模型子集选择方法(最优子集选择、向前逐步选择、向后逐步选择、验证集方法、交叉验证法)
子集选择方法:最优子集选择
#Hitters (棒球)数据集实践最优于集选择方法 library(ISLR) fix(Hitters) names(Hitters)

dim(Hitters)
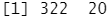
sum(is.na(Hitters$Salary))
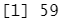
Hitters<-na.omit(Hitters) #删除缺失值 dim(Hitters)
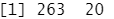
sum(is.na(Hitters)) #检验是否含有缺失值
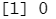
library(leaps)
#R语言中的 regsubset ()函数(于leaps库)通过建立一系列包含给定数目预测变量的最优模型,来实现最优预测变量子集的筛选,其中“最优”这一概念使用RSS来量化。
regfit.full=regsubsets(Salary~.,Hitters) summary(regfit.full)
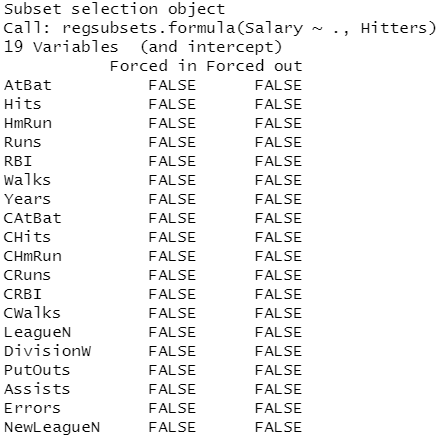
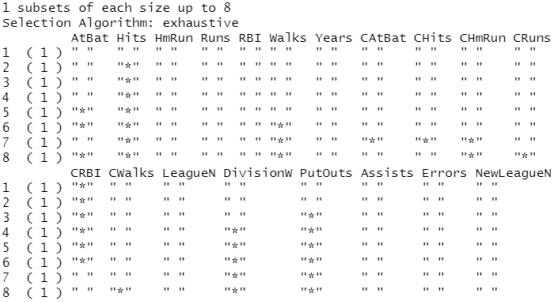
结果分析:星号*表示列对应的变量包含于行对应的模型当中。例如,以上输出结果表示最优的两变量模型仅包含 Hits (前一年究成的安打次数)和 CRBI (职业生涯总跑垒次数)两个变量。
regfit.full<-regsubsets(Salary~.,data=Hitters,nvmax=19) #默认果只给出截至最优八变量模型的八种变量筛选结果,nvmax 选项可以设置用户所需的预测变量个数,这里设置为19。 reg.summary<-summary(regfit.full) names(reg.summary)
reg.summary$rsq

