

基础10-文件读取/下载简述+实战挖掘
内容目录
1.任意文件读取/下载漏洞2.文件读取/下载常见函数3.探测手法 ../探测4.常见参数名5.实战挖掘文件下载漏洞
1.任意文件读取/下载漏洞
产生原因:一些网站的业务需要,可能提供文件查看或下载的功能,如果对用户查看或下载的文件不做限制,就能够查看或下载任意的文件,可以是源文件,敏感文件等等,同时没有对存读取文件的函数,读取文件的路径做到严格控制,且未校验或校验不严输出了文件内容。
2.文件读取/下载常见函数
fopen()函数打开一个文件或URL。
file_get_contents()函数把整个文件读入一个字符串中。
file()函数把整个文件读入一个数组。
readfile()函数读取一个文件,并写入到输出缓冲。
3.探测手法 ../探测
在路径中添加abc/../看是否能回溯
例如原URL地址为:https://baidu.com/download.php?filename=1.pdf
我们可以修改为:https://baidu.com/download.php?filename=aaa/../1.pdf
如果两次下载的文件是一样的,就说明可能存在漏洞。
4.常见参数名
&RealPath=、&readpath=、&FilePath=、&filepath=、&Path=、&path=、&Inputfile=、&inputfile=、&url=、&urls=、&Lang=、&dis=、&Data=、&data=、&readfile=、&filep=、&Src=、&src=、&menu=、META-INF=、name=等等等
