Copper Loser 的题解……
有一个 的网格,有 次操作,每次形如有三种:将 // 染色,其中 。 第三种操作至多只有 次,问之中有多少个格子被染过色。
扫描线板子题,首先令 ,然后考虑如何去掉被重复染色的部分。
对于横线与竖线的,离散化之后使用扫描线求值即可。
由于斜线之后 条,可以将每条斜线和所有其他线的交点算出来,然后去重即可。
时间复杂度 。
给定一棵有 个节点的树 ,保证一个节点的父亲编号小于它的编号。问有多少个有 的节点的树 ,满足对于所有 在 和 上的最近公共祖先相同,对于所有 , 和 在 中的最近公共祖先编号 。
对于第一条限制,就确定了 上 形成的虚树就是 。
我们考虑从 中逐个删除节点得到 的过程。
考虑特殊情况 ,则对于当前最大的节点 ,不存在 , 的最近公共祖先为 。这也就意味着 至多只有一棵子树,所以可以直接将这个点删去。
反转这个过程,也就意味这我们可以从小到大把节点插在一条树边上,或者挂在一个节点下面,成为它的儿子。假设当前大小为 ,则一共有 种方案,所以这种情况的答案就是 ,可以直接 计算。
这给了我们一个想法,对于当前要插入的节点其他的节点会是完全相同的,这也就意味着答案可能和 的形态无关,实际上确实是这样的。
考虑回到一般情况 ,仍然考虑从大到小删除,考虑当前最大的节点 ,由于限制被放宽了,所以它可能会存在若干个儿子。但是,由于公共祖先编号要 ,也就意味着它至多只有一个儿子的子树中存在编号 的节点。那么,我们先跳过这个节点的删除,接着删除比它小的节点,由于上面的那一条限制,在删除到某一个编号 的节点时, 只剩下一个儿子了,也就可以把 删除了。所以我们考虑在删除 的过程中同时删除掉 。
不难发现 都会对应唯一的 , 也至多只能对应一个 。
考虑反过来加入的过程,加入一个节点 时,可能会将一个 的节点作为父亲捆绑加入,而这种情况下,这一对点只能是放在一条树边上的。
设计 DP 状态 表示当前要加入 号节点,在 中已经被加入了的节点集合为 。则最终的答案就是 。
考虑转移:
如果 ,说明 号节点已经被加入了,所以直接跳过,。
否则,我们可以按照正常的方式转移 ,也就是 。
或者可以捆绑一个 的节点一起加入,转移为 。
时间复杂度 。
一棵生成树 ,以及一个非树边边集 ,给定若干个关键点,问有多少个 的子集 ,使得存在关键点 ,使得在 中加入 中的所有边得到的图, 可以是一个以 为根的 dfs 树。
是 dfs 树,也就意味着 中所有的边都是返祖边,不是横插边。
一个边集 可能对于多个关键点合法,考虑容斥。
设对于关键点集合 ,在以这个集合中任意一个点为根是,均是返祖边的边数量为 ,则最终答案为 。
考虑什么样的边会对点集 来说均是返祖边:
建出 点集在 上的虚树,则 要么是虚树的一条树边,要么被虚树的一条虚边包含,要么就是一条不在虚树上的返祖边(在以某一个虚树或虚边上的点的子树内)。
钦定 为根,考虑在 所有点的 lca 处计算贡献,记 表示当前以 为根,只考虑子树内的边的所有情况的带符号和。记 为在 的子树外的返祖边数量(可能在以 为根时是横插边,但是以 为根是返祖边)。
则 最终对答案的贡献为 。
考虑如何转移,假设 为 的子树, 向 的转移会带上很多从满足条件的边的贡献,具体的,就是满足上面说的两种情况的贡献,所以考虑事实维护一个数组 来处理这个贡献。不难知道 初始为 。
