
基本统计分析(基本统计方法、频数表、列联表、独立性检验、相关性计算)
1 基本统计分析
1.1 描述性统计分析
myvar<-c("mpg","hp","wt")
head(mtcars[myvar]) #显示数据框的头部信息
dat<-mtcars[myvar] #查看数据框
1.1.1 方法
(1)简单分析:summary()

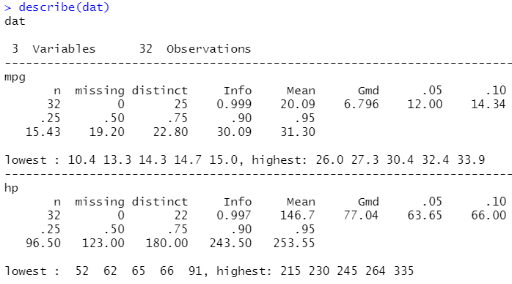
结果分析:计算了最值、分位数、均值等
(2)自定义函数FUN sapply(dat,FUN)
mysta<-function(x,na.omit=F){
if(na.omit)
x<-x[!is.na(x)] #缺失值删除
m<-mean(x)
n<-length(x)
s<-sd(x) #标准差
skew<-sum((x-m)^3/s^3)/n #偏度
kurt<-sum((x-m)^4/s^4)/n-3 #风度
return(c(n=n,mean=m,stdev=s,skew=skew,kurtosis=kurt))
}
sapply(dat, mys)

1.1.2 方法
(1)调用包:Hmisc
library(Hmisc) describe(dat)
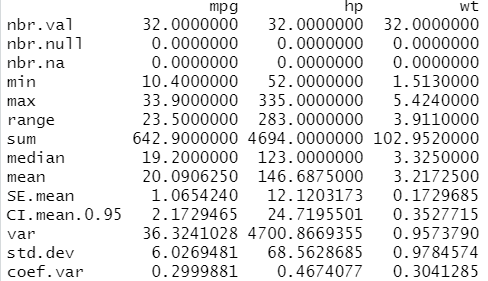
(2) 调用包:pastecs
library(pastecs) stat.desc(dat)
1.1.3 分租计算描述性统计量
(1)每次只能返回一个统计量 aggregate()
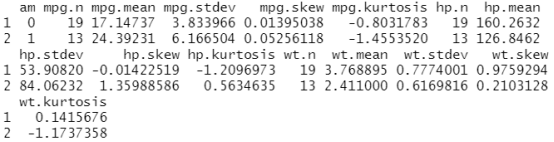
aggregate(dat,by=list(am=mtcars$am),mean) #aggregate()分组函数,dat分组对象,by=list(am=mtcars$am)根据什么分租,mean分组做什么事情

(2)返回多个统计量 by()
dsta<-function(x)sapply(x,mysta) #定义函数dsta,直接引用sapply(x,mysta) by(dat,mtcars$am,dsta)

1.1.4 分组计算的扩展
library("doBy")
summaryBy(mpg+hp+wt~am,data=mtcars,FUN=mysta ) # ~前面mpg+hp+wt是要显示的变量,~后面是根据am进行分组,data指明数据集,FUN指明用到的函数
1.2 频数表和列联表
1.2.1 生成频数表
(1)一维频数表
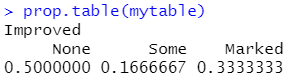
mytable<-with(Arthritis,table(Improved)) #把变量中的每一个取值列出来统计和,with第一个参数Arthritis是确定数据框(数据集),table()统计频率

返回百分比:prop.table(mytable)
(2)二维频数表 xtabs()
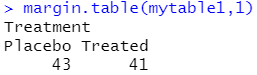
mytable1<-xtabs(~Treatment+Improved,data=Arthritis) #生成列联表

(3)边际操作:1代表对行操作,2代表对列操作
margin.table(mytable1,1) #统计每行的和
prop.table(mytable1,1) #计算每行的百分比

1.2.2 独立性检验(检验数据框中的两列是否相互独立)
(1)卡方检验 原假设是相互独立的
library(vcd) mytable2<-xtabs(~Treatment+Improved,data=dat) #生成一个列联表 mytable2

chisq.test(mytable2)
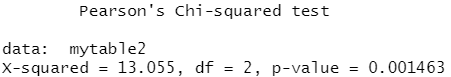
结果分析:结果分析:p-value值小于0.05,拒绝原假设,说明用药与否与病人的改善效果不互相独立,即有关
mytable3<-xtabs(~Sex+Improved,data=dat) mytable3 chisq.test(mytable3)
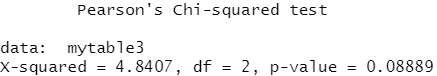
结果分析:p-value值大于0.05,接受原假设,认为性别与改善效果相互独立,即没有关系
(2)精确性检验
fisher.test(mytable3)

