

Go语言的100个错误使用场景(11-20)|项目组织和数据类型
 我的愿景是以这套文章,在保持权威性的基础上,脱离对原文的依赖,对这100个场景进行篇幅合适的中文讲解。所涉内容较多,总计约 8w 字,这是该系列的第二篇文章,对应书中第11-20个错误场景。
我的愿景是以这套文章,在保持权威性的基础上,脱离对原文的依赖,对这100个场景进行篇幅合适的中文讲解。所涉内容较多,总计约 8w 字,这是该系列的第二篇文章,对应书中第11-20个错误场景。
前言
大家好,这里是白泽。《Go语言的100个错误以及如何避免》是最近朋友推荐我阅读的书籍,我初步浏览之后,大为惊喜。就像这书中第一章的标题说到的:“Go: Simple to learn but hard to master”,整本书通过分析100个错误使用 Go 语言的场景,带你深入理解 Go 语言。
我的愿景是以这套文章,在保持权威性的基础上,脱离对原文的依赖,对这100个场景进行篇幅合适的中文讲解。所涉内容较多,总计约 8w 字,这是该系列的第二篇文章,对应书中第11-20个错误场景。
🌟 当然,如果您是一位 Go 学习的新手,您可以在我开源的学习仓库中,找到针对《Go 程序设计语言》英文书籍的配套笔记,期待您的 star。
公众号【白泽talk】,聊天交流群:622383022,原书电子版可以加群获取。
前文链接:
2. Code and project organization
🌟 章节概述:
- 主流的代码组织方式
- 高效的抽象:接口和范型
- 构建项目的最佳实践
2.11 没有使用函数式选项模式(#11)
当设计一个 API 的时候,如何处理可选的配置项输入项是一个问题。下面先展示一些不好的例子。假设场景是创建一个 HTTP Server 服务,需要输入 IP 地址,端口等信息,但同时需要提供默认值,当不传入的时候也可以工作。
反例1(直接包含所有,配置参数):
func NewServer(addr string, port int) (*http.Server, error) {
// ...
}
直接在参数列表罗列各种参数,然后在内部依次处理,但是使用时必须传入所有参数。
反例2(Config 存放可选参数):
package httplib
type Config struct {
// 使用引用类型则未传入int则是nil,否则会和0值混淆
Port *int
}
func NewServer(addr string, cfg Confg) {
}
--------------------------------------------------
func main() {
port := 0
config := httplib.Config{
Port: &port,
}
httplib.NewServer("localhost", config)
}
这种方式允许用户将可选的配置参数通过 Config 存放,然后在 NewServer 方法的内部读取 Config 结构的字段去初始化,但是有两个问题:
- 随着可选参数的增多,NewServer 内的初始化逻辑将无限扩大。
- 如果用户 Config 整个都选择默认参数,则必须传入一个空的 Config{},使得用户需要对 Config 的用法提高理解成本。
httplib.NewServer("localhost", httplib.Config{})
反例3(建造者模式):
package httplib
type Config struct {
Port int
}
type ConfigBuilder sruct {
port *int
}
func (b *ConfigBuilder) Port(port int) *ConfigBuilder {
b.port = &port
return b
}
func (b *ConfigBuilder) Build() (Config, error) {
cfg := Config{}
if b.port == nil {
cfg.Port = defaultHTTPPort
} else {
if *b.port == 0 {
cfg.Port = randomPort()
} else if *b.port < 0 {
return Config{}, errors.New("port should be positive")
} else {
cfg.Port = *b.port
}
}
reutrn cfg, nil
}
func NewServer(addr string, config Config) (http.Server, error) {
// ...
}
----------------------------------------------
// 用法
func main() {
builder := httplib.ConfigBuilder{}
builder.Port(8080)
cfg, err := builder.Build()
if err != nil {
// ...
}
server, err := httplib.NewServer("localhost", cfg)
if err != nil {
// ...
