数据操作-Sort(排序)
插入排序(基于比较的排序算法) 1.直接插入(性能要比冒泡和简单选择排序好些)
2.折半插入 (直接插入改进版)
3.希尔排序
交换排序
1.冒泡排序
2.快速排序
选择排序
1.简单选择
2.堆排序--------插入删除
归并排序
1.归并排序
小总结: (一)经过一趟排序,能够保证一个关键字达到最终位置,这样的排序是交换类:(冒泡,快速)和选择类:(简单选择,堆) (二)排序算法关键字比较次数和原始序列无关---简单选择排序和折半插入排序 (三)排序算法的排序趟数和原始序列有关---交换类的排序(冒泡,快速)
(四)借助于“比较”进行排序的算法,在最坏情况下的时间复杂度至少为O(nlog2n)
(五)快些选队(快希选堆):不稳定; 快速排序,希尔排序,简单选择排序,堆排序都是不稳定排序,其他都是稳定排序
(六)快些排队(快希排堆):
平均情况下时间复杂度都是O(nlog2n),其他都是O(n2);最快情况下快速排序的时间复杂度为O(n2),其他的和平均情况下相同
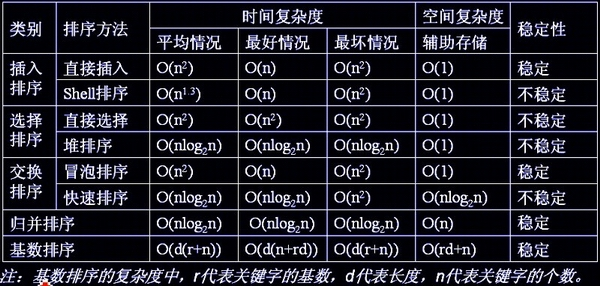
时间复杂度表
数据结构和交换方法
#define max 10 typedef struct { int r[max+1]; int length; }sqList; void swap(sqList *l,int i,int j) { int temp=l->r[i]; l->r[i]=l->r[j]; L->r[j] = temp; } void swaparr(int k[],int i,int j) { int temp=k[i]; k[i]=k[j]; k[j]=temp; }
一:插入排序
1:直接插入
(每次将一个待排序的记录,按其关键字大小插入到前面已经排好序的子序列中的适当位置,直到全部记录插入完成为止。)
void InsertSort(SqList *L) { int i, j, loop, count2; loop = count = 0; for (i = 2; i <= L->length;i++) { if (L->r[i]<L->r[i-1]) //若是前面第一个都不满足顺序,那么我们就要去循环 { L->r[0] = L->r[i]; for (j = i - 1; L->r[j]>L->r[0]; j--) //将大的数据全部向后移动,从后向前防止数据覆盖 { loop++; L->r[j + 1] = L->r[j]; //记录后移 } L->r[j + 1] = L->r[0]; //插入到正确位置 count++; } } printf("loop move count:%d, swap insert count:%d\n", loop, count); }
2:折半插入
(通过不断地将数据元素插入到合适的位置进行排序,在寻找插入点时采用了折半查找。)
1)使用key存储插入值
void BinSort(int k[],int n) { int i,j,//数据位置 low,high,mid,key;//已排序的数列中最小中间最大数据位置 for(i=1;i<n;i++) { key=k[i];//将待插入记录存在key low=1,high=i-1; while(low<=high)//在已经有序的表中折半查找插入位置 { mid=(low+high)/2; if(key<k[mid])high=mid-1; else low=mid+1; } for(j=i;j>low;j--)//将low之后的数据整体后移 { k[j]=k[j-1]; } k[low]=key;//插入操作 } }
2)使用k[0]存储插入值
void BinSort(int k[],int n) { int i,j,//数据位置 low,high,mid;//已排序的数列中最小中间最大数据位置 for(i=2;i<=n;i++) { k[0]=k[i];//将待插入记录存在k【0】 low=1,high=i-1; while(low<=high)//在已经有序的表中折半查找插入位置 { mid=(low+high)/2; if(k[0]<k[mid])high=mid-1; else low=mid+1; } for(j=i-1;j>=high+1;j--)//将low之后的数据整体后移 { k[j+1]=k[j]; } k[high+1]=k[0];//插入操作 /*或者 for(j=i-1;j>=low;j--)//将low之后的数据整体后移 { k[j+1]=k[j]; } k[low]=k[0]; */ } }
3:希尔插入
(把记录按下标的一定增量分组,对每组使用直接插入排序算法排序;随着增量逐渐减少,每组包含的关键词越来越多,当增量减至1时,整个文件恰被分成一组,算法便终止。图片演示看这个https://www.cnblogs.com/ssyfj/p/9510832.html)
void shellSort(sqList *l) { int i,j; int delta=l->length; do { delta=delta/3+1;//自定义增量变化公式 for(i=delta+1;i<=l->length;i++)//用delta分组的数据进行直接插入排序 { if(l->r[i]<l->r[i-delta]) { l->r[0]=l->r[i]; for(j=i-delta;j>0&&l->r[j]>l->r[0];j-=delta) { l->r[j+delta]=l->r[j]; } l->r[j+delta]=l->r[0]; } } }while(delta>1) }
