DirectX11 GerstnerWaves模拟(计算着色器)
DirectX11 GerstnerWaves模拟(计算着色器)
计算着色器(Computer Shader)中可以使用线程组并行进行计算,很适合用来计算波浪(水面、地形等)的顶点数据。在学习完DirectX11 With Windows 计算着色器:波浪(水波)后,自己动手设计了GerstnerWavesRender来模拟GerstnerWaves。此外,还学习了ImGui并在项目中使用,可以通过ImGui窗口来调整波浪参数。
GerstnerWaves
在《GPU精粹1:实时图形编程的技术、技巧和技艺》中提供了Gerstner波函数:
P(x,y,t)=
(
x+∑(QiAi × Di.x × cos(ωiDi·(x,y)+ψit)),
y+∑(QiAi × Di.y × cos(ωiDi·(x,y)+ψit)),
∑(Ai × sin(ωiDi·(x,y)+ψit))
)
其中,Q是控制波陡度的参数。对于单个波,Q=0是正常的正弦波Q=1/(ωA)是尖峰的波形。当Q较大时,会在波峰形成环。在项目中,Q为控制波峰的参数,范围为0~1,使用Qi = Q / (ωiAi × numWaves)来计算分波的Qi。
ω是波传播的角频率,可由波长L计算得到:
也可以简单的使用:ω = 2PI / L 计算 。
A是振幅,振幅决定波浪的峰和谷的高度。我们可以将振幅和波长与外界条件(如天气、风速等)关联,振幅和波长之比也要满足一定条件,在本项目中不作考虑。
D为波的传播方向,它是一个float2l类型的数,x量和y量分别表示x方向和y方向。(在DirectX中应为X方向和Z方向)
除以上参数外,公式中还有ψ和t。ψ是由公式:
Speed是波的传播速度,t是传播时间,可以用程序的执行时间代替,也可以另行定义。
书中也提供了法线的计算公式:
N=(
-∑( Di.x × WA × C()),
-∑( Di.y × WA × C()),
1-∑( Qi × WA × S())
)
其中,
HLSL
在上一部分了解到,我们需要获得每个波的L、A、Q、S、D.x、D.y和系统的时间t。此外,为了在计算着色器中计算index,我们还需要知道列线程组的数目。知道了需要,我们就可以在GerstnerWaves.hlsli中定义结构体:
struct GerstnerWave { float g_WaveL; // 波长 float g_WaveA; // 振幅 float g_WaveSpeed; // 速度 float g_WaveQ; // 陡度 float2 g_WaveD; // 方向 float2 g_pad; // 打包 };
我们要计算顶点的数据,需要在GerstnerWaves.hlsli中定义顶点的结构体:
struct VertexPosNormalTex { float3 PosL : POSITION; float3 NormalL : NORMAL; float2 Tex : TEXCOORD; };
整个GerstnerWaves.hlsli如下:
//GerstnerWaves.hlsli #define GroundThreadSize 16 #define WaveCount 3 static const float PI = 3.14159267f; static const float g = 9.8f; struct GerstnerWave { float g_WaveL; // 波长 float g_WaveA; // 振幅 float g_WaveSpeed; // 速度 float g_WaveQ; // 陡度 float2 g_WaveD; // 方向 float2 g_pad; // 打包 }; struct VertexPosNormalTex { float3 PosL : POSITION; float3 NormalL : NORMAL; float2 Tex : TEXCOORD; }; RWStructuredBuffer<VertexPosNormalTex> g_Input : register(u0); RWStructuredBuffer<VertexPosNormalTex> g_Output : register(u1); // 用于更新模拟 cbuffer cbUpdateSettings : register(b0) { GerstnerWave g_gerstnerData[WaveCount]; // 几个波叠加 float g_TotalTime; // 总时长 float g_GroundCountX; // X方向上的线程团数 float2 g_Pad; }
RWStructuredBuffer是可读写的结构体缓冲区类型的无序访问视图,我们可以通过g_Input来读取顶点数据,通过计算后将新数据写进g_Output。关于各种着色器资源的特点以及用法,可以参考深入了解与使用缓冲区资源。
以下是三个波的叠加的GerstnerWaves计算着色器:
// GerstnerWaves_CS.hlsl #include "GerstnerWaves.hlsli" [numthreads(GroundThreadSize, GroundThreadSize, 1)] void CS(uint3 DTid : SV_DispatchThreadID) { int index = DTid.x + DTid.y * g_GroundCountX * GroundThreadSize; float posx = g_Input[index].PosL.x; float posy = g_Input[index].PosL.z; float3 Gpos = { posx, g_Input[index].PosL.y, posy }; float3 Gnormal = { 0.0f, 0.0f, 0.0f }; // GerstnerWaves计算 for (int i = 0; i < WaveCount; i++) { // 计算顶点坐标 float w = sqrt(g * 2 * PI / g_gerstnerData[i].g_WaveL); //float w = 2 * PI / g_WaveL; float psi = g_gerstnerData[i].g_WaveSpeed * w; // g_WaveQ 相同, 使用以下公式计数分波的Qi float Q = g_gerstnerData[i].g_WaveQ / (w * g_gerstnerData[i].g_WaveA * WaveCount); float phase = w * g_gerstnerData[i].g_WaveD.x * posx + w * g_gerstnerData[i].g_WaveD.y * posy + psi * g_TotalTime; float sinp, cosp; sincos(phase, sinp, cosp); Gpos.x += Q * g_gerstnerData[i].g_WaveA * g_gerstnerData[i].g_WaveD.x * cosp; Gpos.z += Q * g_gerstnerData[i].g_WaveA * g_gerstnerData[i].g_WaveD.y * cosp; Gpos.y += g_gerstnerData[i].g_WaveA * sinp; // 计算法向量 float WA = w * g_gerstnerData[i].g_WaveA; float th = w * (g_gerstnerData[i].g_WaveD.x * Gpos.x + g_gerstnerData[i].g_WaveD.y * Gpos.z) + psi * g_TotalTime; float sint, cost; sincos(th, sint, cost); Gnormal.x = -g_gerstnerData[i].g_WaveD.x * WA * cost; Gnormal.z = -g_gerstnerData[i].g_WaveD.y * WA * cost; Gnormal.y = -Q * WA * sint; } Gnormal.y += 1; Gnormal = normalize(Gnormal); // 标准化 // 保存 g_Output[index].PosL = float3(Gpos); g_Output[index].NormalL = float3(Gnormal); g_Output[index].Tex = g_Input[index].Tex; }
GerstnerWavesRender
GerstnerWavesRender的设计如下图:
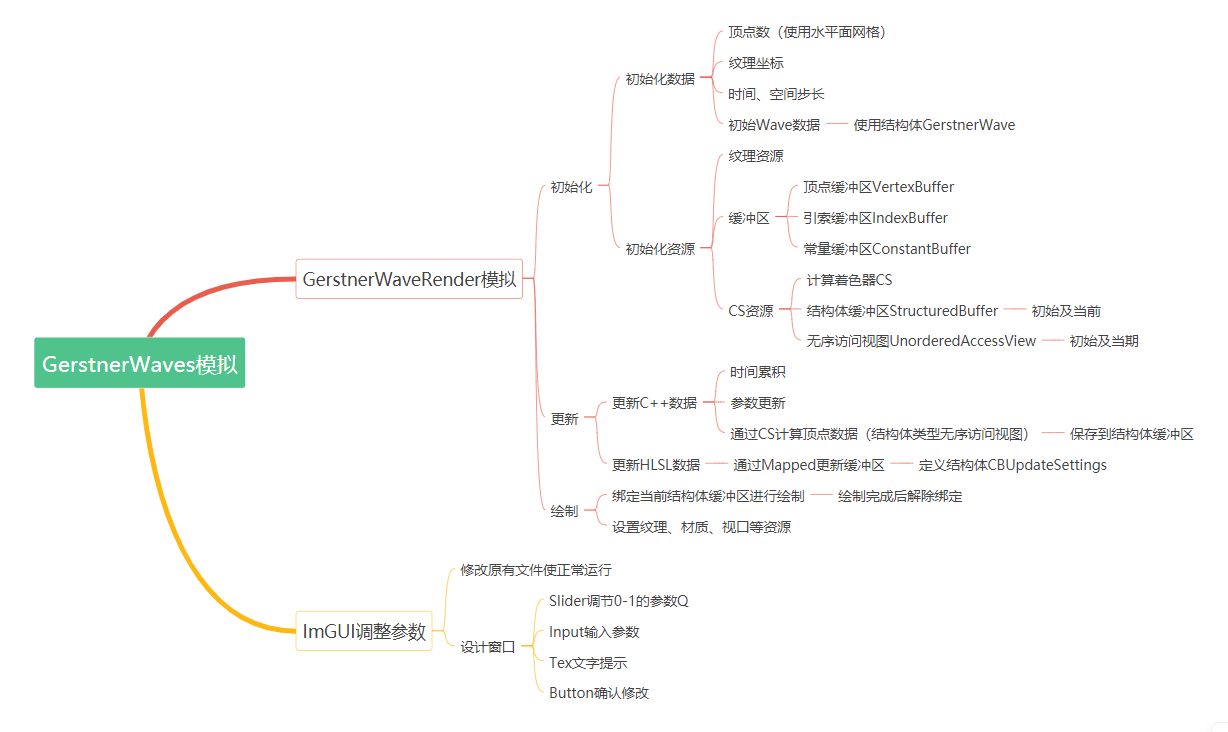
从第一支初始化开始看,GerstnerWavesRender中有较多成员数据:
//********** // 数据类型 // UINT m_NumRows = 0;// 顶点行数 UINT m_NumCols = 0;// 顶点列数 UINT m_VertexCount = 0;// 顶点数目 UINT m_IndexCount = 0;// 索引数目 Transform m_Transform = {};// 水面变换 DirectX::XMFLOAT2 m_TexOffset = {};// 纹理坐标偏移 float m_TexU = 0.0f;// 纹理坐标U方向最大值 float m_TexV = 0.0f;// 纹理坐标V方向最大值 Material m_Material = {};// 水面材质 GerstnerWave m_gerstnerwaveData[3] = {}; float m_TimeStep = 0.0f;// 时间步长 float m_SpatialStep = 0.0f;// 空间步长 float m_AccumulateTime = 0.0f;// 累积时间 float m_TotalTime = 0.0f; // 总时长 //********** // 资源类型 // ComPtr<ID3D11Buffer> m_pCurrVertex; // 保存当前模拟结果的顶点 ComPtr<ID3D11UnorderedAccessView> m_pCurrVertexUAV; // 缓存当前模拟结果的顶点 无序访问视图 ComPtr<ID3D11Buffer> m_pVertex; // 初始顶点 缓冲区 ComPtr<ID3D11UnorderedAccessView> m_pVertexUAV; // 初始顶点 无序访问视图 ComPtr<ID3D11Buffer> m_pVertexBuffer;// 顶点缓冲区 ComPtr<ID3D11Buffer> m_pIndexBuffer;// 索引缓冲区 ComPtr<ID3D11Buffer> m_pConstantBuffer;// 常量缓冲区 ComPtr<ID3D11Buffer> m_pTempBuffer;// 用于顶点数据拷贝的缓冲区 ComPtr<ID3D11ComputeShader> m_pWavesUpdateCS;// 用于计算模拟结果的着色器 ComPtr<ID3D11ShaderResourceView> m_pTextureDiffuse;// 水面纹理
其中数据类型的成员用来保存网格的顶点数、引索数、纹理最大值,各类时间,空间、时间步长,以及三个Gerstner波的参数。资源类型的成员用来保存网格的顶点、引索,在绘制时作为HLSL的资源,其中m_pCurrVertexUAV、m_pVertexUAV是计算着色器m_pWavesUpdateCS输入和输出。
我们还要在类中定义与HLSL中对应的储存波参数的结构体:
