
关联分析--概述(项集、关联规则、支持度、置信度、提升度)
关联分析
概述
关联分析是数据挖掘的核心技术之一,其关联规则模型及数据挖掘算法是由 IBM 公司Almaden研究中心的R.Agrawal在1993年首先提出的,目的是从大量数据中发现项集之间的有趣关联或相互关系,其中最经典的Apriori算法在关联规则分析领域具有很大的影响力。
1.项集(ltemset)
这是一个集合的概念,在一篮子商品中一件消费品即为一项(Item),则若干项的集合称为项集,如{啤酒,尿布}即构成一个二元项集。
2. 关联规则(Association Rule)
一般记为X→Y的形式,称关联规则左侧的项集X为先决条件,右侧项集Y为相应的关联结果,用于表示出数据内隐含的关联性。如:关联规则尿布→啤酒成立则表示购买了尿布的消费者往往也会购买啤酒这一商品,即这两个购买行为之间具有一定关联性。
至于关联性的强度如何,则由关联分析中的三个核心概念——支持度、置信度和提升度来控制和评价。
假设有10000个消费者购买了商品,其中购买尿布的有1000个,购买啤酒的有2000个,购买面包的有500个,且同时购买尿布与啤酒的有800个,同时购买尿布与面包的有100个。
3.支持度(Support)
支持度是指在所有项集中{X,Y}出现的可能性,即项集中同时含有X和Y的概率

该指标作为建立强关联规则的第一个门槛,衡量了所考察关联规则在“量”上的多少。其意义在于通过最小阈值(minsup, Minimum Support)的设定,来剔除那些“出镜率”较低的无意义规则,而相应地保留下出现较为频繁的项集所隐含的规则。上述过程用公式表示,即是筛选出满足:

的项集Z,被称为频繁项集(Frequent Itemset)。
在上述的具体数据中,当我们设定最小阈值为5%,由于{尿布,啤酒}的支持度为800/10000=8%,而{尿布,面包}的支持度为100/10000=1%,则{尿布,啤酒}由于满足了基本的数量要求,成为频繁项集,且规则尿布→啤酒、啤酒→尿布同时被保留,而{尿布,面包}所对应的两条规则都被排除。
4.置信度(Confidence)
置信度表示在关联规则的先决条件X发生的条件下,关联结果Y发生的概率,即含有X的项集中,同时含有Y的可能性;
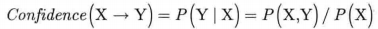
这是生成强关联规则的第二个门槛,我们需要对置信度设定最小阈值(mincon, Minimum Confidence)来实现进一步筛选,从而最终生成满足需要的强关联规则。因此,继筛选出频繁项集后,需从中进而选取满足:

的规则,至此完成所需关联规则的生成。
具体的,当设定置信度的最小阈值为70%时,尿布→啤酒的置信度为800/1000=80%,而规则啤酒→尿布的置信度则为800/2000=40%,被剔除。至此,我们根据需要筛选出了一条强关联规则——尿布→啤酒。
5.提升度(lift)
提升度表示在含有X的条件下同时含有Y的可能性与没有这个条件下项集中含有Y的可能性之比,即在Y自身出现可能性P(Y)的基础上,X的出现对于Y的“出镜率”P(YIX)的提升程度:
该指标与置信度同样用于衡量规则的可靠性,可以看作是置信度的一种互补指标。
举例来说,我们考虑1000个消费者,发现有500人购买了茶叶,其中有450人同时购买了咖啡,另50人没有,由于规则茶叶→咖啡的置信度高达450/500=90%,由此我们可能会认为喜欢喝茶的人往往喜欢喝咖啡。但当我们来看另外没有购买茶叶的500人,其中同样有450人也买了咖啡,且同样是很高的置信度90%,由此,我们看到不喝茶的人也爱喝咖啡。这样来看,其实是否购买咖啡,与有没有购买茶叶并没有关联,两者是相互独立的,其提升度为90%/(450+450)y/1000=1。
由此可见,提升度正是弥补了置信度的这一缺陷,当lift值为1时表示X与Y相互独立,X对Y出现的可能性没有提升作用,而其值越大(>1)则表明X对Y的提升程度越大,也即表明关联性越强。
通过以上概念,我们可总结出关联分析的基本算法步骤。(1)选出满足支持度最小阈值的所有项集,即频繁项集。
一般来说,由于所研究的数据集往往是海量的,我们想要考察的规则不可能占有其中的绝大部分。就像如果想要考察买了啤酒的消费者还会购买哪些商品时,当我们把阈值设为50%,就基本已经剔除了所有含有“啤酒”的项,因为不可能去超市的消费者一半都买了啤酒。因此,该阈值一般设定为5%~10%就足够了。
(2)从频繁项集中找出满足最小置信度的所有规则。
而置信度的阈值往往设定得较高,如70%~90%,因为这是我们剔除无意义的项集,获取强联规则的重要步骤。当然,这也是依情况而定的,如果想要获取大量关联规则,该阈值则可以为较低的值。
本文来自博客园,作者:zhang-X,转载请注明原文链接:https://www.cnblogs.com/YY-zhang/p/15244184.html