在url中看到这些参数的时候就要注意一下了,可以尝试一下了。
5.实战挖掘文件下载漏洞
瞎逛,看见了一个企业的网站,发现存在下载,顺便看一眼。
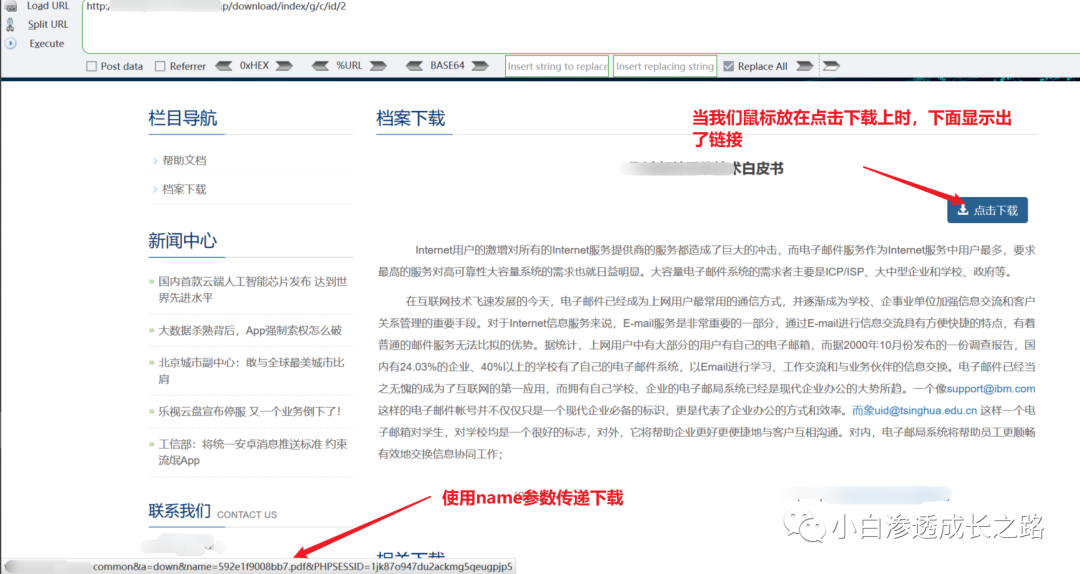
这里我们使用刚才说的回溯判断法,
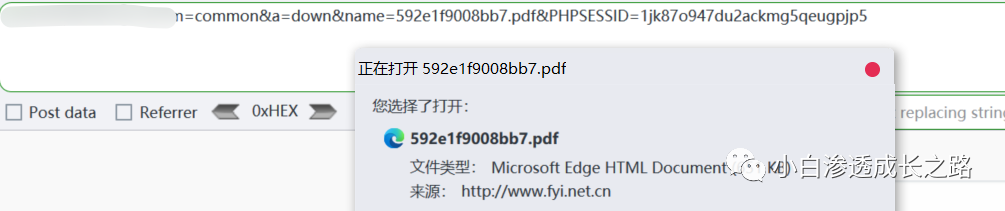
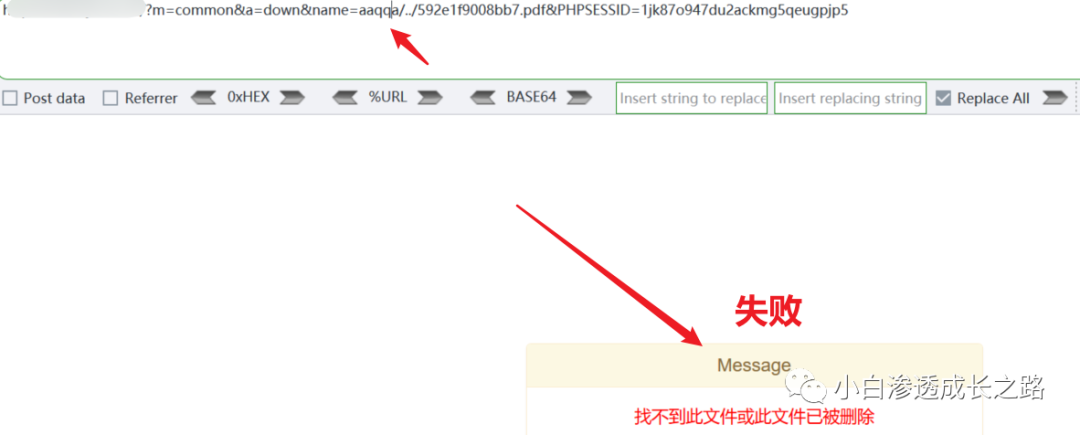
发现利用失败,难道这就放弃吗?不可能,FUZZ走一手再说。
修改域名其中一个字母为大写,报错,说明为linux系统,那我们就在name参数处跑/etc/password。
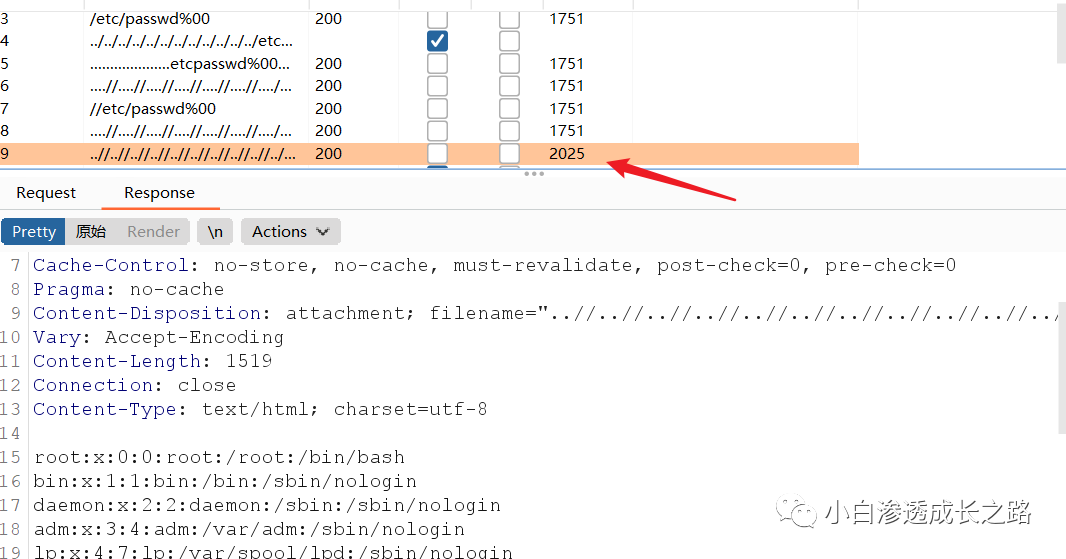
发现一个响应值不同的包,点开一看,直接吃🍉
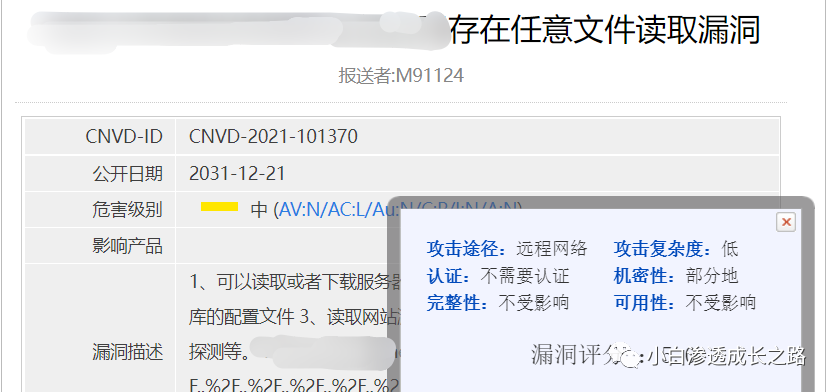
成功拿到一个任意文件下载漏洞。(其实还是可以去进一步挖掘,读一些敏感信息,最后还可能能拿到shell,这里就不搞了,顺手交个cnvd,小白瞎挖
大佬莫喷。)
【其实挖到这个后,我们可以更具网站特征去找同类网站,找源码搞通用,这又回到了信息收集的部分。
6.代码层漏洞绕过
1、未进行任何防御

2、双写进行绕过

3、利用编码进行绕过

4、利用%00截断后缀绕过

5、利用文件路径绕过

参考文章:https://blog.csdn.net/sycamorelg/article/details/111592282
暂时就这么多吧,小白一个,学到后面深入了再写。感谢各位大佬赏阅。
