


第四次作业 构建之法
|
作业GIT地址 |
|
|
搭档博客地址 |
|
|
作业链接 |
|
PSP2.1 |
Personal Software Process Stages |
预估耗时(分钟) |
实际耗时(分钟) |
|
Planning |
· 计划 |
30 |
60 |
|
· Estimate |
· 估计这个任务需要多少时间 |
1200 |
1440 |
|
Development |
· 开发 |
600 |
720 |
|
· Analysis |
· 需求分析 (包括学习新技术) |
300 |
240 |
|
· Design Spec |
· 生成设计文档 |
180 |
240 |
|
· Design Review |
· 设计复审 (和同事审核设计文档) |
80 |
60 |
|
· Coding Standard |
· 代码规范 (为目前的开发制定合适的规范) |
60 |
40 |
|
· Design |
· 具体设计 |
60 |
60 |
|
· Coding |
· 具体编码 |
600 |
480 |
|
· Code Review |
· 代码复审 |
60 |
30 |
|
· Test |
· 测试(自我测试,修改代码,提交修改) |
120 |
150 |
|
Reporting |
. 报告 |
60 |
80 |
|
· Test Report |
· 测试报告 |
40 |
50 |
|
· Size Measurement |
· 计算工作量 |
30 |
30 |
|
· Postmortem & Process Improvement Plan |
· 事后总结, 并提出过程改进计划 |
40 |
70 |
|
|
合计 |
3460 |
3750 |
计算机接口的设计与实现过程:
总的设计思路在我的同伴博客:搭档博客地址 这里我只给出了我负责的内容
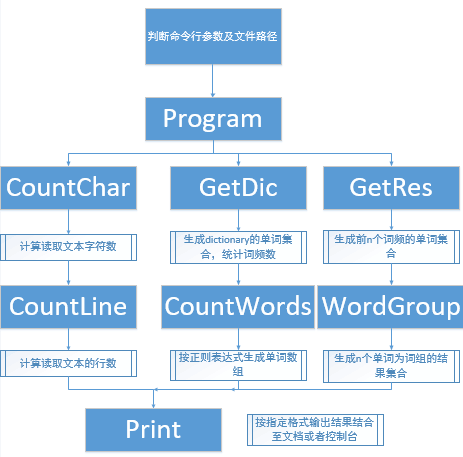
那我负责的功能模块主要是GetDic类和GetRes类及Print类这三个类。
print类主要是分辨命令行参数,判断是文本输出还是控制台输出,文本输出则使用StreamWriter这个字符流。
