高效字符串匹配算法——BM 算法详解(C++)
定义
BM 算法是由 Boyer 和 Moore 两人提出的一种高效的字符串匹配算法,被认为是一种亚线性算法(即平均的时间复杂度低于线性级别),其时间效率在一般情况下甚至比 KMP 还要快 3 ~ 5 倍。
原理
BM 算法跟其他的字符串匹配算法相比,其中一个不同之处是在比对字符的时候,扫描的顺序不是从左往右,而是从右往左的。
暴力匹配
所谓暴力匹配,就是从右向左比对字符,当遇到不匹配的字符时,就将模式串往右移动一个字符,循环执行,直到所有字符都能匹配上(成功),或模式串的右边界超过了文本串的右边界(失败)。如图:



代码实现:
int brute(std::string t, std::string p) {
const int m = p.length(), n = t.length();
int align; // 模式串的对齐位置
int i; // 模式串中的下标
// 循环执行以下步骤,直到全部字符比对成功或模式串的右边界超过了文本串的右边界
for (align = 0; align + i < n && i >= 0; align++) {
// 从右向左逐个比对,直到全部字符比对成功或某个字符比对失败
for (i = m - 1; i >= 0 && t[align + i] == p[i]; i--);
// 如果全部字符比对成功,则退出循环,否则就将模式串向右移动一个字符
if (i < 0) break;
}
return i < 0 // 如果比对成功的话
? align // 就返回模式串的对齐位置
: -1; // 否则就返回-1
}
设文本串的长度为 n,模式串的长度为 m,那么显然暴力匹配算法的时间复杂度为 \(O(mn)\)。
BM 算法利用了坏字符规则和好后缀规则,排除掉肯定不可能匹配上的位置,使得匹配失败的时候模式串能够跳跃尽可能多的距离,时间复杂度能够大大降低。
坏字符规则
如果某次扫描比对的时候发现匹配失败,那么就称文本串中匹配失败的那个字符为坏字符(Bad character)。
所谓坏字符规则(Bad character shift),就是指当遇到坏字符的时候,在模式串中寻找能够与之匹配的字符并将两者对齐。


如果模式串中找不到能够与之匹配的字符,那就直接将模式串越过匹配失败的位置。


如果模式串中有多个字符能够与坏字符匹配上,那就将最右边的那个字符与坏字符对齐,这样就能避免遗漏对齐位置。


好后缀规则
如果某次扫描比对的时候发现匹配失败,那么就称模式串中匹配失败的那个字符右侧比对成功的字符所构成的后缀称为好后缀(Good suffix)。
所谓好后缀规则(Good suffix shift),分为以下3种情况:
- 模式串中有能够与好后缀匹配上的子串,将该子串与好后缀对齐。如果有多个能够与好后缀匹配上的子串,选择最靠右的那一个。


