
袋装法、随机森林、提升法(回归)
袋装法
#装袋法是随机森林在 m=p 时的一种特殊情况。 因此函数 randomForest() 既可以用来做随机森林,也可以执行装袋法。
1 2 3 4 5 | library(randomForest)set.seed(1)dim(Boston) |
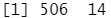
1 2 3 | bag.boston=randomForest(medv~.,data=Boston,subset=train,mtry=13,importance=TRUE) #参数 mtry=13 意味着树上的每一个分裂点都应该考虑全部 13 个预测变量,此时执行装袋法。bag.boston |

1 2 3 4 5 | yhat.bag = predict(bag.boston,newdata=Boston[-train,])plot(yhat.bag, boston.test)abline(0,1) |
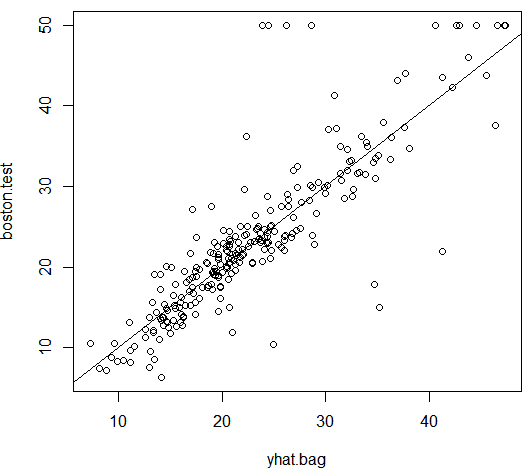
1 | mean((yhat.bag-boston.test)^2) |
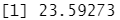
结果分析:装袋法回归树的测试均方误差是 23.59。
1 2 3 4 5 | bag.boston=randomForest(medv~.,data=Boston,subset=train,mtry=13,ntree=25) #用参数ntree 改变由 randomForest ()生成的树的数目yhat.bag = predict(bag.boston,newdata=Boston[-train,])mean((yhat.bag-boston.test)^2) |
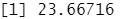
1 | set.seed(1) |
随机森林
#生成随机森林的过程和生成装袋法模型的过程一样,区别只是所取的 mtry 值更小,函数randomForest ()默认在用回归树建立随机森林时取p/3个变量,而用分类树建立随机森林时取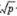 个变量,这里取 mtry=6。
个变量,这里取 mtry=6。
1 2 3 4 5 | rf.boston=randomForest(medv~.,data=Boston,subset=train,mtry=6,importance=TRUE)yhat.rf = predict(rf.boston,newdata=Boston[-train,])mean((yhat.rf-boston.test)^2) |
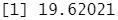
结果分析:测试均方误是19.62,这意味着在这种情况下,随机森林会对装袋法有所提升。
1 | importance(rf.boston) #函数importance ()浏览各变量的重要性。 |
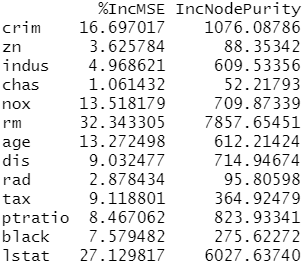
结果分析:上面列出了变量重要性的两个测度,前者基于当一个给定的变量被排除在模型之外时,预测袋外样本的准确性的平均减小值。后者衡量的是由此变量导致的分裂使结点不纯度减小的总量。在回归树中,结点不纯度是由训练集RSS衡量的,而分类树的结点纯度是由偏差衡量的。反映这些变量重要程度的图可自函数 varlmpPlot ()画出。
1 | varImpPlot(rf.boston) |
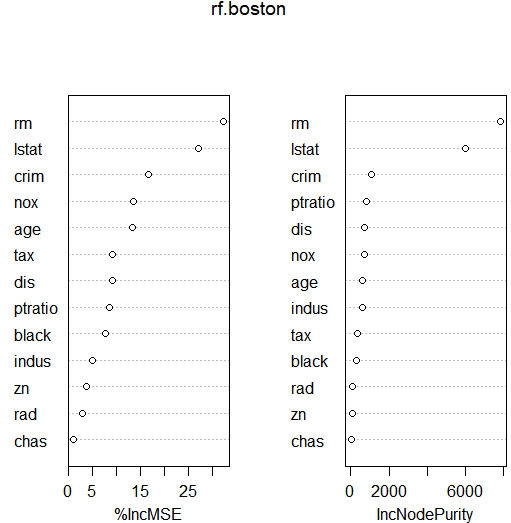
结果分析:结果表明,在随机森林考虑的所有变绕中, lstat 和rm 是目前最重要的两个变量。
提升法
#用gbm包和其中的 gbm() 函数对 Boston 数据集建立回归树
1 2 3 4 5 6 7 | library(gbm)set.seed(1)boost.boston=gbm(medv~.,data=Boston[train,],distribution="gaussian",n.trees=5000,interaction.depth=4) #由于是回归问题,在执行gbm() 时选择 distribution =" gaussian" ;如果是二分类问题,应选择 distribution =" bernoulli" 。对象n. trees = 5000 表示提升法模型共需要5000 棵树,选项interaction.dept=4 限制了每棵树的深度summary(boost.boston) #用函数 summary ()生成一张相对影响图,并输出相对影响统计数据 |