较为关键的则是GetDic类和GetRes类,GetDic类则是使用了dictionary集合生成具有词频的单词集合,那我通过CountWords 所得到的单词集合传入GetDic类遍历集合,第一次的存入集合,重复的词频加一,生成了一个具有词频的单词集合。
流程图
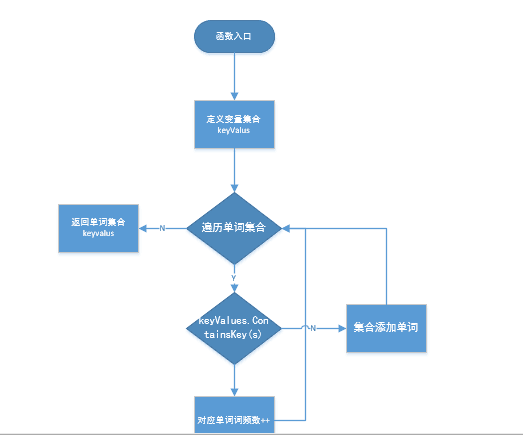GetRes类则是使用上述getdic所产生的集合进行数据处理,同样是使用dictionary作为结果集合,我优先进行单词集合词频的统计,再由词频在已经排好字典序的单词集合中找,如果符合则添加到我的结果集合中,由Print函数输出
流程图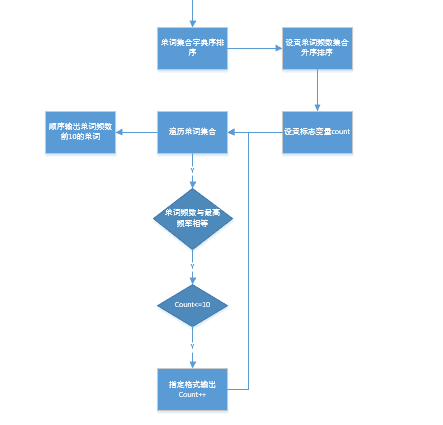
关键代码展示:
GetDic类:
//传入有countWords使用的单词集合
//得到单词以及对应的数目存入泛型数组keyValues
public static Dictionary<string, int> createDic(StreamReader sr,List<string>words)
{
Dictionary<string, int> keyValues = new Dictionary<string, int>();
//如果这个泛型集合里面如果有这个单词的话就数量增加如果没有这个单词的话就把它加入这个集合
foreach (string s in words)
{
if (keyValues.ContainsKey(s))
{
keyValues[s]++;
}
else
{
keyValues.Add(s, 1);
}
}
return keyValues;
}
GetRes类:
//将单词进行词频排序并且输出前n个词频的单词
public static void SortKey(Dictionary<string, int> keyValues, Dictionary<string, int> result, int count)
{
//对该集合进行字典序排序
keyValues = keyValues.OrderBy(o => o.Key, StringComparer.Ordinal).ToDictionary(p => p.Key, o => o.Value);
