

爬虫基本原理
阅读目录
- 一 爬虫是什么
- 二 爬虫的基本流程
- 三 请求与响应
- 四 Request
- 五 Response
- 六 总结
一 爬虫是什么
# 1、什么是互联网? 互联网是由网络设备(网线、路由器、交换机、防火墙等等)和一台台计算机连接而成,像一张网一样。 # 2、互联网建立的目的? 互联网的核心价值在于数据的共享/传递:数据是存放于一台台计算机上的,而将计算机互联到一起的目的就是为了能够方便彼此之间的数据共享/传递,否则你只能拿U盘去别人的计算机上拷贝数据了。 # 3、什么是上网?爬虫要做的是什么 我们所谓的上网便是由用户端计算机发送请求给目标计算机,将目标计算机的数据下载到本地的过程。 #3.1 只不过,用户获取网络数据的方式是: 浏览器提交请求->下载网页代码->解析/渲染成页面。 #3.2 而爬虫程序要做的就是: 模拟浏览器发送请求->下载网页代码->只提取有用的数据->存放于数据库或文件中 #3.1与3.2的区别在于: 我们的爬虫程序只提取网页代码中对我们有用的数据 # 4、总结爬虫 # 4.1 爬虫的比喻: 如果我们把互联网比作一张大的蜘蛛网,那一台计算机上的数据便是蜘蛛网上的一个猎物,而爬虫程序就是一只小蜘蛛,沿着蜘蛛网抓取自己想要的猎物/数据 # 4.2 爬虫的定义: 模拟浏览器向网站发起请求,获取资源后分析并提取有用数据的程序 # 4.3 爬虫的价值: 互联网中最有价值的便是数据,比如天猫商城的商品信息,链家网的租房信息,雪球网的证券投资信息等等,这些数据都代表了各个行业的真金白银,可以说,谁掌握了行业内的第一手数据,谁就成了整个行业的主宰,如果把整个互联网的数据比喻为一座宝藏,那我们的爬虫课程就是来教大家如何来高效地挖掘这些宝藏,掌握了爬虫技能,你就成了所有互联网信息公司幕后的老板,换言之,它们都在免费为你提供有价值的数据。
二 爬虫的基本流程

#1、定义url 根据需求去定义需要去爬取网页的URL(get、post) #2、发起请求 使用http库想目标站点发起请求,即发起一个request request包含:请求头、请求体等 #3、获取响应内容 如果服务器能正常响应,则会得到一个response response包含:html,json,图片,视频等 #4、解析内容 解析html数据:正则表达式,第三方解析库如Beautifulsoup,pyquery等 解析json数据:json模块 解析二进制数据:以byte的方式写入文件 #5、保存数据 数据库 文件
三 请求与响应
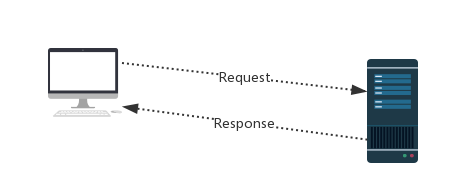
#http协议:http://www.cnblogs.com/linhaifeng/articles/8243379.html # Request:用户将自己的信息通过浏览器(socket client)发送给服务器(socket server) # Response:服务器接收请求,分析用户发来的请求信息,然后返回数据(返回数据中可能包含其他链接,如:图片,js,css等) #ps:浏览器在接收Reponse后,会解析其内容来显示给用户,而爬虫程序在模拟浏览器发送请求后接收Response,是要抓取其中的有用数据。
四 Request
#1、请求方式 常用的请求方式:GET,POST 其他请求方式:HEAD, PUT, DELETE,OPTIONS post和get请求最终都会拼接成这种形式:k1=xxx&k2=yyy&k3=zzz post请求的参数放在请求体内: 可用浏览器查看,存放与form data内 get请求的参数直接放在url后 #2、请求url url全称统一资源定位符,如一个网页文档,一张图片 一个视频等都可以用url唯一来确定 加载一个网页,通常都是先加载document文档, 在解析document文档的时候,遇到链接,则针对超链接发起下载图片的请求 #3、请求头 User-agent: 请求头中如果没有user-agent客户端配置 服务端可能将你当做一个非法用户 host cookie:保存用户登录信息 一般做爬虫都会加上请求头 #4、请求体 如果是get方式,请求体没有内容 如果是post方式,请求体是form data 1、登录窗口,文件上传等,信息都会被附加到请求体内 2、登录,输入错误的用户名密码,然后提交,就可以看到post,正确登录后页面通常会跳转,无法捕捉到post
五 Response
#1、响应状态 200:代表成功 301:永久重定向 302:临时重定向 403:权限问题 404:文件不存在 502:服务器错误 #2、Respone header set-cookie :可能有多个,是用来告诉浏览器,把cookie保存下来 #3、preview就是网页源代码 最主要的部分,包含了请求资源的内容 如网页html,图片 二进制数据等
六 总结
#1、总结爬虫流程: 定义url--->发送请求--->获取解析内容--->解析--->存储 #2、爬虫所需工具: 请求库:urllib,requests,selenium 解析库:正则,beautifulsoup,pyquery 存储库:文件,MySQL,Mongodb,Redis #3、爬虫常用框架: scrapy


