JavaSE面试题
JavaSE面试题
集合
集合类存放于 Java.util 包中,主要有 3 种:set(集)、list(列表包含 Queue)和 map(映射)
Collection:是集合 List、Set、Queue 的最基本的接口
1、List
List共有特点:排列有序(这里的顺序指的是存储顺序),可重复
- ArrayList:底层使用数组,查询快,增删慢;线程不安全;当容量不够时,ArrayList是当前容量*1.5+1
- Vector:底层使用数组,查询快,增删慢;线程安全;当容量不够时,Vector默认扩展一倍容量
- LinkedList:底层使用双向循环链表数据结构;查询慢,增删快;线程不安全
2、Set
Set共有特点:排列无序(这里的顺序指的是存储顺序),不可重复
如何判断一个对象是否重复:首先判断两个元素的哈希值,如果哈希值一样,接着会比较equals 方法, 如果 equls 结果为 true ,就视为同一个元素;反之不是同一个元素
- HashSet:存取速度快,内部是HashMap
- TreeSet:可以实现排序,内部是TreeMap
Integer 和 String 对象都可以进行默认的 TreeSet 排序,而自定义类的对象是不可以的,自己定义的类必须实现 Comparable 接口,并且覆写相应的 compareTo()函数,才可以正常使用
- LinkedHashSet:继承HashSet;采用hash表存储,并用双向链表记录插入顺序,内部是LinkedHashMap
3、Queue
在两端出入的List,所以也可以用数组或链表来实现
Map:是映射表的基础接口
map共有特点:数据都是以键值对形式存储,键不可重复,值可重复;
- HashMap:底层hash表;线程不安全,允许null键、null值;初始化容量是16,每次扩容2的n次方,负载因子默认是0.75, 2^n是为了让散列更加均匀
hash表是由数组+链表实现的;jdk1.8后HashMap底层采用数组+(链表|红黑树)实现,当存储数据大于8链表转化成红黑树
- HashTable:底层hash表;线程安全,不允许null键、null值;初始化容量是11,每次扩容变为原来的2n+1
- TreeMap:底层二叉树;可以实现排序
在使用 TreeMap 时,key 必须实现 Comparable 接口或者在构造 TreeMap 传入自定义的Comparator,否则会在运行时抛出 java.lang.ClassCastException 类型的异常
Iterator和ListIterator的区别
- Iterator可用来遍历Set和List集合,但是ListIterator只能用来遍历List。
- Iterator对集合只能是前向遍历,ListIterator既可以前向也可以后向。
- ListIterator实现了Iterator接口,并包含其他的功能,比如:增加元素,替换元素,获取前一个和后一个元素的索引,等等。
反射
反射机制
JAVA反射机制是在运行状态中,对于任意一个类,都能够知道这个类的所有属性和方法;对于任意一个对象,都能够调用它的任意一个方法;这种动态获取的以及动态调用对象的方法的功能称为java语言的反射机制
反射API
- Class 类:反射的核心类,可以获取类的属性,方法等信息
- Field 类:Java.lang.reflec 包中的类,表示类的成员变量,可以用来获取和设置类之中的属性值
- Method 类: Java.lang.reflec 包中的类,表示类的方法,它可以用来获取类中的方法信息或者执行方法
- Constructor 类: Java.lang.reflec 包中的类,表示类的构造方法
反射使用步骤
- 获取想要操作的类的 Class 对象,他是反射的核心,通过 Class 对象我们可以任意调用类的方法
- 调用 Class 类中的方法,既就是反射的使用阶段
- 使用反射 API 来操作这些信息
获取Class对象的三种方法
- 调用某个对象的getClass方法
Person p=new Person();
Class clazz=p.getClass();
- 调用某个类的class属性来获取该类对应的Class对象
Class clazz=Person.class;
- 使用Class类中的forName静态方法(最常用,最安全,性能最好)
Class clazz=Class.forName("类的全路径");
通过反射创建对象的两种方法
- Class对象的newInstance()
- 调用Constructor对象的newInstance()
多线程
启动线程的唯一方法就是通过Thread类的start实例方法,start方法是一个native方法,它将启动一个新线程,并执行 run方法
线程的创建方式
1、继承Thread类,重写run方法:Thread 类本质上是实现了 Runnable 接口的一个实例,eg:
package com.yl;
public class ThreadTest extends Thread{
@Override
public void run() {
System.out.println("start run");
}
}
继承Thread类创建线程的启动方式
package com.yl;
public class ThreadMain {
public static void main(String[] args) {
ThreadTest threadTest = new ThreadTest();
threadTest.start();
}
}
2、实现Runnable接口,重写run方法:无返回值,eg:
package com.yl;
public class ThreadTest implements Runnable{
@Override
public void run() {
System.out.println("start run");
}
}
实现Runnable接口创建线程的启动方式
package com.yl;
public class ThreadMain {
public static void main(String[] args) {
ThreadTest threadTest = new ThreadTest();
// 实例化一个Thread对象,并传入自己的线程(threadTest)实例
Thread thread = new Thread(threadTest);
thread.start();
}
}
3、实现Callable 接口,重写call方法:有返回值,eg:
package com.yl;
import java.util.concurrent.Callable;
public class ThreadTest implements Callable<String> {
@Override
public String call() throws Exception {
return "start call";
}
}
实现Callable 接口创建线程的启动方式
package com.yl;
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.*;
public class ThreadMain {
public static void main(String[] args) {
// 线程数
int count = 2;
// 创建一个线程池
ExecutorService pool = Executors.newFixedThreadPool(count);
// 存储返回值
List<Future> list = new ArrayList<Future>();
for (int i = 0; i < count; i++) {
Callable callable = new ThreadTest();
// 启动线程并获取Future对象
Future future = pool.submit(callable);
list.add(future);
}
// 关闭线程池
pool.shutdown();
// 获取返回值
list.forEach(future -> {
try {
System.out.println(future.get().toString());
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
});
}
}
四种线程池
Java 里面线程池的顶级接口是 Executor,但是严格意义上讲 Executor 并不是一个线程池,而只是一个执行线程的工具。真正的线程池接口是 ExecutorService
- newCachedThreadPool:创建一个可缓存线程池,如果线程池长度超过处理需要,可灵活回收空闲线程,若无可回收,则新建线程
- newFixedThreadPool:创建一个定长线程池,可控制线程最大并发数,超出的线程会在队列中等待
- newScheduledThreadPool:创建一个定长线程池,支持定时及周期性任务执行
- newSingleThreadExecutor:创建一个单线程化的线程池,它只会用唯一的工作线程来执行任务,保证所有任务按照指定顺序(FIFO, LIFO, 优先级)执行
线程生命周期
- 新建:当程序使用new关键字创建了一个线程之后,该线程就处于新建状态,此时仅由JVM为其分配内存,并初始化其成员变量的值
- 就绪:当线程对象调用了 start方法之后,该线程处于就绪状态;Java 虚拟机会为其创建方法调用栈和程序计数器,等待调度运行
- 运行:如果处于就绪状态的线程获得了 CPU,开始执行 run方法的线程执行体,则该线程处于运行状态