二:交换排序
1:冒泡排序
(两两比较相邻记录的关键字,如果反序则交换,直到没有反序的记录为止)
void bubbleSort(sqList *l) { int i,j; int flag=1; /** for(i=1;i<l->length;i++) { for(j=l->length-1;j>=i;j--)//从后往前两两比较 { if(l->r[j]>l->r[j+1) { swap(l,j,j+1); } } } **/ for(i=1;i<l->length;i++) { flag=0; for(j=l->length-1;j>=i;j--)//从后往前两两比较 { if(l->r[j]>l->r[j+1) { swap(l,j,j+1); flag=1; } } if(flag==0)break;//上次排序中没有发生序列变化,说明已经完成排序 } } }
2:快速排序
(快排----冒泡排序的改进版:【关于快排优化和快排演示看这个https://www.cnblogs.com/ssyfj/p/9515744.html】
1.在待排序的元素任取一个元素作为基准(通常选第一个元素,但最的选择方法是从待排序元素中随机选取一个作为基准),称为基准元素; 2.将待排序的元素进行分区,比基准元素大的元素放在它的右边,比其小的放在它的左边; 3.对左右两个分区重复以上步骤直到所有元素都是有序的。)
1)递归快排
void quickSort(int k[],int low,int high) { int pivot; if(low<high) { pivot=Partition(k,low,high) quickSort(k,low,pivot-1); quickSort(k,pivot+1,high); } } int Partition(int k[],int low,int high) { int pivotkey; pivotkey=k[low];//用子表第一个记录左枢轴记录 while(low<high) //从表的两端交替向中间扫描 { while(low<high&&k[high]>=pivotkey)high--; swap(k, high, low); //将比枢轴记录小的记录交换到低端 while(low<high&&k[low]<=pivotkey)low++; swap(k, low, high);//将比枢轴记录大的记录交换到高端 } return low; //返回枢轴所在位置 }
2)非递归快排
void Push(linkStack &stack,int left,int right) { push(left); push(right); } int Partition(int k[],int low,int high) { int pivotkey; pivotkey=k[low];//用子表第一个记录左枢轴记录 while(low<high)//从表的两端交替向中间扫描 { while(low<high&&k[high]>=pivotkey)high--; swap(k, high, low); //将比枢轴记录小的记录交换到低端 while(low<high&&k[low]<=pivotkey)low++; swap(k, low, high);//将比枢轴记录大的记录交换到高端 } return low; //返回枢轴所在位置 } void norecQsort(int k[],int begin,int end) { //递归的算法主要是在划分子区间,如果要非递归实现快排,只要使用一个栈来保存区间就可以了。 linkStack sta; Push(sta,begin,end); while(!isEmptyStack(sta)) { int right,left; top(sta,right);pop(sta); top(sta,left);pop(sta); if(l>=r)continue; int mid=Partition(k,left,right); Push(sta,left,mid-1); Push(sta,mid+1,right); } }
三:选择排序
1:简单选择
(通过n-i次关键字间的比较,从n-i+1个记录中选出关键字最小的记录,并和第i(1<=i<=n)个记录交换之)
void SelectSort(SqList *L) { int i, j, min,count1,count2; count1 = count2 = 0; for (i = 1; i < L->length;i++) { min = i; //将当前下标定义为最小值下标 for (j = i + 1; j <= L->length;j++) //循环之后的数据 { count1++; if (L->r[min]>L->r[j]) //如果由小于当前最小值的关键字 min = j; //更新最小值 } if (i != min) //若是我们在上面循环中找到最小值,则min会改变,与i不同,就需要进行交换 { swap(L, i, min); count2++; } } printf("loop count:%d, swap count:%d\n", count1, count2); }
2:堆排序(不怎么懂,知道原理无法独自实现)
具体步骤图解和实现算法参考链接https://www.cnblogs.com/ssyfj/p/9512451.html