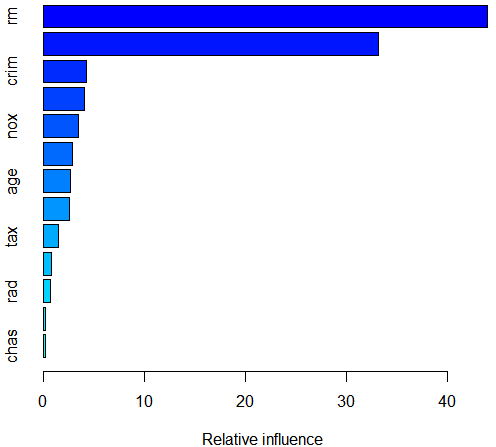
结果分析:可见lstat和 rm 是目前最重要的变量。
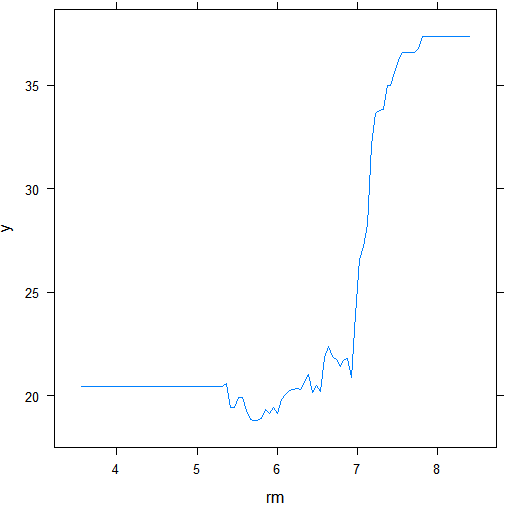
1 2 3 | #par(mfrow=c(1,2))plot(boost.boston,i="rm") #画出rm变量的偏相关图 |
1 | plot(boost.boston,i="lstat") |
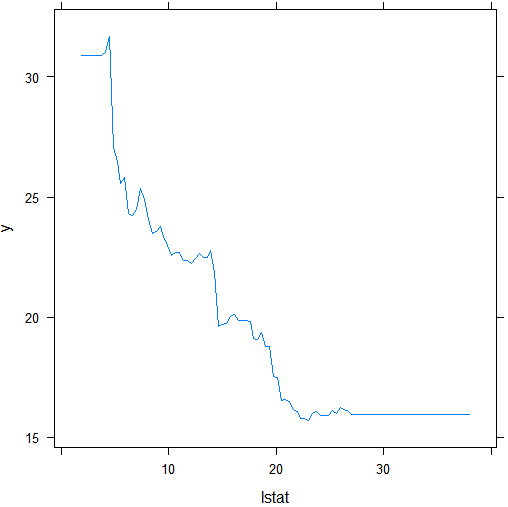
结果分析:这是两个变量rm和lstat的偏相关图 ( partial dependence plot) ,这些图反映的是排除其他变量后,所选变量对响应值的边际影响。在这个例子中,住宅价格中位数(响应值)随rm的增大而增大,随后lstat的增大而减小。
1 2 3 | yhat.boost=predict(boost.boston,newdata=Boston[-train,],n.trees=5000) #用提升法模型在测试集上预测 medv。mean((yhat.boost-boston.test)^2) |
结果分析:测试均方误差是18.85,这个结果与随机森林类似,比装袋法略好。
1 2 3 4 5 | boost.boston=gbm(medv~.,data=Boston[train,],distribution="gaussian",n.trees=5000,interaction.depth=4,shrinkage=0.2,verbose=F) #取不同的压缩参数做提升法yhat.boost=predict(boost.boston,newdata=Boston[-train,],n.trees=5000)mean((yhat.boost-boston.test)^2) |
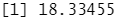
结果分析:此时得到的均方误差略低。
本文来自博客园,作者:zhang-X,转载请注明原文链接:https://www.cnblogs.com/YY-zhang/p/16000276.html


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· 从HTTP原因短语缺失研究HTTP/2和HTTP/3的设计差异
· 三行代码完成国际化适配,妙~啊~