//单词频数集合
List
四大原则体现:
Design By Contract:
调用上述方法时对文件路径有一定要求,我设置了以.txt格式的文本来作为数据源,那如果不是文本的话,则会提示错物信息
Information Hiding:
那每个模块的功能是独立的,即使我设置为了静态方法,但是在CountWords的时候使用了正则表达式,具体的正则表达式对于其他模块来讲,应该时封闭的,因此我设置了关于正则表达式的数据时私有的。
Interface Design:
按照功能模块定义为接口或者接口功能的名字,任意接口之间没有什么直接的联系,如直接调用等聚合方式,但是在参数部分,需要使用其他接口调用的结果。
Loose Coupling :
各模块之间可独立运行,在第一版中我们时使用了一个工具类包括了这些方法,同样的使用了相同的静态数据来存储结果,在和同伴讨论后,发现模块之间联系的过于紧密,因此将具体方法分类,模块独立使用。增强他的松耦合。
代码复审过程:
### 结对编程代码规范 - 缩进:采用 4个空格缩进,不用 Tab键的理由是Tab键在不同的情况下会显示不同的长度。4个空格的距离从可读性来说正好。 - 括号:在复杂的条件表达式当中,用括号清楚地表示出逻辑关系。 - 如果出现{}的存在,采取下面的形式: if ( condition) { DoSomething(); } else { DoSomethingElse(); } - 分行:不要把多条语句放在一行上,不要把不同的变量定义在一行上。 - 命名规范:命名要有一定的可理解性。变量的第一个字母通常为大写字母,Pascal——所有单词的第一个字母都大写; - 程序注释:将语句注释放在单独的行上,变量注释放在同一行。用句号结束注释文本。每个类的开头做出对这个类的说明。对于函数的注释,将函数的功能注释写在函数的开头的上面一行。对于一些重要的功能语句换行在下方注释。 - 对于大多数异常处理,请使用try-catch语句。 - 将每个功能分离开来,分类书写。 - 析构函数:把所有的清理工作都放在析构函数中。如果有些资源在析构函数之前就释放了,记住要重置这些成员为0或NULL。 - 不要定义无用的变量。审查
本次的代码经过了自审及互审的过程,完善了一些不足。自审过程则发现了流的释放问题及代码注释问题,并且感觉自己的接口设计有缺陷,重复使用了StreamReader类,那我将streamreader写主程序中,以参数方式使用,节省空间。