- 阻塞:阻塞状态是指线程因为某种原因放弃了 cpu 使用权,也即让出了 cpu timeslice,暂时停止运行
- 死亡:线程结束
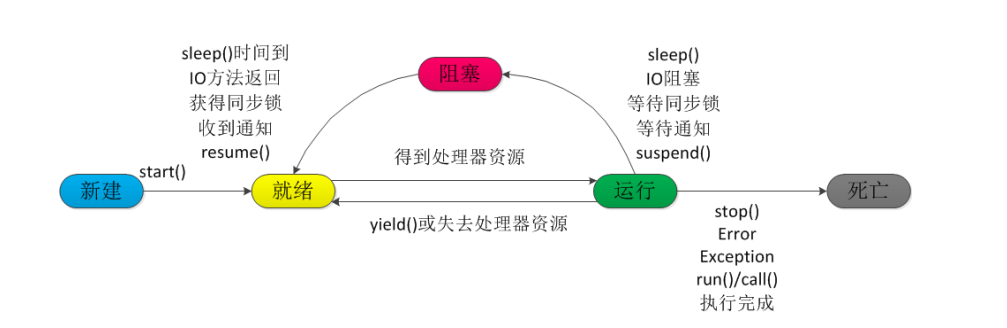
sleep和wait方法的区别
- sleep方法是属于 Thread 类中的,wait方法,则是属于Object 类
- 调用 sleep方法的过程中,线程不会释放对象锁;调用 wait()方法的时候,线程会放弃对象锁,进入等待此对象的等待锁定池,只有针对此对象调用 notify方法后本线程才进入对象锁定池准备获取对象锁进入运行状态
volatile关键字的作用
Java 语言提供了一种稍弱的同步机制,即 volatile 变量,用来确保将变量的更新操作通知到其他线程。volatile 变量具备两种特性,volatile 变量不会被缓存在寄存器或者对其他处理器不可见的地方,因此在读取 volatile 类型的变量时总会返回最新写入的值
其一是保证该变量对所有线程可见,这里的可见性指的是当一个线程修改了变量的值,那么新的值对于其他线程是可以立即获取的
volatile 禁止了指令重排
在访问 volatile 变量时不会执行加锁操作,因此也就不会使执行线程阻塞,因此 volatile 变量是一种比 sychronized 关键字更轻量级的同步机制。volatile 适合这种场景:一个变量被多个线程共享,线程直接给这个变量赋值
值得说明的是对 volatile 变量的单次读/写操作可以保证原子性的,如 long 和 double 类型变量,但是并不能保证 i++这种操作的原子性,因为本质上 i++是读、写两次操作
当对非 volatile 变量进行读写的时候,每个线程先从内存拷贝变量到 CPU 缓存中。如果计算机有多个 CPU,每个线程可能在不同的 CPU 上被处理,这意味着每个线程可以拷贝到不同的 CPU cache 中。而声明变量是 volatile 的,JVM 保证了每次读变量都从内存中读,跳过 CPU cache 这一步
synchronized和volatile关键字的区别
volatile关键字是线程同步的轻量级实现,所以volatile性能肯定比synchronized关键字要好
volatile关键字只能用于变量而synchronized关键字可以修饰方法以及代码块
多线程访问volatile关键字不会发生阻塞,而synchronized关键字可能会发生阻塞
volatile关键字能保证数据的可见性,但不能保证数据的原子性。synchronized关键字两者都能保证
volatile关键字主要用于解决变量在多个线程之间的可见性,而synchronized关键字解决的是多个线程之间访问资源的同步性
什么是线程死锁?如何避免死锁
死锁: 多个线程同时被阻塞,它们中的一个或者全部都在等待某个资源被释放
- 破坏互斥条件: 这个条件我们没有办法破坏,因为我们用锁本来就是想让他们互斥的(临界资源需要互斥访问)。
- 破坏请求与保持条件: 一次性申请所有的资源。
- 破坏不剥夺条件: 占用部分资源的线程进一步申请其他资源时,如果申请不到,可以主动释放它占有的资源。
- 破坏循环等待条件: 靠按序申请资源来预防。按某一顺序申请资源,释放资源则反序释放。破坏循环等待条件
线程sleep方法和yield方法的区别
- sleep()方法给其他线程运行机会时不考虑线程的优先级,因此会给低优先级的线程以运行的机会;yield()方法只会给相同优先级或更高优先级的线程以运行的机会;
- 线程执行sleep()方法后转入阻塞(blocked)状态,而执行yield()方法后转入就绪(ready)状态;
- sleep()方法声明抛出InterruptedException,而yield()方法没有声明任何异常;
- sleep()方法比yield()方法(跟操作系统CPU调度相关)具有更好的可移植性。
Syncronized关键字修饰静态方法和成员方法,分别锁住了什么
- synchronized修饰静态方法以及同步代码块的synchronized (类.class)用法锁的是类
- synchronized修饰成员方法,线程获取的是当前调用该方法的对象实例的对象锁
Synchronized和lock 的区别
- Lock是一个接口,而synchronized是Java中的关键字
- synchronized在发生异常时,会自动释放线程占有的锁,因此不会导致死锁现象发生;而Lock在发生异常时,如果没有主动通过unLock()去释放锁,则很可能造成死锁现象
- Lock可以让等待锁的线程响应中断,而synchronized却不行,使用synchronized时,等待的线程会一直等待下去,不能够响应中断
- 通过Lock可以知道有没有成功获取锁,而synchronized却无法办到
线程池原理