struct GerstnerWave { float WaveL; // 波长 float WaveA; // 振幅 float WaveSpeed; // 速度 float WaveQ; // 陡度 DirectX::XMFLOAT2 WaveD; // 方向 DirectX::XMFLOAT2 pad; // 打包 };
// 以及与常量缓冲区修改相关的m_CBUpdateSettings: struct { GerstnerWave gerstnerData[3]; float TotalTime; // 总时长 float GroundCountX; // X方向上的线程团数 DirectX::XMFLOAT2 Pad; }
顶点缓冲区、引索缓冲区、常量缓冲区、计算着色器的创建比较常规,下面讲一讲结构化缓冲区和无序访问视图的创建。
我们想要在CS中使用存有顶点的资源,就需要使用结构化缓冲区以及对应的无序访问视图
// 创建GPU结构体缓冲区 hr = CreateStructuredBuffer(device, meshData.vertexVec.data(), (UINT)meshData.vertexVec.size() * sizeof(VertexPosNormalTex), (UINT)sizeof(VertexPosNormalTex), m_pCurrVertex.GetAddressOf(), false, true ); // 实际调用了 d3dDevice->CreateBuffer(&bufferDesc, &initData, buffer); // 具体可查看文档
创建无序访问视图需要先填充D3D11_UNORDERED_ACCESS_VIEW_DESC:
D3D11_UNORDERED_ACCESS_VIEW_DESC uavDesc; uavDesc.ViewDimension = D3D11_UAV_DIMENSION_BUFFER; uavDesc.Format = DXGI_FORMAT_UNKNOWN; uavDesc.Buffer.FirstElement = 0; uavDesc.Buffer.NumElements = (UINT)meshData.vertexVec.size(); uavDesc.Buffer.Flags = 0;
再调用:
// 创建无序访问视图 hr = device->CreateUnorderedAccessView(m_pCurrVertex.Get(), &uavDesc, m_pCurrVertexUAV.GetAddressOf());
更新
更新分为两步:
// 设置数据 void SetData(GerstnerWave* gerstnerData); // 更新 void Update(ID3D11DeviceContext* deviceContext, float t);
先通过SetData设置波的参数,再使用Update进行时间上的更新:
void GerstnerWavesRender::SetData(GerstnerWave* gerstnerData) { for (int i = 0; i < sizeof(m_gerstnerwaveData) / sizeof(GerstnerWave); ++i) { m_gerstnerwaveData[i] = *(gerstnerData + i); } } void GerstnerWavesRender::Update(ID3D11DeviceContext* deviceContext, float t) { // 时间累加 m_AccumulateTime += t; m_TotalTime += t; // 纹理位移 for (int i = 0; i < sizeof(m_gerstnerwaveData) / sizeof(GerstnerWave); ++i) { float DirSide = sqrt(m_gerstnerwaveData[i].WaveD.x * m_gerstnerwaveData[i].WaveD.x + m_gerstnerwaveData[i].WaveD.y * m_gerstnerwaveData[i].WaveD.y); m_TexOffset.x -= m_gerstnerwaveData[i].WaveSpeed * m_gerstnerwaveData[i].WaveD.x / DirSide * t * 0.1f; m_TexOffset.y -= m_gerstnerwaveData[i].WaveSpeed * m_gerstnerwaveData[i].WaveD.y / DirSide * t * 0.1f; } // 在累积时间大于时间步长时更新 if (m_AccumulateTime > m_TimeStep) { // 更新常量缓冲区 D3D11_MAPPED_SUBRESOURCE data; m_CBUpdateSettings.gerstnerData[0] = m_gerstnerwaveData[0]; m_CBUpdateSettings.gerstnerData[1] = m_gerstnerwaveData[1]; m_CBUpdateSettings.gerstnerData[2] = m_gerstnerwaveData[2]; m_CBUpdateSettings.TotalTime = m_TotalTime; m_CBUpdateSettings.GroundCountX = m_NumCols / 16; deviceContext->Map(m_pConstantBuffer.Get(), 0, D3D11_MAP_WRITE_DISCARD, 0, &data); memcpy_s(data.pData, sizeof m_CBUpdateSettings, &m_CBUpdateSettings, sizeof m_CBUpdateSettings); deviceContext->Unmap(m_pConstantBuffer.Get(), 0); // 设置计算资源 deviceContext->CSSetShader(m_pWavesUpdateCS.Get(), nullptr, 0); deviceContext->CSSetConstantBuffers(0, 1, m_pConstantBuffer.GetAddressOf()); ID3D11UnorderedAccessView* pUAVs[2] = { m_pVertexUAV.Get() ,m_pCurrVertexUAV.Get() }; deviceContext->CSSetUnorderedAccessViews(0, 2, pUAVs, nullptr); // 开始调度 使用16 * 16 * 1的线程组 deviceContext->Dispatch(m_NumCols / 16, m_NumRows / 16, 1); // 清除绑定 pUAVs[0] = pUAVs[1] = nullptr; deviceContext->CSSetUnorderedAccessViews(0, 2, pUAVs, nullptr); // 数据copy // 读取 deviceContext->CopyResource(m_pTempBuffer.Get(), m_pCurrVertex.Get()); D3D11_MAPPED_SUBRESOURCE rsSrc; VertexPosNormalTex* dataSrc; deviceContext->Map(m_pTempBuffer.Get(), 0, D3D11_MAP_READ, 0, &rsSrc); dataSrc = (VertexPosNormalTex*)rsSrc.pData; deviceContext->Unmap(m_pTempBuffer.Get(), 0); // 写入 D3D11_MAPPED_SUBRESOURCE rsDest; deviceContext->Map(m_pVertexBuffer.Get(), 