#1 BanG Dream It's MyGOlang!!!!!

长期素食导致的 - [pixiv111124804]

睦头人 (\(\mathrm{a\color{red}{ctypedef}}\) 诱捕器) - [pixiv110897467]
但是这其实是一篇正经的 Golang 上手简记,并不是 MyGO 简评(MyGO 简评还在咕着(大概率不补了
鉴于后端用 go,有必要开展 golang 大学习
references: Go语言圣经、Go快速入门、《The Way to Go》中文译本、Go语言高级编程、Go语言简明教程、Go语言高性能编程
这里只以最简约的方式记录一些要点,和一点自己实验得到的认识,意在快速了解 go 的基本语言特性
参考资料主要是 references 第一个《Go 语言圣经》。引用块里的内容大多是其中的原文
0 Get Start
代码扩展名 .go
用 go run test.go 直接运行。也可以先 go build test.go 编译成可执行文件,再 ./test
用 go run <file> 来 run 单个文件,用 go run <directory> 来运行某目录下的 package main
go 项目由包 (package) 组织
任何 go 代码都以 package xxx 开始,声明此代码属于什么包
下面几行语句导入依赖包,import xxx 等
注释语法同 c/c++
注意 go 的神秘特性:
- 不允许出现被
import但没有被使用的包 - 不允许出现声明了但没有被使用的局部名字
- go 的编译输出只有错误没有警告
非常逆天。
1 声明相关
1.0 命名
标识符命名:典规则,但支持 unicode
在 go 中,内建语句属于关键字,但一些内建类型名称,字面量和函数名属于预定义名字
预定义名字有:
内建常量: true false iota nil
内建类型: int int8 int16 int32 int64
uint uint8 uint16 uint32 uint64 uintptr
float32 float64 complex128 complex64
bool byte rune string error
内建函数: make len cap new append copy close delete
complex real imag
panic recover
用户标识符不能与关键字相同,但是可以与预定义名字相同,你可以在使用中重新定义他们,在一些特殊的场景中重新定义它们也是有意义的
比如可以这样
var int int
fmt.Println(int) // 0
不过你这么干之后下面就都不能再用 int 了
var a int = 1 // 报错
在全局定义的名字是“包级名字”,如全局量、全局函数等
包级名字首字母大小写决定了该名字是否在其他包中可见。小写字母开头的名字是该包私有的,可以在该包的每个源文件中访问,但其他包不能访问;大写字母开头名字是该包导出的,可以被其他包访问,比如 package fmt 中的 Printf
1.1 变量
声明语句定义了各种实体对象
var,const,type,func 声明分别对应变量、常量、类型、函数
type 类似 typedef xxx xxx 或 using xxx = xxx
/*1*/ var s string = ""
/*2*/ var s string
/*3*/ var s = ""
/*4*/ var a, b, c int = 1, 2, 3
/*5*/ var a, b, c = 1, "2", 3.0
/*6*/ s := ""
/*7*/ a, b, c := 1, "2", 3.0
/*8*/ var (
a = 5
b string = ""
)
-
定义
s,类型string,初值为"" -
未指定初值时根据默认零值赋为
""
- 数值类型的默认零值是
0 bool零值为falsestring零值为""- 接口或引用类型(包括 slice、指针、map、chan 和函数)变量对应的零值是
nil - 数组或结构体等聚合类型对应的零值是每个元素或字段都是对应该类型的零值
因此,go 中不存在未初始化的变量
-
定义
s,类型由字面量""推导 -
多重声明,类型均为
int -
多重声明,类型自动推导。注意,(4) 写法仅能定义相同类型的一组量
-
简短变量声明,类型自动推导
-
多重简短声明,类型自动推导
这里有一个细节:
- 简短声明不允许用于声明全局变量
- 简短声明的
:=左侧的若干量可以不是新定义的,如果某个量在相同的词法域已经被声明过,那么:=对他的作用为赋值。同时要想使用:=,左侧必须至少一个变量是新定义的
全局变量初始化在 main() 执行前完成,局部变量在执行到时初始化
1.2 常量
const x int = 1
const x = 1
const x, y, z int = 1, 2, 3
- 常量必须赋初值,不存在默认零值规则
- 常量没有简短声明
多行常量定义时,如果一个常量没有写初始化,那么抄写上一个常量的初值表达式后计算其初值
const (
a = 5
b // 5
c // 5
d = 2
)
如果多个常量写在一行定义,其多重初始化的表达式也会复制给下一行
const (
a, b = 3, 4
c, d // 3, 4
)
iota 是一种只有常量初始化能用的东西
iota 的值在每次遇到 const 的第一行初始化时变成 0。在多重声明时,每遇到下一行初始化,值就 += 1。在同一行内,iota 值相等
const a = iota // 0
const b, c = iota, iota // 0, 0
const a,
b, c = iota, iota, iota // 0, 0, 0 -> 字面上换行不影响逻辑上是一行声明的
const (
x = iota // 0
y = 10