- 模式串中没有能够与好后缀匹配上的子串,但是模式串的某个前缀能够与好后缀的真后缀匹配,将该前缀的最后一个字符与好后缀的最后一个字符对齐。
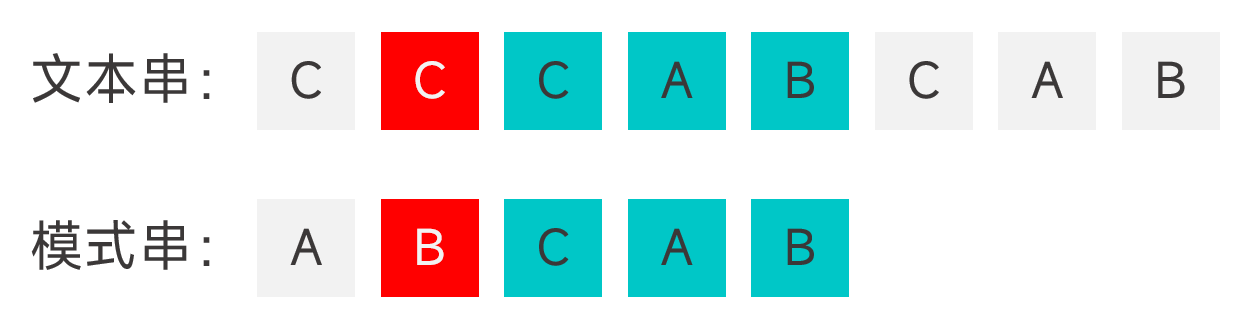
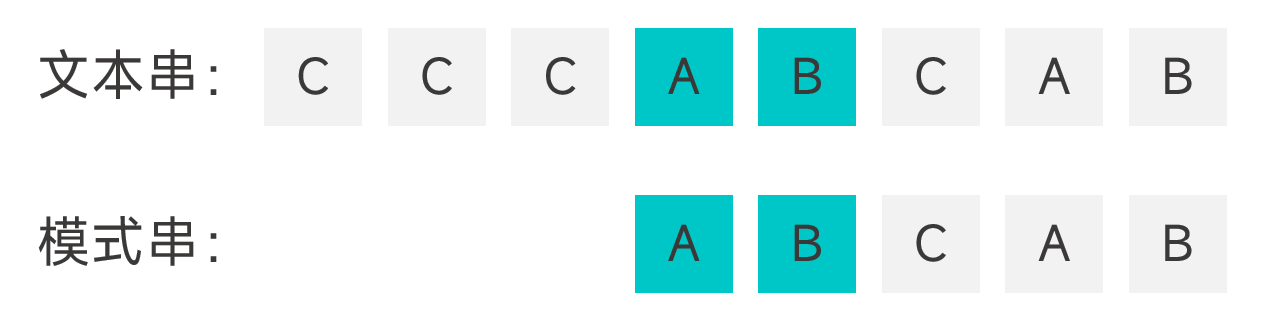
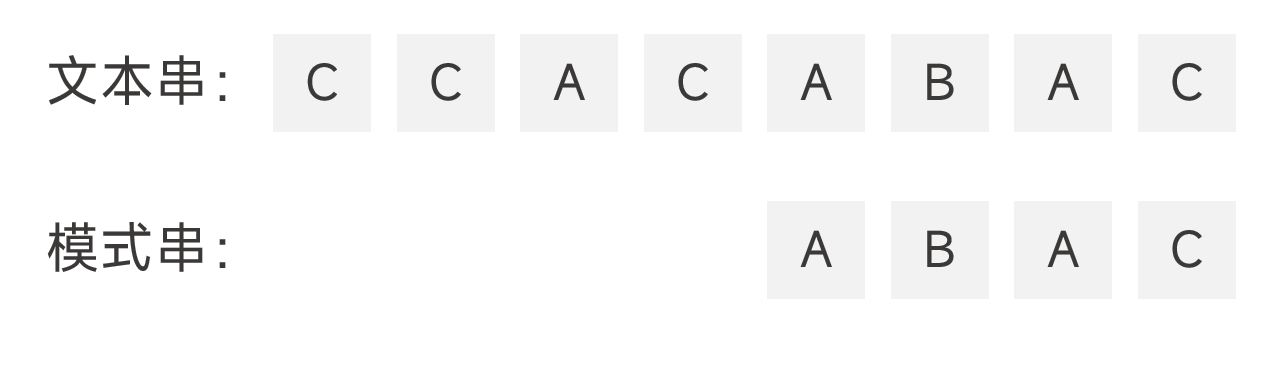
- 模式串中没有能够与好后缀匹配上的子串,且没有哪个前缀能够与好后缀的真后缀匹配,直接将模式串越过好后缀的位置。

算法步骤
整个 BM 算法的步骤为:从后往前比对字符,如果遇到不匹配的字符,看坏字符规则和好后缀规则中哪个规则会使得模式串移动的距离更大,并相应的移动。
举例:

(其中x为无关紧要的字符)
第一轮比对在倒数第2个字符的位置失败了:

