
数据预处理--缺失值判断和处理(删除法、插补法(均值插补、热平台插补))
数据预处理
1 数据集加载
这里使用mice软件包下的nhanes2数据集进行演示,这是一个含有缺失值的小规模数据集。
1 2 3 4 5 6 7 8 9 10 11 12 13 | library(lattice)library(MASS)library(nnet)library(mice)data("nhanes2")dim(nhanes2) #获取数据集的维度 25*4summary(nhanes2) |

结果分析:age和hyp是定性变量,分别为3类和2类,bmi和chl是定量变量;age没有缺失值,bmi有9个缺失值,hyp有8个缺失值,chi有10个缺失值。
对数据集nhanes2做一个初步了解:
age:年龄段,取值为1、2、3,分别代表20-39、40-59、60-99这三个年龄段
bmi:身体质量指数,单位为kg/m2
hyp:是否患高血压,1代表否,2代表是
chl:血清胆固醇总量,单位为mg/dL
2 数据清理
对于探索性数据,我们通常使用统计图来探索数据规律,经常用直方图hist,点图dotchart,箱线图boxplot和Q-Q图qqnorm(可以加上线qqline())。
2.1 缺失值处理
在数据预处理中,可以使用函数is.an()判断缺失值:
1 | sum(is.na(nhanes2)) |
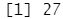
还有一个常用的函数complete.cases,用来判断某一观测样本是否完整:
1 | sum(complete.cases(nhanes2)) |
函数的结果显示:数据中共有27个缺失值,数据框中共有13条完整观测值。
存在缺失值数据的情况下,需要进一步对数据缺失状况进行观测,判断缺失数据是否随机,可以利用mice包中的md.pattern函数判断:
1 | md.pattern(nhanes2) |
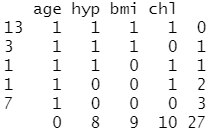
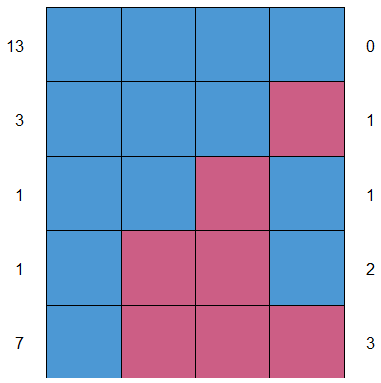
洁后果分析:1表示没有缺失数据,0表示存在缺失数据,第1行第1列的13表示有13个样本是完整的,第1列最后一个7表示有7个样本少了hyp,bmi,chl三个变量,最后一行表示各个变量缺失的样本数合计。
对缺失数据最简单处理的方法是直接删除含有缺失值的样本,这样做到的前提是缺失数据的比例较少,且缺失数据是随机出现的,这样删除之后对分析结果影响不大。
也可以用变量均值或者中位数来代替缺失值的方式,这样做的缺点在于当缺失数据不是随机出现时会产生偏误。
多重插补法通过变量间的关系对数据进行预测,利用蒙特卡洛方法生成多个完整的数据集,再对这些数据集分别进行分析。
在R中可以调用mice包中的mice函数实现,函数的基本形式是:
1 | mice(data,m=5,...) |
其中,data代表一个有缺失值的数据框或者矩阵,缺失值用NA表示;m表示多插补重数,即生成m个完整数据集,默认为5。
举个例子,若要构建以chl为因变量,age,hyp,bmi为自变量的线性回归模型,因为数据集中存在缺失值,不能直接用来构建模型,因此可以通过如下方式构建模型:
1 | imp<-mice(nhanes2,m=4) #生成4组完整的数据库并赋给imp |

1 2 3 4 5 | fit<-with(imp,lm(chl~age+hyp+bmi)) #生成线性回归模型pooled<-pool(fit) #对建立的4个模型汇总summary(pooled) |


以上是对缺失值的判断,下面是缺失值的处理方法:
1.删除法
在不影响数据结构的情况下,根据数据处理的不同角度,可以将删除法分为以下4种:
(1)删除观测样本
(2)删除某变量
(3)使用原始完整数据分析
(4)改变权重:通过对完整数据按照不同的权重进行加权,可以降低删除缺失数据带来的偏差。
2. 插补法
均值插补、回归插补、二阶插补、热平台、冷平台、抽样填补等单一变量插补,多变量插补是单变量插补的推广。
均值插补:是通过计算缺失值所在变量所有非缺失观测值的据那只,使用均值来代替缺失值的插补方法(类似的也可以使用中位数、四分位数进行插补)。
1 2 3 4 5 6 7 8 9 | sub<-which(is.na(nhanes2[,4])==T) #返回数据集第4列为NA的行dataTR<-nhanes2[-sub,] #将4列不为NA的数存入数据集dataTR中dataTE<-nhanes2[sub,] #将第4列为NA的数存入数据集dataTE中dataTE[,4]<-mean(dataTR[,4]) #用非缺失值的均值代替缺失值dataTE |
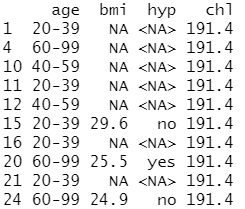
结果分析:均值插补的结果是191.4
随机插补和均值插补没有利用到相关变量信息,因此会存在一定的误差,而回归模型将需要插补的变量作为因变量,其他相关变量作为自变量,用过建立回归模型预测出因变量的值对缺失变量进行插补。
1 2 3 4 5 6 7 | sub<-which(is.na(nhanes2[,4])==T)dataTR<-nhanes2[-sub,]dataTE<-nhanes2[sub,]dataTE |

1 2 3 4 5 | lm<-lm(chl~age,data=dataTR) #构建回归模型nhanes2[sub,4]=round(predict(lm,dataTE)) #利用dataTE中数据按照模型lm对数据集中chl中的缺失数据进行预测head(nhanes2) #显示缺失值处理后的结果 |

热平台插补:是指在非缺失数据集中找到一个于缺失值所在样本相似的样本,利用其中的观测值对缺失值进行插补。
1 2 3 4 5 | accept<-nhanes2[which(apply(is.na(nhanes2),1,sum)!=0),] #存在缺失值的样本donate<-nhanes2[which(apply(is.na(nhanes2),1,sum)==0),] #无缺失值的样本accept[1,] |

1 | donate[1,] |

对于存在缺失值的accept中的每个样本呢,热平台插补就是在donate中找到于该样本相似的样本,用相似样本的对应值代替该样本的缺失值。当变量数量很多时,很难找到于需要插补相似的样本,此时可以按照某些变量将数据分层,在层中对缺失值使用均值插补,即采用冷平台插补方法。
本文来自博客园,作者:zhang-X,转载请注明原文链接:https://www.cnblogs.com/YY-zhang/p/15243469.html


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· 从HTTP原因短语缺失研究HTTP/2和HTTP/3的设计差异
· 三行代码完成国际化适配,妙~啊~