0, D3D11_MAP_WRITE_DISCARD, 0, &rsDest); memcpy_s(rsDest.pData, m_VertexCount * sizeof(VertexPosNormalTex), dataSrc, m_VertexCount * sizeof(VertexPosNormalTex)); deviceContext->Unmap(m_pVertexBuffer.Get(), 0); m_AccumulateTime = 0.0f;// 重置时间 } }
StructuredBuffer不能直接作为顶点缓冲区绑定到渲染管线上,因为IASetVertexBuffers的缓冲区必须有D3D11_BIND_VERTEX_BUFFER标记,StructuredBuffer已经有D3D11_BIND_SHADER_RESOURCE | D3D11_BIND_UNORDERED_ACCESS标记,当尝试添加D3D11_BIND_VERTEX_BUFFER时,发现无法创建出缓冲区,也就是说,一个缓冲区不能同时拥有这三个属性。因此我们需要从m_pCurrVertex读取顶点数据,再写人m_pVertexBuffer。
绘制
绘制的代码大部分使用到开头提及的教程中的BasicEffect,不好展开讲解,直接给出代码:
UINT strides[1] = { sizeof(VertexPosNormalTex) }; UINT offsets[1] = { 0 }; // 设置绘制所有的顶点缓冲区(当前顶点缓冲区) deviceContext->IASetVertexBuffers(0, 1, m_pCurrVertex.GetAddressOf(), strides, offsets); // 设置绘制所有的引索缓冲区 deviceContext->IASetIndexBuffer(m_pIndexBuffer.Get(), DXGI_FORMAT_R32_UINT, 0); // 关闭波浪绘制,因为这里的波浪绘制时教程中用来计算法线的,我们不需要 effect.SetWavesStates(false); // 设置材质 effect.SetMaterial(m_Material); // 设置纹理 effect.SetTextureDiffuse(m_pTextureDiffuse.Get()); // 设置世界矩阵 effect.SetWorldMatrix(m_Transform.GetLocalToWorldMatrixXM()); // 设置纹理位移(偏移) effect.SetTexTransformMatrix(XMMatrixScaling(m_TexU, m_TexV, 1.0f) * XMMatrixTranslationFromVector(XMLoadFloat2(&m_TexOffset))); effect.Apply(deviceContext); // 绘制 deviceContext->DrawIndexed(m_IndexCount, 0, 0); // 解除当前顶点缓冲区的绑定 deviceContext->IASetVertexBuffers(0, 1, m_pVertexBuffer.GetAddressOf(), strides, offsets); effect.Apply(deviceContext);
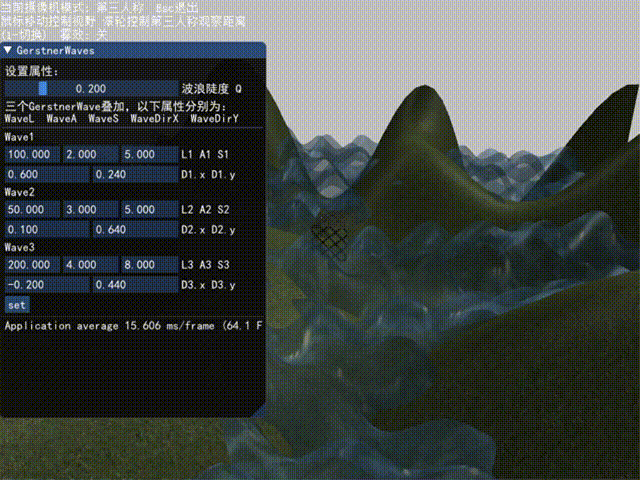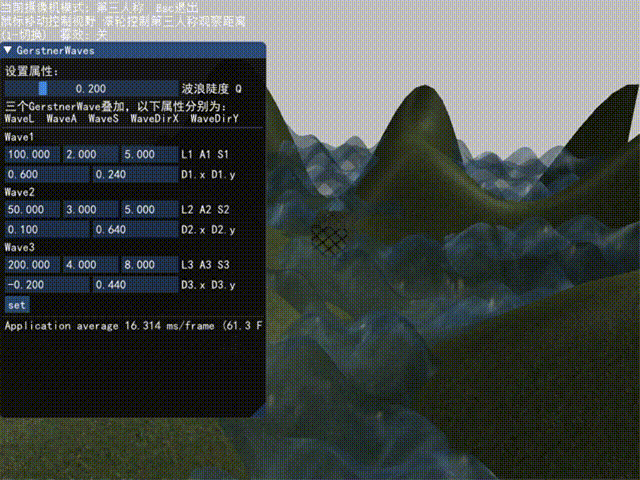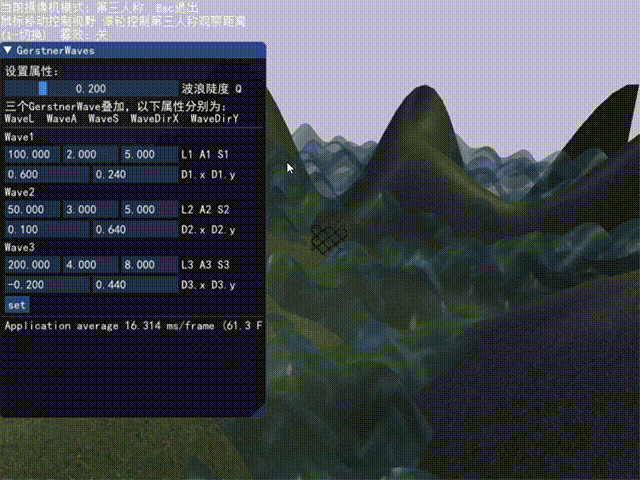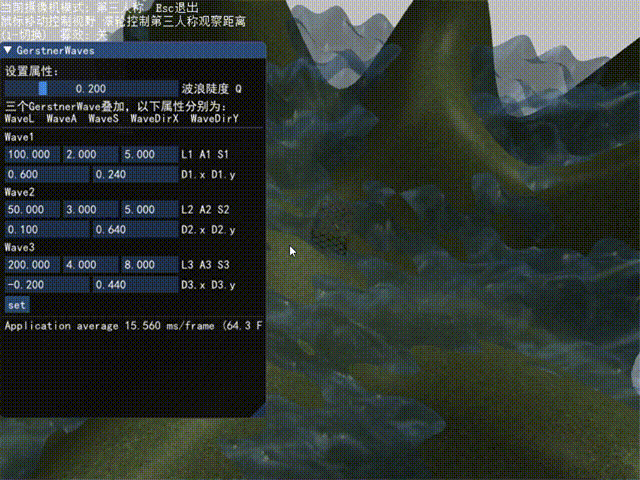
演示
这里给出最终结果(包括ImGui)的演示,以后有时间再录制每一步的演示结果。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号