

Go语言的100个错误使用场景(55-60)|并发基础
 我的愿景是以这套文章,在保持权威性的基础上,脱离对原文的依赖,对这100个场景进行篇幅合适的中文讲解。所涉内容较多,总计约 8w 字,这是该系列的第七篇文章,对应书中第55-60个错误场景。
我的愿景是以这套文章,在保持权威性的基础上,脱离对原文的依赖,对这100个场景进行篇幅合适的中文讲解。所涉内容较多,总计约 8w 字,这是该系列的第七篇文章,对应书中第55-60个错误场景。
前言
大家好,这里是白泽。《Go语言的100个错误以及如何避免》是最近朋友推荐我阅读的书籍,我初步浏览之后,大为惊喜。就像这书中第一章的标题说到的:“Go: Simple to learn but hard to master”,整本书通过分析100个错误使用 Go 语言的场景,带你深入理解 Go 语言。
我的愿景是以这套文章,在保持权威性的基础上,脱离对原文的依赖,对这100个场景进行篇幅合适的中文讲解。所涉内容较多,总计约 8w 字,这是该系列的第七篇文章,对应书中第55-60个错误场景。
🌟 当然,如果您是一位 Go 学习的新手,您可以在我开源的学习仓库中,找到针对《Go 程序设计语言》英文书籍的配套笔记,其他所有文章也会整理收集在其中。
📺 B站:白泽talk,公众号【白泽talk】,聊天交流群:622383022,原书电子版可以加群获取。
前文链接:
8. 并发基础
🌟 章节概述
- 理解并发和并行
- 为什么并发并不总是更快
- cup 负载和 io 负载的影响
- 使用 channel 对比使用互斥锁
- 理解数据竞争和竞态条件的区别
- 使用 Go context
8.1 混淆并发与并行的概念(#55)
以一家咖啡店的运作为例讲解一下并发和并行的概念。
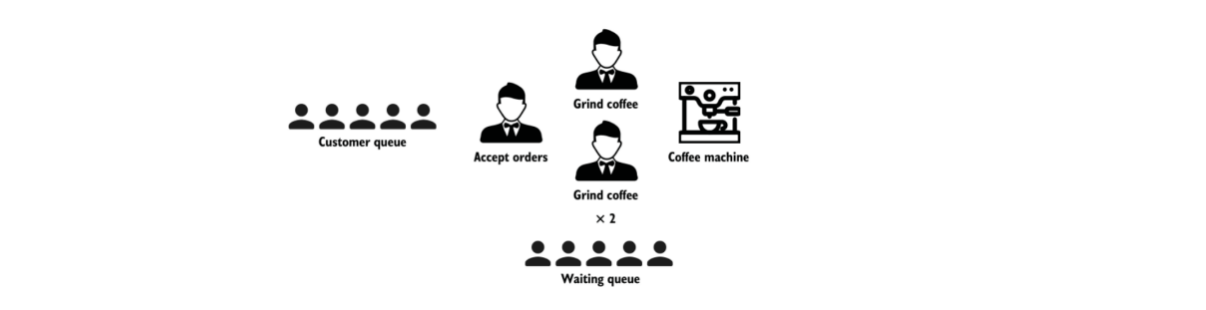
- 并行:强调执行,如两个咖啡师同时在给咖啡拉花
- 并发:两个咖啡师竞争一个咖啡研磨机器的使用
8.2 认为并发总是更快(#56)
- 线程:OS 调度的基本单位,用于调度到 CPU 上执行,线程的切换是一个高昂的操作,因为要求将当前 CPU 中运行态的线程上下文保存,切换到可执行态,同时调度一个可执行态的线程到 CPU 中执行。
- 协程:线程由 OS 上下文切换 CPU 内核,而 Goroutine 则由 Go 运行时上下文切换协程。Go 协程占用内存比线程少(2KB/2MB),协程的上下文切换比线程快80~90%。
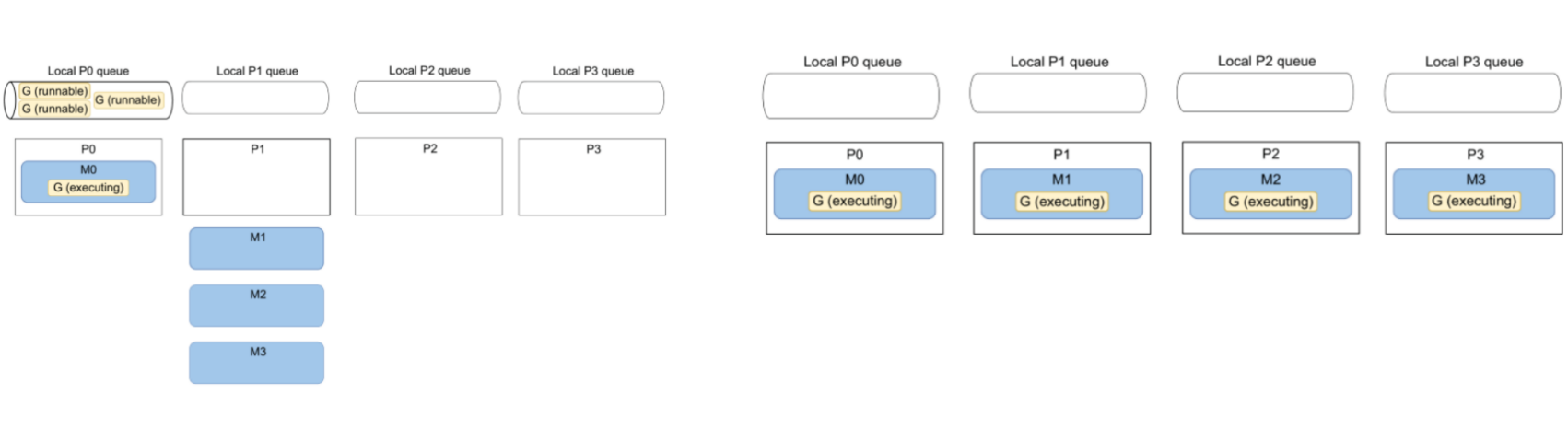
🌟 GMP 模型:
- G:Goroutine
- 执行态:被调度到 M 上执行
- 可执行态:等待被调度
- 等待态:因为一些原因被阻塞
- M:OS thread
- P:CPU core