}
}
这种写法下仍然有两个问题:
- 当可选参数希望使用默认值的时候,需要传递 nil(虽然已经比示例2进步了)。
server, err := httplib.NewServer("localhost", nil)
- 使用建造者模式链式创建过程中,只允许返回一个参数。一旦过程中发生错误,为了确保链式调用继续,即使需要错误处理也只能内聚的具体一个个方法内部,并不能将 err 传递出来。从而只能在 Builder 方法内验证可能发生的错误,使得 err 的处理成本大大提高。
cfg, err := builder.Foo("foo").Bar("bar").Build()
🌟 推荐方法(函数式配置选项模式),核心思想如下:
- 用一个不对外倒出的结构存放配置:options
- 每一个 option 是一个函数返回同一个结构:Option
代码展示:
package httplib
type options struct {
port *int
}
type Option func(options *options) error
func WithPort(port int) Option {
return func(options *options) error {
if port < 0 {
return errors.New("port should be positive")
}
options.port = &port
return nil
}
}
WithPort 接受一个 port 参数代表端口号,返回一个给 options 设置端口号的函数。这种形式的函数本质是一个匿名的闭包,持有外部的 options 配置集合。
func NewServer(addr string, opts ...Option) (*http.Server, error) {
// 初始化配置集合 options
var options options
for _, opt := range opts {
err := opt(&options)
if err != nil {
return nil, err
}
}
// 针对配置字段内容,添加验证需要的逻辑
var port int
if options.port == nil {
port = defaultHTTPPort
} else {
if *options.port == 0 {
port = randomPort()
} else {
port = *options.port
}
}
}
---------------------------------------------
// 用法
int main() {
server, err := httplib.NewServer("localhost", httplib.WithPort(8080), httplib.WithTimeout(time.second))
}
在 NewServer 内通过循环将 Option 的配置通过函数调用应用到 options 集合中,然后在编写针对 options 配置字段的验证逻辑,因为所有可选的 Option 都是外部传入的,NewServer 内需要为其进行二次校验。
🌟 这种方式也是 Go 的地道用法,在很多开源项目如 gRPC 中都大量使用。
2.12 项目缺乏组织(#12)
Go 语言是一个自由的语言,并不强制要求你选择某一种组织项目的模板,但是你需要为此行动。一个常见的模板展示:
/cmd # 主要的源代码位置,foo应用的入口文件位于 /cmd/foo/main.go
/internal # 内部使用的代码,不希望被导出使用
/pkg # 公共的代码,希望被导出
/test # 额外的外部测试代码和测试数据,Go的单测应该和源代码在同一个package内,但是集成测试等代码需要在这个目录
/configs # 配置文件
/docs # 设计文档和用户手册
/examples # 项目的使用示例代码
/api # API 文件,例如 Swagger,PB等
/web # Web应用拥有的资源文件,如静态文件等
/build # 打包和持续集成文件
/scripts # 各种脚本
/vendor # 当前项目的依赖文件
没有 src/ 目录因为它太泛用了,从而将其细分成了上述的各个目录。但这只是一个参考。
package 的组织方式:
/net
/http
client.go
...
/smtp
auth.go
...
addrselect.go
...
这是 Go 标准库中 net 包的组织结构,虽然 /http 位于 /net 之后,但是 net/http 这个包只能访问 net 包中被导出的内容(大写开头),使用子目录这种组织结构是为了使相关功能的包聚集在一起管理。
🌟 选择根据上下文进行组织项目还是分层组织项目都可以,只要你可以确保项目清晰:
-
按上下文:将代码分成 customer,constract 等等模块。
-
六边形架构(DDD):按功能进行分层。
🌟 最佳实践:
- 避免为时过早的 package 创建,允许演化,而不是一直遵守一开始的强制规划。
- 避免产生大量细粒度的 package,只包含个别文件。当然过大也是一个问题。
- 包的命名需要根据它提供的功能出发,用一个小写单词表示。
- 最小化包需要导出的内容,减少耦合,不确定就先不导出。
- 代码库的编码风格一致性。
2.13 创建公共设施包(#13)
一种常见的不好的实践:创建共享的包如 utils,common & base。
代码展示:
package util
func NewStringSet(...string) map[string]struct{} {
// ...
}
func SortStringSet(map[string]struct{}) []string {
// ...
}
-----------------------------------------
// 用法
func main() {
set := util.NewStringSet("a", "b", "c")
fmt.Println(util.SortStringSet(set))
}
工具包内的两个函数实现了创建 string 集合和针对 key 进行排序输出的函数,但是此处包命名为 util 则没有任何意义,完全可以替换成 common,shared...
