
深入解析 Java集合类ArrayList与Vector的区别
集合类分为两个分支,Collection与Map,其中Collection接口继承了Iterator接口,继承Iterator接口的类可以使用迭代器遍历元素(即Collection接口的类都可以使用),今天我们从相同点、不同点、以及JDK源码等各个方面来深入解析下,底层使用数组实现的两个集合类:ArrayList与Vector的区别与联系
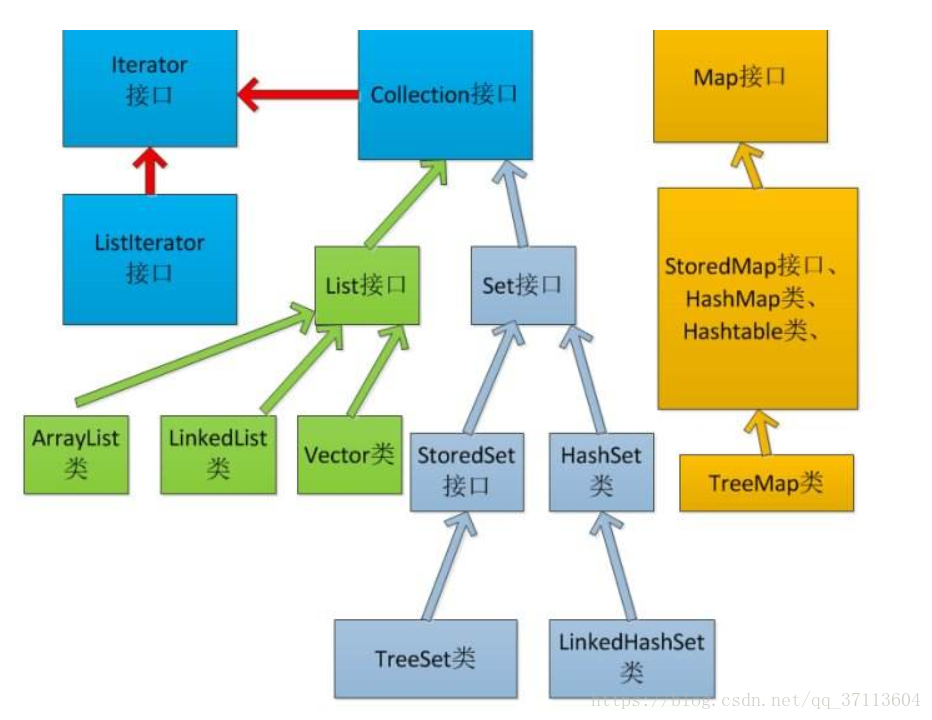
区别与联系:
1.ArrayList出现于jdk1.2,vector出现于1.0.两者底层的数据存储都使用的Object数组实现,因为是数组实现,所以具有查找快(因为数组的每个元素的首地址是可以得到的,数组是0序的,所以: 被访问元素的首地址=首地址+元素类型字节数*下标 ),增删慢(因为往数组中间增删元素时,会导致后面所有元素地址的改变)的特点
2.继承的类实现的接口都是一样的,都继承了AbstractList类(继承后可以使用迭代器遍历),实现了RandomAccess(标记接口,标明实现该接口的list支持快速随机访问),cloneable接口(标识接口,合法调用clone方法),serializable(序列化标识接口)
3.当两者容量不够时,都会进行对Object数组的扩容
(1)解析ArrayList扩容源码(假设从初始开始size=0,且构造方法为: new ArrayList<>(); ):
①首先调用add方法,添加元素,在add中调用ensureCapacityInternal(确保内部容量),将当前的size(实际元素数量)传输

②在ensureCapacityInternal中,首先将elementData数组 与 DEFAULTCAPACITY_EMPTY_ELEMENTDATA 进行比较,这里我们假设的构造方法为下图,此时两个数组相等,minCapacity等于大的值,DEFAULT_CAPACOTY的值为10(在成员变量中定义),即minCapacity=10。

