饮冰三年-人工智能-Pandas-80-Pandas 数据扩增与索引
上一篇:饮冰三年-人工智能-Pandas-78-Pandas 新增、统计、排序
数据准备可参考:饮冰三年-人工智能-Django淘宝拾遗-75-数据准备
一、索引
索引(index)是 Pandas 的重要工具,通过索引可以从 DataFame 中选择特定的行数和列数,这种选择数据的方式称为“子集选择”。在 Pandas 中,索引值也被称为标签(label)
索引作用:
- 方便数据查询
- 使用index可以提升性能
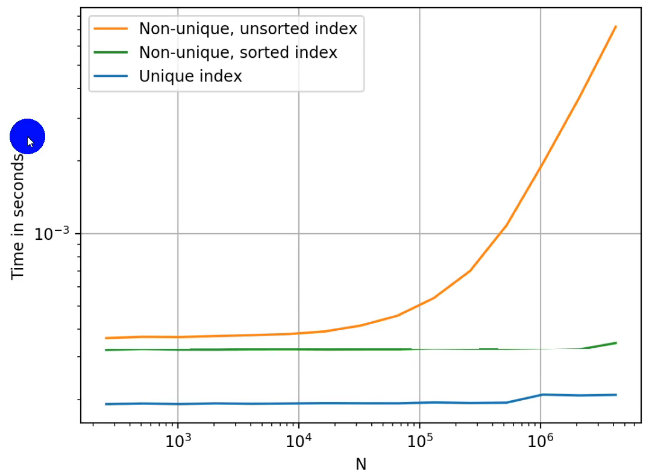
- 如果index是唯一的,Pandas会使用 哈希表优化,查询性能为O(1);
- 如果index不是唯一的,但是有序,Pandas会使用 二分查找算法,查询性能为O(logN);
- 如果index不是唯一的,而且无序,Pandas只能扫描全表,查询性能为O(N);
- 自动的数据对齐功能
- 更强大的数据结构支持
- Categoricall Index :基于分类的index,提升性能
- Multi Index :多维索引,用于group by 多维聚合后结果
- Datetime Index :时间类型索引,强大的日期和时间的方法支持
1.1 方便查询


from timeit import timeit import pandas as pd from api_service.pandas_ import get_data_from_db df = get_data_from_db() def query_easy(): print(df.head()) """ id gender ... add_time modify_time 0 7 0 ... 2022-02-11 17:16:52 2022-02-11 17:16:54 1 8 0 ... 2022-02-11 17:16:52 2022-02-11 17:16:54 2 9 0 ... 2022-02-11 17:16:52 2022-02-11 17:16:54 3 10 1 ... 2022-02-11 17:16:52 2022-02-11 17:16:54 4 11 1 ... 2022-02-11 17:16:52 2022-02-11 17:16:54 """ df.set_index("student_id", inplace=True, drop=False) # drop=False 让索引列还保持在 column print(df.head()) """ id gender ... add_time modify_time student_id ... 101 7 0 ... 2022-02-11 17:16:52 2022-02-11 17:16:54 102 8 0 ... 2022-02-11 17:16:52 2022-02-11 17:16:54 103 9 0 ... 2022-02-11 17:16:52 2022-02-11 17:16:54 114 10 1 ... 2022-02-11 17:16:52 2022-02-11 17:16:54 115 11 1 ... 2022-02-11 17:16:52 2022-02-11 17:16:54 """ # 方式一: 使用index的查询方法 df_easy = df.loc[101].head() print(df_easy) """ id gender ... add_time modify_time student_id ... 101 7 0 ... 2022-02-11 17:16:52 2022-02-11 17:16:54 101 13 0 ... 2022-02-11 17:16:52 2022-02-11 17:16:54 101 19 0 ... 2022-02-11 17:16:52 2022-02-11 17:16:54 101 25 0 ... 2022-02-11 17:16:52 2022-02-11 17:16:54 101 103 0 ... 2022-02-22 17:16:52 2022-02-22 17:16:54 """ # 方式二: 使用column的condition查询方法 df_hard = df.loc[df["student_id"] == 101].head() print(df_hard) """ id gender ... add_time modify_time student_id ... 101 7 0 ... 2022-02-11 17:16:52 2022-02-11 17:16:54 101 13 0 ... 2022-02-11 17:16:52 2022-02-11 17:16:54 101 19 0 ... 2022-02-11 17:16:52 2022-02-11 17:16:54 101 25 0 ... 2022-02-11 17:16:52 2022-02-11 17:16:54 101 103 0 ... 2022-02-22 17:16:52 2022-02-22 17:16:54 """
1.2 提升性能
1.3 数据对齐