- 每个 P 有一个本地 G 队列(任务队列)
- 所有 P 有一个公共 G 队列(任务队列)
协程调度规则:每一个 OS 线程(M)被调度到 P 上执行,然后每一个 G 运行在 M 上。
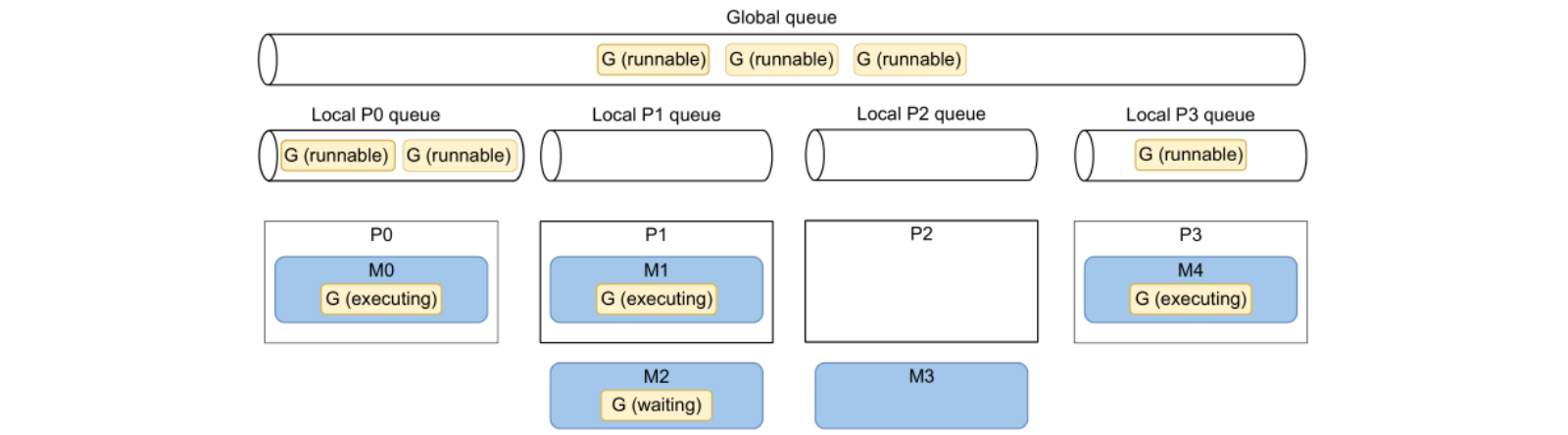
🌟 上图中展示了一个4核 CPU 的机器调度 Go 协程的场景:
此时 P2 正在闲置因为 M3 执行完毕释放了对 P2 的占用,虽然 P2 的 Local queue 中已经空了,没有 G 可以调度执行,但是每隔一定时间,Go runtime 会去 Global queue 和其他 P 的 local queue 偷取一些 G 用于调度执行(当前存在6个可执行的G)。
特别的,在 Go1.14 之前,Go 协程的调度是合作形式的,因此 Go 协程发生切换的只会因为阻塞等待(IO/channel/mutex等),但 Go1.14 之后,运行时间超过 10ms 的协程会被标记为可抢占,可以被其他协程抢占 P 的执行。
🌟 为了印证有时候多协程并不一定会提高性能,这里以归并排序为例举三个例子:
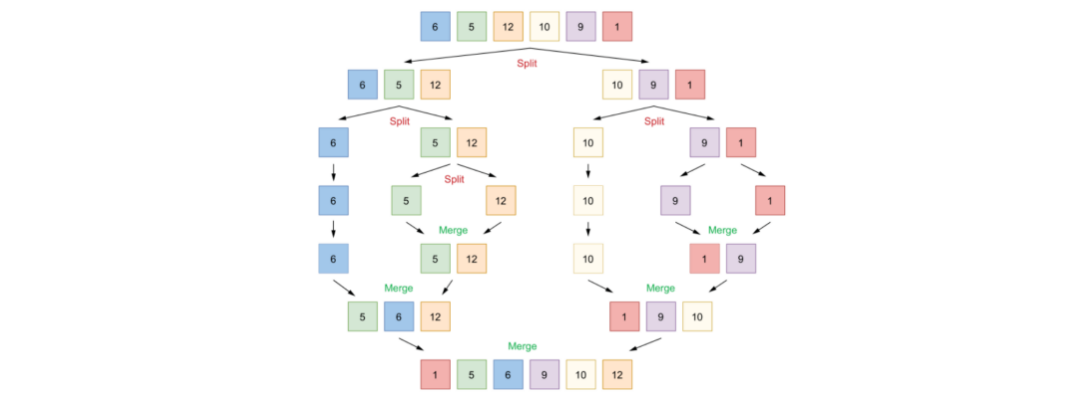
示例一:
func sequentialMergesort(s []int) {
if len(s) <= 1 {
return
}
middle := len(s) / 2
sequentialMergesort(s[:middle])
sequentialMergesort(s[middle:])
merge(s, middle)
}
func merge(s []int, middle int) {
// ...
}
示例二:
func sequentialMergesortV1(s []int) {
if len(s) <= 1 {
return
}
middle := len(s) / 2
var wg sync.WaitGroup()
wg.Add(2)
go func() {
defer wd.Done()
parallelMergesortV1(s[:middle])
}()
go func() {
defer wd.Done()
parallelMergesortV1(s[middle:])
}()
wg.Wait()
merge(s, middle)
}
示例三:
const max = 2048
func sequentialMergesortV2(s []int) {
if len(s) <= 1 {
return
}
if len(s) < max {
sequentialMergesort(s)
} else {
middle := len(s) / 2
var wg sync.WaitGroup()