#par(mfrow=c(2,2)) #画布分成4个区域,第一行有两个区域,第二行也是二个区域
#画出所有模型的 RSS 、调整 R2 ,及Cp 、BIC 的图像可以辅助确定最终选择哪一个模型
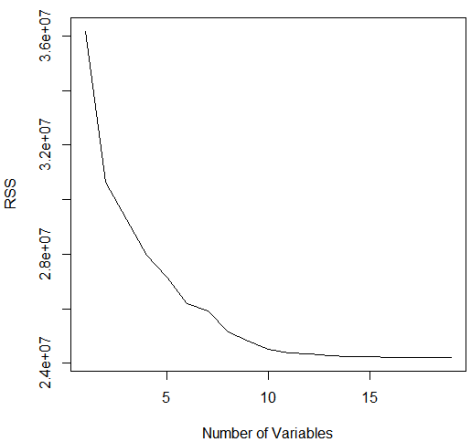
plot(reg.summary$rss,xlab="Number of Variables",ylab="RSS",type="l") #RSS
plot(reg.summary$adjr2,xlab="Number of Variables",ylab="Adjusted RSq",type="l") #R2
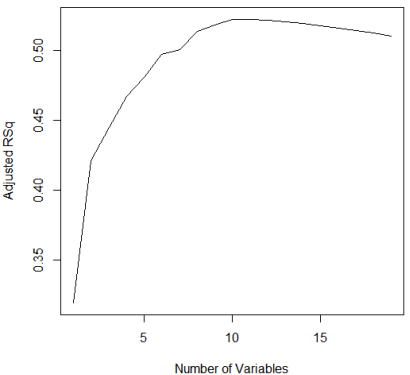
which.max(reg.summary$adjr2) #which. max ()函数可以用于识别一个向量中最大值所对应点的位置
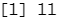
points(11,reg.summary$adjr2[11], col="red",cex=2,pch=20)#points ()用于将点加在已有图像上
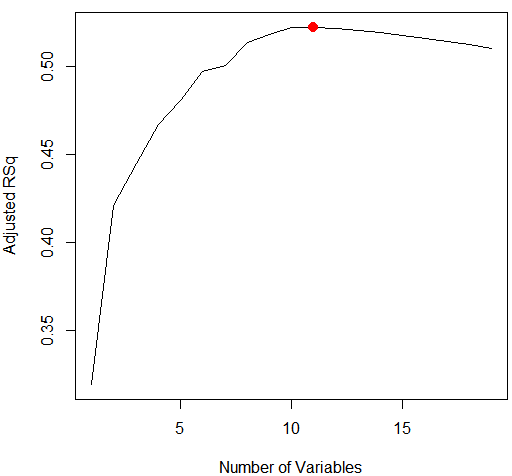
plot(reg.summary$cp,xlab="Number of Variables",ylab="Cp",type='l') #Cp
which.min(reg.summary$cp) #which min() 函数标示出统计指标最小的模型。
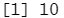
points(10,reg.summary$cp[10],col="red",cex=2,pch=20) #points ()用于将点加在已有图像上
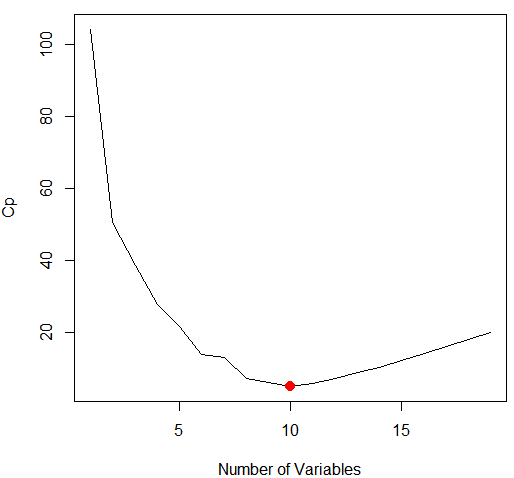
which.min(reg.summary$bic) #which min() 函数标示出统计指标BIC最小的模型。
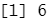
plot(reg.summary$bic,xlab="Number of Variables",ylab="BIC",type='l') #BIC
points(6,reg.summary$bic[6],col="red",cex=2,pch=20) #points ()用于将点加在已有图像上
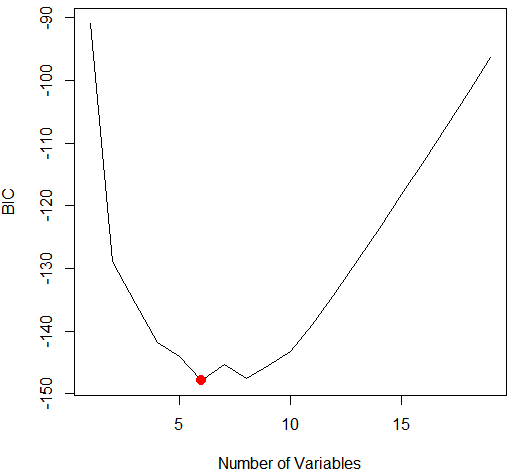
plot(regfit.full,scale="r2")
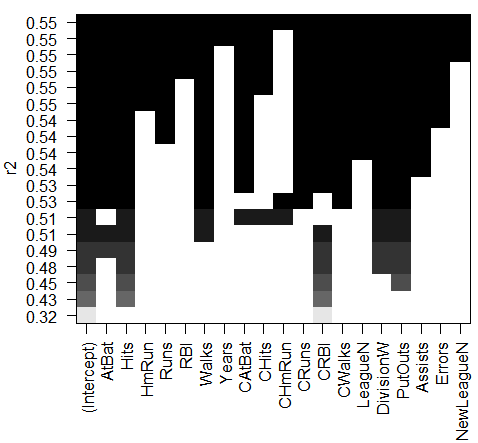
plot(regfit.full,scale="adjr2")
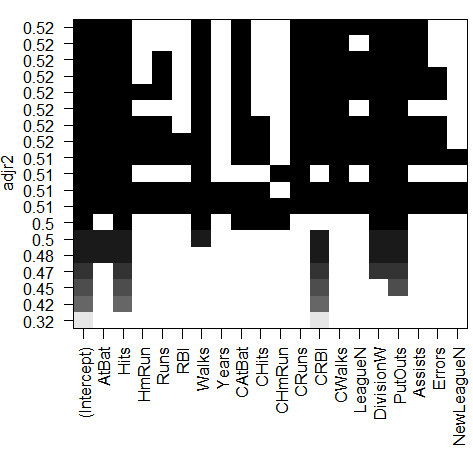
plot(regfit.full,scale="Cp")
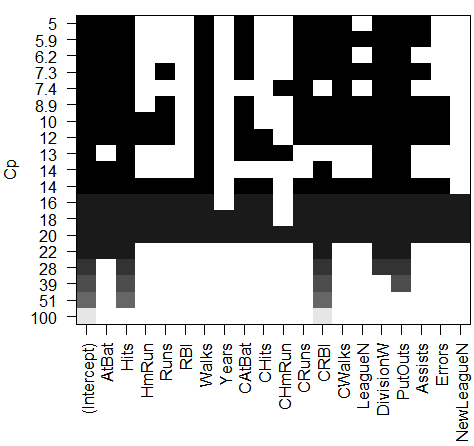
plot(regfit.full,scale="bic")
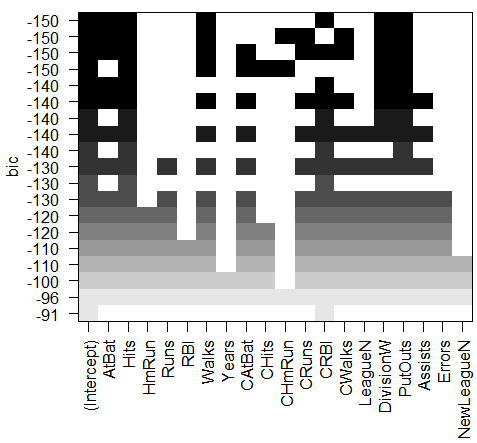
结果分析:每个图像第一行的黑色方块表示根据相应统计指标选择的最优模型所包含的变量。例如,多个模型的BIC都接近与-150。而BIC 指标最小的模型为包含变量AtBat (前一年的打数)、 Hits (前一年完成的安打次数)、 Walks (前一年的保送次数)、 CRBI (职业生涯单跑线次数)、 Division (年来翻联赛级别)和 PutOuts (前一年的接杀次数)的六变量模型。
coef(regfit.full,6) #coef ()函数可以提取该模型的参数估计值。