def align_data(): s1 = pd.Series([1, 2, 3], index=list("abc")) s2 = pd.Series([2, 3, 4], index=list("bcd")) print(s1 + s2) """ a NaN b 4.0 c 6.0 d NaN dtype: float64 """
二、merge
pandas 的 Merge,相当于SQL的Join,将不同的表按key关联到一个表。官方文档
2.1 Merge语法
merge语法:DataFrame.merge(right, how='inner', on=None, left_on=None, right_on=None,left_index=False, right_index=False, sort=False, suffixes=('_x', '_y'), copy=True, indicator=False, validate=None)
right:要merge的 DataFrame 或者 有named的Series
how:join类型,‘left’, ‘right’, ‘outer’, ‘inner’
on:join的key,left和right都需要有这个key
left_on:left的df或者series的key
right_on:right的df或者seires的key
left_index,right_index:使用index而不是普通的column做join
suffixes:两个元素的后缀,如果列有重名,自动添加后缀,默认是(‘_x’, ‘_y’)
2.2 Merge时表之间的对应关系
one-to-one:一对一关系,关联的key都是唯一的
one-to-many:一对多关系,左边唯一key,右边不唯一key。 eg:查看专业开设了哪些课程
many-to-many:多对多关系,这种会涉及到第三张表。eg:查看学生各科成绩
import pandas as pd from django.utils.http import urlquote from sqlalchemy import create_engine from api_service.pandas_ import MYSQL_USER, MYSQL_PASSWORD, MYSQL_HOST, MYSQL_PORT, MYSQL_NAME def get_data_from_db(): """ 新版本的pandas库中con参数使用sqlalchemy库创建的create_engine对象 创建create_engine对象(格式类似于URL地址): """ create_engine(f'postgresql+psycopg2://') engine = create_engine( f'mysql+pymysql://{MYSQL_USER}:{urlquote(MYSQL_PASSWORD)}@{MYSQL_HOST}:{MYSQL_PORT}/{MYSQL_NAME}') profession = pd.read_sql("SELECT id,profession_name FROM tb_profession", engine) # 专业表, course = pd.read_sql("SELECT id,profession_id,subject_name FROM tb_course", engine) # 课程表, score = pd.read_sql("SELECT id,student_id,course_id,exams_date,score_total FROM tb_score", engine) # 成绩表 student = pd.read_sql("SELECT id,student_name FROM tb_student", engine) # 学生表 return profession, course, score, student def get_merge(): pd.set_option('display.width', 2000) pd.set_option('display.max_columns', None) profession, course, score, student = get_data_from_db() print(student.head(), profession.head(), course.head(), score.head(), ) ''' id student_name 0 101 小明-经 1 102 小红-经 2 103 小花-经 3 114 张三-经 4 115 李四-经 id profession_name 0 1 经济与管理 1 2 计算机 2 3 文学与历史 3 4 挖掘机 id profession_id subject_name 0 11 1 语文-经 1 12 1 数学-经 2 13 1 英语-经 3 14 1 经济学-经 4 21 2 语文-计 id student_id course_id exams_date score_total 0 7 101 11 2022-02-11 77.0 1 8 102 11 2022-02-11 60.0 2 9 103 11 2022-02-11 50.0 3 10 114 11 2022-02-11 100.0 4 11 115 11 2022-02-11 80.0 ''' # 01 