wg.Add(2)
go func() {
defer wd.Done()
parallelMergesortV2(s[:middle])
}()
go func() {
defer wd.Done()
parallelMergesortV2(s[middle:])
}()
wg.Wait()
merge(s, middle)
}
}
由于创建协程和调度协程本身也有开销,第二种情况无论多少个元素都使用协程去进行并行排序,导致归并很少的元素也需要创建协程和调度,开销比排序更多,导致性能还比不上第一种顺序归并。
而在本台电脑上,经过调试第三种方式可以获得比第一种方式更优的性能,因为它在元素大于2048个的时候,选择并行排序,而少于则使用顺序排序。但是2048是一个魔法数,不同电脑上可能不同。这里这是为了证明,完全依赖并发/并行的机制,并不一定会提高性能,需要注意协程本身的开销。
8.3 分不清何时使用互斥锁或 channel(#57)
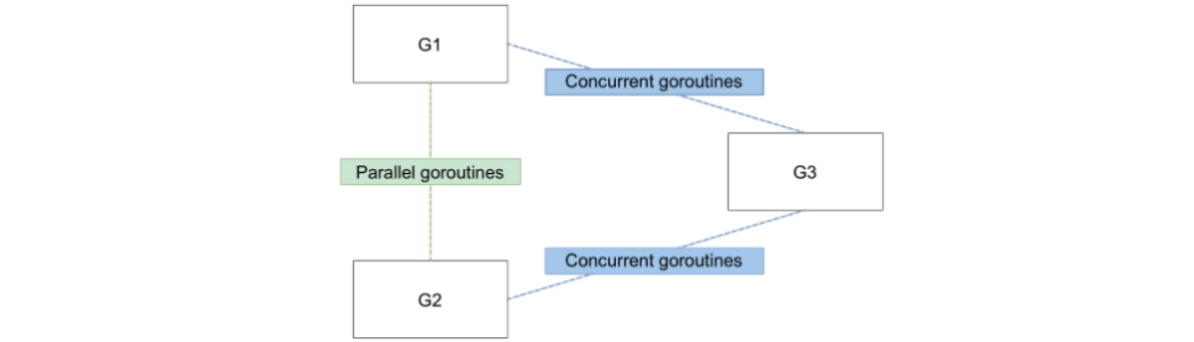
- mutex:针对 G1 和 G2 这种并行执行的两个协程,它们可能会针对同一个对象进行操作,比如切片。此时是一个发生资源竞争的场景,因此适合使用互斥锁。
- channel:而上游的 G1 或者 G2 中任何一个都可以在执行完自己逻辑之后,通知 G3 开始执行,或者传递给 G3 某些处理结果,此时使用 channel,因为 Go 推荐使用 channel 作为协程间通信的手段。
8.4 不理解竞态问题(#58)
🌟 数据竞争:多个协程同时访问一块内存地址,且至少有一次写操作。
假设有两个并发协程对 i 进行自增操作:
i := 0
go func() {
i++
}()
go func() {
i++
}()
因为 i++ 操作可以被分解为3个步骤:
- 读取 i 的值
- 对应值 + 1
- 将值写会 i
当并发执行两个协程的时候,i 的最终结果是无法预计的,可能为1,也可能为2。
修正方案一:
var i int64
go func() {
atomic.AddInt64(&i, 1)
}()
go func() {
atomic.AddInt64(&i, 1)
}()
使用 sync/atomic 包的原子运算,因为原子运算不能被打断,因此两个协程无法同时访问 i,因为客观上两个协程按顺序执行,因此最终的结果为2。
但是因为 Go 语言只为几种类型提供了原子运算,无法应对 slices、maps、structs。
修正方案二:
i := 0
mutex := sync.Mutex{}
go func() {
mutex.Lock()
i++
mutex.UnLock()
}()
go func() {
mutex.Lock()
i++
mutex.UnLock()