代替方案:
package stringset
type Set map[string]struct{}
func New(...string) Set {...}
func (s Set) Sort() []string {...}
-----------------------------------------
// 用法
set := stringset.New("a", "b", "c")
fmt.Println(set.Sort())
用 stringset 代替 util 这个包的名称,使其更具表达性。同时将方法的前缀去除,用一个结构 Set 去接收 Sort 方法,将所有逻辑内聚在一个用途明确的 stringset 包中。调用侧使用也收到了明确约束,更加方便。
2.14 忽略包名的冲突(#14)
示例代码:
package redis
type Client struct {...}
func NewClient() *Client {...}
func (c *Client) Get(key string) (string, error) {...}
----------------------------------------------------
// 冲突的场景
func main() {
redis := redis.NewClient()
v, err := redis.Get("Foo")
}
在这种场景下,虽然 redis 变量现在是可以工作的,但它本质是变量,会被修改。但是 redis 包将无法再在代码中访问。
- 直观的解决方案:
func main() {
redisClient := redis.NewClient()
v, err := redisClient.Get("Foo")
}
修改变量名称,避免冲突。
- 更推荐的解决方案:
import redisapi "mylib/redis"
func main() {
redis := redis.NewClient()
v, err := redis.Get("Foo")
}
通过给 import 的 redis 包起别名的方式,避免与变量名的冲突,这是一种更推荐的做法。
📒 Tips:变量名的创建要避免与内置关键字或者函数同名
2.15 代码文档缺失(#15)
文档对于项目的开发者和使用者都十分重要,这里给出几个法则:
- 为每一个导出的对象都配备文档(通过注释)
// Customer is a customer representation
type Customer struct
// ID returns the customer identifier
func (c Customer) ID() string {...}
- 注释需要是一个完整的句子,以
.结尾。并且针对于描述对象的功能,而不是如何实现。确保提供足够的描述信息,使得用户无需阅读代码即可使用。 - 针对废弃的 API 使用注释:
// ComputePath returns the fastset path between two points
// Deprecated: This function uses a deprecated way to compute
// the fastest Path. Use ComputeFastestPath instead. func ComputePath () {}
func ComputePath() {}
- 为 package 添加文档:
// Package math provides basic constants and mathmatical functions
//
// This package ...
package math
第一行需要简洁,因为在文档中会展现:

2.16 不使用 code-linter(#16)
Linter 是一个自动化代码分析工具,可以帮助我们分析代码,找到潜在的错误。所以 Code Linter 也是持续集成中必不可少的一环。
go vet:Go 内置的静态代码检查工具。
go vet ./...
Linters:可以是外部工具,如 Golint、GolangCI-Lint、Staticcheck 等,它们通过外部安装,并提供更多的规则和功能。
通常情况下,建议同时使用 go vet 和 linters 以确保代码的质量和一致性。
示例代码:
func main() {
unusedVariable := 42 // 未使用的变量
}
运行 go vet ./...:
