fofa-spider爬虫
正则出现问题,脚本已废弃(呜呜菜鸡本人不会正则)
需要的小伙伴自行搜索fofaviewer工具
本文废弃本文废弃本文废弃
本文脚本已废弃,仅供学习
fofa重生
自从上次fofa挂了再到上线,发现关于fofa的爬虫脚本都不能用了,于是,一个想法萌生出来,要不自己写一个?
说干就干
脚本编写
构造数据包请求头,fofa搜索内容是base64加密的,并且由page控制页数

search_data_b=base64.b64encode(search_data.encode('utf-8'))
search_data_bs=search_data_b.decode('utf-8')
headers={
'user-agent':'Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)',
"cookie":'xxxx'
}
url="https://fofa.info/result?page="+str(yeshu)+"&qbase64="
urls=url+search_data_bs
将请求内容储存到result变量中
timeout防止超时等待
etree.HTML()构造XPath解析对象
result=requests.get(urls,headers=headers,timeout=0.8).content
soup =etree.HTML(result)
利用soup.xpath找出节点,打印并写入url.txt文件
ip_data=soup.xpath('//div[@class="list_mod_t"]/a[@target="_blank"]/@href')
print(url_data)
ipdata='\n'.join(url_data)
with open('url.txt','a+') as f:
f.write(ipdata+'\n')
f.close()
time.sleep(0.8)
完整代码
import base64
import time
import requests
from lxml import etree
def logo():
print('''
/$$$$$$$$ /$$$$$$ /$$$$$$$$ /$$$$$$
| $$_____//$$__ $$| $$_____//$$__ $$
| $$ | $$ \ $$| $$ | $$ \ $$
| $$$$$ | $$ | $$| $$$$$ | $$$$$$$$
| $$__/ | $$ | $$| $$__/ | $$__ $$
| $$ | $$ | $$| $$ | $$ | $$
| $$ | $$$$$$/| $$ | $$ | $$
|__/ \______/ |__/ |__/ |__/
/$$$$$$ /$$ /$$
/$$__ $$ |__/ | $$
| $$ \__/ /$$$$$$ /$$ /$$$$$$$ /$$$$$$ /$$$$$$
| $$$$$$ /$$__ $$| $$ /$$__ $$ /$$__ $$ /$$__ $$
\____ $$| $$ \ $$| $$| $$ | $$| $$$$$$$$| $$ \__/
/$$ \ $$| $$ | $$| $$| $$ | $$| $$_____/| $$
| $$$$$$/| $$$$$$$/| $$| $$$$$$$| $$$$$$$| $$
\______/ | $$____/ |__/ \_______/ \_______/|__/
| $$
| $$
|__/
version:1.0
''')
def fofa_search(search_data,page):
pages = page + 1
search_data_b=base64.b64encode(search_data.encode('utf-8')) #base64加密
search_data_bs=search_data_b.decode('utf-8')
headers={
'user-agent':'Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)',
"cookie":'xxxx' # cookie
}
for yeshu in range(1,pages):
url="https://fofa.info/result?page="+str(yeshu)+"&qbase64="
urls=url+search_data_bs #拼接参数,加上base64
print("正在提取" + str(yeshu) + "页")
try:
result=requests.get(urls,headers=headers,timeout=0.8).content #请求
soup =etree.HTML(result)
url_data=soup.xpath('//div[@class="list_mod_t"]/a[@target="_blank"]/@href') #找到节点的值
print(url_data)
urldata='\n'.join(url_data)
with open('url.txt','a+') as f: #写文件
f.write(ipdata+'\n')
f.close()
time.sleep(0.8)
except Exception as e:
pass
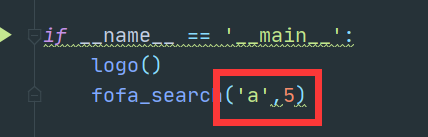
if __name__ == '__main__':
logo()
fofa_search('1',5)
脚本参考大佬的代码:
https://www.cnblogs.com/Cl0ud/p/12384457.html
脚本使用
补充cookie部分

设定搜索内容 页数



【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 清华大学推出第四讲使用 DeepSeek + DeepResearch 让科研像聊天一样简单!
· 推荐几款开源且免费的 .NET MAUI 组件库
· 实操Deepseek接入个人知识库
· 易语言 —— 开山篇
· Trae初体验