
爬取小说并以章节名保存
今天我们爬取网页中的文字,与上次的爬取网页中的图片相似,网页的中的文字也是在网页的源码中(一般情况下)。
所以我们就以在某小说网站上爬取小说《圣墟》为例,使用爬虫爬取网页中的文本内容,并根据小说的章节名保存。
我们的思路如下:
1.爬取当前网页的源码:
2.提取出需要的数据(标题,正文)
3.保存(标题为文件名)
我们首先找到要爬取的网页:https://www.nbiquge.com/0_89/15314.html,可以看到小说的标题和正文,这是本次爬取的目标。

首先分析网页的编码格式,可以看到该网站的编码格式是”gbk“。
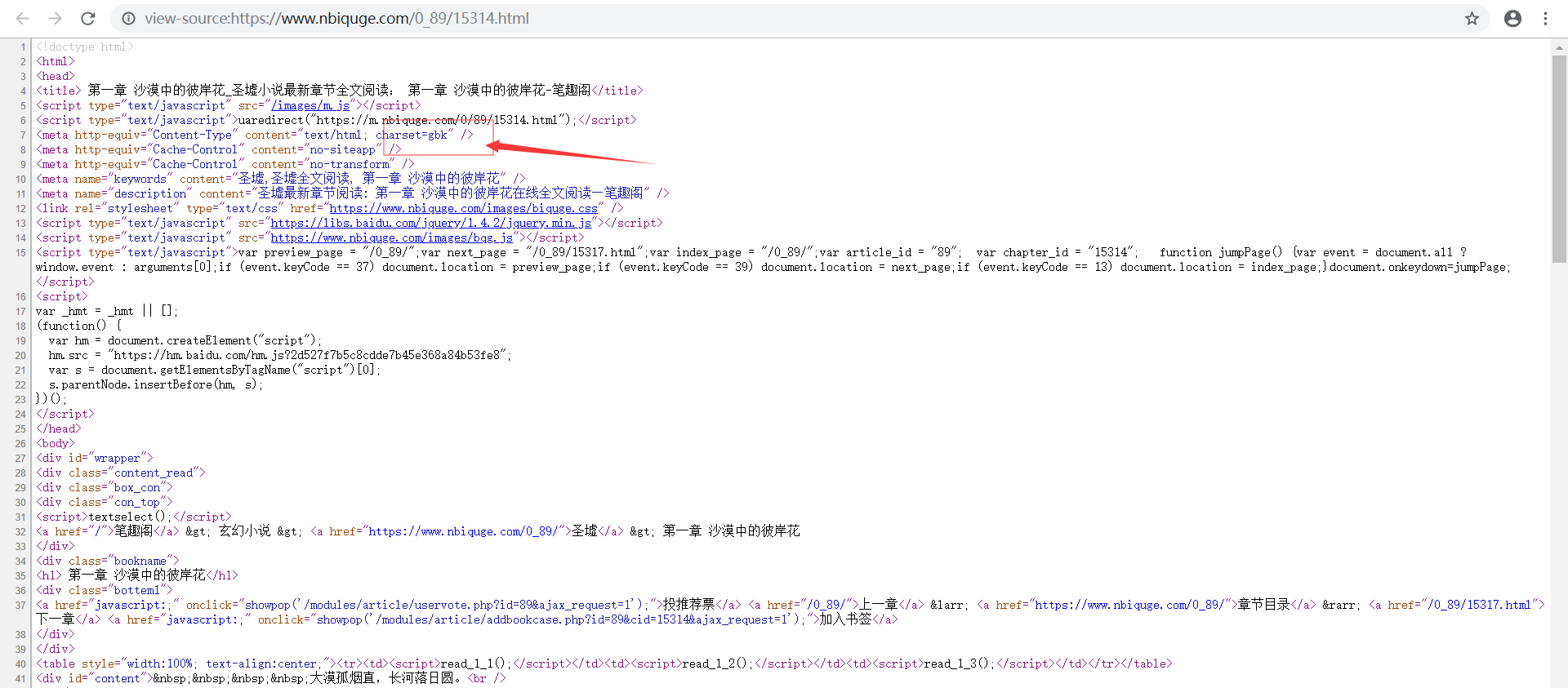
然后找到我们要爬取的信息在网页中的位置:
标题,在网页中右键点击标题,点击”检查“,就可以看到标题在网页中所处的位置。

正文:
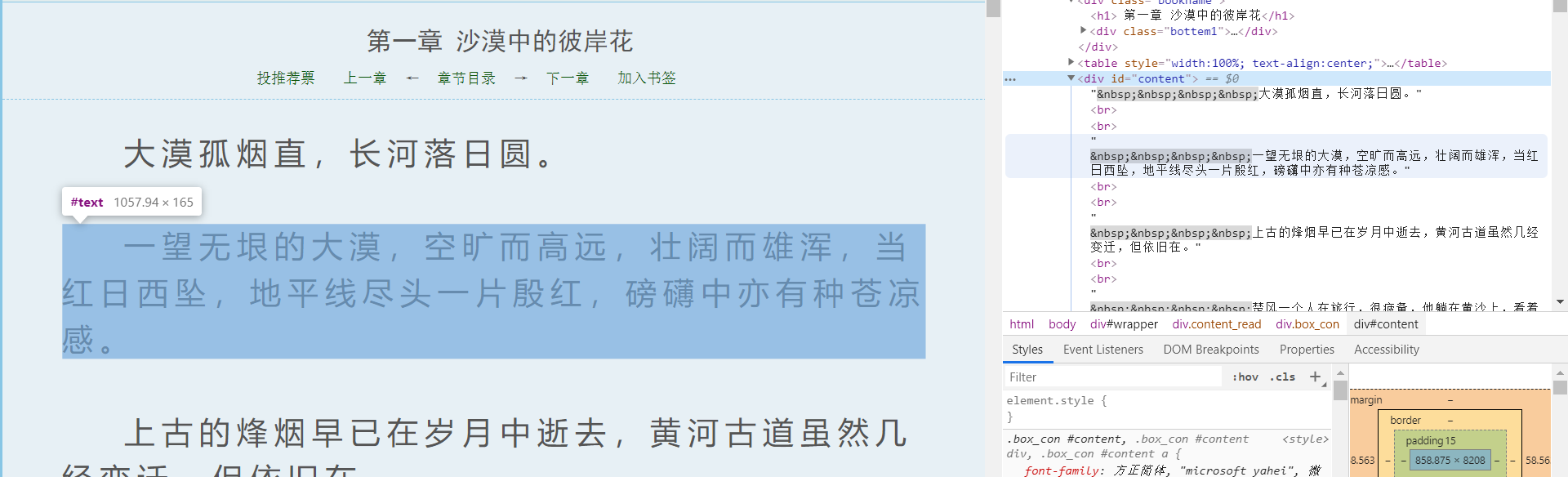
在了解网站的编码和标题正文的位置后,我们就可以编写代码来进行爬取了!