如果有一条边 ,则 的子树内所有的 变成 ;将 向 转移时,对于 某一个子树 内的所有返祖边 ,会将所有不在 子树内的点 变成 。
发现这些变化都是子树乘,可以通过对点的 dfs 序建线段树维护。
由于 只能从每一个子树内选择一个点转移,所以可以使用背包维护 。
最终的 ,如果 是关键点,则 。
如果 不是关键点,则 。
但是发现这样处理只能通过特殊性质 AB,也就意味着,有横插边对答案造成了影响。
我们发现,被漏算的部分,是 的转移时,假设选择的子树为 和 ,同时没有选择点 ,这时横跨了 的横插边是会对答案做贡献的,具体如下图中的红边:
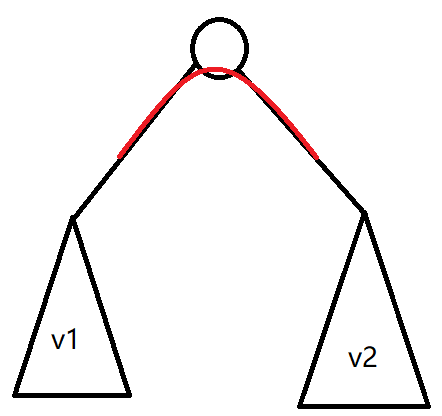
还是将子树拍成 dfs,则这样的每条边 ,都会对 或 的答案做贡献。
将每一对 抽象成二维平面上的一个点,我们相当于要做若干次矩形乘和一次矩形和的操作。
对于每一个 ,把这样的操作离散化之后做一次扫描线即可。
总体复杂度 。
给定一个带边权内向完全二叉树,同时给出若干条从祖先到子孙的边,定义 为 到 的最短路长度,求 。
考虑处理出所有的 ,表示从祖先 走到子孙 的最短路, 为从子孙 走到祖先 的距离,则最终 就等于 ,其中 为 的最近公共祖先。
的值可以使用一个类似 floyd 的过程求出, 可以直接通过树上差分得到。
最终求和是简单的。
总体复杂度 。
给定一个字符串 ,多次询问 ,有多少个 ,使得 。
由于 ,即 ,即 。
对于 ,上式等价于 。
将 后缀排序,上式在大多数情况下等价于 ,从大往小扫 数组,则对于每一个 ,我们可以使用树状数组维护出做贡献的 。
现在回到大多数情况下等价于的问题,我们会发现,当 的时候,它也可能有 。考虑怎么减去这种情况。
如果 ,就说明 是一个回文串,如果以 这个回文中心向外延伸,第一次不同的两个字符满足 ,则就会出现 ,这个东西可以用 manacher 找出来,并再做一次扫描线求解。
时间复杂度 。
有 堆书本,每一堆书本有两个参数 ,初始时 给定,。你需要进行 次合并,如果合并 和 ,则会消耗 的代价,得到一堆参数为 的书,要求最小化代价和。
发现合并的过程是一棵二叉树,对于 数组造成的代价,是每一个叶子节点到根的过程中作为右孩子的次数;对于 数组造成的贡献 ,只与树形态有关。
对于一棵二叉树,我们确定了每一个叶子在代价中的系数 ,则我们将所有的书本的 从小到大排序,所有的 从大到小排序,同时对位相乘即可。
现在的问题是我们要如何求出这个系数可重集 和 的关系。
考虑每次将若干叶子分裂的过程,那么我们会将集合中的若干个 变成 和 。根据贪心策略可以得到,我们必然选择前若干小的叶子分裂。
但是这个时候我们发现 并不是很好计算,考虑如何维护分裂,反转成为合并考虑:每一次删去所有的叶子,每一次删除的叶子树是逐渐减少的。
所以考虑钦定分裂的叶子数 ,每一次分裂的叶子数量不会减少。这样每一次所有非叶子节点的代价都会 ,所以可以直接计算。
发现这样的搜索十分优秀,可以通过此题。
代码


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 使用C#创建一个MCP客户端
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· ollama系列1:轻松3步本地部署deepseek,普通电脑可用
· 按钮权限的设计及实现