那在互审过程中,我发现了同伴的代码问题
应该使用\W 表示的非英文数字字符,那\w 表示的是英文字符如果使用上文中的,则是分割了字母,而不是单词,会导致程序可以运行,但是结果异常。
接口部分性能改进:
性能改进: 第一个版本将所有的功能都写在一个类当中: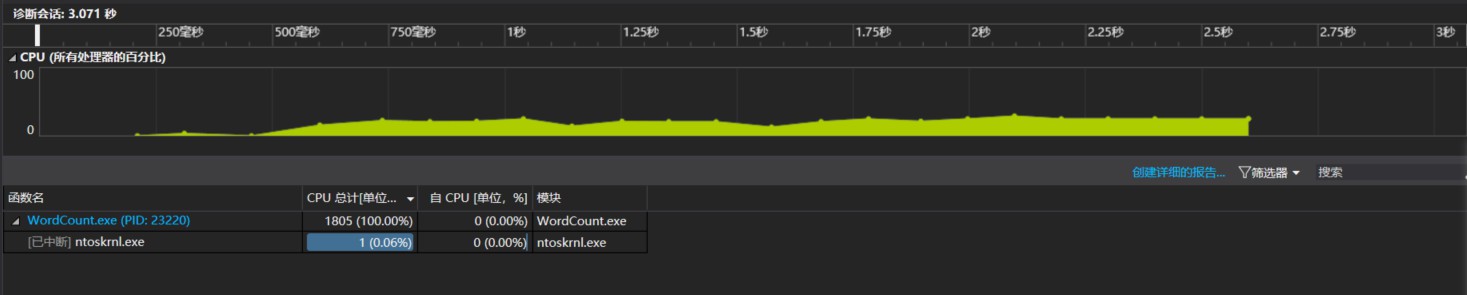 发现CPU的消耗很大,所以将其解耦,也就是将每个功能分为一个一个的类得到性能分析图:
发现CPU的消耗很大,所以将其解耦,也就是将每个功能分为一个一个的类得到性能分析图:
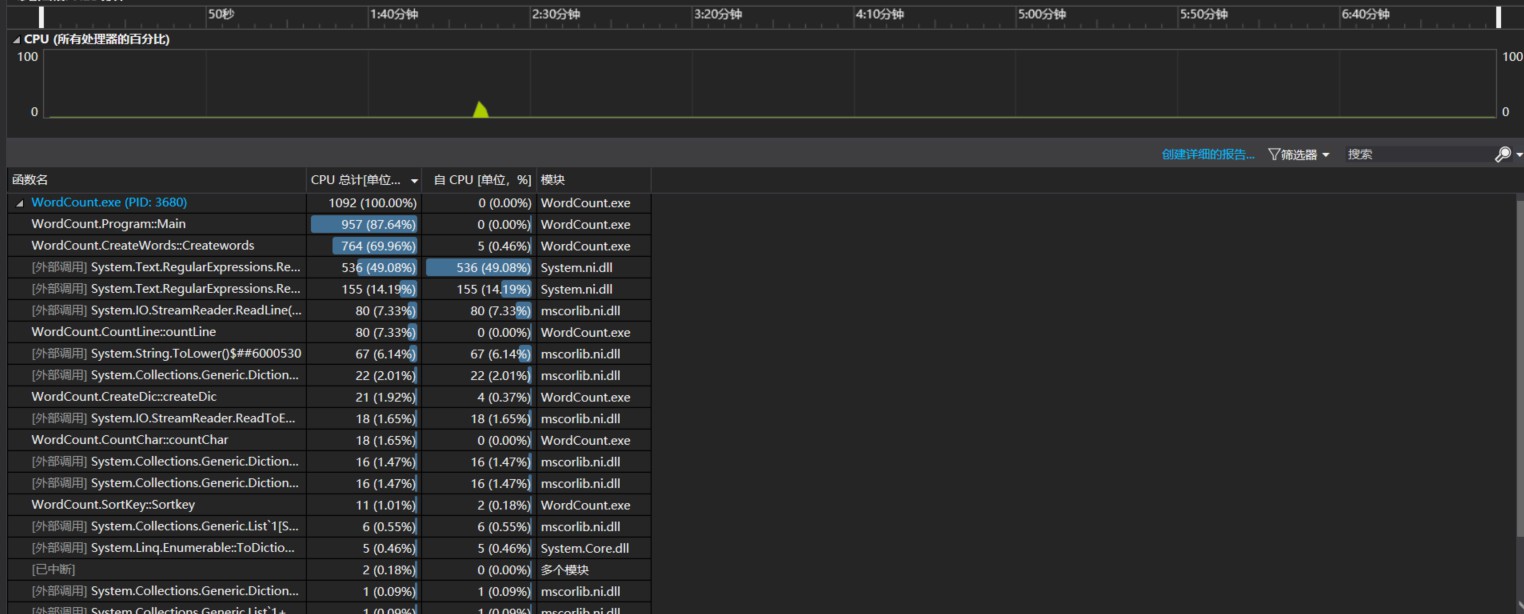
计算模块花费的时间:

进行效能分析:
为了方便进行效能分析直接规定输入输出txt文件以及对应的命令参数的值。
1.VS当中内置有效能工具,名叫性能探查器。
2.为了查看程序的执行效率,选择测试CPU使用率->开始:
3.等待分析一段时间后,停止收集,最后就会产生一份效能分析报告:
但是在进行分析报告的时候出现了问题如图:
于是百度查找了一下解决方式:点击调试->选项->右边勾上启用源服务器支持->左边点符号把微软符号服务器勾选上->确定:
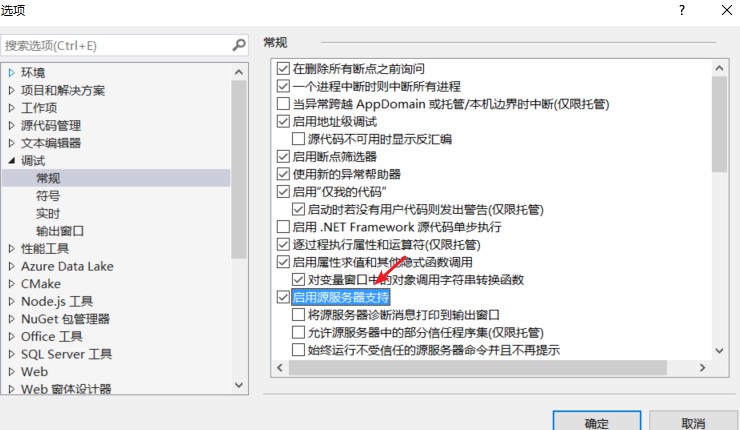
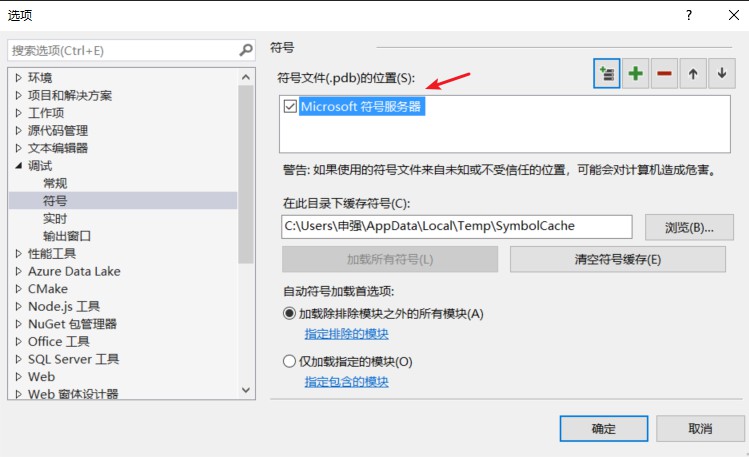
4.再次根据1、2步骤进行性能测试,为了方便性能测试将主函数的命令行输入的参数直接固定,因此将参数判定改为:
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
using System.IO;
using System.Text.RegularExpressions;
namespace WordCount
{
class Program
{
static void Main(string[] args)
{
//设置读取路径变量
String Inpath ="ming.txt";
String Outpath = "out.txt";