baize@baizedeMacBook-Air mistakes % go vet ./...
# mistake
vet: ./main.go:4:2: unusedVariable declared and not used
3. Data types
🌟 章节概述:
- 基本类型涉及的常见错误
- 掌握 slice 和 map 的基本概念,避免使用时产生 bug
- 值的比较
3.1 八进制产生的混乱局面(#17)
在 Go 当中,以0字面量开头的数值表示8进制,因此:
sum := 100 + 010 // 结果为108
但是8进制也有其发挥作用的场景,如赋予文件对应 Linux 系统的权限:
file, err := os.OpenFile("foo", os.O_RDONLY, 0644)
// 0644可以替换成0o644或者0O644
Go 语言中的不同进制表示:
- 二进制:使用 0b 或者 0B 为前缀
- 十六进制:使用0x 或者 0X 为前缀
- 虚数:使用 i 为后缀
Go 语言中支持用下划线作为数值的分隔符,提高可读性:
1_000_000_000 // 一百万
0b00_00_01 // 二进制也是可以的
3.2 忽略整型溢出(#18)
常见的整型类型:

整型溢出场景:
var counter int32 = math.MaxInt32
counter++
fmt.Printf("counter=%d\n", counter)
整个程序编译和运行不会报错,但是:
counter = -2147483648 // counter++ 导致int32溢出
计算机存储有符号整数用二进制表示:

针对有符号整数,第一位为符号位,0表示正数,1表示负数,全0表示0(约定)。
比如上述 int32 有符号整型最大值+1(左侧图片),得到右侧图片(是一个负数)。
计算时使用补码:正数的补码等于原码,负数的补码等于原码除去符号位外,所有位数取反,最后整体+1。
举例 int8 计算 8 + (-8) = 0 用补码的表示:
00001000 + 10001000 // 原码
00001000 + 11111000 = 1|00000000 // 补码,左侧0溢出,因为只有8位,得到0
如果希望手动检测整型溢出,这是一些模板代码:
func Inc32(counter int32) int32 {
if counter == math.MaxInt32 {
panic("int32 overflow")
}
return counter+1
}
func addInt(a, b int) int {
if a > math.MaxInt-b {
panic("int overflow")
}
return a + b
}
func MultiplInt(a, b int) int {
if a == 0 || b == 0 {
return 0
}
result := a * b
if a == 1 || b == 1 {
return result
}
if a == math.MinInt || b == math.MinInt {
panic("integer overflow")
}
if result/b != a {
panic("integer overflow")
}
return result
}
3.3 不理解浮点数(#19)
浮点数在计算机中的存储通常遵循 IEEE 754 标准,该标准定义了单精度和双精度浮点数的表示方式。
-
单精度浮点数(32位):
- 符号位:1位
- 指数位:8位
- 尾数位:23位
单精度浮点数的存储结构如下:
SEEEEEEE EMMMMMMM MMMMMMMM MMMMMMMM- S:符号位,表示正负。
- E:指数位,以偏移值(127)存储,范围为-126到+127。
- M:尾数位,23位精度。
具体数值表示为:(-1)^S * 1.M * 2^(E-127)
-
双精度浮点数(64位):
- 符号位:1位
- 指数位:11位
- 尾数位:52位
双精度浮点数的存储结构如下:
SEEEEEEE EEEEMMMM MMMMMMMM MMMMMMMM MMMMMMMM MMMMMMMM MMMMMMMM MMMMMMMM- S:符号位,表示正负。
- E:指数位,以偏移值(1023)存储,范围为-1022到+1023。
- M:尾数位,52位精度。
具体数值表示为:(-1)^S * 1.M * 2^(E-1023)