z = iota // 2
a, b, c = iota, iota, iota // 3, 3, 3
)
const (
x = 1 + iota // 1
y // 2
z // 3
)
1.3 指针
指向 int 的指针类型为 *int,使用 p = &x 取地址,*p 取值
右值不能被取地址。指针的零值为 nil
1.4 new
var p *int = new(int) // *p == 0
1.5 生命周期
包级名字的生命周期与程序相同
局部变量的生命周期持续到该变量不再被引用为止
那么 Go 语言的自动垃圾收集器是如何知道一个变量是何时可以被回收的呢?这里我们可以避开完整的技术细节,基本的实现思路是,从每个包级的变量和每个当前运行函数的每一个局部变量开始,通过指针或引用的访问路径遍历,是否可以找到该变量。如果不存在这样的访问路径,那么说明该变量是不可达的,也就是说它是否存在并不会影响程序后续的计算结果。
因为一个变量的有效周期只取决于是否可达,因此一个循环迭代内部的局部变量的生命周期可能超出其局部作用域。同时,局部变量可能在函数返回之后依然存在。
编译器会自动选择在栈上还是在堆上分配局部变量的存储空间,但可能令人惊讶的是,这个选择并不是由用 var 还是 new 声明变量的方式决定的。
var global *int func f() { var x int x = 1 global = &x } func g() { y := new(int) *y = 1 }f 函数里的 x 变量必须在堆上分配,因为它在函数退出后依然可以通过包一级的 global 变量找到,虽然它是在函数内部定义的;用 Go 语言的术语说,这个 x 局部变量从函数 f 中逃逸了。相反,当 g 函数返回时,变量
*y将是不可达的,也就是说可以马上被回收的。因此,*y并没有从函数 g 中逃逸,编译器可以选择在栈上分配*y的存储空间(译注:也可以选择在堆上分配,然后由 Go 语言的 GC 回收这个变量的内存空间),虽然这里用的是 new 方式。其实在任何时候,你并不需为了编写正确的代码而要考虑变量的逃逸行为,要记住的是,逃逸的变量需要额外分配内存,同时对性能的优化可能会产生细微的影响。Go 语言的自动垃圾收集器对编写正确的代码是一个巨大的帮助,但也并不是说你完全不用考虑内存了。你虽然不需要显式地分配和释放内存,但是要编写高效的程序你依然需要了解变量的生命周期。例如,如果将指向短生命周期对象的指针保存到具有长生命周期的对象中,特别是保存到全局变量时,会阻止对短生命周期对象的垃圾回收(从而可能影响程序的性能)。
1.6 类型
type 类型名字 底层类型
与 typedef 同。这个类型名字也是和普通变量同级的名字,如果新创建的类型名字的首字符大写,则在包外部也可以使用
1.7 作用域
由于垃圾回收机制,变量的作用域不等于变量的生命周期
其他与 c++ 同
1.x 注
-
我们失去了通用的 "引用类型",现在这里只有指针了
-
关于 “元组赋值”:
f, err = os.Open("foo.txt") // ok f, err, a = os.Open("foo.txt"), true // 错误的
2 运算符の噩耗
下面是算术运算、逻辑运算和比较运算的二元运算符(按优先级排序)
* / % << >> & &^
+ - | ^
== != < <= > >=
&&
||
-
各种赋值不再是运算符。比如
=,+=,等等。所以a += (b += 2) // 错误的 a = b = c // 错误的 -
自增自减不再是运算符。现在
++和--只能后置,如a++,并且是语句而非运算符a = b++ // 错误的 -
逗号不再是运算符。
,被用于 “元组赋值” 去了a = 5, b = 3, c = 4 // 错误的 a = 5; b = 3; c = 4 // ok
原先能一行写完的精妙代码现在只能拆成一堆 shit
你吗的,不让压行 /fn
其他一些细节:
- 不再有
~号。^号在用于双目运算时表示异或,单目运算时表示按位取反 - 取模运算得到结果的符号只取决于被模数。
-5 % 2,-5 % -2都等价于-(5 % 2) - 添加了一个
&^号,表示 “位清除(bit clear)”。a &^ b的意思是,如果b中某一位是1,则将a的这一位设置为0。注意到它等价于a & (^b),但是在一些情况下使用&^要比拆开写更易于规避整形溢出
还有很重要的一点,go 要求运算符两侧操作数类型相同是非常严苛的,不会自动隐式类型转换
int 和 int16 相加会报错,int 和 float32 相加也会报错。必须显式指明类型转换才能运行
使用 int(...),float64(...) 来实现强制类型转换
给类型添加括号:(int)(...),(float64)(...) 亦可
并且:相同底层类型的不同名字被视为不同的类型,他们之间做运算也需要类型转换
type Celsius float64 // 摄氏温度
type Fahrenheit float64 // 华氏温度
Celsius 和 Fahrenheit 分别对应不同的温度单位。它们虽然有着相同的底层类型 float64,但是它们是不同的数据类型,因此它们不可以被相互比较或混在一个表达式运算。刻意区分类型,可以避免一些像无意中使用不同单位的温度混合计算导致的错误;因此需要一个类似 Celsius(t) 或 Fahrenheit(t) 形式的显式转型操作才能将 float64 转为对应的类型。Celsius(t) 和 Fahrenheit(t) 是类型转换操作,它们并不是函数调用。类型转换不会改变值本身,但是会使它们的语义发生变化。
对于每一个类型 T,都有一个对应的类型转换操作 T(x),用于将 x 转为 T 类型(译注:如果 T 是指针类型,可能会需要用小括弧包装 T,比如 (*int)(0)`)。
3 基本数据类型
3.1 整型 & 字符