//默认讲标志量设为-1
int count = -1;
//设置读取词组的个数
int group = -1;
//遍历命令参数
count = 5;
group= 5;
//路径读取失败
if (Inpath == null)
{
Console.Write("未输入文档路径");
Environment.Exit(404);
}
else if (!Inpath.EndsWith(".txt"))
{
Console.Write("文档格式不正确,请使用txt文档");
Environment.Exit(404);
}
else
{
try
{
StreamReader streamReader = new StreamReader(Inpath);
//封存结果的一个集合
Dictionary<string, int> result = new Dictionary<string, int>();
//得到文本字符串
string txt = CountChar.countChar(streamReader);
//统计字符数
result.Add("characters: ",txt.Length);
//得到符合要求的英语单词集合
List<string> words = CountWords.CreateWords(streamReader, txt);
//统计单词数
result.Add("words: ", words.Count);
//统计行数
result.Add("lines: ", CountLine.countLine(streamReader));
//Dictionary<string,int> 也是一个泛型集合,得到对应的单词以及单词的数量
Dictionary<string, int> keyValues = GetDic.createDic(streamReader, words);
//得到频数前n的单词及频数封装到result集合里
GetRes.SortKey(keyValues, result, count);
if (group != -1)
{
WordGroup.wordgroup(group, words, result);
}
Print.print(result, Outpath);