import requests import re import time import hashlib def get_page(url): print('GET %s' %url) try: response=requests.get(url) if response.status_code == 200: return response.content except Exception: pass def parse_index(res): obj=re.compile('class="items.*?<a href="(.*?)"',re.S) detail_urls=obj.findall(res.decode('gbk')) for detail_url in detail_urls: if not detail_url.startswith('http'): detail_url='http://www.xiaohuar.com'+detail_url yield detail_url def parse_detail(res): obj=re.compile('id="media".*?src="(.*?)"',re.S) res=obj.findall(res.decode('gbk')) if len(res) > 0: movie_url=res[0] return movie_url def save(movie_url): response=requests.get(movie_url,stream=False) if response.status_code == 200: m=hashlib.md5() m.update(('%s%s.mp4' %(movie_url,time.time())).encode('utf-8')) filename=m.hexdigest() with open(r'./movies/%s.mp4' %filename,'wb') as f: f.write(response.content) f.flush() def main(): index_url='http://www.xiaohuar.com/list-3-{0}.html' for i in range(5): print('*'*50,i) #爬取主页面 index_page=get_page(index_url.format(i,)) #解析主页面,拿到视频所在的地址列表 detail_urls=parse_index(index_page) #循环爬取视频页 for detail_url in detail_urls: #爬取视频页 detail_page=get_page(detail_url) #拿到视频的url movie_url=parse_detail(detail_page) if movie_url: #保存视频 save(movie_url) if __name__ == '__main__': main() #并发爬取 from concurrent.futures import ThreadPoolExecutor import queue import requests import re import time import hashlib from threading import current_thread p=ThreadPoolExecutor(50) def get_page(url): print('%s GET %s' %(current_thread().getName(),url)) try: response=requests.get(url) if response.status_code == 200: return response.content except Exception as e: print(e) def parse_index(res): print('%s parse index ' %current_thread().getName()) res=res.result() obj=re.compile('class="items.*?<a href="(.*?)"',re.S) detail_urls=obj.findall(res.decode('gbk')) for detail_url in detail_urls: if not detail_url.startswith('http'): detail_url='http://www.xiaohuar.com'+detail_url p.submit(get_page,detail_url).add_done_callback(parse_detail) def parse_detail(res): print('%s parse detail ' %current_thread().getName()) res=res.result() obj=re.compile('id="media".*?src="(.*?)"',re.S) res=obj.findall(res.decode('gbk')) if len(res) > 0: movie_url=res[0] print('MOVIE_URL: ',movie_url) with open('db.txt','a') as f: f.write('%s\n' %movie_url) # save(movie_url) p.submit(save,movie_url) print('%s下载任务已经提交' %movie_url) def save(movie_url): print('%s SAVE: %s' %(current_thread().getName(),movie_url)) try: response=requests.get(movie_url,stream=False) if response.status_code == 200: m=hashlib.md5() m.update(('%s%s.mp4' %(movie_url,time.time())).encode('utf-8')) filename=m.hexdigest() with open(r'./movies/%s.mp4' %filename,'wb') as f: f.write(response.content) f.flush() except Exception as e: print(e) def main(): index_url='http://www.xiaohuar.com/list-3-{0}.html' for i in range(5): p.submit(get_page,index_url.format(i,)).add_done_callback(parse_index) if __name__ == '__main__': main()
转载自:http://www.cnblogs.com/linhaifeng/articles/7773496.html
