有7个测试观测被预测会购买保险。更糟糕的是,这7个预测都是错误的!现在不要求阈值为0.5。如果预测购买概率超过 0.25 时就预测购买的话,结果会好很多,预测有 33 人将会购买保险,而在这些人中正确预测率为33%;这比随机猜测的五倍还多!
逻辑回归案例:婚外情数据的应用
当通过一系列连续型和/或类别型预测变量来预测二值型结果变量时,Logistic回归是一个非常有用的工具。以AER包中的数据框Affairs为例,我们将通过探究婚外情的数据来阐述Logistic回归的过程。
婚外情数据即著名的“Fair’s Affairs”,取自于1969年《今日心理》(Psychology Today)所做的一个非常有代表性的调查,该数据从601个参与者身上收集了9个变量,包括一年来婚外私通的频率以及参与者性别、年龄、婚龄、是否有小孩、宗教信仰程度(5分制,1分表示反对,5分表示非常信仰)、学历、职业(逆向编号的戈登7种分类),还有对婚姻的自我评分(5分制,1表示非常不幸福,5表示非常幸福)。
install.packages("AER")
data(Affairs, package="AER")
summary(Affairs)
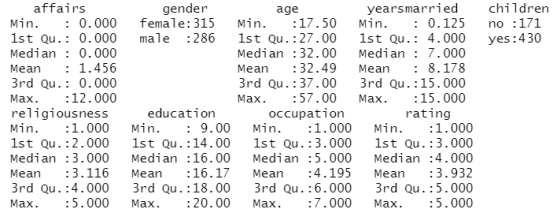
table(Affairs$affairs) #统计婚外情次数的人数
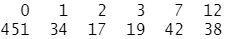
结果分析:从这些统计信息可以看到,315/601=52%的调查对象是女性,430/601=72%的人有孩子,样本年龄的中位数为32岁。对于响应变量,72%的调查对象表示过去一年中没有婚外情(451/601),而婚外偷情的最多次数为12(占了6%)。
虽然这些婚姻的轻率举动次数被记录下来,但此处我们感兴趣的是二值型结果(有过一次婚
外情/没有过婚外情)。按照如下代码,可将affairs转化为二值型因子ynaffair:
Affairs$ynaffair[Affairs$affairs > 0] <- 1 #赋值
Affairs$ynaffair[Affairs$affairs == 0] <- 0
Affairs$ynaffair <- factor(Affairs$ynaffair,
levels=c(0,1), #值的结果是0和1
labels=c("No","Yes")) #给二值型因子贴上标签
table(Affairs$ynaffair)

该二值型因子现可作为Logistic回归的结果变量:
fit.full <- glm(ynaffair ~ gender + age + yearsmarried + children +
religiousness + education + occupation +rating,
data=Affairs, family=binomial()) #family是设置概率分布
summary(fit.full)

结果分析:从回归系数的p值(最后一栏)可以看到,性别、是否有孩子、学历和职业对方程的贡献都不显著(后面没有星星),也就是我们无法拒绝参数为0的假设。去除这些变量重新拟合模型,检验新模型是否拟合得好呢?
fit.reduced <- glm(ynaffair ~ age + yearsmarried + religiousness +
rating, data=Affairs, family=binomial())
summary(fit.reduced)

结果分析:新模型的每个回归系数都非常显著(p<0.05)。由于两模型嵌套(fit.reduced是fit.full的一个子集),你可以使用anova()函数对它们进行比较,对于广义线性回归,可用卡方检验。
anova(fit.reduced, fit.full, test="Chisq")

结果分析:结果的卡方值不显著(p=0.21),表明四个预测变量的新模型与九个完整预测变量的模型拟合程度一样好。这使得你更加坚信添加性别、孩子、学历和职业变量不会显著提高方程的预测精度,因此可以依据更简单的模型进行解释。
解释模型参数:先看看回归系数
coef(fit.reduced)
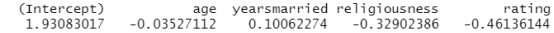
对每个观测值各分解项的值取指数,将结果转化为原始尺度:
exp(coef(fit.reduced))

结果分析:可以看到婚龄增加一年,婚外情的优势比将乘以1.106(保持年龄、宗教信仰和婚姻评定不变);相反,年龄增加一岁,婚外情的的优势比则乘以0.965。因此,随着婚龄的增加和年龄、宗教信仰与婚姻评分的降低,婚外情优势比将上升。
评价预测变量对结果概率的影响
使用predict()函数,可以观察某个预测变量在各个水平时对结果概率的影响。首先创建一个包含你感兴趣预测变量值的虚拟数据集,然后对该数据集使用predict()函数,以预测这些值的结果概率。
现在我们使用该方法评价婚姻评分对婚外情概率的影响。首先,创建一个虚拟数据集,设定年龄、婚龄和宗教信仰为它们的均值,婚姻评分的范围为1~5。
testdata <- data.frame(rating=c(1, 2, 3, 4, 5), age=mean(Affairs$age),
yearsmarried=mean(Affairs$yearsmarried),
religiousness=mean(Affairs$religiousness))
testdata
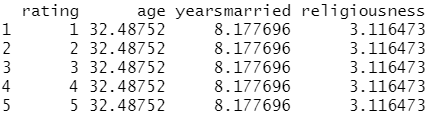
testdata$prob <- predict(fit.reduced, newdata=testdata, type="response") #用测试数据集预测相应的概率
#predict:从拟合的稳健广义线性模型(GLM)对象中获取预测值,并可选择估计这些预测值的标准误差。Newdata:可选地,一个数据框架,在其中寻找用于预测的变量,如果省略,则使用拟合的线性预测器。
testdata
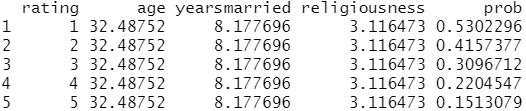
结果分析:从这些结果可以看到,当婚姻评分从1(很不幸福)变为5(非常幸福)时,婚外情概率从0.53降低到了0.15(假定年龄、婚龄和宗教信仰不变)。下面我们再看看年龄的影响:
testdata <- data.frame(rating=mean(Affairs$rating),
age=seq(17, 57, 10), #从17岁到57岁,每隔10岁生成一个
yearsmarried=mean(Affairs$yearsmarried),
religiousness=mean(Affairs$religiousness))
testdata
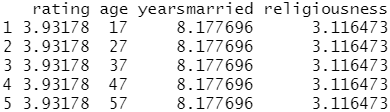
testdata$prob <- predict(fit.reduced, newdata=testdata, type="response") testdata
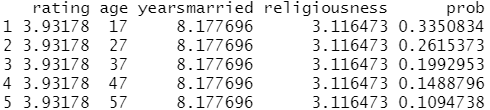
结果分析:此处可以看到,当其他变量不变,年龄从17增加到57时,婚外情的概率将从0.34降低到0.11。
本文来自博客园,作者:zhang-X,转载请注明原文链接:https://www.cnblogs.com/YY-zhang/p/16000379.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号