此时,分别运用好后缀规则和坏字符规则,发现运用坏字符规则移动的距离更远:

重新开始新一轮的比对:

再次运用这两个规则,发现好后缀规则移动的距离更远。

开始第三轮比对,发现这次比对成功了。

至此,算法宣告结束。
代码实现
为了能够快速得到某次比对失败时,按照这两个规则,模式串需要移动的位置,我们需要对模式串进行预处理,构建两个辅助数组。
预处理:构造 bc 数组
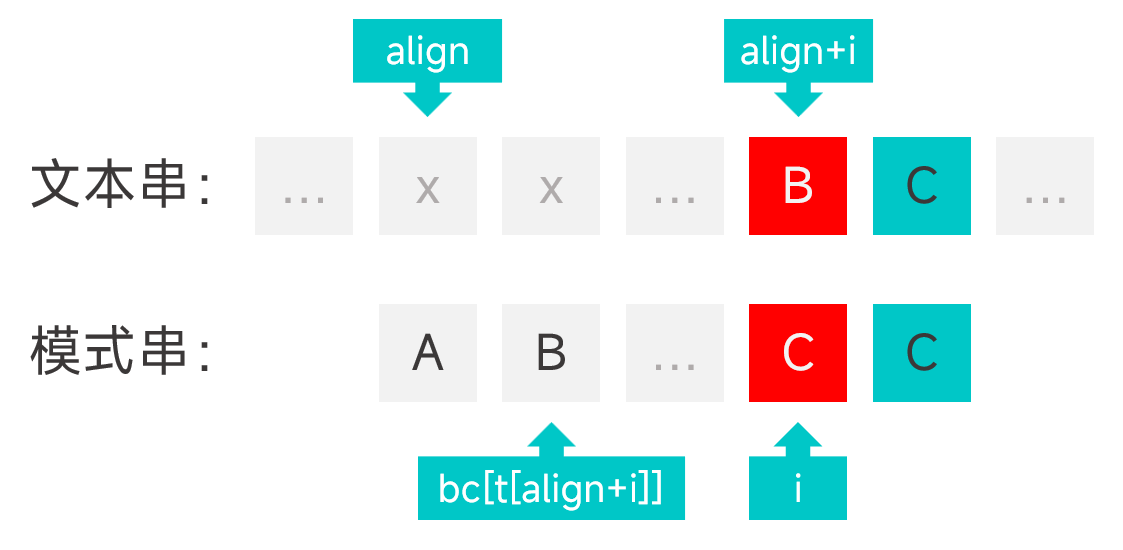
构造 bc 数组用于坏字符规则,其中 bc[c] 表示坏字符 c 在模式串中的最大下标。如果模式串中不存在字符 c 则为 -1,这样才能确保模式串移动的时候能够刚好越过坏字符的位置。当然数组的大小要足够大,这样才能容纳文本串中的所有字符。
这样,当遇到坏字符时,假设模式串中匹配失败的字符的下标为 i,模式串的头部在文本串中的对齐位置为 align,那么模式串需要移动的距离为 i - bc[t[align + i]],如图。
代码实现:
void buildBC(std::string &p, int range) { // range为字符集大小。对于英文的话,128就足够了
const int m = p.length();
std::vector<int> bc(range, -1);
for (int i = 0; i < m; ++i) {
char c = p[i];