int,int8,int16,int32,int64
uint,uint8,uint16,uint32,uint64
未指定大小的 int 和 uint 的具体大小由实现定义
go 中区分 “字符” 与 “字符串”,字符用单引号,字符串双引号
但是,go 没有提供字符的底层类型,你可以用各种整型来存一个字符
一般我们存 ascii 字符用 byte,底层类型为 uint8
unicode 占用 2 或 4 字节,一般用 int16 或者 int
go 预定义了一种 unicode 类型 rune,其底层为 int32
最后,还有一种无符号的整数类型
uintptr,没有指定具体的 bit 大小但是足以容纳指针。uintptr类型只有在底层编程时才需要,特别是 Go 语言和 C 语言函数库或操作系统接口相交互的地方。
- 按照通用规则,有符号整数的最高一个 bit 是符号位
- 注意,浮点数到整数的类型转换会丢掉所有小数位(向零取整)而不是四舍五入
- 以
0开头的整数字面量将被视为八进制数,比如0666(438)
3.2 浮点
float32 (float)大约精确到小数点后 6 位
float64 (double)大约精确到小数点后 15 位
合法的浮点数:.1,15.,2e5,等等
浮点数值包括 +Inf,-Inf 和 NaN
用 math.NaN() 获得一个 NaN。NaN 和任何东西都不相等,包括自己。使用 math.isNaN() 来测试一个浮点数是不是一个 NaN
3.3 复数
complex64 和 complex128,精度分别与 float32 和 float64 相同
使用 real() 和 imag 得到实部与虚部
var x complex128 = complex(1, 2) // 1+2i
var y complex128 = complex(3, 4) // 3+4i
fmt.Println(x*y) // "(-5+10i)"
fmt.Println(real(x*y)) // "-5"
fmt.Println(imag(x*y)) // "10"
复数字面量形如 2i,1 + 2i
计算 Math.Sqrt(-1) 会得到 NaN,用 math/cmplx 包中的 cmplx.Sqrt(-1) 得到 i
3.4 布尔
true 和 false
- go 中
and,or等不是运算符 - go 的
&&和||依旧做短路运算 - 布尔和整型互相之间均不能直接强制类型转换。逆天
3.5 字符串
字符串的类型就是 string,不同于数组、切片等,是独立的基本数据类型
go 认为,字符串是一排不可变字节排成的序列
所以一个字符串中可以混杂着以不同的字节数存储的字符,比如:
使用 len() 获取字符串的字节数
s := "hello, world"
fmt.Println(len(s)) // 12 --> 每个字符用 1 字节
n := "mihoyo: 原神怎么你了"
fmt.Println(len(n)) // 26 --> "mihoyo: " 这一段每个字符一个字节, 后面每个汉字 3 字节
使用 s[i] 取出字符串的第 i 字节,i 必须在 0 ~ len(s) - 1 之间,否则程序 panic
使用 s[i:j] 左闭右开地取第 i ~ j 字节。string 的切片还是 string
和 python 一样,参数可以省略。比如 s[i:],s[:j],s[:]
字符串可以 +,可以 == 和大小比较。大小比较为逐字节比较
字符串每一字节的值不可变!不能给 s[i] 赋值
3.5.1 【关于 ASCII】
双引号包含的字符串字面量中支持各种 ascii 码转义
\a 响铃
\b 退格
\f 换页
\n 换行
\r 回车
\t 制表符
\v 垂直制表符
\' 单引号(只用在 '\'' 形式的rune符号面值中)
\" 双引号(只用在 "..." 形式的字符串面值中)
\\ 反斜杠
也可以通过 16 进制或 8 进制转义来表示一字节 ascii 字符
使用 \x 加两位 16 进制数字,比如 "A" 等同于 "\x41"
使用 \ 加三位 8 进制数字,比如 "\123",但是字符不能超过 \377,即 10 进制下 255
一个原生的字符串面值形式是`...`,使用反引号代替双引号。在原生的字符串面值中,没有转义操作;全部的内容都是字面的意思,包含退格和换行,因此一个程序中的原生字符串面值可能跨越多行(译注:在原生字符串面值内部是无法直接写 ` 字符的,可以用八进制或十六进制转义或 + " ` " 连接字符串常量完成)。唯一的特殊处理是会删除回车以保证在所有平台上的值都是一样的,包括那些把回车也放入文本文件的系统(译注:Windows系统会把回车和换行一起放入文本文件中)。
原生字符串面值用于编写正则表达式会很方便,因为正则表达式往往会包含很多反斜杠。原生字符串面值同时被广泛应用于 HTML 模板、JSON 面值、命令行提示信息以及那些需要扩展到多行的场景。
const GoUsage = `Go is a tool for managing Go source code. Usage: go command [arguments] ...`
3.5.2 【关于 Unicode】
通用的表示一个 Unicode 码点的数据类型是 int32,也就是 Go 语言中 rune 对应的类型;它的同义词 rune 符文正是这个意思。
我们可以将一个符文序列表示为一个 int32 序列。这种编码方式叫 UTF-32 或 UCS-4,每个 Unicode 码点都使用同样大小的 32bit 来表示。这种方式比较简单统一,但是它会浪费很多存储空间,因为大多数计算机可读的文本是 ASCII 字符,本来每个 ASCII 字符只需要 8bit 或 1 字节就能表示。而且即使是常用的字符也远少于 65536 个,也就是说用 16bit 编码方式就能表达常用字符。但是,还有其它更好的编码方法吗?