③modcount是在ArrayList的父类AbstractList中定义的成员变量,用于记录修改次数(对当前ArrayList的修改次数),
minCapacity=10,element.length=0,所以执行grow方法。
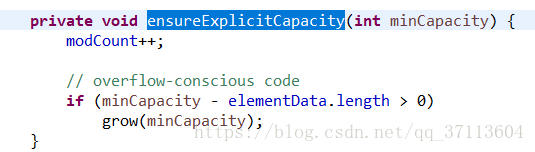
④grow方法中由于初始容量为0,所以newCapatcoty=0,然后newCapacity=minCapacity等于10 (即通常说的:ArrayList的默认构造方法,会默认分配长度为10的内存空间,这里的分配不是在创建对象时分配,而是在增加第一条数据的过程中分配,这样防止了内存的浪费),然后进行Arrays.copyOf 。如果再次扩容的话,扩容到当前容量的1.5倍。

(2)解析Vector扩容源码
①首先调用add方法,与arraylist相同,vector也有一个继承父类的成员变量modCount来记录修改次数。
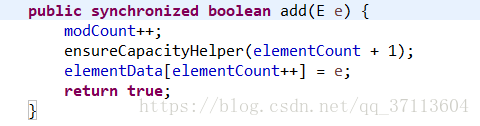
②如果当前实际元素数+1大于数组定义长度,执行grow方法
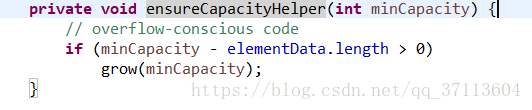
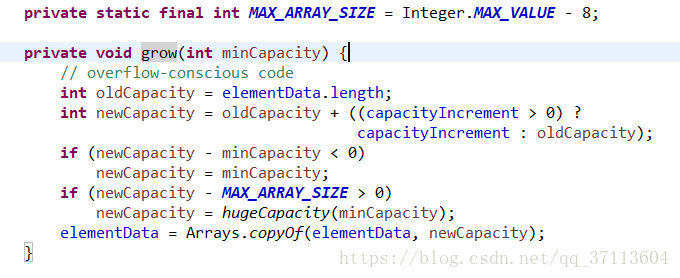
③将elementData copy到 一个新的长度数组中,完成gorw。 其中, capacityIncrement为自定义的增长因子(此处与arrayList不同,arraylist默认增长1.5倍;vector可以自定义若不自定义,则增长2倍,若定义则新长度=之前的长度+增长因子) MAX_ARRAY_SIZE为数组定义的最大长度,如果是负数,则抛出OutOfMemoryError异常,如果大于MAX_ARRAY_SIZE,则赋值为Int类型的最大值。

4.构造方法略有不同。
ArrayList:
(1)ArrayList a1 = new ArrayList(int i); 指定初始化容量的构造方法

(2)ArrayList a2 = new ArrayList(); 默认构造方法,在添加第一个元素过程中初始化一个长度为10的Object数组

(3) ArrayList a3 = new ArrayList(Collection); 在构造方法中添加集合,本方法创建的集合的object数组长度等于实际元素个数

Vector:
(1)Vector v1 = new Vector(10,2); 指定初始长度(initialCapacity)与增长因子(capacityIncrement)注意这里的增长因子不是oldCapacity * capacityIncrement而是+,如果不指定或者指定为0,则默认扩容当前容量的两倍,这里上面提过了

(2)Vector v2 = new Vector(10); 通过this关键字调用上面的构造方法,自定义初始数组长度,增长因子默认为0

(3)Vector v3 = new Vector(); 默认构造方法,在创建对象时便分配长度为10的Object数组。(这里在创建时便分配内存,一定意义上,浪费了内存空间)