首先获得网页源码,再对源码进行分析,提取所要获得的数据,最后保存为.txt文件。代码如下:
import requests from bs4 import BeautifulSoup #网页url url="https://www.nbiquge.com/0_89/15314.html"
#获得网页源码 def getHtml(url): r=requests.get(url) r.encoding='gbk' return r.text
#获得标题和正文内容 def getTxt(html): s=BeautifulSoup(html) title=s.find('div',{'class':'bookname'}).find('h1') text=s.find('div',{'id':'content'}) ls=[] ls.append(title.string) ls.append(str(text)) return ls
#保存 def saveTxt(ls): name=ls[0]+'.txt' fo=open(name,'w+',encoding='utf8') # ls[1] = ls[1].replace(" ", "") ls[1] = ls[1].replace("<br/>", "") fo.writelines(ls[1]) fo.close() h1=getHtml(url) h2=getTxt(h1) saveTxt(h2)
在Pycharm中运行代码,该项目的文件夹中就会出现一个txt文件。
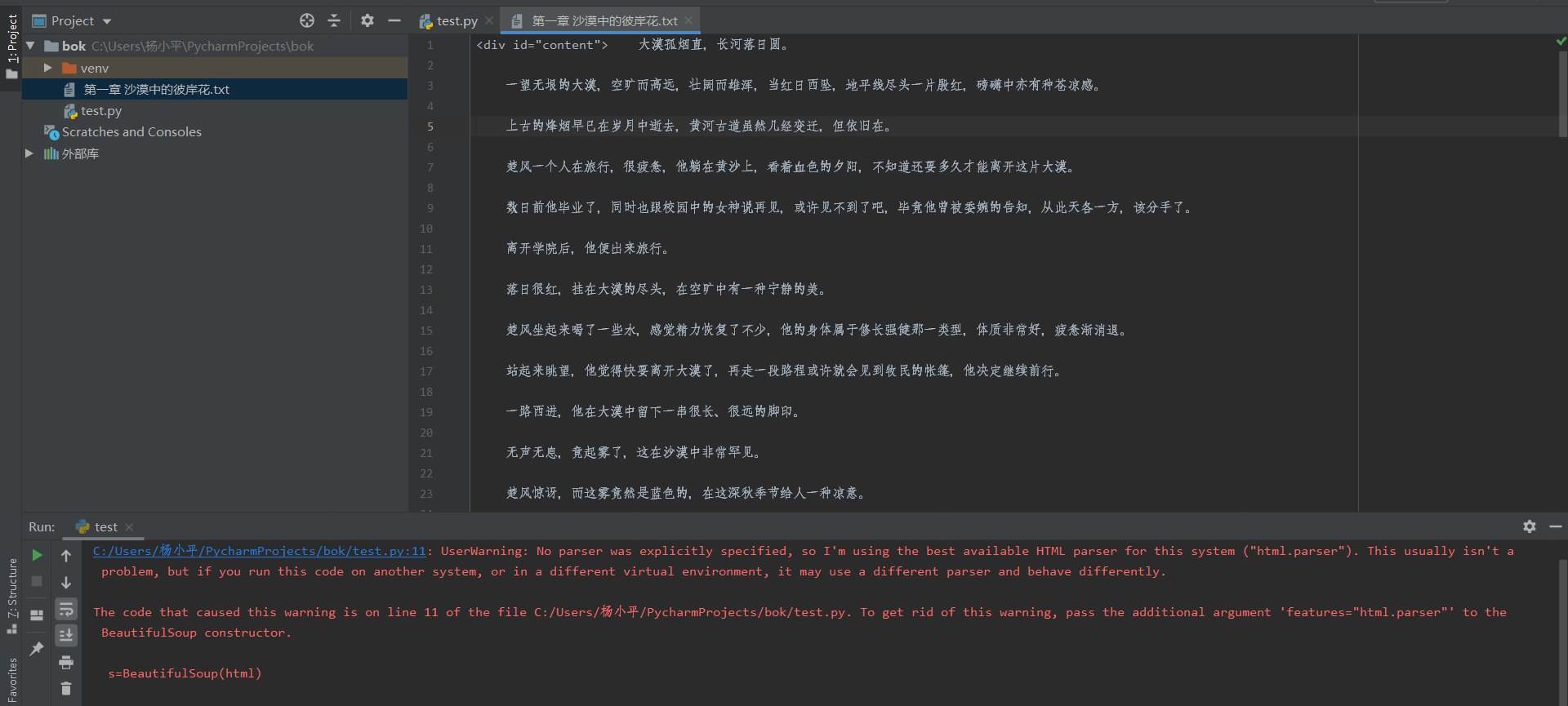
打开该txt文件,里面保存了小说的内容,其中标题为小说的章节名。
以上就是一个简单的爬取小说的代码了。这里还有其他的功能没有展现出,比如爬取小说的更多章节并保存,如果是在起点中文网上该怎么操作(起点的网页源码没有文章内容),这就需要我们进一步进行探索了。网页的爬取是需要我们根据网页的结构进行分析,然后编写相应的代码进行爬取的,在这个过程中会遇到很多的预料不到的情况,需要我们根据所学内容以及自己的查阅来解决问题。

