find()和find_all()的具体使用
在我们学会了BeautifulSoup库的用法后,我们就可以使用这个库对HTML进行解析,从网页中提取我们需要的内容。
在BeautifulSoup 文档里,find()、find_all()两者的定义如下:
find(tag, attributes, recursive, text, keywords)
find(标签,属性,递归,文本,关键词)
find_all(tag, attributes, recursive, text, limit, keywords)
find_all(标签、属性、递归、文本、限制、关键词)
find()与find_all()的区别,find()只会取符合要求的第一个元素,find_all()会根据范围限制参数limit限定的范围取元素(默认不设置代表取所有符合要求的元素,find 等价于 find_all的 limit =1 时的情形),接下来将对每个参数一一介绍。
另外,find_all()会将所有满足条件的值取出,组成一个list
下面我们就一一介绍函数中各个参数的作用:
一、标签tag
标签参数 tag 可以传一个标签的名称或多个标签名称组成的set做标签参数。例如,下面的代码将返回一个包含 HTML 文档中所有链接标签的列表: find_all("a")
下面以“百度一下”网页举例,如下图,现在要将百度页面上的所有的链接取出,观察网页源代码可以发现,标题对应的tag 是a,则soup.find_all('a')
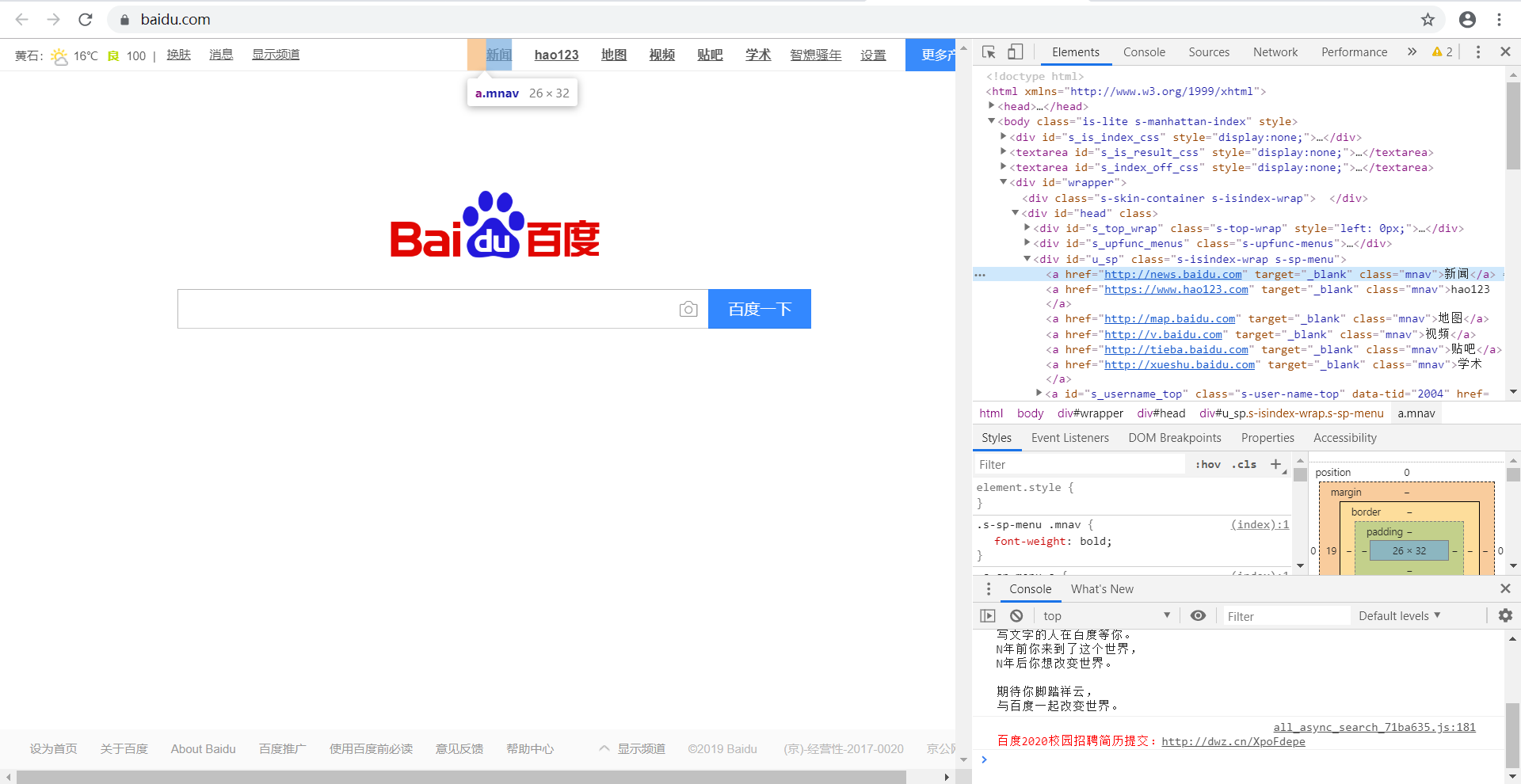
代码如下:
from bs4 import BeautifulSoup
import requests
url = 'https://www.baidu.com/'
urlhtml = requests.get(url)
urlhtml.encoding = 'utf-8'
soup = BeautifulSoup(urlhtml.text, 'lxml')
n = soup.find_all('a')
print(n)
结果如下,我们就找出了全部的<a>标签。

上面例子只是一个标签的情况,如果多个标签写法相同,只是注意要将所有的标签写在一个set里面
二、属性attributes
属性参数 attributes 是用字典封装一个标签的若干属性和对应的属性值。如,下面这个函数会返回 HTML 文档里“mnav”的a标签。find_all("a", {"class":{"mnav"}})
如下图,现在要获取网页中的“新闻”等信息,通过观察可知,它们的属性为"mnav",标签为a。
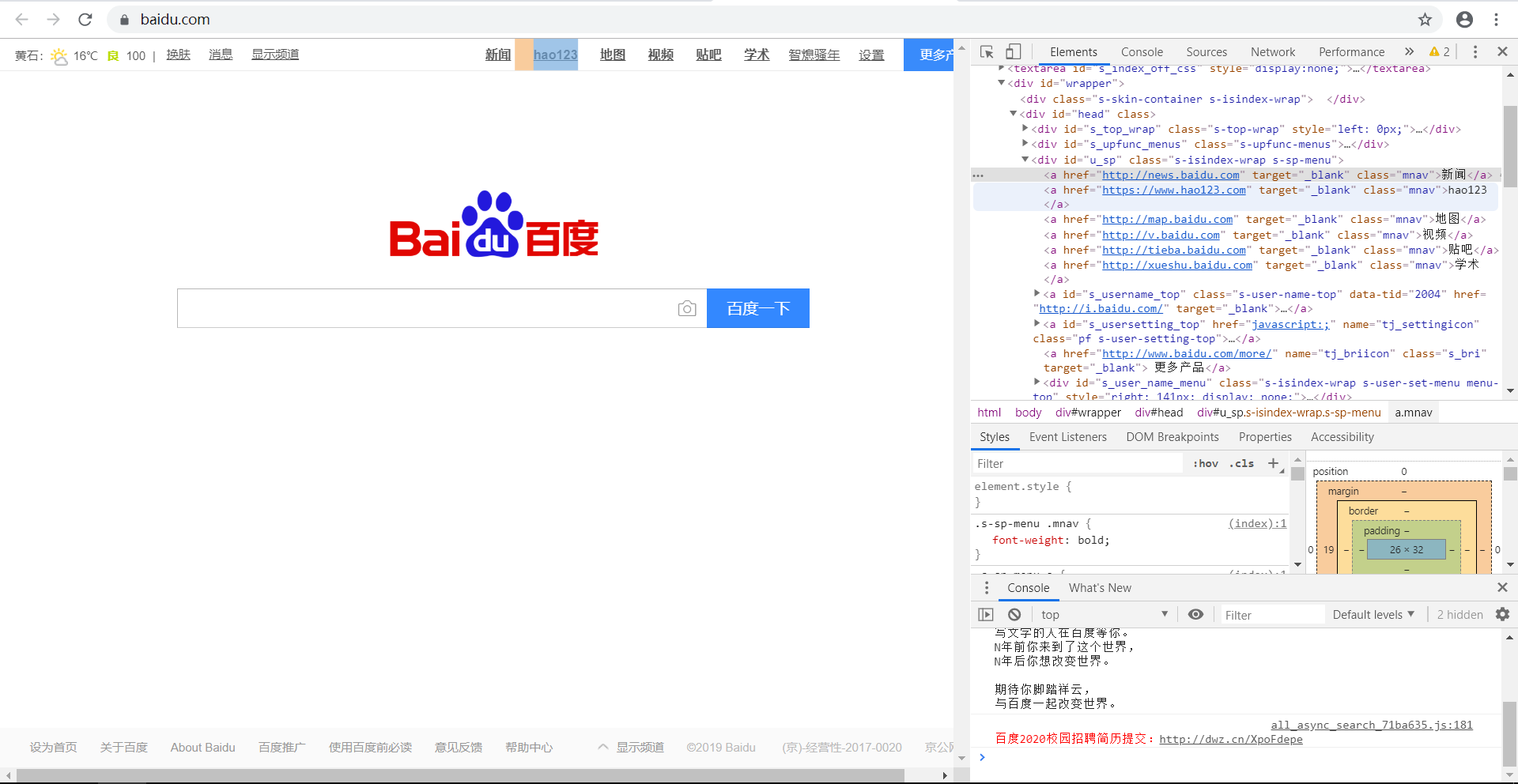
则我们可以编写代码:
from bs4 import BeautifulSoup import requests url = 'https://www.baidu.com/' urlhtml = requests.get(url) urlhtml.encoding = 'utf-8' soup = BeautifulSoup(urlhtml.text, 'lxml')