5.线程的安全性不同,vector是线程安全的,在vector的大多数方法都使用synchronized关键字修饰,arrayList是线程不安全的(可以通过Collections.synchronizedList()实现线程安全)
6.性能上的差别,由于vector的方法都有同步锁,在方法执行时需要加锁、解锁,所以在执行过程中效率会低于ArrayList,另外,性能上的差别还体现在底层的Object数组上
vector:
arrayList:
可以看出来,arrayList多了一个transient关键字,这个关键字的作用是防止序列化,然后在ArrayList中重写了了readObject和writeObject方法,这样是为了在传输时提高效率,我们先来看下源码:
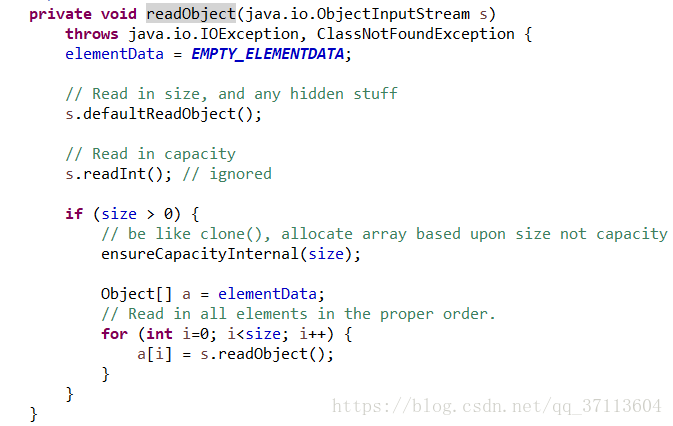
可以看到,这两个方法中将elementData数组中实际存在的元素遍历出来进行传输,假设现在容量为10000但是实际有8000元素,如果将2000空的元素也进行传输势必会影响效率,所以这么做提高了效率,节省了时间。
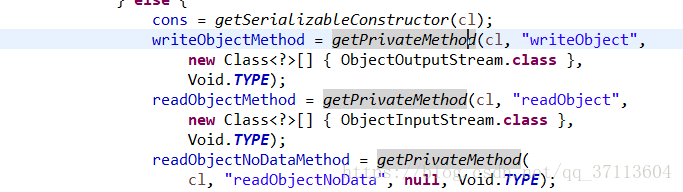
这两个方法在序列化时如何被调用的,为什么是private修饰?在传输时,ObjectInputStream与ObjectOutputStream会通过反射调用这两个方法。 private修饰时因为,在ObjectStreamClass类中,调用的是传输对象中private修饰的writeObject与readObject(这里就不深入研究了,光从找下面这个图片的源码就可以感觉到,IO流的源码比集合类可能复杂的多)
defaultReadObject与dafaultWriteObject的作用?
如果类中不自定义readObject与writeObject,那么类在序列化的时候会调用ObjectInputStream与ObjectOutputStream中的defaultReadObject与defaultWriteObject方法进行默认序列化,这样的话,就不会序列化transiend中的数组。但是transiend修饰的数组是必须要序列化的! 如果自定义的话,就不会调用这两个default方法,这样的话类中所有需要序列化的都要自定义,这样太麻烦了,所以在自定义的方法中先调用下他,将不是transiend的序列化,然后再自定义object数组的序列化。
最后再说一下,这两个集合类如何在迭代时保证线程安全,这里就要提一下上面说过的在AbstractList类中有一个静态变量
modcount(我看网上一些帖子说modcount只存在于线程不安全的集合类中,其实这种说法是错误的,在vector中也使用了modcount用于保证迭代时数据安全)他用于记录一个集合类对象被修改的次数。这两个类在迭代时(调用iterator方法时),Iterator iterator = arrayList.iterator();或Iterator iterator2 = vector.iterator(); 返回的iterator对象都是类中的一个私有内部类。这个类在调用时,便初始化了一个expectedModCount=modcount,即在迭代前先用成员变量保存下modcount的值。
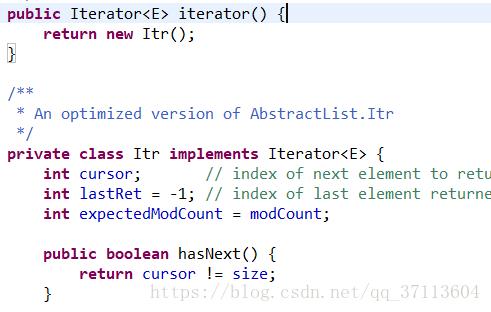
在迭代时,首先会调用checkForComodification方法,来比较modCount的值有没有被改变,如果改变则会抛出异常,这样就保证了迭代时的安全性(这里的安全性不只是保证了多线程下的安全,也保证了单线程中迭代时,如果修改数据所造成的隐患)这就是所谓fail-fast策略(快速失败策略)。

原文链接:https://blog.csdn.net/qq_37113604/article/details/80836025
虽然看来一半就半知半懂,但是膜拜大佬

 浙公网安备 33010602011771号
浙公网安备 33010602011771号