查看专业开设了哪些课程(专业:课程《==》1:N) df_profession_course = pd.merge(profession, course, left_on="id", right_on="profession_id", how="inner") print(df_profession_course) ''' id_x profession_name id_y profession_id subject_name 0 1 经济与管理 11 1 语文-经 1 1 经济与管理 12 1 数学-经 2 1 经济与管理 13 1 英语-经 3 1 经济与管理 14 1 经济学-经 4 2 计算机 21 2 语文-计 5 2 计算机 22 2 数学-计 6 2 计算机 23 2 英语-计 7 2 计算机 24 2 计算机-计 8 3 文学与历史 31 3 语文-文 9 3 文学与历史 32 3 数学-文 10 3 文学与历史 33 3 英语-文 11 3 文学与历史 34 3 世界史-文 12 4 挖掘机 41 4 语文-挖 13 4 挖掘机 42 4 数学-挖 14 4 挖掘机 43 4 英语-挖 15 4 挖掘机 44 4 挖掘机实操-挖 ''' # 02 查看学生各科成绩(需要借助中间表:成绩表)(多对多) df_student_course_score = pd.merge(pd.merge(student, score, left_on="id", right_on="student_id", how="inner"), course, left_on="course_id", right_on="id", how="inner") print(df_student_course_score) ''' id_x student_name id_y student_id course_id exams_date score_total id profession_id subject_name 0 101 小明-经 7 101 11 2022-02-11 77.0 11 1 语文-经 1 101 小明-经 103 101 11 2022-02-22 77.0 11 1 语文-经 2 101 小明-经 199 101 11 2022-02-15 77.0 11 1 语文-经 3 101 小明-经 295 101 11 2022-03-08 77.0 11 1 语文-经 4 101 小明-经 391 101 11 2022-03-14 77.0 11 1 语文-经 .. ... ... ... ... ... ... ... .. ... ... 475 416 王五-挖 102 416 44 2022-02-11 90.0 44 4 挖掘机实操-挖 476 416 王五-挖 198 416 44 2022-02-22 90.0 44 4 挖掘机实操-挖 477 416 王五-挖 294 416 44 2022-02-15 90.0 44 4 挖掘机实操-挖 478 416 王五-挖 390 416 44 2022-03-08 90.0 44 4 挖掘机实操-挖 479 416 王五-挖 486 416 44 2022-03-14 90.0 44 4 挖掘机实操-挖 '''
字段重复会默认加后缀,也可以通过suffixes手动设置
# 字段重复会默认加后缀,也可以通过suffixes手动设置 df_student_course_score = pd.merge( pd.merge(student, score, left_on="id", right_on="student_id", how="inner", suffixes=('_学生', '_成绩')), course, left_on="course_id", right_on="id", how="inner", suffixes=('_成绩', '_课程')) print(df_student_course_score) """ id_学生 student_name id_成绩 student_id course_id exams_date score_total id profession_id subject_name 0 101 小明-经 7 101 11 2022-02-11 77.0 11 1 语文-经 """
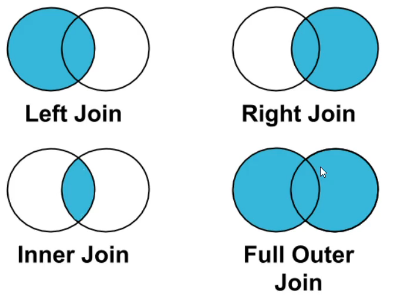
2.3 Merge时表之间的连接的区别
- inner join(内连接)默认的连接方式,当key两个表都存在的时候才作为返回表的key
- left join(左连接)左边所有的key都会作为返回表的key,而右边针对这一key没有对应值则填充Null
- right join(右连接)与左连接相反,右边的所有key都会出现在返回的表中,如果左边没有相应的则填充Null
- outer join(外连接)左右两边的key都会出现在返回表中,如果没有对应值,则填充Null