【UTF-8】
UTF8 是一个将 Unicode 码点编码为字节序列的变长编码。
UTF8 编码使用 1 到 4 个字节来表示每个 Unicode 码点,ASCII 部分字符只使用 1 个字节,常用字符部分使用 2 或 3 个字节表示。每个符号编码后第一个字节的高端 bit 位用于表示编码总共有多少个字节。如果第一个字节的高端 bit 为 0,则表示对应 7bit 的 ASCII 字符,ASCII 字符每个字符依然是一个字节,和传统的 ASCII 编码兼容。如果第一个字节的高端bit是110,则说明需要 2 个字节;后续的每个高端 bit 都以 10 开头。更大的Unicode码点也是采用类似的策略处理。
0xxxxxxx runes 0-127 (ASCII)
110xxxxx 10xxxxxx 128-2047 (values <128 unused)
1110xxxx 10xxxxxx 10xxxxxx 2048-65535 (values <2048 unused)
11110xxx 10xxxxxx 10xxxxxx 10xxxxxx 65536-0x10ffff (other values unused)
变长的编码无法直接通过索引来访问第 n 个字符,但是 UTF8 编码获得了很多额外的优点。
【字符串的 UTF8】
有很多 Unicode 字符很难直接从键盘输入,并且还有很多字符有着相似的结构;有一些甚至是不可见的字符(译注:中文和日文就有很多相似但不同的字)。Go 语言字符串面值中的 Unicode 转义字符让我们可以通过 Unicode 码点输入特殊的字符。有两种形式:
\uhhhh对应 16bit 的码点值,\Uhhhhhhhh对应 32bit 的码点值,其中 h 是一个十六进制数字;一般很少需要使用 32bit 的形式。每一个对应码点的 UTF8 编码。例如:下面的字母串面值都表示相同的值:
"世界"
"\xe4\xb8\x96\xe7\x95\x8c"
"\u4e16\u754c"
"\U00004e16\U0000754c"
上面三个转义序列都为第一个字符串提供替代写法,但是它们的值都是相同的。
【字符中的 UTF8】
Unicode 转义也可以使用在 rune 字符中。下面三个字符是等价的:
'世' '\u4e16' '\U00004e16'
但是,字符和字符串中的转义限制有所差别
对于小于 256 的码点值可以写在一个十六进制转义字节中,例如
\x41对应字符 'A',但是对于更大的码点则必须使用\u或\U转义形式。因此,\xe4\xb8\x96并不是一个合法的 rune 字符,虽然这三个字节对应一个有效的 UTF8 编码的码点。
go 提供的一些基本字符串工具假设你不关心一个一个的字符,只把字符串看成是字节流,比如 len() 返回的是字节数
如果关心具体每个字符,我们可以使用 unicode/utf8 包提供的工具
3.5.3 range 的隐式转换
幸运的是,go 语言的 range 循环在作用于字符串的时候,会隐式解码 utf-8 字符,例如:

3.5.4 rune 序列 & byte 序列
string 类型本身只读,但这并不意味着需要在 string 上困难的操作
将 string 对象类型转换为整型切片,比如 []rune 或者 []byte 时
s := "abc"
a := []rune(s)
b := []byte(s)
会发生这样的事:
string对象解码 utf-8,变成 byte 序列或者每个 unicode 字符一个 rune 的 rune 序列。- 创建新的一个底层数组来存放这些整型数据
- 将切片引用自这个底层数组
将 []rune 类型转换应用到 UTF8 编码的字符串,将返回字符串编码的 Unicode 码点序列:
// "program" in Japanese katakana s := "プログラム" fmt.Printf("% x\n", s) // "e3 83 97 e3 83 ad e3 82 b0 e3 83 a9 e3 83 a0" r := []rune(s) fmt.Printf("%x\n", r) // "[30d7 30ed 30b0 30e9 30e0]"(在第一个 Printf 中的
% x参数用于在每个十六进制数字前插入一个空格。)如果是将一个 []rune 类型的 Unicode 字符 slice 或数组转为 string,则对它们进行 UTF8 编码:
fmt.Println(string(r)) // "プログラム"将一个整数转型为字符串意思是生成以只包含对应 Unicode 码点字符的 UTF8 字符串:
fmt.Println(string(65)) // "A", not "65" fmt.Println(string(0x4eac)) // "京"如果对应码点的字符是无效的,则用
\uFFFD无效字符作为替换:fmt.Println(string(1234567)) // "?"