bc[c] = i;
}
return bc;
}
为什么是从左往右呢,因为这样的话,对于同一个字符,如果存在多个下标,大的下标才能覆盖小的下标。
预处理:构造 gs 数组
构造 gs 数组用于好后缀规则,其中 gs[i] 表示如果模式串中下标为i的字符与文本串中的相应字符比对失败的话,为了使好后缀对齐,模式串应该移动的距离。
然而,如果我们直接构造的话,时间成本为 \(O(m^3)\)!这显然是不能接受的,于是我们需要用“空间换时间”的策略将时间成本降低。
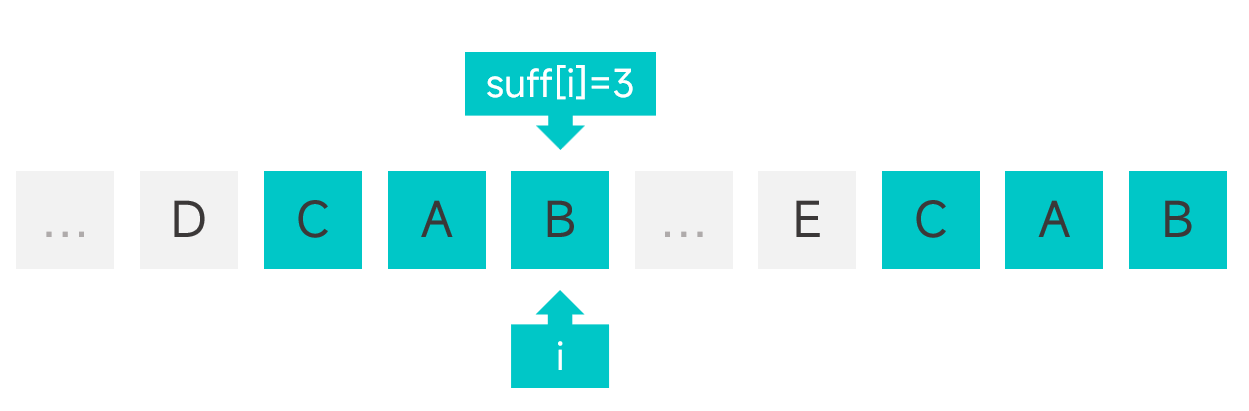
为此我们需要引入另外一个辅助数组 suff,其中 suff[i] 为模式串中下标为i的字符左侧(包括下标为 i 的字符)最多能有多少个字符能够与模式串的后缀匹配,如图:
代码如下:
std::vector<int> buildSuff(std::string &p) {
const int m = p.length();
std::vector<int> suff(m, 0);
suffix[m - 1] = m; // 对于最后一个字符,显然该字符以左的所有字符都能与模式串的后缀匹配
for (int i = m - 2; i >= 0; i--) { // 从右往左扫描
int j = i, k = m - 1;
for (; j >= 0 && p[j] == p[k]; j--, k--); // 双指针同步向左扫描