def join_way(): left = pd.DataFrame({ 'key': ['K0', 'K1', 'K2', 'K3'], 'A': ['A0', 'A1', 'A2', 'A3'], 'B': ['B0', 'B1', 'B2', 'B3'], }) right = pd.DataFrame({ 'key': ['K0', 'K1', 'K4', 'K5'], 'C': ['C0', 'C1', 'C4', 'C5'], 'D': ['D0', 'D1', 'D4', 'D5'], }) print(left) """ key A B 0 K0 A0 B0 1 K1 A1 B1 2 K2 A2 B2 3 K3 A3 B3 """ print(right) """ key C D 0 K0 C0 D0 1 K1 C1 D1 2 K4 C4 D4 3 K5 C5 D5 """ # inner join(内连接)默认的连接方式,当key两个表都存在的时候才作为返回表的key inner_join = pd.merge(left, right, how="inner") print(inner_join) """ key A B C D 0 K0 A0 B0 C0 D0 1 K1 A1 B1 C1 D1 """ # left join(左连接)左边所有的key都会作为返回表的key,而右边针对这一key没有对应值则填充Null left_join = pd.merge(left, right, how="left") print(left_join) """ key A B C D 0 K0 A0 B0 C0 D0 1 K1 A1 B1 C1 D1 2 K2 A2 B2 NaN NaN 3 K3 A3 B3 NaN NaN """ # right join(右连接)与左连接相反,右边的所有key都会出现在返回的表中,如果左边没有相应的则填充Null right_join = pd.merge(left, right, how="right") print(right_join) """ key A B C D 0 K0 A0 B0 C0 D0 1 K1 A1 B1 C1 D1 2 K4 NaN NaN C4 D4 3 K5 NaN NaN C5 D5 """ # outer join(外连接)左右两边的key都会出现在返回表中,如果没有对应值,则填充Null outer_join = pd.merge(left, right, how="outer") print(outer_join) """ key A B C D 0 K0 A0 B0 C0 D0 1 K1 A1 B1 C1 D1 2 K2 A2 B2 NaN NaN 3 K3 A3 B3 NaN NaN 4 K4 NaN NaN C4 D4 5 K5 NaN NaN C5 D5 """
三、concat
Pandas实现数据的合并concat
使用场景:批量合并相同格式的Excel、给DataFrame添加行或列
3.1 concat
concat语法(按照轴向合并pandas对象)
- pandas.concat(objs, axis=0, join='outer', ignore_index=False)
- objs:一个列表,内容可以是DataFrame或者Series,可以混合
- axis:默认是0代表按行合并,如果等于1代表按列合并
- join:合并的时候索引的对齐方式,默认是outer join,也可以是inner join
- ignore_index:是否忽略掉原来的数据索引
一言以蔽之:
使用某种合并方式(inner/outer)
沿着某个轴向(axis=0/1)
把多个Pandas对象(DataFrame/Series)合并成一个
def test_concat(): # 一、使用pandas.concat合并数据 df1 = pd.DataFrame({ 'A': ['A0', 'A1', 'A2', 'A3'], 'B': ['B0', 'B1', 'B2', 'B3'], 'C': ['C0', 'C1', 'C2', 'C3'], 'D': ['D0', 'D1', 'D2', 'D3'], 'E': ['E0', 'E1', 'E2', 'E3'], }) df2 = pd.DataFrame({ 'A': ['A4', 'A5', 'A6', 'A7'], 'B': ['B4', 'B5', 'B6', 'B7'], 'C': ['C4', 'C5', 'C6', 'C7'], 'D': ['D4', 'D5', 'D6', 'D7'], 'F': ['F4', 'F5', 'F6', 'F7'], }) print(df1) print(df2) """ A B C D E 0 A0 B0 C0 D0 E0 1 A1 B1 C1 D1 E1 2 A2 B2 C2 D2 E2 3 A3 B3 C3 D3 E3 A B C D F 0 A4 B4 C4 D4 F4 1 A5 B5 C5 D5 F5 2 A6 B6 C6 D6 F6 3 A7 B7 C7 D7 F7 """ # 1:默认的concat,参数为axis=0,join=outer,ignore_index=False df_result_1 = pd.concat([df1, df2]) print(df_result_1) """ A B C D E F 0 A0 B0 C0 D0 E0 NaN 1 A1 B1 C1 D1 E1 NaN 2 A2 B2 C2 D2 E2 NaN 3 A3 B3 C3 D3 E3 NaN 0 A4 B4 C4 D4 NaN F4 1 A5 