子集选择:向前逐步选择
#向前逐步选择和向后逐步选择可以分别通过设定 regsubsets 函数中的参数 method =" forward" 和method =" backward" 来实现。
regfit.fwd=regsubsets(Salary~.,data=Hitters,nvmax=19,method="forward") summary(regfit.fwd)
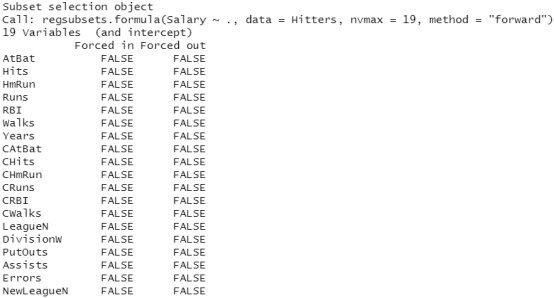
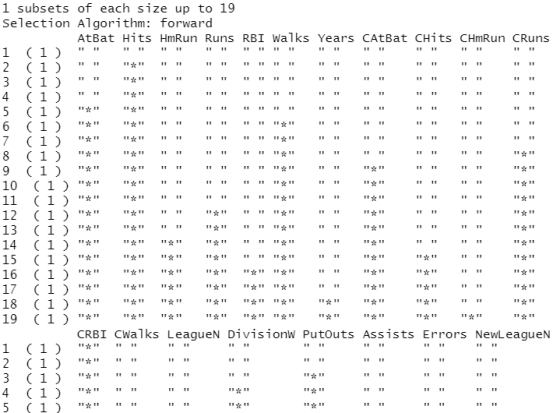
结果分析:使用向前逐步选择筛选变量时,最优的单变量模型只包含预测变量 CRBI ,最优的两变量模型在此基础上引人了预测变盘Hits。
子集选择:向后逐步选择
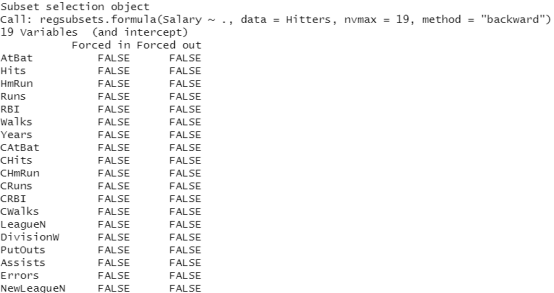
regfit.bwd=regsubsets(Salary~.,data=Hitters,nvmax=19,method="backward") summary(regfit.bwd)
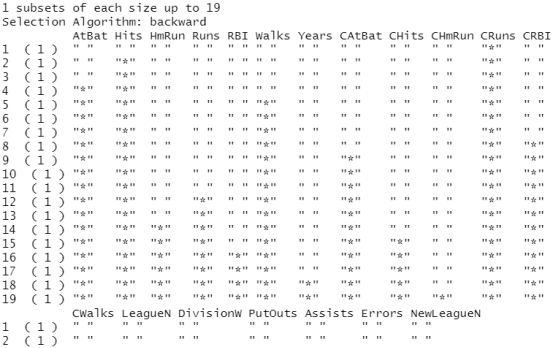
coef(regfit.full,7) #最优子集选择