}catch(Exception e)
{
Console.Write("文件读取异常,未找到该资源,请检查输入");
Environment.Exit(404);
}
}
}
}
}
5.得到性能详细报告:

程序中消耗最大的函数:

其中主要是由于调用了一个函数Regex.LsMatch调用了堆栈底部所以对CPU的消耗比较大。
单元测试展示:
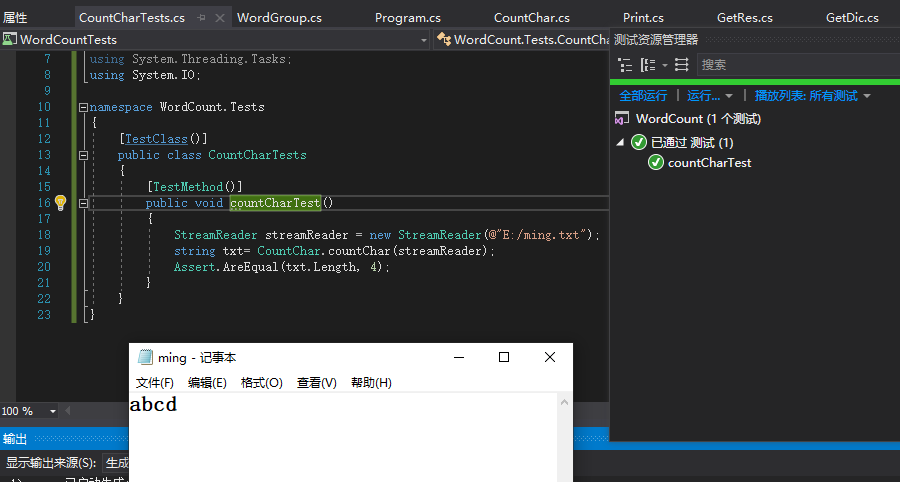
测试函数-CountChar(统计字符类)
思路:读取一个简单的文档,使用断言判断字符串长度是否等于自己的预期
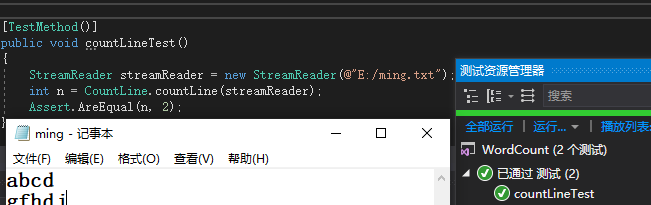
 p>测试函数-CountLine(统计行数类)思路:读取一个简单的文档,使用断言判断其行数是否等于自己预期
测试函数CreatWords(统计单词类)
思路:同样是读取一个文件 得到起文本字符串 ,使用测试函数生成单词词组,判断单词的个数。
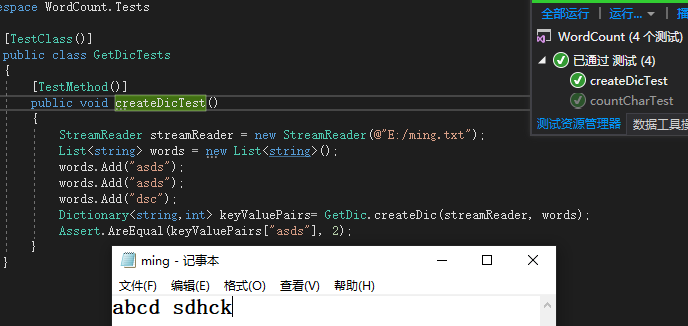
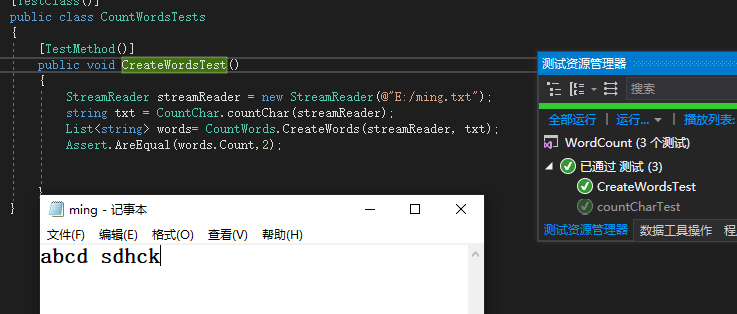测试函数-GetDic(生成单词)
思路:本想使用读取文件,但是速度较慢,为验证功能,我摸拟了一个单词列表,借由此单词列表测试被测试函数,可以测试出对应单词的频数符合自己的预期
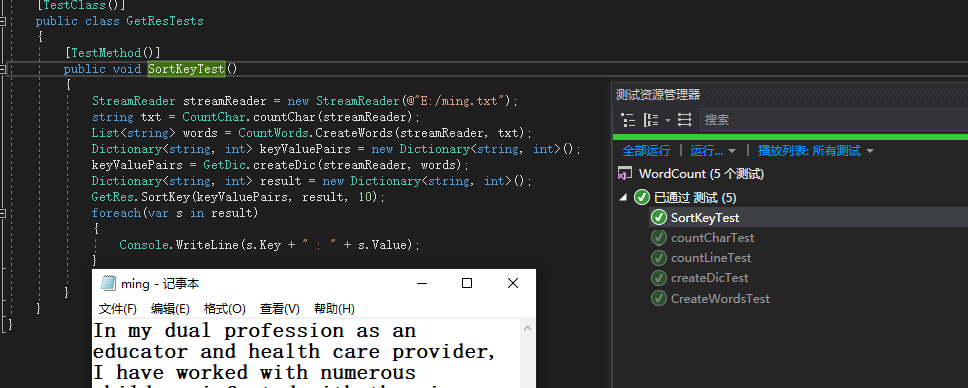
测试函数-GetRes(统计词频前n并添加到结果集合)
思路:读取文档生成了一个dictionary的单词集合,借由集合测试被测试函数,会输出到前10的单词 至控制台中,结果如下
测试函数-WordGroup(词组输出)
思路,读取文本文件,得到其单词数量list,测试被测试函数,输出以三个为一组的单词,将测试结果输出至控制台
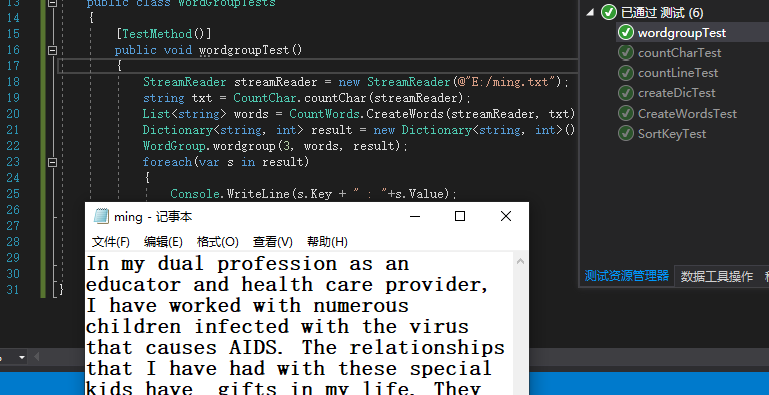 
全部测试通过
计算模块部分异常处理说明
异常处理机制,忽略因代码问题所产生的异常,我在这里主要考虑的就是有关文件读取方面的相关异常,那我设计了几个相关的操作,其中文件格式和未输入文件是通过if else 在主方法前进行判断的,数据的来源则是最重要的,那有了正确的输入文件和格式,但是路径失败会导致读取不到相应的文件,因此我使用了try catch 语句进行异常的捕获,具体如下