}()
此时被 mutex 包裹的部分,同一时刻只能允许一个协程访问。
修正方案三:
i := 0
ch := make(chan int)
go func() {
ch <- 1
}
go func() {
ch <- 1
}
i += <-ch
i += <-ch
使用阻塞的 channel,主协程必须从 ch 中读取两次才能执行结束,因此结果必然是2。
🌟 Go 语言的内存模型
我们使用 A < B 表示事件 A 发生在事件 B 之前。
i := 0
go func() {
i++
}()
因为创建协程发生在协程的执行,因此读取变量 i 并给 i + 1在这个例子中不会造成数据竞争。
i := 0
go func() {
i++
}()
fmt.Println(i)
协程的退出无法保证一定发生在其他事件之前,因此这个例子会发生数据竞争。
i := 0
ch := make(chan struct{})
go func() {
<-ch
fmt.Println(i)
}()
i++
ch <- struct{}{}
这个例子由于打印 i 之前,一定会执行 i++ 的操作,并且子协程等待主协程的 channel 的解除阻塞信号。
i := 0
ch := make(chan struct{})
go func() {
<-ch
fmt.Println(i)
}()
i++
close()
和上一个例子有点像,channel 在关闭事件发生在从 channel 中读取信号之前,因此不会发生数据竞争。
i := 0
ch := make(chan struct{}, 1)
go func() {
i = 1
<-ch
}()
ch <- struct{}{}
fmt.Println(i)
主协程向 channel 放入值的操作执行,并不能确保与子协程的执行事件顺序,因此会发生数据竞争。
i := 0
ch := make(chan struct{})
go func() {
i = 1
<-ch
}()
ch <- struct{}{}
fmt.Println(i)
主协程的存入 channel 的事件,必然发生在子协程从 channel 取出事件之前,因此不会发生数据竞争。
i := 0
ch := make(chan struct{})
go func() {
i = 1
<-ch
}()
ch <- struct{}{}
fmt.Println(i)
无无缓冲的 channel 确保在主协程执行打印事件之前,必须会执行 i = 1 的赋值操作,因此不会发生数据竞争。
8.5 不了解工作负载类型对并发性能的影响(#59)
🌟 工作负载执行时间受到下述条件影响:
- CPU 执行速度:例如执行归并排序,此时工作负载称作——CPU约束。