线程池做的工作主要是控制运行的线程的数量,处理过程中将任务放入队列,然后在线程创建后启动这些任务,如果线程数量超过了最大数量超出数量的线程排队等候,等其它线程执行完毕,再从队列中取出任务来执行。他的主要特点为:线程复用;控制最大并发数;管理线程
异常
Throwable 是 Java 语言中所有错误或异常的超类,下一层分为 Error 和 Exception
Error 类是指 java 运行时系统的内部错误和资源耗尽错误;应用程序不会抛出该类对象,如果出现了这样的错误,除了告知用户,剩下的就是尽力使程序安全的终止
Exception 又有两个分支,一个是运行时异常-RuntimeException ,一个是编译时异常-CheckedException
运行时异常eg:空指针、数组越界、栈溢出、IO异常
编译时异常eg:找不到类
Throw 和 throws 的区别
- throws用在方法上,后面跟的是异常类,可以跟多个;而 throw用在方法内,后面跟的是异常对象
- throws 表示出现异常的一种可能性,并不一定会发生这些异常;throw 则是抛出了异常,执行 throw 则一定抛出了某种异常对象
注解
Annotation(注解)是 Java 提供的一种对元程序中元素关联信息和元数据(metadata)的途径和方法。Annatation(注解)是一个接口,程序可以通过反射来获取指定程序中元素的 Annotation对象,然后通过该 Annotation 对象来获取注解中的元数据信息
4种标准元注解
@Target:指定Annotation所修饰的对象范围
@Retention:指定该 Annotation 被保留的时间长短
- SOURCE:在源文件中有效(即源文件保留)
- CLASS:在class 文件中有效(即 class 保留)
- RUNTIME:在运行时有效(即运行时保留)
@Documented:描述-javadoc,用于描述其它类型的 annotation 应该被作为被标注的程序成员的公共 API
@Inherited:是一个标记注解,@Inherited 阐述了某个被标注的类型是被继承的,如果一个使用了@Inherited 修饰的 annotation 类型被用于一个class,则这个annotation 将被用于该class 的子类
内部类
定义在类内部的类就被称为内部类,根据定义的方式不同,内部类分为:静态内部类,成员内部类,局部内部类,匿名内部类四种
静态内部类
- 静态内部类可以访问外部类所有的静态变量和方法,即使是 private 的也一样
- 静态内部类和一般类一致,可以定义静态变量、方法,构造方法等
- 其它类使用静态内部类需要使用"外部类.静态内部类"方式,eg:Out.Inner inner = new Out.Inner();inner.print();
- Java集合类HashMap内部就有一个静态内部类Entry,Entry是HashMap存放元素的抽象,HashMap 内部维护 Entry 数组用了存放元素,但是 Entry 对使用者是透明的。像这种和外部类关系密切的,且不依赖外部类实例的,都可以使用静态内部类
成员内部类
定义在类内部的非静态类,就是成员内部类
成员内部类不能定义静态方法和变量(final 修饰的除外),这是因为成员内部类是非静态的,类初始化的时候先初始化静态成员,如果允许成员内部类定义静态变量,那么成员内部类的静态变量初始化顺序是有歧义的
局部内部类
定义在方法中的类,就是局部类;如果一个类只在某个方法中使用,则可以考虑使用局部类
匿名内部类
匿名内部类我们必须要继承一个父类或者实现一个接口,当然也仅能只继承一个父类或者实现一个接口。同时它也是没有 class 关键字,这是因为匿名内部类是直接使用 new 来生成一个对象的引用
泛型
泛型提供了编译时类型安全检测机制,该机制允许程序员在编译时检测到非法的类型
类型擦除
Java 中的泛型基本上都是在编译器这个层次来实现的。在生成的 Java 字节代码中是不包含泛型中的类型信息的。使用泛型的时候加上的类型参数,会被编译器在编译的时候去掉。这个过程就称为类型擦除
其他
java8的新特性
- Lambda 表达式 − Lambda允许把函数作为一个方法的参数
- Date Time API − 加强对日期与时间的处理
- Stream API −新添加的Stream API(java.util.stream) 把真正的函数式编程风格引入到Java中
- Optional 类 − Optional 类已经成为 Java 8 类库的一部分,用来解决空指针异常
- 默认方法− 默认方法就是一个在接口里面有了一个实现的方法
- 新工具− 新的编译工具,如:Nashorn引擎 jjs、 类依赖分析器jdeps
- Nashorn, JavaScript 引擎 − Java 8提供了一个新的Nashorn javascript引擎,它允许我们在JVM上运行特定的javascript应用

 浙公网安备 33010602011771号
浙公网安备 33010602011771号