
高级编程--编写有效的代码(有效的数据输入、矢量化、并行化)
高级编程--编写有效的代码
在程序员中间流传着一句话:“优秀的程序员是花一个小时来调试代码而使得它的运算速度提高一秒的人。”R是一种鲜活的语言,大多数用户不用担心写不出高效的代码。作为一般规则,让代码易于理解、易于维护比优化它的速度更重要。但是当你使用大型数据集或处理高度重复的任务时,速度就成为一个问题了。
几种编码技术可以使你的程序更高效:
q 程序只读取需要的数据。
q 尽可能使用矢量化替代循环。
q 创建大小正确的对象,而不是反复调整。
q 使用并行来处理重复、独立的任务。
1. 有效的数据输入
使用read.table()函数从含有分隔符的文本文件中读取数据的时候,你可以通过指定所需的变量和它们的类型实现显著的速度提升。这可以通过包含colClasses参数的函数来实现。例如,假设你想在用逗号分隔的、每行10个变量的文件中获得3个数值变量和2个字符变量。数值变量的位置是1、2和5,字符变量的位置是3和7。在这种情况下,代码:
my.data.frame <- read.table(mytextfile, header=TRUE, sep=',',
colClasses=c("numeric", "numeric", "character",
NULL, "numeric", NULL, "character", NULL,
NULL, NULL))
将比下面的代码运行得更快:
my.data.frame <- read.table(mytextfile, header=TRUE, sep=',')
2. 矢量化
在有可能的情况下尽量使用矢量化,而不是循环。这里的矢量化意味着使用R中的函数,这些函数旨在以高度优化的方法处理向量。初始安装时自带的函数包括 ifelse()、colsums()、rowSums()和rowMeans()。matrixStats包提供了很多进行其他计算的优化函数,包括计数、求和、乘积、集中趋势和分散性、分位数、等级和分级的措施。plyr、dplyr、reshape2和
data.table等包也提供了高度优化的函数。
考虑一个1 000 000行10列的矩阵。让我们使用循环并且再次使用colSums()函数来计算列的和。首先,创建矩阵:
set.seed(1234) mymatrix <- matrix(rnorm(10000000), ncol=10)
然后,创建一个accum()函数来使用for循环获得列的和:
accum <- function(x){
sums <- numeric(ncol(x))
for (i in 1:ncol(x)){
for(j in 1:nrow(x)){
sums[i] <- sums[i] + x[j,i]
}
}
}
system.time()函数可以用于确定CPU的数量和运行该函数所需的真实时间:
system.time(accum(mymatrix))

使用colSums()函数计算和的时间:
system.time(colSums(mymatrix))
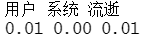
结果分析:很明显,矢量化的运行速度更快
3. 并行化
并行化包括分配一个任务,在两个或多个核同时运行组块,并把结果合在一起。这些内核可能是在同一台计算机上,也可能是在一个集群中不同的机器上。需要重复独立执行数字密集型函数的任务很可能从并行化中受益。这包括许多蒙特卡罗方法(Monte Carlo method),如自助法(bootstrapping)。
R中的许多包支持并行化,参见Dirk Eddelbuettel的“CRAN Task View: High-Performance and Parallel Computing with R”(http://mng.bz/65sT)。在本节中,你可以使用foreach和doParallel
包在单机上并行化运行。foreach包支持 foreach循环构建(遍历集合中的元素)同时便于并行执行循环。doParallel包为foreach包提供了一个平行的后端。
(1)foreach和doParallel包的并行化
#(1)加载包并登记内核数量
install.packages("foreach")
library(foreach)
install.packages("doParallel")
library(doParallel)
library(iterators)
library(parallel)
registerDoParallel(cores=4)
#(2)定义函数,在这里分析100 000×100的随机数据矩阵。使用foreach和%do%执行eig()函数500次
eig <- function(n, p){
x <- matrix(rnorm(100000), ncol=100)
r <- cor(x)
eigen(r)$values
}
n <- 1000000
p <- 100
k <- 500
#(3)正常执行
system.time( x <- foreach(i=1:k, .combine=rbind) %do% eig(n, p) )

#(4)并行执行,system.time( %do%操作符按顺序运行函数,.combine=rbind操作符追加对象x作为行。最后,函数使用%dopar%操作符进行并行运算
x <- foreach(i=1:k, .combine=rbind) %dopar% eig(n, p))

本文来自博客园,作者:zhang-X,转载请注明原文链接:https://www.cnblogs.com/YY-zhang/p/15154260.html