标准库中有四个包对字符串处理尤为重要:bytes、strings、strconv 和 unicode 包。strings 包提供了许多如字符串的查询、替换、比较、截断、拆分和合并等功能。
bytes 包也提供了很多类似功能的函数,但是针对和字符串有着相同结构的 []byte 类型。因为字符串是只读的,因此逐步构建字符串会导致很多分配和复制。在这种情况下,使用 bytes.Buffer 类型将会更有效
关于各种包的使用略
3.6 无类型常量
Go 语言的常量有个不同寻常之处。虽然一个常量可以有任意一个确定的基础类型,例如 int 或 float64,或者是类似 time.Duration 这样命名的基础类型,但是许多常量并没有一个明确的基础类型。编译器为这些没有明确基础类型的数字常量提供比基础类型更高精度的算术运算;你可以认为至少有 256bit 的运算精度。这里有六种未明确类型的常量类型,分别是无类型的布尔型、无类型的整数、无类型的字符、无类型的浮点数、无类型的复数、无类型的字符串。
通过延迟明确常量的具体类型,无类型的常量不仅可以提供更高的运算精度,而且可以直接用于更多的表达式而不需要显式的类型转换。例如,例子中的 ZiB 和 YiB 的值已经超出任何 Go 语言中整数类型能表达的范围,但是它们依然是合法的常量
另一个例子,math.Pi 无类型的浮点数常量,可以直接用于任意需要浮点数或复数的地方:
var x float32 = math.Pi var y float64 = math.Pi var z complex128 = math.Pi如果 math.Pi 被确定为特定类型,比如 float64,那么结果精度可能会不一样,同时对于需要 float32 或 complex128 类型值的地方则会强制需要一个明确的类型转换:
const Pi64 float64 = math.Pi var x float32 = float32(Pi64) var y float64 = Pi64 var z complex128 = complex128(Pi64)对于常量面值,不同的写法可能会对应不同的类型。例如 0、0.0、0i 和
\u0000虽然有着相同的常量值,但是它们分别对应无类型的整数、无类型的浮点数、无类型的复数和无类型的字符等不同的常量类型。同样,true 和 false 也是无类型的布尔类型,字符串面值常量是无类型的字符串类型。const ( deadbeef = 0xdeadbeef // untyped int with value 3735928559 a = uint32(deadbeef) // uint32 with value 3735928559 b = float32(deadbeef) // float32 with value 3735928576 (rounded up) c = float64(deadbeef) // float64 with value 3735928559 (exact) d = int32(deadbeef) // compile error: constant overflows int32 e = float64(1e309) // compile error: constant overflows float64 f = uint(-1) // compile error: constant underflows uint )
只有常量可以是无类型的。当一个无类型的常量被赋值给一个变量的时候,无类型的常量将会被隐式转换为对应的类型,如果转换合法的话。
对于一个没有显式类型的变量声明(包括简短变量声明),常量的形式将隐式决定变量的默认类型,就像下面的例子:
i := 0 // untyped integer; implicit int(0)
r := '\000' // untyped rune; implicit rune('\000')
f := 0.0 // untyped floating-point; implicit float64(0.0)
c := 0i // untyped complex; implicit complex128(0i)
注意到,无类型整数的默认推导是 int,int 的大小不总是相同;但对于浮点和复数来说,float64 和 complex128 大小固定。go 的浮点数和复数的内存大小总是确定的。
4 复合数据类型
4.1 数组
长度固定(可以为 0),元素类型一致,下标从 0 开始
因为数组的长度是固定的,因此在 Go 语言中很少直接使用数组。和数组对应的类型是Slice(切片),它是可以增长和收缩的动态序列,slice 功能也更灵活
使用 len(数组) 取得元素个数
默认情况下,数组的每个元素都被初始化为元素类型对应的零值
你也可以使用 initializer_list(👈学 cpp 学的
var q [3]int = [3]int{1, 2, 3}
var r [3]int = [3]int{1, 2}
fmt.Println(r[2]) // "0"
方括号填 ... 表示按照 initializer_list 确定长度(不填长度为 0)
initializer_list 还有另外一种规则,可以用 下标: 值 初始化
r := [...]int{99: -1}
定义了一个含有 100 个元素的数组 r,最后一个元素被初始化为 -1,其它元素都是用 0 初始化。
type Currency int
const (
USD Currency = iota // 美元
EUR // 欧元
GBP // 英镑
RMB // 人民币
)
symbol := [...]string{USD: "$", EUR: "€", GBP: "£", RMB: "¥"}
fmt.Println(RMB, symbol[RMB]) // "3 ¥"
两种规则可以混用:a := [...]int{1, 2, 3, 99: -1, 50: 6} // 长度为 100
数组的长度是数组类型的一个组成部分,因此 [3]int 和 [4]int 是两种不同的数组类型。数组的长度必须是常量表达式
注意理解 “长度是类型的一部分”。一个指向 [3]int 的指针不能直接指向 [4]int 对象
var p1 *[3]int
var a [4]int
p1 = &a // error
鉴于数组是非常僵化的类型,我们一般用 slice 代替数组
4.2 Slice
slice 类型一般写作 []T,slice 的长度可变!