结果分析:p-value值大于0.05,接受原假设,认为性别与改善效果相互独立,即没有关系
(3)分层独立性检验 分男性和女性来说,用药与改善效果相互独立
mytable4<-xtabs(~Treatment+Improved+Sex,data=dat) #生成列联表

mantelhaen.test(mytable4)
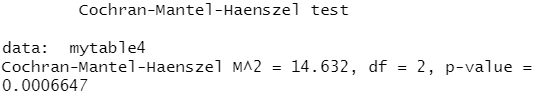
结果分析:p-value值小于0.05,拒绝原假设,无论对于男性还是女性,用药与否对症状的改善都不是相互独立的,即该药无论是对男性还是女性,都是有效果的
2 相关
2.1 相关性度量
mytable2<-xtabs(~Treatment+Improved,data=dat) #生成一个列联表 mytable2
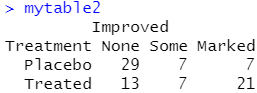
assocstats(mytable2)

结果:phi系数 phi-Coefficient:只对两个变量有效,即行变量两个,列变量也两个
列连系数 Contingency Coeff
克莱姆系数 Cramer’s v
2.2 相关系数的类型
(1)Peason相关系数,Spearman相关系数,Kendall相关系数
dat<-state.x77 #指定数据集 states<-dat[,1:6] #只取前6列 cor(states) #列出所有变量两两之间的相关性,默认相关系数为Peason相关系数
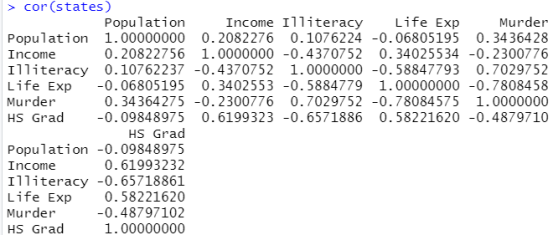
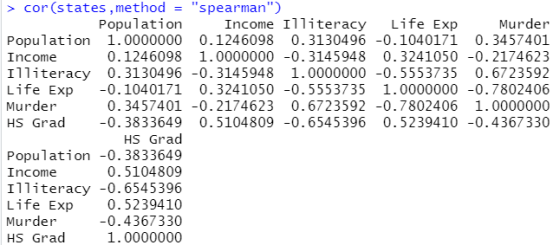
cor(states,method = "spearman") #指定是Spearman相关系数
cov(states) #计算协方差矩阵

(2)偏相关系数
install.packages("ggm")
library(ggm)
colnames(states) #显示出表的列名
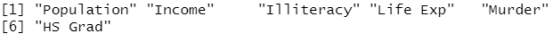
pcor(c(1,5,2,3,6),cov(states)) #pcor()计算偏相关系数,c(1,5,2,3,6)在控制第2、3、6列的情况下,计算第1列和第5列的偏相关性,cov(states)协方差矩阵
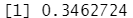
2.3相关系数显著性检验
原假设变量之间不相关,相关系数是接近于0的
cor.test(states[,3],states[,5])
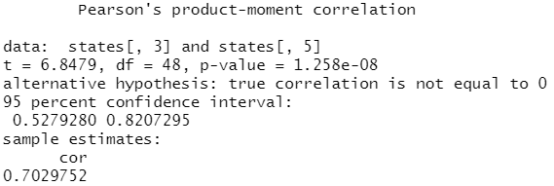
结果分析:p-value值小于0.05,拒绝原假设,即折两列是相关的,同时也可以看到相关系数 cor 比较高
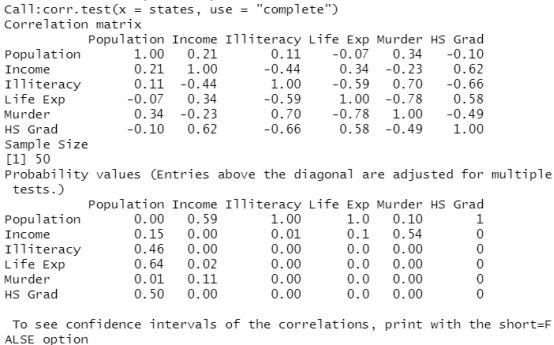
计算相关系数的另一个函数corr.test()
library("psych")
corr.test(states,use="complete")
本文来自博客园,作者:zhang-X,转载请注明原文链接:https://www.cnblogs.com/YY-zhang/p/14972922.html