- IO 执行速度:对DB进行查询,此时工作负载称作——IO约束。
- 可用内存:此时工作负载称作——内存约束。
🌟 接下来通过一个场景讲解为何讨论并发性能,需要区分负载类型:假设有一个 read 函数,从循环中每次读取1024字节,然后将获得的内容传递给一个 task 函数执行,返回一个 int 值,并每次循环对这个 int 进行求和。
串行实现:
func read(r io.Reader) (int, error) {
count := 0
for {
b := make([]byte, 1024)
_, err := r.Read(b)
if err != nil {
if err == io.EOF {
break
}
return 0, err
}
count += task(b)
}
return count, nil
}
并发实现:Worker pooling pattern(工作池模式)是一种并发设计模式,用于管理一组固定数量的工作线程(worker threads)。这些工作线程从一个共享的工作队列中获取任务,并执行它们。这个模式的主要目的是提高并发性能,通过减少线程的创建和销毁,以及通过限制并发执行的任务数量来避免资源竞争。
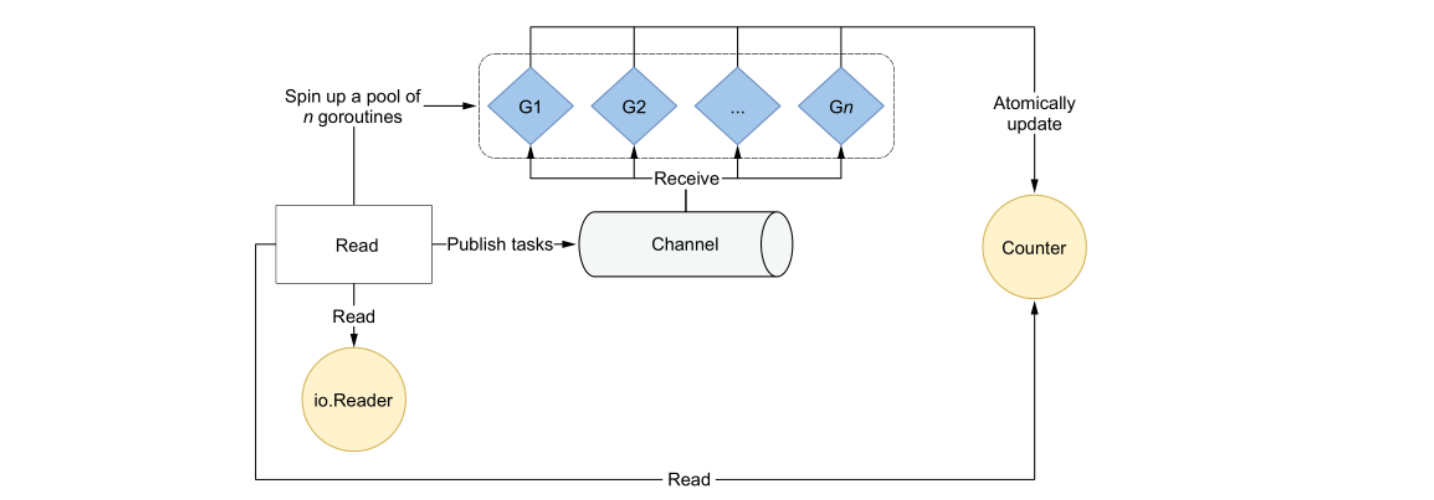
func read(r io.Reader) (int, error) {
var count int64
wg := sync.WaitGroup{}
var n = 10
ch := make(chan []byte, n)
wg.Add(n)
for i := 0; i < n; i++ {
go func() {
defer wg.Done()
for b := range ch {
v := tasg(b)
atomic.AddInt64(&count, int64(v))
}
}()
}
for {
b := make([]byte, 1024)
ch <- b
}
close(ch)
wg.Wait()
return int(count), nil
}
这个例子中,关键在于如何确定 n 的大小:
- 如果工作负载被 IO 约束:则 n 取决于外部系统,使得系统获得最大吞吐量的并发数。
- 如果工作负载被 CPU 约束:最佳实践是取决于 GOMAXPROOCS,这是一个变量存放系统允许分配给执行协程的最大线程数量,默认情况下,这个变量用于设置逻辑 CPU 的数量,因为理想状态下,只能允许最大线程数量的协程同时执行,
8.6 不懂得使用 Go contexts(#60)
🌟 A Context carries a deadline, a cancellation signal, and other values across API boundaries.
