

Paper Reading:The Google File System(一)
中午扫了一篇,细读到2.5,先把笔记记下来,明日继续。
- The Google File System
- Abstract
- a scalable distributed file system for large distributed data-intensive applications.
- Features
- provides fault tolerance while running on inexpensive commodity hardware
- delivers high aggregate performance to a large number of clients
- In this paper
- present file system interface extensions designed to support distributed applications
- discuss many aspects of our design
- report measurements from both micro-benchmarks and real world use
- Introduction
- 1、component failures are the norm rather than the exception.
- Therefore, constant monitoring, error detection, fault tolerance, and automatic recovery must be integral to the system.
- 2、files are huge by traditional standards.
- design assumptions and parameters such as I/O operation and blocksizes have to be revisited.
- 3、most files are mutated by appending new data rather than overwriting existing data.
- appending becomes the focus of performance optimization and atomicity guarantees, while caching data blocks in the client loses its appeal.
- 4、co-designing the applications and the file system API benefits the overall system by increasing our flexibility.
- 1、component failures are the norm rather than the exception.
- Design Overview
- 基本假设
- 1、运行在廉价设备上,经常当机。
- GFS必须持久地监视系统,并且能检错、容错、在运行中对当机节点及时重启
- 2、系统中存储了一定量的大文件
- GB级别的文件很常见,需要对其有效管理,小文件也支持,但是不必要优化
- 3、作业中包含两类读操作:大型的流式读取、小型的随机读取
- 4、作业中包含大型的、连续的写操作:向文件中附加数据
- 一旦写入,很少被修改;也支持小型的随机写操作,可以不用很高效
- 5、系统必须为多客户端并行附加数据到同一文件提供设计合理、实现高效定的机制
- 保证同步的最低要求:原子性
- 6、带宽高稳定性第一位,容许少量延时响应
- 大部分目标作业响应时间有一定的容忍度
- 1、运行在廉价设备上,经常当机。
- 接口
- 1、未实现标准的POSIX API
- 2、文件组织为目录层次结构,用路径名区分
- 3、支持create、delete、open、close、read、write
- 4、额外支持
- snapshot
- 低耗费地建立一个文件或目录树的备份
- record append
- 允许多客户端向同一个文件添加记录,并且保证各客户端各自操作的原子性
- 无需额外加锁
- 允许多客户端向同一个文件添加记录,并且保证各客户端各自操作的原子性
- snapshot
- 架构
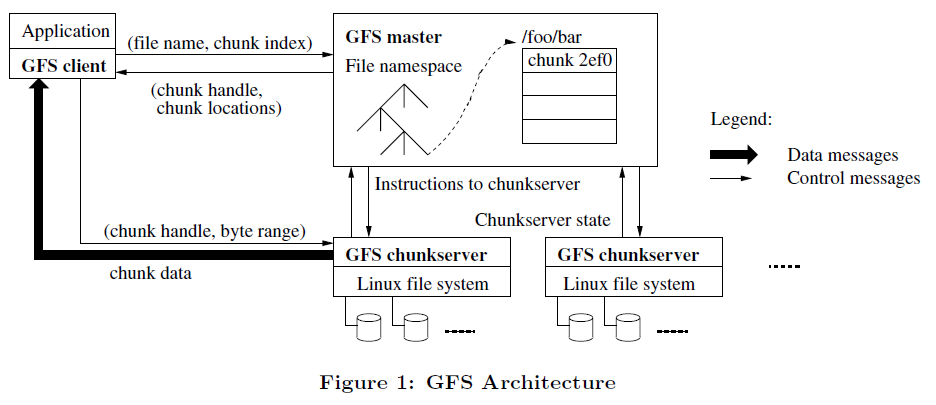
- Tips
- 1、整体:单台主机+多台块服务器
- 一个块服务器和一个客户端可以在同一台机器上
- 2、文件存储
- 分割成多个固定大小的块
- 每个块由主机在块创建之初分配一个可数的全局唯一的64位整数:chunk handle标记
- 块在块服务器上作为Linux文件被读写
- 读写块的时候通过(chunk handle+byte range)指定
- 每个块有3个冗余存储,用户可以为不同的文件命名空间指定不同的冗余级别
- 3、主机保存所有的文件系统元数据,管理整个系统的运行
- 元数据
- 命名空间
- 访问控制信息
- 文件到块的映射
- 块的当前存储位置
- 其他职能
- 块租赁管理(chunk lease management)
- 孤岛块的垃圾回收(garbage collection of orphaned chunks)
- 块服务器之间的块迁移
- 其他
- 周期性地通过心跳(HeartBeat)信息向块服务器发送指令和收集其运行状态
- 元数据
- 4、客户端同主机交互,进行元数据操作;数据相关交互直接访问块服务器
- 5、客户端和块服务器都不做缓存
- 客户端
- 数据量大缓存放不下(Client caches offer little benefit because most applications stream through huge files or have working sets too large to be cached.)
- 但是对元数据做缓存
- 块服务器
- 不需要是因为块作为Linux文件被存储,Linux系统的缓冲机制已经把常用数据放在了内存里
- 客户端
- 1、整体:单台主机+多台块服务器
- 单台主机
- 优缺点
- 优点
- 简化设计,允许主机使用全局信息实现完善的块分配和冗余机制
- 注意
- 尽可能少地参与数据读写过程,免得使单个主机成为瓶颈
- 优点
- 举例:一次客户端读取数据作业
- 1、通过固定的块大小,客户端将应用程序提供的文件名和比特位移转化为文件中一个块索引
- 2、客户端向主机发送请求(包含:文件名+块索引)
- 3、主机回复指定的chunk handle和副本的位置,此时,客户端缓存次信息,以Key-value的形式(key:文件名+块索引,value:主机返回信息)
- 4、客户端向某一个副本发送数据请求,请求指定了chunk handle和块内的byte range
- 5、在同一个chunck内的数据读取,不需要再进行client-master的交互
- 除非
- 缓存信息用完
- 文件重新打开
- 除非
- 补充:一般客户端在一次请求中,会请求多个块信息,主机会在接到请求后立即返回请求的信息
- 优缺点
- 块大小(chunk size)
- 基本信息
- 64MB
- 存储为块服务器上的普通的Linux文件
- 懒惰的空间分配策略:只有在必须的情况下才扩展
- 避免了内碎片导致的空间浪费
- 优点
- 1、减少了客户端与主机之间的交互
- 客户端多为顺序地读写,在一个块上的多次读写,一次请求就够了
- 2、减少了网络请求耗费
- 在较长时间内与一个块服务器建立一个较持久的TCP连接
- 3、减少了元数据存储的空间耗费
- 可以将元数据保存在内存里
- 1、减少了客户端与主机之间的交互
- 缺点
- 小文件,只占用了较少数目,甚至是一个块,容易引起访问热点
- 但实际大文件居多,小文件极少
- 举例
- GFS第一次使用批量查询系统,可执行文件可能只占用了一个块,多个客户端同时请求可执行程序,此时形成热点
- 解决办法:
- 提高单点程序的冗余级别,多备份,将请求分散到不同的块服务器上
- 错开各个客户端请求的时间
- 小文件,只占用了较少数目,甚至是一个块,容易引起访问热点
- 基本信息
- 元数据
- 一致性模型
- 基本假设
- System Interactions
- Master Operation
- Fault tolerance an diagnosis
- Measurements
- Experiences
- Related work
- Conclusions
- Abstract