coef(regfit.fwd,7) #向前逐步选择

coef(regfit.bwd,7) #向后逐步选择

结果分析:对于这个数据集,使用最优子集选择方法和向前逐步选择所得的单变量模型到六变盘模型的结果是完全一致的。但是,使用向前逐步选择、向后逐步选择和最优子集选择所得的最优七变量模型是不同的。
模型选择:验证集方法
# 验证集方法选择模型,需要划分训练集和测试集
set.seed(1)
Train<-sample(c(TRUE,FALSE), nrow(Hitters),rep=TRUE)
Test<-(!train)
regfit.best<-regsubsets(Salary~.,data=Hitters[train,],nvmax=19)
test.mat<-model.matrix(Salary~.,data=Hitters[test,])
val.errors<-rep(NA,19)
for(i in 1:19){
Coefi<-coef(regfit.best,id=i)
Pred<-test.mat[,names(coefi)]%*%coefi
val.errors[i]<-mean((Hitters$Salary[test]-pred)^2)
}
val.errors

which.min(val.errors) #通过验证集方法,可以得出最优的模型含有7个预测变量
coef(regfit.best,7)

#编写预测函数
predict.regsubsets=function(object,newdata,id,...){
form=as.formula(object$call[[2]])
mat=model.matrix(form,newdata)
coefi=coef(object,id=id)
xvars=names(coefi)
mat[,xvars]%*%coefi
}
regfit.best=regsubsets(Salary~.,data=Hitters,nvmax=19) #对整个数据集使用最优子集选择,选出最优的七变量模型
coef(regfit.best,7)

模型选择:交叉验证法
k=10 set.seed(1) folds=sample(1:k,nrow(Hitters),replace=TRUE) ##定义一个向量将数据集中每个观测归为k= 10 折中的某一折,从1到k中随机筹集有放回的抽取nrow(Hitters)个样本 length(folds)
folds
cv.errors=matrix(NA,k,19, dimnames=list(NULL, paste(1:19))) #定义一个存储计算结果的矩阵,k行19列。 cv.errors

#通过一个循环语句实现了交叉验证。在第j 折中,数据集中对应 folds向量中等于j 的元素归于测试集,其他元素归于训练集中
for(j in 1:k){
best.fit=regsubsets(Salary~.,data=Hitters[folds!=j,],nvmax=19)
for(i in 1:19){
pred=predict(best.fit,Hitters[folds==j,],id=i)
cv.errors[j,i]=mean( (Hitters$Salary[folds==j]-pred)^2)
}
}
mean.cv.errors=apply(cv.errors,2,mean) #使用apply ()函数求该矩阵的列平均(1表示对行,2表示1对列),从而得到一个向量,该列向量的第j个元素表示j变量模型的交叉验证误差。
mean.cv.errors

par(mfrow=c(1,1)) plot(mean.cv.errors,type='b')
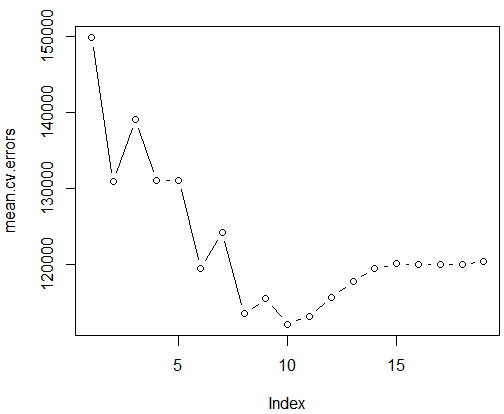
结果分析:从上图可知,交叉验证选择了十变最模型。
reg.best=regsubsets(Salary~.,data=Hitters, nvmax=19) #对整个数据集使用最优子集选择,以获得该十变最模型的参数估计结果。 coef(reg.best,10)

本文来自博客园,作者:zhang-X,转载请注明原文链接:https://www.cnblogs.com/YY-zhang/p/15999824.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号