需要注意的是,由于二进制浮点数的特性,某些十进制小数可能无法精确表示,会有舍入误差。在编程中,特别是涉及金融等需要高精度的领域,需要小心处理浮点数的精度问题。
🌟 举例 1.0001 在单精度和双精度下的存储:
-
单精度(32位):
0 01111111 00010010000111101011100- 符号位:0(正数)
- 指数位:01111111(127的二进制表示,表示偏移值为0)
- 尾数位:00010010000111101011100(23位精度)
具体数值表示为:(-1)^0 * 1.00010010000111101011100 * 2^(0-127) ≈ 1.0001
-
双精度(64位):
0 01111111111 0001001000011110101110000101000111101011100010100011111- 符号位:0(正数)
- 指数位:01111111111(1023的二进制表示,表示偏移值为0)
- 尾数位:0001001000011110101110000101000111101011100010100011111(52位精度)
具体数值表示为:(-1)^0 * 1.0001001000011110101110000101000111101011100010100011111 * 2^(0-1023) ≈ 1.0001
🌟 浮点数的使用准则:
- 比较大小需要在合理精度范围内
- 运算时注意相似精度优先运算,减少精度波动
3.4 不理解切片长度和容量(#20)
Go 的切片本质上是一个结构体,包含一个指向数组的指针,以及两个变量记录长度和容量。
🌟 切片创建于扩容场景分析:
s := make([]int, 3, 6) // 创建长度为3容量为6的int类型的切片
s[1] = 1 // 赋值s[1]=1

访问切片大于长度范围的位置将触发 panic:
panic: runtime error: index out of range [4] with length 3
在 len 小于 cap 的时候,可以直接向切片添加元素:
s = append(s, 2)
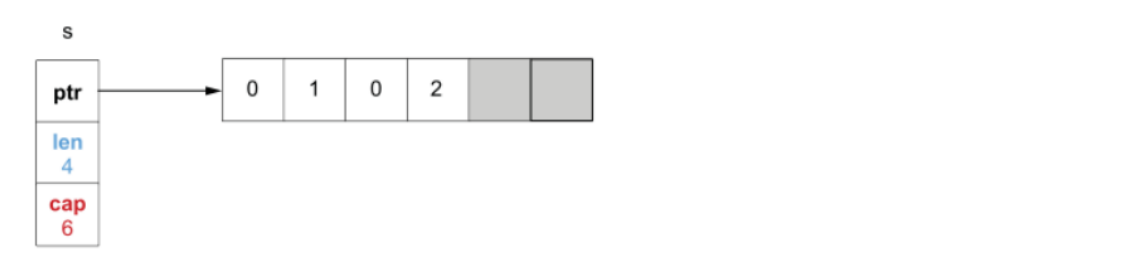
此时切片的 len 自动增加到4,因为容量足够,不会触发切片的扩容,但如果添加的元素数量超过 cap 的限制,则会触发切片的扩容:
s = append(s, 3, 4, 5)
fmt.Println(s) // 得到:[0 1 0 2 3 4 5]
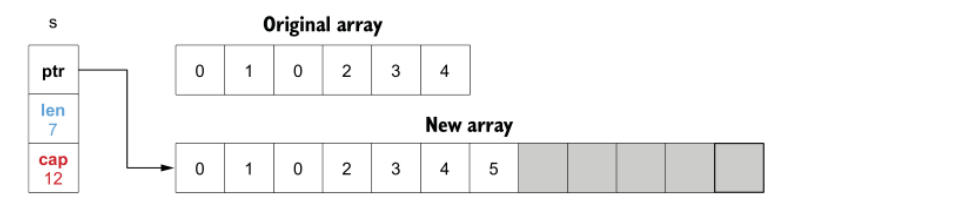
当添加5的时候,原底层数组的容量达到上限6,触发2倍扩容(创建新数组),拷贝原切片内容到新数组,并追加5。
大致的 Go 切片扩容规则:容量1024以下双倍扩容,以上扩容25%
原底层数组因为丢失了引用,如果在堆内存内,会被后续的 Go GC 回收(GC 相关场景将在全书后期讲解)。
🌟 切片截取场景分析:
s1 := make([]int, 3, 6) // 长度为3,容量为6
s2 := s1[1:3] // 从s1的索引1-3截取,左闭右开,此时s2的长度为2,容量是5
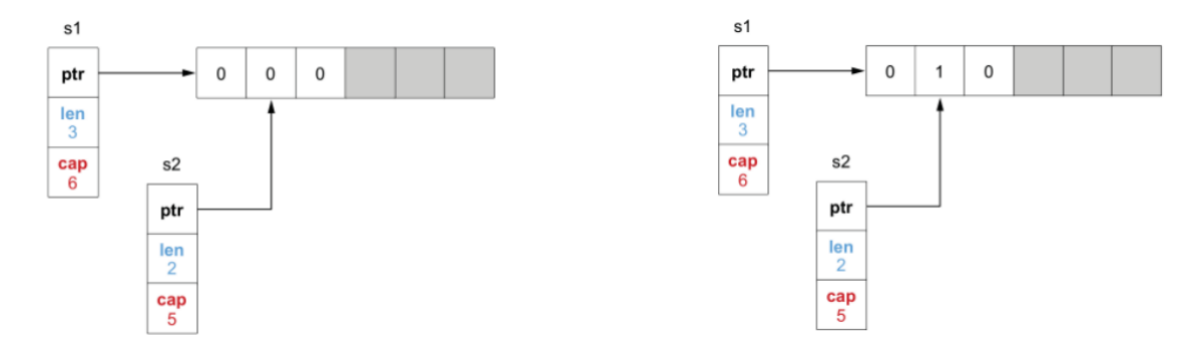
此时如果更新 s1[1] 或者 s2[0] 为1,则由于共享底层数组的原因,导致另一方可以读取到变更内容。
如果追加内容,则底层共享的数组追加2。此时 s2 的 len 变为3,但是 s1 的 len 依旧为3。

并且此时打印两个切片得到的内容如下:
s1 = [0 1 0], s2 = [1 0 2]
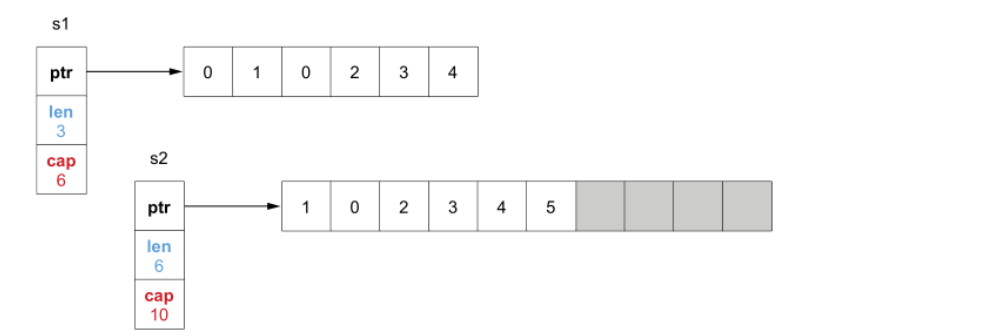
如果继续向 s2 追加元素直到 s2 的长度超过容量,则会触发扩容,创建新底层数组(二倍):
s2 = append(s2, 3)
s2 = append(s2, 4)
s2 = append(s2, 5)
小结
已完成全书学习进度20/100,再接再厉。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 全程不用写代码,我用AI程序员写了一个飞机大战
· DeepSeek 开源周回顾「GitHub 热点速览」
· 记一次.NET内存居高不下排查解决与启示
· 物流快递公司核心技术能力-地址解析分单基础技术分享
· .NET10 - 预览版1新功能体验(一)
2020-01-31 PAT天梯赛练习 L3-003 社交集群 (30分) DFS搜索