

tibble包实现简单数据框(tibble、data.frame)
使用tibble实现简单数据框
1.1 创建tibble
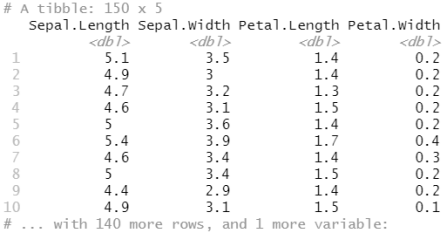
as_tibble(iris)
可以通过 tibble() 函数使用一个向量来创建新 tibble。tibble() 会自动重复长度为 1 的输入,并可以使用刚刚创建的新变量,如下所示:
tibble( x = 1:5, y = 1, z = x ^ 2 + y )
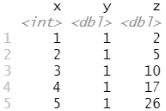
tibble() 函数的功能要少得多:它不能改变输入的类型(例如,不能将字符串转换为因子)、变量的名称,也不能创建行名称。
可以在 tibble 中使用在 R 中无效的变量名称(即不符合语法的名称)作为列名称。例如,
列名称可以不以字母开头,也可以包含特殊字符(如空格)。要想引用这样的变量,需要使用反引号 ` 将它们括起来:
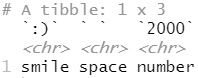
tb <- tibble( `:)` = "smile", ` ` = "space", `2000` = "number" ) tb
tribble 是 transposed tibble(转置 tibble)的缩写。tribble() 是定制化的,可以对数据按行进行编码:列标题由公式(以 ~ 开头)定义,数据条目以逗号分隔,这样就可以用易读的方式对少量数据进行布局:
tribble( ~x, ~y, ~z, #--|--|---- "a", 2, 3.6, "b", 1, 8.5 )
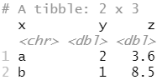
1.2 创建数据框data.frame
数据框是一种表格式的数据结构,数据框旨在模拟数据集,与其他统计软件例如SAS和SPSS中的数据集一致.
数据集通常由数据构成一个举行数组,行表示观测,列表示变量,不同的行业对于数据集的行和列叫法不同.
数据框实际上是一个列表,列表中的元素是向量,这些向量构成数据框的列,每一个列必须具有相同的长度,所以数据框是矩形结构,而且数据框的列必须命名.
矩阵与数据框
数据框形状上很像矩阵
数据框是比较规则的列表
矩阵必须为同一个数据类型
数据框每一列必须同一类型,每一行可以不同
iris数据集是一个数据框,其他还有mtcars,rock等
数据框可以通过data.frame()函数创建,类似于excle中的表格
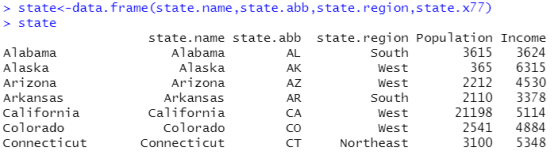
数据框的索引,state[1]输出第一列,state[c(2,4)]输出第2列和第4列,state[-c(2,4)]删除第2列和第4列
通过名字索引,通过这个符号$索引

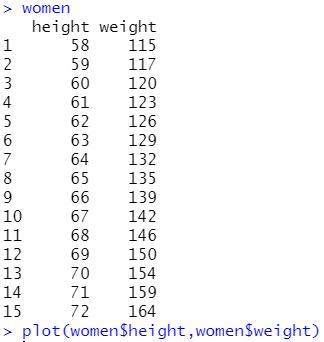
women数据集里面有身高体重
plot()函数可以显示散点图

利用lm()函数进行线性回归,直接给出列名即可
lm(weight ~height,data=women) 与下面的一句话作用一样

attach()加载数据框,之后只需要输入列名就可以显示数据了

rownames(mtcars)显示数据集mtcars的行名,colnames(mtcars)显示数据集mtcars的列名,并通过行名、列名查询显示

detach(mtcars)函数可以去除此数据框

with()函数加载数据框并显示,不需要这个符号$

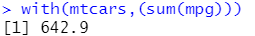
1.2.1数据框操作--基本数据管理
R基本数据管理--创建变量,变量重编码和重命名
数据框增加列,可以使用符号$

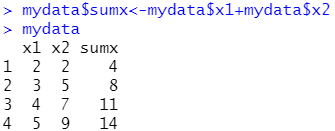
自定义数据框
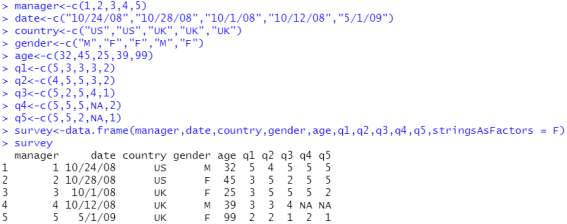
赋值操作,变量的重编码

赋值并判断,也就是变量的重编码,主要使用中括号[]
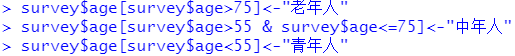
重命名

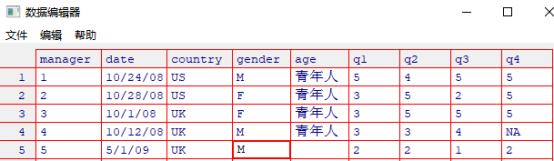

通过索引重命名
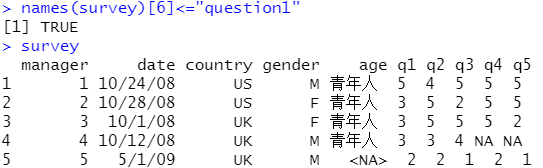
2对比tibble与data.frame
tibble 和传统 data.frame 的使用方法主要有两处不同:打印和取子集。
2.1 打印
tibble 的打印方法进行了优化,只显示前 10 行结果,并且列也是适合屏幕的,这种方式非
常适合大数据集。除了打印列名,tibble 还会打印出列的类型,这项非常棒的功能借鉴于str() 函数。
tibble( a = lubridate::now() + runif(1e3) * 86400, b = lubridate::today() + runif(1e3) * 30, c = 1:1e3, d = runif(1e3), e = sample(letters, 1e3, replace = TRUE) )
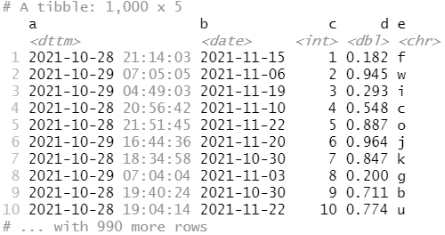
可以明确使用 print() 函数来打印数据框,并控制打印的行数(n)和显示的宽度(width)。width = Inf 可以显示出所有列:
nycflights13::flights %>%
print(n = 10, width = Inf)
还可以通过设置以下选项来控制默认的打印方式。
options(tibble.print_max = n, tibble.pring_min = m):如果多于 m 行,则只打印出 n行。options(tibble.print_min = Inf) 表示总是打印所有行。
options(tibble.width = Inf) 表示总是打印所有列,不考虑屏幕的宽度。
2.2 取子集
如 $ 和 [[。[[ 可以按名称或位置提取变量;$ 只能按名称提取变量,但可以减少一些输入:
df <- tibble( x = runif(5), y = rnorm(5) ) # 按名称提取 df$x df[["x"]]

# 按位置提取
df[[1]]

在管道中使用这些提取操作,需要使用特殊的占位符 . :
df %>% .$x df %>% .[["x"]]

本文来自博客园,作者:zhang-X,转载请注明原文链接:https://www.cnblogs.com/YY-zhang/p/15577311.html