n = soup.find_all('a', {'class': 'mnav'}) print(n)
运行结果如下,可以看出输出的链接的属性全部为“mnav”。

三、递归recursive
递归参数 recursive 是一个布尔变量。你想抓取 HTML 文档标签结构里多少层的信息?如recursive 设置为 True, find_all()就会根据你的要求去查找标签参数的所有子标签,以及标签的子标签。如果 recursive 设置为 False, find_all()就只查找文档的一级标签。 find_all默认是支持递归查找的(recursive 默认值是 True),这里是很少使用的,所以我在这儿就不在举例了。
四、文本text
文本参数 text 有点不同,它是用标签的文本内容去匹配,而不是用标签的属性。
我们再以“百度一下”的网页举例吧,在这个网页中,我们查找一下“新闻”在该网页中出现了多少个(其实只出现了一个)
from bs4 import BeautifulSoup import requests url = 'https://www.baidu.com/' urlhtml = requests.get(url) urlhtml.encoding = 'utf-8' soup = BeautifulSoup(urlhtml.text, 'lxml') n = soup.find_all(text='新闻') print(n)
结果如下:
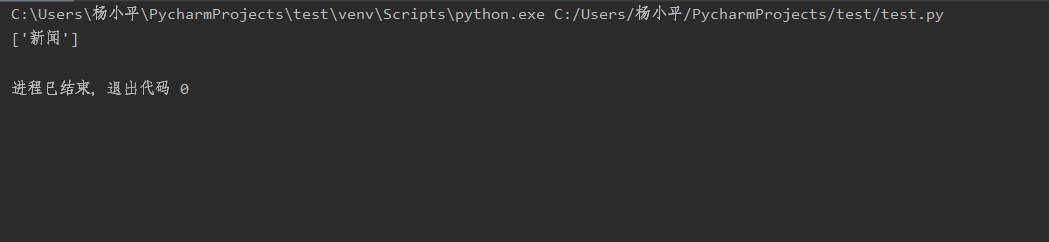
需要特别注意一点,这里查找是用的是完全匹配原则,意思是如果这里你用了find_all(text=“新”),得到的结果会是0个
五、关键词keywords
关键词参数 keyword,自己选择那些具有指定属性的标签
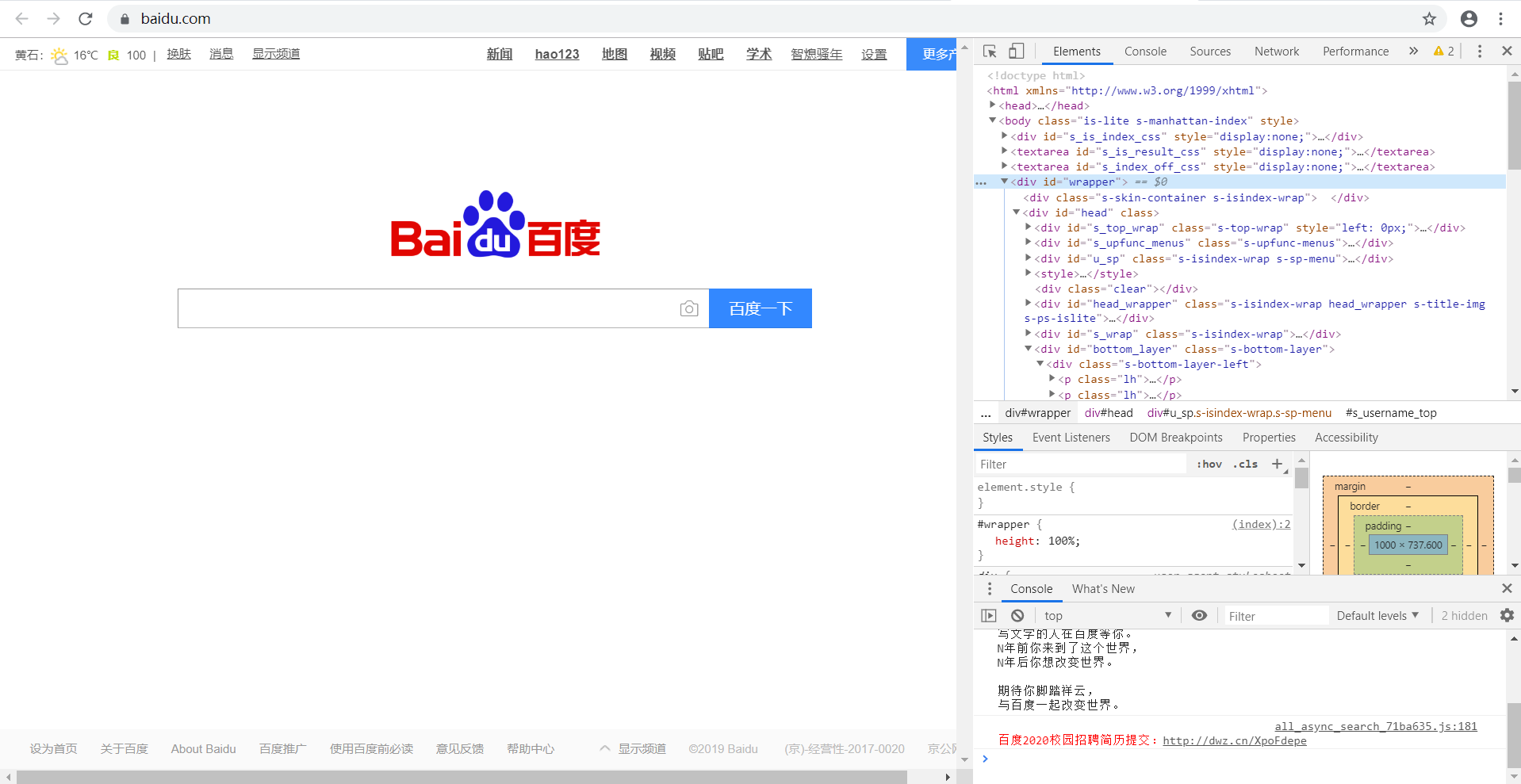
上面网页的内容,现在要取id='wrapper'的内容,则
from bs4 import BeautifulSoup import requests url = 'https://www.baidu.com/' urlhtml = requests.get(url) urlhtml.encoding = 'utf-8' soup = BeautifulSoup(urlhtml.text, 'lxml') n = soup.find_all(id='wrapper') print(n)
结果如下,也就是选中的<div>中的内容
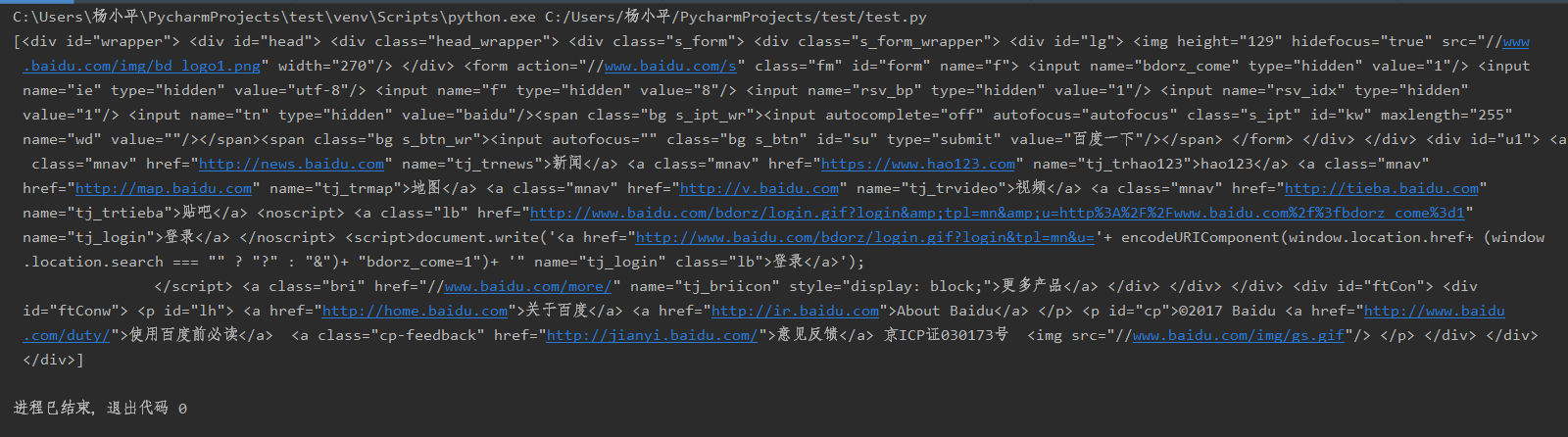
注意:如果是class、id等参数,用keywords 或者attributes用法一样,如果是一些其他参数,则用keywords

 浙公网安备 33010602011771号
浙公网安备 33010602011771号