1:简介
堆排序是一种树形选择排序,在排序过程中可以把元素看成是一颗完全二叉树,每个节点都大(小)于它的两个子节点
1)当每个节点都大于等于它的两个子节点时,就称为大顶堆;
2)当每个节点都小于等于它的两个子节点时,就称为小顶堆。
2:步骤
1.将长度为n的待排序的数组进行堆有序化(层序遍历)构造成一个大顶堆 2.将根节点与尾节点交换并输出此时的尾节点 3.将剩余的n -1个节点重新进行堆有序化 4.重复步骤2,步骤3直至构造成一个有序序列
void swap(int K[], int i, int j) { int temp = K[i]; K[i] = K[j]; K[j] = temp; } //大顶堆的构造,传入的i是父节点 void HeapAdjust(int k[],int p,int n) { int i,temp; temp = k[p]; for (i = 2 * p; i <= n;i*=2) //逐渐去找左右孩子结点 { //找到两个孩子结点中最大的 if (i < n&&k[i] < k[i + 1]) i++; //父节点和孩子最大的进行判断,调整,变为最大堆 if (temp >= k[i]) break; //将父节点数据变为最大的,将原来的数据还是放在temp中, k[p] = k[i]; //若是孩子结点的数据更大,我们会将数据上移,为他插入的点提供位置 p = i; } //当我们在for循环中找到了p子树中,满足条件的点,我们就加入数据到该点p,注意:p点原来数据已经被上移动了 //若没有找到,就是相当于对其值不变 //插入 k[p] = temp; } //大顶堆排序 void HeapSort(int k[], int n) { int i; //首先将无序数列转换为大顶堆 for (i = n / 2; i > 0;i--) //注意由于是完全二叉树,所以我们从一半向前构造,传入父节点 HeapAdjust(k, i, n); //上面大顶堆已经构造完成,我们现在需要排序,每次将最大的元素放入最后 //然后将剩余元素重新构造大顶堆,将最大元素放在剩余最后 for (i = n; i >1;i--) { swap(k, 1, i); HeapAdjust(k, 1, i - 1); } } int main() { int i; int a[11] = {-1, 5, 2, 6, 0, 3, 9, 1, 7, 4, 8 }; HeapSort(a, 10); for (i = 1; i <= 10; i++) printf("%d ", a[i]); system("pause"); return 0; }
四:归并排序
1:归并排序
(将已有序的子序列合并,得到完全有序的序列;即先使每个子序列有序,再使子序列段间有序。若将两个有序表合并成一个有序表,称为二路归并。)
具体参考:https://www.cnblogs.com/linzeliang1222/p/13779914.html
void merge(int a[],int left,int mid,int right){ int m=right - left + 1; int arr[m]; int l = left; int r = mid + 1; int k = 0; while (l <= mid && r <= right) { if (a[l] < a[r]) { arr[k++] = a[l++]; } else { arr[k++] = a[r++]; } } while (l <= mid) { arr[k++] = a[l++]; } while (r <= right) { arr[k++] = a[r++]; } k = 0; while (k < arr.length()) { a[left++] = arr[k++]; } } }
1)递归归并
void 归并排序(int k[],int start,int end){//先排序再合并 int mid; if(start<end){ mid=(start+end)/2; 归并排序(k,start,mid); 归并排序(k,mid+1,end); merge(k,start,mid,end); } }
2)非递归归并
void 归并排序(int a[],int len){ int i; //子数组大小分别为1、2、4、8···,刚开始是1然后2(自底向上, //即先按照一个数组两个个元素排序然后四个) //i为1时是两个元素一个数组,2时四个元素一个数组,进行排序 for ( i = 1; i < len; i += i) { //left为0从最左端开始 int left = 0; //mid和right是固定的 int mid = left + i - 1; int right = mid + i; //进行合并,将数组两两有序合并 while (right < len) { //merge方法和递归用的一样 merge(a, left, mid, right); //移到下一组继续合并 left = right + 1; mid = left + i - 1; right = mid + i; } //由于并不是所有的数组大小都刚好一样大,最后一组不一定满了, //所以对最后一组再来合并 if (left < len && mid < len) { merge(a, left, mid, len - 1); } }


 浙公网安备 33010602011771号
浙公网安备 33010602011771号