切片由数组生成,可以看成是一个数组 buffer 的部分引用
比如 Q2 := months[4:7] 定义了一个 slice
注意,slice 是一种底层数据的引用,并不新申请空间存放数据
不同 slice 的的引用区间可以重叠
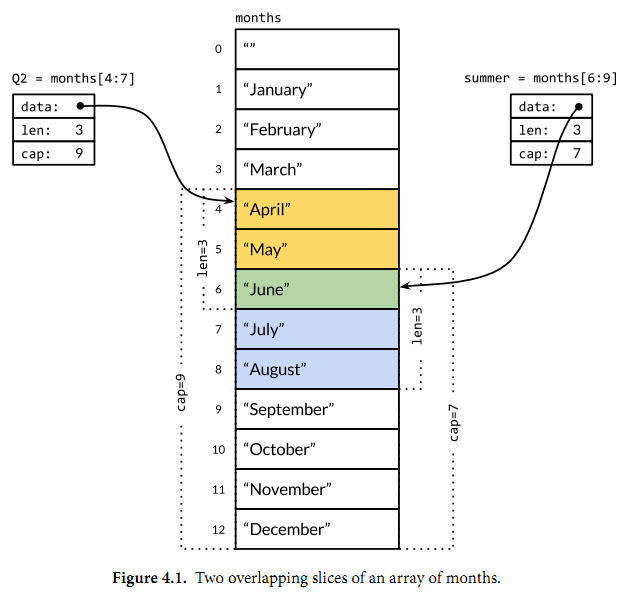
slice 三要素:指针、长度、容量
指针指向第一个元素对应的底层数组元素地址,长度对应 slice 中元素的数目;长度不能超过容量,容量一般是从 slice 的开始位置到底层数据的结尾位置。内置的 len 和 cap 函数分别返回 slice 的长度和容量。
使用切片操作 s[i:j] 取得一个切片,左闭右开
切片操作越界会导致 panic
因为 slice 包含指向第一个元素的指针,因此向函数传递 slice 将允许在函数内部修改底层数组的元素。换句话说,复制一个 slice 只是对底层的数组创建了一个新的 slice 别名。
也可以不用已有的数组,直接用一个 initializer_list 当作 “数组字面量” 创建 slice:
s := []int{0, 1, 2, 3, 4, 5}
这会隐式地创建一个合适大小的数组,然后 slice 的指针指向底层的数组。这里 initializer_list 的写法和数组同。
和数组不同的是,slice 之间不能比较。不能用 == 来判断两个 slice 的各元素相等
slice 唯一合法的比较操作是和 nil 比较相等或不等。
一个零值的 slice 等于 nil。一个 nil 值的 slice 没有底层数组。一个 nil 值的 slice 的长度和容量都是 0,但是也有非 nil 值的 slice 的长度和容量也是 0 的,例如 []int{} 或 make([]int, 3)[3:]。与任意类型的 nil 值一样,我们可以用 []int(nil) 类型转换表达式来生成一个对应类型 slice 的 nil 值。
如果你需要测试一个 slice 是否是空的,使用 len(s) == 0 来判断,而不应该用 s == nil 来判断。除了和 nil 相等比较外,一个 nil 值的 slice 的行为和其它任意 0 长度的 slice 一样;例如 reverse(nil) 也是安全的。除了文档已经明确说明的地方,所有的 Go 语言函数应该以相同的方式对待 nil 值的 slice 和 0 长度的 slice。
内置的 make 函数创建一个指定元素类型、长度和容量的 slice。容量部分可以省略,在这种情况下,容量将等于长度。
make([]T, len) make([]T, len, cap) // same as make([]T, cap)[:len]在底层,make 创建了一个匿名的数组变量,然后返回一个 slice;只有通过返回的 slice 才能引用底层匿名的数组变量。在第一种语句中,slice 是整个数组的 view。在第二个语句中,slice 只引用了底层数组的前 len 个元素,但是容量将包含整个的数组。额外的元素是留给未来的增长用的。
【append 函数】
前面提到过 slice 长度可变。
append(s, ele) 可以在切片 s 后添加一个元素 ele(即添加到原先 s[len(s)] 处),返回新的切片
该操作的具体实现可能是这样:
- 如果
len(s) + 1 <= cap(s),则直接给s[len(s)]赋值ele,创建一个新切片 z 返回。其中 z 满足起始指针与 s 相同,len(z) = len(s) + 1。 - 如果
len(s) + 1 > cap(s),说明底层数组没空间了,此时 make 一个新切片 z 引用新创建的底层数组,其长度是原数组的二倍,把数组复制过去。(即 vector 扩容,单次操作均摊 \(O(1)\)
但是,
内置的 append 函数可能使用更复杂的内存扩展策略。因此,通常我们并不知道 append 调用是否导致了内存的重新分配,因此也不能确认新的 slice 和原始的 slice 是否引用的是相同的底层数组空间。同样,我们不能确认在原先的 slice 上的操作是否会影响到新的 slice。因此,通常是将 append 返回的结果直接赋值给输入的 slice 变量:
runes = append(runes, r)更新 slice 不仅对调用 append 函数是必要的,实际上对应任何可能导致长度、容量或底层数组变化的操作都是必要的。要正确地使用 slice,需要记住尽管底层数组的元素是间接访问的,但是 slice 对应结构体本身的指针、长度和容量部分是直接访问的。要更新这些信息需要像上面例子那样一个显式的赋值操作。从这个角度看,slice 并不是一个纯粹的引用类型,它实际上是一个类似下面结构体的聚合类型:
type IntSlice struct { ptr *int len, cap int }
append 还可以一次添加多个元素,以及可以 append slice
var x []int
x = append(x, 1)
x = append(x, 2, 3)
x = append(x, 4, 5, 6)
x = append(x, x...) // append the slice x
fmt.Println(x) // "[1 2 3 4 5 6 1 2 3 4 5 6]"
允许的其中几种 0 长度 slice
x := [3]int{0, 1, 2}
a := x[3:] // == x[3:3]
b := x[:0] // == x[0:0]
c := x[1:1]
4.3 Map
一个 map 是一个 hash table 的引用
这里所称哈希表,键值对 key-value 无序,其中 key 两两不同(unordered_map
map 类型可以写为 map[K]V,其中 K,V 是 key 和 value 的类型,并且 K 类型必须定义了 operator==
/*1*/ ages := make(map[string]int) // 空 map
/*2*/ ages := map[string]int{} // 空 map
/*3*/ ages := map[string]int{ // 带初值
"alice": 31,
"charlie": 34,
}
用 key 作为下标访问 value:
ages["alice"] = 32
fmt.Println(ages["alice"]) // "32"
使用 len(ages) 得到键值对数
使用内置 delete 函数删除元素
delete(ages, "alice") // remove element ages["alice"]