B5 C5 D5 NaN F5 2 A6 B6 C6 D6 NaN F6 3 A7 B7 C7 D7 NaN F7 """ # 2:使用 ignore_index=False 忽略掉原来的数据索引 df_result_2 = pd.concat([df1, df2], ignore_index=True) print(df_result_2) """ A B C D E F 0 A0 B0 C0 D0 E0 NaN 1 A1 B1 C1 D1 E1 NaN 2 A2 B2 C2 D2 E2 NaN 3 A3 B3 C3 D3 E3 NaN 4 A4 B4 C4 D4 NaN F4 5 A5 B5 C5 D5 NaN F5 6 A6 B6 C6 D6 NaN F6 7 A7 B7 C7 D7 NaN F7 """ # 3:使用 join:过滤匹配不到的列 df_result_3 = pd.concat([df1, df2], join="inner", ignore_index=True) print(df_result_3) """ A B C D 0 A0 B0 C0 D0 1 A1 B1 C1 D1 2 A2 B2 C2 D2 3 A3 B3 C3 D3 0 A4 B4 C4 D4 1 A5 B5 C5 D5 2 A6 B6 C6 D6 3 A7 B7 C7 D7 """ # 4_1:添加一列Series s1 = pd.Series(list(range(4)), name="F") df_result_4_1 = pd.concat([df1, s1], axis=1) print(df_result_4_1) """ A B C D E F 0 A0 B0 C0 D0 E0 0 1 A1 B1 C1 D1 E1 1 2 A2 B2 C2 D2 E2 2 3 A3 B3 C3 D3 E3 3 """ # 4_2:添加多列Series s2 = df1.apply(lambda x: x["A"] + "_GG", axis=1) s2.name = "G" df_result_4_2 = pd.concat([s1, df1, s2], axis=1) # 列表顺序随意的 print(df_result_4_2) """ F A B C D E G 0 0 A0 B0 C0 D0 E0 A0_GG 1 1 A1 B1 C1 D1 E1 A1_GG 2 2 A2 B2 C2 D2 E2 A2_GG 3 3 A3 B3 C3 D3 E3 A3_GG """ df_result_4_3 = pd.concat([s1, s2], axis=1) # 列表内容可以只有Series print(df_result_4_3) """ F G 0 0 A0_GG 1 1 A1_GG 2 2 A2_GG 3 3 A3_GG """
3.2 append(不建议使用)
真香警告:FutureWarning: The frame.append method is deprecated and will be removed from pandas in a future version. Use pandas.concat instead.
大概意思是:后期不在支持append语法,建议使用concat。
append语法
- pandas.concat(objs, axis=0, join='outer', ignore_index=False)
- other:单个dataframe、series、dict,或者列表
- ignore_index:是否忽略掉原来的数据索引
def test_append(): # 二、使用pandas.concat合并数据 # FutureWarning: The frame.append method is deprecated and will be removed from pandas in a future version. Use pandas.concat instead df1 = pd.DataFrame([[1, 2], [3, 4]], columns=list('AB')) df2 = pd.DataFrame([[5, 6], [7, 8]], columns=list('AB')) # 1:给一个DataFrame添加一个DataFrame df_result_1 = df1.append(df2, ignore_index=True) # 建议用:df_result_1 = pd.concat([df1, df2], ignore_index=True) print(df_result_1) """ A B 0 1 2 1 3 4 2 5 6 3 7 8 """
四、分层索引(MultiIndex)
为什么要学习分层索引
- 分层索引:在一个轴向上拥有多个索引层级,可以表达更高纬度的形式
- 可以更方便的进行数据帅选,如果有序则性能更好
- groupby等操作结果,如果是多key,结果是分层索引,需要会使用
- ps:虽然MultiIndex有构造函数,但是一般不用
主要内容:
- 1:Series的分层索引MultiIndex
- 2:Series的多层索引怎样筛选数据?
- 3:DataFrame的分层索引MultiIndex
- 4:DataFrame的多层索引怎样筛选数据?