这个是判断路径及格式问题,测试用例如下:
场景则是防止在用户输入错误的文档格式或者忘记输入文档路径进行的处理机制,否则会引发程序中的异常。
这个则是在streamReader读取文档时因检索不到本地资源导致抛出异常,异常会被catch捕获,输出提示信息并中断程序。
场景则是用户输入了正常的格式及文档路径,但是在本地没有这个资源文件而导致的异常。
 ### 附加功能: 完整在搭档博客上,这里只给我编写的代码。 附加功能我负责得主要是后台操作数据,也就是计算字符串个数行数,统计频率及单词数组,返回到前台。 图示如下 由输入框传来得文本分别调用上述得方法,然后将结果字符串返回至输出框,显示出输出结果   ##### 实现效果展示: 1.展示导入文件的:  2.展示自定义文件的:  ### 结对过程 结对编程还真是第一次,之前虽有队伍一起写xx项目的经历,但是像这样的一个过程却是第一次,那我和我的搭档在讨论出整个项目的需求及分工后,在第一天我们起草了一份计划,并按照计划的分工来编写。我们找了一个时间段,聚在一起编程,能够提高编程效率。很感谢搭档的帮助,和结对编程的过程,更加增强了我对团队协作的认知。 提供非摆拍的两人在讨论的结对照片:  (实际会有一些变动)
###心得体会
就我个人来说 我感觉1+1>2,这次的编码过程,不同以往,是一个很新的体验,两个人的合作,可以互相学习优点,也可以互相指出缺点。通过这次的学习,掌握了一定的集合知识和文件操作的相关知识,还学习了一点winform的东西,感觉收获还是很多的。合作中,每个人的思路习惯时不一样的,但是我们很好得遵守代码规范,并在互审中发现设计盲区。很喜欢这种结对得模式。
 (实际会有一些变动)
###心得体会
就我个人来说 我感觉1+1>2,这次的编码过程,不同以往,是一个很新的体验,两个人的合作,可以互相学习优点,也可以互相指出缺点。通过这次的学习,掌握了一定的集合知识和文件操作的相关知识,还学习了一点winform的东西,感觉收获还是很多的。合作中,每个人的思路习惯时不一样的,但是我们很好得遵守代码规范,并在互审中发现设计盲区。很喜欢这种结对得模式。