若 key 不存在,返回的 value 为 value 类型对应的零值
对原先不存在的 key 赋值或自增自减等,则创建键值对
但是 map 中的元素并不是一个变量,因此我们不能对 map 的元素取址:
_ = &ages["bob"] // compile error: cannot take address of map element禁止对 map 元素取址的原因是 map 可能随着元素数量的增长而重新分配更大的内存空间,从而可能导致之前的地址无效。
要想遍历 map 中全部的 key/value 对的话,可以使用 range 风格的 for 循环实现,和之前的 slice 遍历语法类似。
for name, age := range ages { fmt.Printf("%s\t%d\n", name, age) }map 的迭代顺序是不确定的,并且不同的哈希函数实现可能导致不同的遍历顺序。在实践中,遍历的顺序是随机的,每一次遍历的顺序都不相同。这是故意的,每次都使用随机的遍历顺序可以强制要求程序不会依赖具体的哈希函数实现。
map 上的大部分操作,包括查找、删除、len 和 range 循环都可以安全工作在 nil 值的 map 上,它们的行为和一个空的 map 类似。但是向一个 nil 值的 map 存入元素将导致一个 panic 。即,在向 map 存数据前必须先创建 map。
使用 ages[key] 也可以接受两个返回值,第二个是一个 bool 用来表示该键是否存在
age, ok := ages["bob"]
if !ok { /* "bob" is not a key in this map; age == 0. */ }
和 slice 一样,map 之间也不能进行相等比较,只能和 nil 比较相等性。
map 的 key 类型要求是可比的,那如果你想用 slice 之类的东西当作 key,只好自己定义一个 trans 函数把不可比对象 hash 成可比对象。mp[slice] -> mp[trans(slice)]
go 不提供 set 类型,太坏了
所以一些时候只能 map 当 set 用了
4.4 结构体
比如
type Employee struct {
ID int
Name, Address string // 这样也是可以的
DoB time.Time
Position string
Salary int
ManagerID int
}
var dilbert Employee
成员用 . 号访问,可以取地址
position := &dilbert.Position
*position = "Senior " + *position
指向结构体的指针可以直接用 . 号访问成员
var employeeOfTheMonth *Employee = &dilbert
employeeOfTheMonth.Position += " (proactive team player)" // 可以的
(*employeeOfTheMonth).Position += " (proactive team player)" // 和这个等价
首字母大写的成员为导出成员。非导出成员仅在当前的 package 可访问,导出成员在外部也可以访问
如果结构体里每个成员的类型都可比,则结构体之间也可比
type Point struct{ X, Y int }
p := Point{1, 2}
q := Point{2, 1}
fmt.Println(p.X == q.X && p.Y == q.Y) // "false"
fmt.Println(p == q) // "false"
可比较的结构体和其他可比较类型一样,可以作 map 的 key 类型。
如果结构体没有任何成员的话就是空结构体,写作 struct{}。它的大小为 0,也不包含任何信息,但是有时候依然是有价值的。有些 Go 语言程序员用 map 来模拟 set 数据结构时,用它来代替 map 中布尔类型的 value,只是强调 key 的重要性,但是因为节约的空间有限,而且语法比较复杂,所以我们通常会避免这样的用法。
seen := make(map[string]struct{}) // set of strings // ... if _, ok := seen[s]; !ok { seen[s] = struct{}{} // ...first time seeing s... }
【结构体字面值】
type Point struct{ X, Y int }
p := Point{1, 2} // 这样
上面这种写法要求对所有成员按顺序赋初值
更常用下面这样写
anim := gif.GIF{LoopCount: nframes}
如果用这种写法,被忽略的成员为默认零值。因为提供了成员的名字,所以成员出现的顺序并不重要
两种写法不能混用
结构体字面量还有一种神奇特性:可以取地址
ptr := &User{"alice", 5} // ok
除了结构体字面量允许这种 “右值当左值” 取地址的行为,其他情况下的任何右值都不能被取地址,或者做写操作
【Embedded Struct】
结构体嵌入
type People struct {
Name string
}
type User struct {
People // embedded struct
ID int
}
User 里填写了一个 People,那么 People 的成员 Name 也就被引入到 User 类里了
看下面一个例子:
type Point struct {
X, Y int
}
type Circle struct {
Point
Radius int
}
type Wheel struct {
Circle
Spokes int
}
var w Wheel
w.X = 8 // equivalent to w.Circle.Point.X = 8
w.Y = 8 // equivalent to w.Circle.Point.Y = 8
w.Radius = 5 // equivalent to w.Circle.Radius = 5
w.Spokes = 20
在右边的注释中给出的显式形式访问这些叶子成员的语法依然有效,因此匿名成员并不是真的无法访问了。其中匿名成员 Circle 和 Point 都有自己的名字——就是命名的类型名字——但是这些名字在点操作符中是可选的。我们在访问子成员的时候可以忽略任何匿名成员部分。
特别的,在类型中内嵌的匿名字段也可以是一个类型的指针,这种情况下字段和方法会被间接地引入到当前的类型中(译注:访问需要通过该指针指向的对象去取)。添加这一层间接关系让我们可以共享通用的结构并动态地改变对象之间的关系。下面这个 ColoredPoint 的声明内嵌了一个 *Point 的指针。