4.1 Series的分层索引MultiIndex
def series_multi_index_score(): # 一、Series的分层索引MultiIndex # 获取数据 df = get_data_from_db() df = df[["id", "profession_name", "course_name", "score_total"]] print(df) """ id profession_name course_name score_total 0 7 经济与管理 语文-经 77.0 1 8 经济与管理 语文-经 60.0 2 9 经济与管理 语文-经 50.0 3 10 经济与管理 语文-经 100.0 4 11 经济与管理 语文-经 80.0 .. ... ... ... ... 475 482 挖掘机 挖掘机实操-挖 60.0 """ # 1:首先需要利用.groupby(多个字段列表) 就会建立一个多维索引的结构,即先按一个字段分,再按另一个字段分 data_1 = df.groupby(['profession_name', 'course_name'])["score_total"].mean() print(data_1) # 在多维索引中,空白表示上面的值,例如索引列。 """ profession_name course_name 挖掘机 挖掘机实操-挖 100.0 数学-挖 90.0 英语-挖 100.0 语文-挖 100.0 文学与历史 世界史-文 100.0 数学-文 90.0 英语-文 100.0 语文-文 100.0 经济与管理 数学-经 90.0 经济学-经 100.0 英语-经 100.0 语文-经 100.0 ....... """ print(data_1.index) # 我们来看下series的分层索引。列表[(一级索引,二级索引)] """ MultiIndex([( '挖掘机', '挖掘机实操-挖'), ( '挖掘机', '数学-挖'), ( '挖掘机', '英语-挖'), ( '挖掘机', '语文-挖'), ('文学与历史', '世界史-文'), ...... """ print(data_1.unstack()) # unstack 把二级索引变成列 """ course_name 世界史-文 挖掘机实操-挖 ... 语文-经 语文-计 profession_name ... 挖掘机 NaN 57.333333 ... NaN NaN 文学与历史 57.333333 NaN ... NaN NaN 经济与管理 NaN NaN ... 76.166667 NaN 计算机 NaN NaN ... NaN 76.166667 """ print(data_1.reset_index()) # reset_index 把索引变成列 """ profession_name course_name score_total 0 挖掘机 挖掘机实操-挖 57.333333 1 挖掘机 数学-挖 66.166667 2 挖掘机 英语-挖 71.346154 3 挖掘机 语文-挖 76.166667 4 文学与历史 世界史-文 57.333333 5 文学与历史 数学-文 66.166667 6 文学与历史 英语-文 69.833333 7 文学与历史 语文-文 76.166667 ...... """ # 二、Series的分层索引MultiIndex怎样筛选数据 # 1:当Series拥有多层索引后使用.loc[‘字段’]可以取出整个, print(data_1.loc["挖掘机"]) """ course_name 挖掘机实操-挖 57.333333 数学-挖 66.166667 英语-挖 71.346154 语文-挖 76.166667 """ # 可以使用元组的形式筛选 print(data_1.loc[("挖掘机", "语文-挖")]) """ 76.16666666666667 """ # 可以只筛选第二层索引 print(data_1.loc[:, "语文-挖"]) """ profession_name 挖掘机 76.166667 """
4.2 DataFrame的分层索引MultiIndex
# 一、DataFrame的分层索引MultiIndex # 获取数据 df = get_data_from_db() data_1 = df[["id", "profession_name", "course_name", "exams_date", "score_total"]] data_1["exams_date"] = data_1["exams_date"].apply(str) print(data_1) """ id profession_name course_name exams_version score_total 0 7 经济与管理 语文-经 2022-02-11 77.0 1 8 经济与管理 语文-经 2022-02-11 60.0 2 9 经济与管理 语文-经 2022-02-11 50.0 3 10 经济与管理 语文-经 2022-02-11 100.0 4 11 经济与管理 语文-经 2022-02-11 80.0 .. ... ... ... ... ... 475 482 挖掘机 挖掘机实操-挖 2022-03-14 60.0 """ # 1:利用set_index 设置分层索引 data_1.set_index(['profession_name', 'exams_date'], inplace=True) print(data_1.index) # 在多维索引中,空白表示上面的值,例如索引列。 """ MultiIndex([('经济与管理', 2022-02-11), ('经济与管理', 2022-02-11), ('经济与管理', 2022-02-11), ... ( '挖掘机', 2022-03-14), ( '挖掘机', 2022-03-14), ( '挖掘机', 2022-03-14)], names=['profession_name', 'exams_date'], length=480) """ data_2 = data_1.copy() data_2.sort_index(inplace=True) print(data_2) """ id course_name score_total profession_name exams_date 挖掘机 2022-02-11 79 语文-挖 77.0 2022-02-11 80 语文-挖 60.0 2022-02-11 81 语文-挖 50.0 2022-02-11 82 语文-挖 100.0 2022-02-11 83 语文-挖 80.0 ... ... ... ... 计算机 2022-03-14 434 计算机-计 60.0 2022-03-14 435 计算机-计 9.0 2022-03-14 436 计算机-计 100.0 """ # 二、DataFrame的分层索引MultiIndex怎样筛选数据 # 在选择数据时: # 元组(key1,key2)代表筛选多层索引,其中key1是索引第一级,key2是第二级,比如key1=计算机, key2=2022-03-14 # 列表[key1,key2]代表同一层的多个KEY,其中key1和key2是并列的同级索引,比如key1=计算机, key2=挖掘机 print(data_2.loc["计算机"]) # 通过列表,一级索引 """ exams_date 2022-02-11 31 语文-计 77.0 2022-02-11 32 语文-计 60.0 2022-02-11 33 语文-计 50.0 2022-02-11 34 语文-计 100.0 2022-02-11 35 语文-计 80.0 ... ... ... ... 2022-03-14 434 计算机-计 60.0 """ print(data_2.loc[("计算机", '2022-02-11'), :]) # 通过元祖,(一级索引,二级索引),: 冒号表示选择所有列 """ id course_name score_total profession_name exams_date 计算机 2022-02-11 31 语文-计 77.0 2022-02-11 32 语文-计 60.0 2022-02-11 33 语文-计 50.0 2022-02-11 34 语文-计 100.0 2022-02-11 35 语文-计 80.0 2022-02-11 36 语文-计 90.0 2022-02-11 37 数学-计 69.0 ... ... ... """ print(data_2.loc[("计算机", '2022-02-11'), 'score_total']) # 通过元祖,(一级索引,二级索引),可以指明某些列 """ profession_name exams_date 计算机 2022-02-11 77.0 2022-02-11 60.0 2022-02-11 50.0 2022-02-11 100.0 2022-02-11 80.0 ... ... ... """ print(data_2.loc[["计算机", "挖掘机"], :]) # 通过列表,(一级索引=计算机,一级索引=挖掘机),: 冒号表示选择所有列 """ id course_name score_total profession_name exams_date 计算机 2022-02-11 31 语文-计 77.0 2022-02-11 32 语文-计 60.0 2022-02-11 33 语文-计 50.0 2022-02-11 34 语文-计 100.0 2022-02-11 35 语文-计 80.0 ... ... ... ... 挖掘机 2022-03-14 482 挖掘机实操-挖 60.0 2022-03-14 483 挖掘机实操-挖 9.0 2022-03-14 484 挖掘机实操-挖 100.0 2022-03-14 485 挖掘机实操-挖 80.0 """ print(data_2.loc[(["计算机", "挖掘机"], ['2022-02-11', '2022-03-14']), "score_total"]) # 通过列表 """ profession_name exams_date 计算机 2022-02-11 77.0 2022-02-11 60.0 2022-02-11 50.0 2022-02-11 100.0 2022-02-11 80.0 ... 挖掘机 2022-03-14 60.0 2022-03-14 9.0 2022-03-14 100.0 2022-03-14 80.0 2022-03-14 90.0 """ print(data_2.loc[(slice(None), ['2022-02-11', '2022-03-14']), :]) # slice(None)代表筛选这一索引的所有内容 """ id course_name score_total profession_name exams_date 挖掘机 2022-02-11 79 语文-挖 77.0 2022-02-11 80 语文-挖 60.0 2022-02-11 81 语文-挖 50.0 2022-02-11 82 语文-挖 100.0 2022-02-11 83 语文-挖 80.0 ... ... ... ... 计算机 2022-03-14 434 计算机-计 60.0 2022-03-14 435 计算机-计 9.0 2022-03-14 436 计算机-计 100.0 2022-03-14 437 计算机-计 80.0 2022-03-14 438 计算机-计 90.0 """ # print(data_2.reset_index()) # reset_index 把索引变成列

 浙公网安备 33010602011771号
浙公网安备 33010602011771号