截止时间
- time.Duration(250ms)
- time.Time(2024-02-28 00:00:00 UTC)
当截止时间到达的时候,一个正在执行的行为将停止。(如IO请求,等待从 channel 中读取消息)
假设有一个雷达程序,每隔四秒钟,向其他应用提供坐标坐标信息,且只关心最新的坐标。
type publisher interface {
Publish(ctx context.Content, position flight.Position) error
}
type publishHandler struct {
pub publisher
}
func (h publishHandler) publishPosition(position flight.Position) error {
ctx, cancel := context.WithTimeout(context.Background(), 4*time.Second)
defer cancel()
return h.pub.Publish(ctx, position)
}
通过上述代码,创建一个过期时间4秒中的 context 上下文,则应用可以通过判断 ctx.Done() 判断这个上下文是否过期或者被取消,从而判断是否为4秒内的有效坐标。
cancel() 在 return 之前调用,则可以通过 cancel 方法关闭上下文,避免内存泄漏。
取消信号
func main() {
ctx. cancel := context.WithCancel(context.Background())
defer cacel()
go func() {
CreateFileWatcher(ctx, "foo.txt")
}()
}
在 main 方法执行完之前,通过调用 cancel 方法,将 ctx 的取消信号传递给 CreateFileWatcher() 函数。
上下文传递值
ctx := context.WithValue(context.Background(), "key", "value")
fmt.Println(ctx.Value("key"))
# value
key 和 value 是 any 类型的。
package provider
type key string
const myCustomKey key = "key"
func f(ctx context.Context) {
ctx = context.WithValue(ctx, myCustomKey, "foo")
// ...
}
为了避免两个不同的 package 对同一个 ctx 存入同样的 key 导致冲突,可以将 key 设置成不允许导出的类型。
一些用法:
- 在借助 ctx 在函数之间传递同一个 id,实现链路追踪。
- 借助 ctx 在多个中间件之间传递,存放处理信息。
type key string
const inValidHostKey key = "isValidHost"
func checkValid(next http.Handler) http.Handler {
return http.HandlerFunc(func(w http.ResponseWriter, r *http.Request) {
validHost := r.Host == "came"
ctx := context.WithValue(r.Context(), inValidHostKey, validHost)
next.ServeHTTP(w, r.WithContext(ctx))
})
}
checkValid 作为一个中间件,优先处理 http 请求,将处理结果存放在 ctx 中,传递给下一个处理步骤。
捕获 context 取消
context.Context 类型提供了一个 Done 方法,返回了一个接受关闭信号的 channel:<-chan struct{},触发条件如下:
- 如果 ctx 通过 context.WithCancel 创建,则可以通过 cancel 函数关闭。
- 如果 ctx 通过 context.WithDeadline 创建,当过期的时候 channel 关闭。
此外,context.Context 提供了一个 Err 方法,将返回导致 channel 关闭的原因,如果没有关闭,调用则返回 nil。
- 返回 context.Canceled error 如果 channel 被 cancel 方法关闭。
- 返回 context.DeadlineExceeded 如果达到 deadline 过期。
func handler(ctx context.Context, ch chan Message) error {
for {
select {
case msg := <-ch:
// Do something with msg
case <-ctx.Done():
return ctx.Err()
}
}
}
小结
你已完成《Go语言的100个错误》全书学习进度60%,欢迎追更。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 全程不用写代码,我用AI程序员写了一个飞机大战
· DeepSeek 开源周回顾「GitHub 热点速览」
· 记一次.NET内存居高不下排查解决与启示
· 物流快递公司核心技术能力-地址解析分单基础技术分享
· .NET10 - 预览版1新功能体验(一)