性能优化:
数据库缓存、热点数据放到缓存。
数据库垂直拆分、不同的数据放到不同的数据库中存储。
主从复制、给数据库添加备份库。
读写分离。写数据库到主库,读数据到备份库。
配置集群。
分库:将热点数据放到一个库,将冷数据放到另外数据库。
分表:将同一张表的数据放到不同的库中的相同表。例如:按照 id <3000 的放在库1。id > 3000的放在库2。
mysql 数据库引擎:
MyISAM :使用的表表锁。
InnoDB:使用的是行锁。并发性能更好。
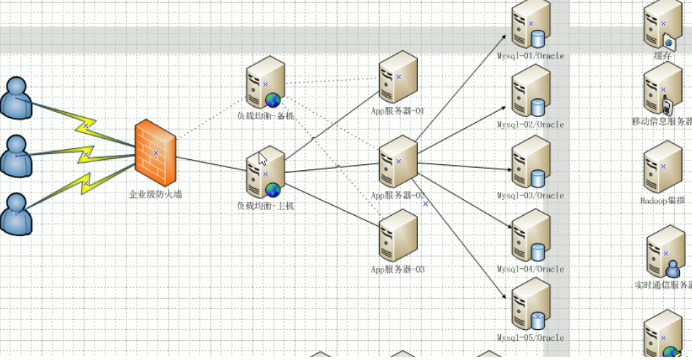
高性能架构:
用户 》防火墙 》负载均能服务器nginx 》web服务器群 》数据库服务器群 》 缓存、大文件、等等冷数据。
![]()
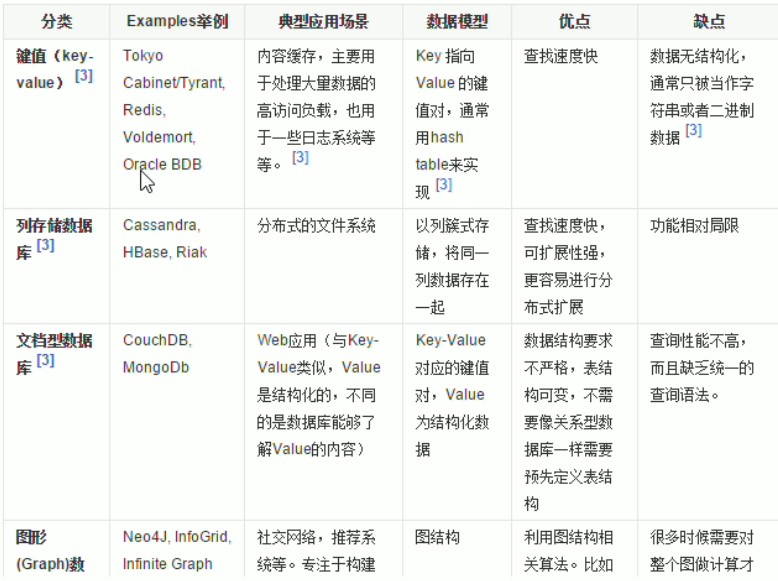
文档数据库的代表: MongoDB
列存储数据库的代表:HBase
图关系数据库的代表:Neo4j,InfoGrid
高并发的操作不建议多表查询
noSql数据库的的数据模型: kv键值对、Bson、列族、图。
![]()
关系型数据库的ACID:
A:(Atomicity)原子性
C:(Consistency)一致性
I:(Isolation)独立性
D:(Durability)持久性
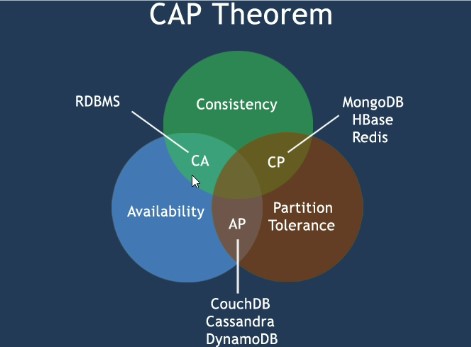
Nosql数据库的CAP
C:Consistency 强一致性(数据精准)
A:Availability 可用性(系统稳定可用,高可用)
P:Partition tolerance 分布式容错性 (数据一致,不出错)
CAP的三进二
一个分布式系统不可能同事满足CAP
CA:单点集群,满足一致性,可用性的系统。通常扩展性不强。
CP:满足一致性,分布式容错的系统。性能不高。
AP:满足可用性和分布式容错性,通常对一致性要求低。
![]()
BASE:基本可用,软状态,最终一致性。(通过对系统放松对某一时刻的数据一致性,换取系统整体伸缩性和性能的提升。)
负载均衡:例如:薅羊毛,不能顶住一个羊薅。
分布式:不同多台服务器上部署不同的服务模块
集群:不同的服务器上部署相同的服务(机器多力量大)


 浙公网安备 33010602011771号
浙公网安备 33010602011771号