suffix[i] = i - j;
}
return suff;
}
时间复杂度为 \((n^2)\),但是最坏情况只有当模式串所有字符全都一样的时候才会出现,一般情况下只会比 \(O(n)\) 略微多一点点,因此是可以接受的。
然后我们就可以利用 suff 数组求得 gs 数组了。构建 gs 数组的部分也有讲究。
我们首先需要计算第 3 种情况,然后是第二种,最后是第一种。为什么呢,因为如果同一个字符同时满足以上三种情况中的至少 2 种的话,位移距离:第三种情况 > 第二种 > 第一种,为了不遗漏对齐位置,我们要选择最靠右的那个好后缀,那只能用小的位移距离覆盖大的位移距离。
第三种情况比较简单,直接全都设为 m 就可以了。(C++ 里面这一步在初始化的时候就可以完成)
std::vector<int> gs(m, m);
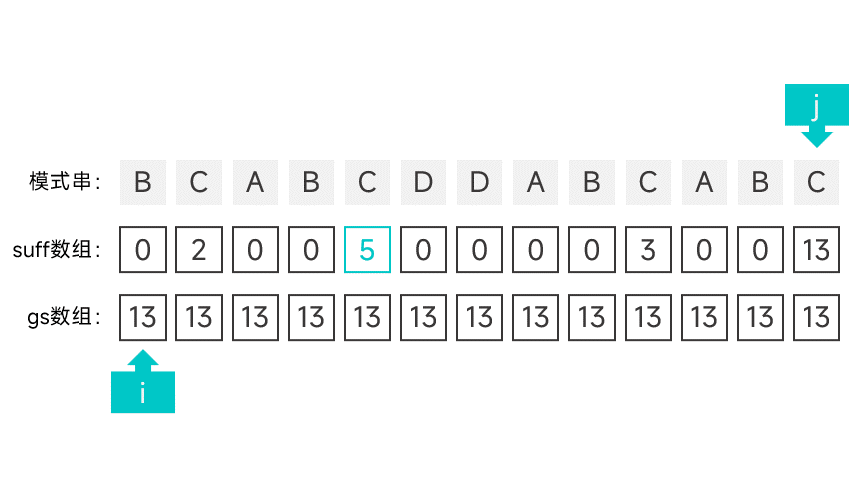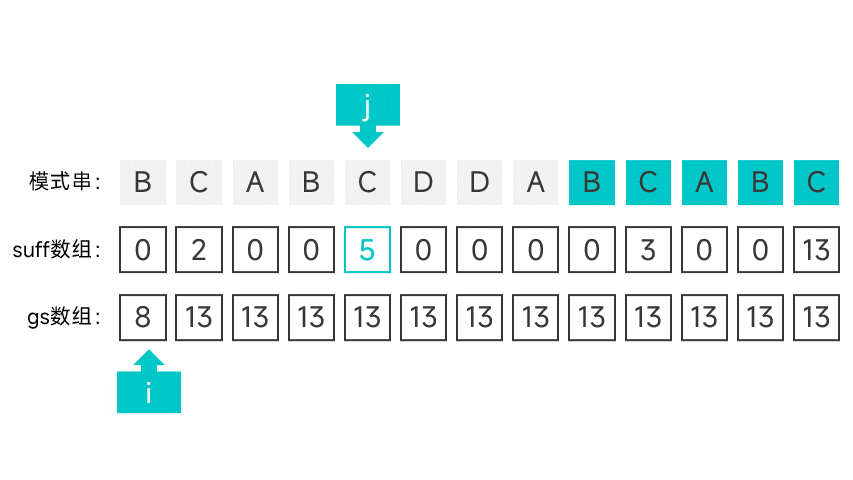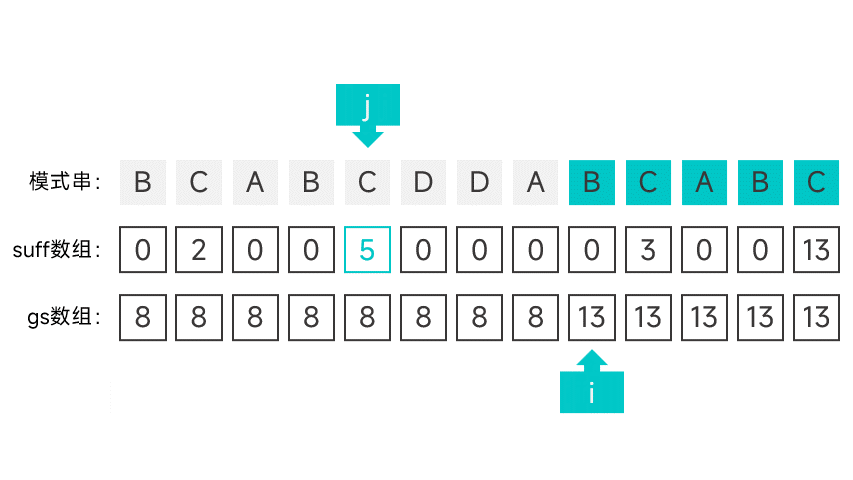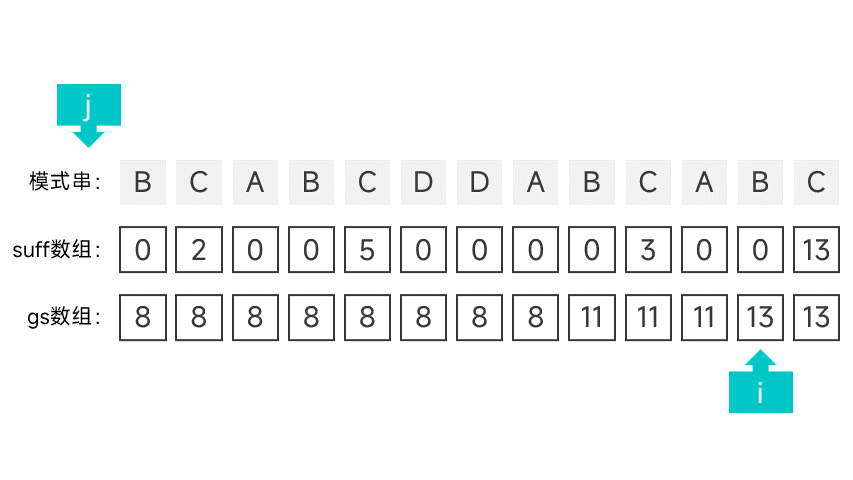
第二种情况有点讲究,首先需要维护一个指针 i,初始时指向模式串的第一个字符。从右往左扫描字符串,根据对应的 suff 数组项判断是否满足第二种情况。怎么判断呢,看图就知道了:

如果某个字符的 suff 数组项刚好等于下标 + 1 的话(此时的数组项记作 sufLen),那就说明该字符以左的所有字符组成的前缀都能与模式串的后缀匹配。如果该后缀为某次比对中的好后缀的后缀,那就说明符合第二种情况。这就说明模式串中倒数第 sufLen 个字符(也就是下标为 m - suflen 的字符)的左边某个字符如果发生匹配失败,模式串应该右移 m - sufLen 个字符。
如果遇到符合第二种情况的字符的话,就将指针 i 指向的字符的 gs 数组项设为 m - suflen,并向后移动一个字符,直到指针指向了 m - sufLen。
继续向左扫描,重复以上操作,直到扫描到模式串的最左端。
动画表示:
代码实现:
for (int i = 0, j = m - 1; j >= 0; j--) {
int sufLen = suff[j];
if (sufLen == j + 1) {
for (; i < m - sufLen; i++) {
if (gs[i] == m) { // 加上这一句条件判断的目的是为了防止重复设置
gs[i] = m - sufLen;
}
}
}
}
有人会问,为什么是从右向左扫描字符串呢,是因为如果存在多个字符满足第二种情况,那必然是右边字符的 sufLen 大于左边字符的 sufLen。sufLen 越大,m - sufLen 越小。而如果某个字符发生匹配失败需要用到第二种情况的话,那必然优先选择 m - sufLen 小的那个,也就是 sufLen 大的那个。那为什么不像 bc 数组和 suff 数组构建算法那样采用 “大的覆盖小的” 的方法呢,是因为这样的话每次都要设置一大片字符的 gs,反而会使时间复杂度上升到 \(O(n^2)\),不划算。
最后再来看第一种情况,从左往右扫描模式串,根据扫描到的字符的下标及 suff 数组项可以方便的求出对应坏字符的下标及 gs 数组项,如图:
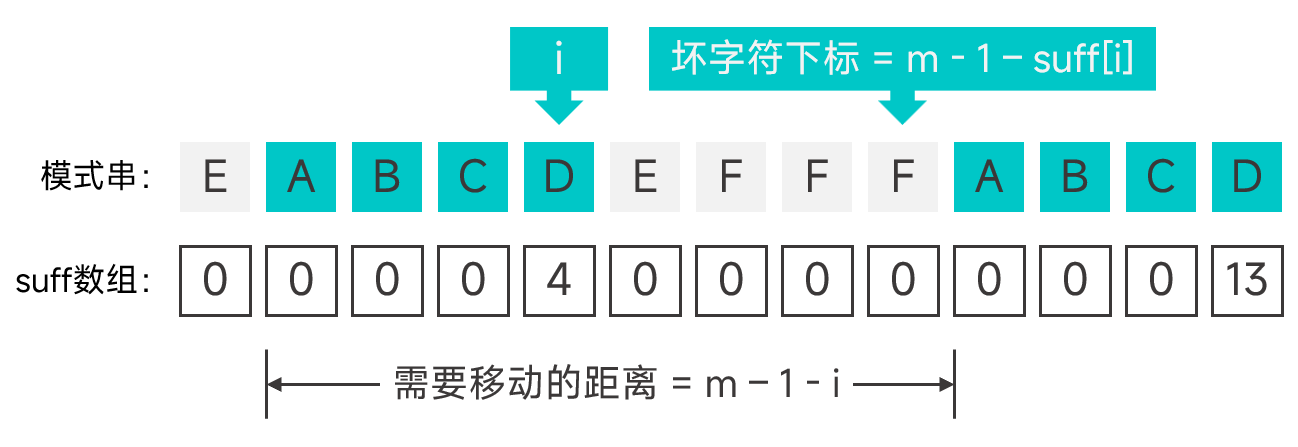
代码实现:
for (int i = 0; i < m - 1; ++i) {
int sufLen = suff[i];
gs[m - 1 - sufLen] = m - 1 - i;
}
至此,通过 suff 数组构建 gs 数组的完整实现代码:
std::vector<int> buildGS(std::string &p) {
const int m = p.length();
auto suff = buildSS(p);
std::vector<int> gs(m, m);
for (int i = 0, j = m - 1; j >= 0; j--) {
int sufLen = suffix[j];
if (sufLen == j + 1) {
for (; i < m - sufLen; i++) {
if (gs[i] == m) {
gs[i] = m - sufLen;
}
}
}
}
for (int i = 0; i < m - 1; ++i) {
int sufLen = suffix[i];
gs[m - 1 - sufLen] = m - 1 - i;
}
return gs;
}
主算法实现
int match(std::string t, std::string p, int range) {
const int m = p.length(), n = t.length();
// 两个预处理数组
auto bc = buildBC(p, range);
auto gs = buildGS(p);
int align = 0; // 模式串的对齐位置
int i = m - 1; // 模式串中的下标
while (align + i < n && i >= 0) {
for (; i >= 0 && t[align + i] == p[i]; i--); // 从右往左比对
if (i < 0) break; // 比对成功就退出循环
// 以下处理比对失败的情况
int distBc = i - bc[t[align + i]]; // 根据坏字符规则得到的移动距离
int distGs = gs[i]; // 根据好后缀规则得到的移动距离
align += std::max(distBc, distGs); // 模式串的位移距离取两者之间的较大者
i = m - 1; // 重新开始新一轮的比对
}
return i < 0 ? align : -1;
}
复杂度分析
空间复杂度
不计文本串和模式串本身所占用的空间,算法的空间复杂度为 \(O(m + |\Sigma|)\),其中 m 为模式串的长度,\(|\Sigma|\) 为字符集的大小。其中 bc 数组所占用的空间为 \(O(|\Sigma|)\),gs 数组则为 \(O(m)\)。
时间复杂度
最好:\(O(n/m)\),最坏:\(O(n+m)\),其中 n 和 m 分别为文本串和模式串的长度。
最好情况的一个实例:
文本串:AAAAAA...AAAA
模式串:AAB
每次比对,都会在倒数第一个字符发生匹配失败。按照坏字符规则,模式串应该向右移动 m 个字符。所以,模式串的移动次数最多为 n / m。而每次比对的次数都是 1 次,因此这种情况下的时间复杂度为 \(O(n/m)\)。
最坏情况的一个实例:
文本串:AAAAAA...AAAA
模式串:BAA
每次比对,都会在第一个字符发生匹配失败。按照好后缀规则,模式串应该向右移动 m 个字符。所以,模式串的移动次数最多为 n / m。而每次比对的次数都是 m 次,因此这种情况下的时间复杂度为 \(O(n/m*m)=O(n)\)。
本文来自博客园,作者:YVVT_Real,转载请注明原文链接:https://www.cnblogs.com/YWT-Real/p/17120732.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号