type ColoredPoint struct {
*Point
Color color.RGBA
}
p := ColoredPoint{&Point{1, 1}, red}
q := ColoredPoint{&Point{5, 4}, blue}
fmt.Println(p.Distance(*q.Point)) // "5"
q.Point = p.Point // p and q now share the same Point
p.ScaleBy(2)
fmt.Println(*p.Point, *q.Point) // "{2 2} {2 2}"
不幸的是,结构体字面值并没有简短表示匿名成员的语法
我们只能用树状方式来初始化 Wheel 各成员
w = Wheel{Circle{Point{8, 8}, 5}, 20} // 这样
w = Wheel{ // 或者这样
Circle: Circle{
Point: Point{X: 8, Y: 8},
Radius: 5,
},
Spokes: 20, // NOTE: trailing comma necessary here (and at Radius)
}
关于名字冲突:当两个字段拥有相同的名字(可能是继承来的名字)时该怎么办呢?
- 外层名字会覆盖内层的名字(但是两者实际上都存在)
- 如果相同的名字在同一级别出现了两次,如果这个名字被程序使用了,将会引发一个错误(不使用没关系)。没有办法来解决这种问题引起的二义性,必须由程序员自己修正。
例子:
type A struct {a int}
type B struct {a, b int}
type C struct {A; B}
var c C
使用 C.a 会导致错误,使用 c.A.a 和 c.B.a 则可行
type D struct {B; b float32}
var d D
使用 D.b 是可以的,它是 float32 的那个 b,想要内层的 b 必须写 C.B.b
关于导出性:如果上例的 Point 和 Circle 首字母小写,那么在外部 package 中
w.X = 8 // because equivalent to w.circle.point.X = 8
这样写是不允许的
5 函数
5.1 上手
- go 的栈空间可变。无需担心递归爆栈
- 具名函数只能定义在全局
func name(<parameter-list>) (<result-list>) {
// ...
}
一点例子:
func hello() {
fmt.Println("Hello")
}
func f(x int, y int, z int) int {
return x
}
func f(x, y, z int) int {
return x
}
func f(x, y int, z int) int {
return x
}
func f(x int, _ int) int { // 被忽略的参数
return x
}
func f(x int, _ int, _ int) int {
return x
}
func f(x int, _, _ int) int {
return x
}
func f() int {
return 1
}
func f() (int, string) {
return 1, "hello"
}
func f() (ret int) { // 返回值可以被命名
ret = 1
return
// 如果返回值列表每个都有命名,return 可以省略操作数 (bare return)
}
func f() (ret int) {
ret = 1
return ret
}
func f() (ret int) {
return 1
}
func f() (ret1, ret2 int) {
return 1, 2
}
// func f() (ret int, string) // 错误, 不允许混用
func f() (_ int) { // 可以命名为 _, 但是跟没命名一样
return 1
}
func f() (ret int, _ string) {
ret = 1
return ret, "hello" // 如果某返回值被命名为 _, 就必须把整个列表 return 全
}
函数的类型也称函数的签名
如果两个函数形参的类型对应相同,返回值类型也对应相同,则认为两个函数是同类型的
每一次函数调用都必须按照声明顺序为所有参数提供实参(参数值)。在函数调用时,Go 语言没有默认参数值,也没有任何方法可以通过参数名指定形参,因此形参和返回值的变量名对于函数调用者而言没有意义。
你可能会偶尔遇到没有函数体的函数声明,这表示该函数不是以 Go 实现的。这样的声明定义了函数签名。
package math func Sin(x float64) float //implemented in assembly language
函数有多返回值,每个返回值都必须被接住,不想要的用 _ 接
多返回值可以用作另一个函数的参数
func f() (int, int) {
return 1, 2
}
func printTwo(x, y int) {
fmt.Println(x, y)
}
func main() {
printTwo(f()) // 1 2
}
但是函数的多参数返回值不能作为字面多参数列表的一部分
printThree(f(), 3) // 错误
5.2 函数值
函数像其他值一样,拥有类型,可以被赋值给其他变量,传递给函数,从函数返回。对函数值(function value)的调用类似函数调用。例子如下:
func square(n int) int { return n * n } func negative(n int) int { return -n } func product(m, n int) int { return m * n } f := square fmt.Println(f(3)) // "9" f = negative fmt.Println(f(3)) // "-3" fmt.Printf("%T\n", f) // "func(int) int" f = product // compile error: can't assign func(int, int) int to func(int) int函数类型的零值是 nil。调用值为 nil 的函数值会引起 panic:
var f func(int) int f(3) // 此处f的值为nil, 会引起panic错误函数值可以与 nil 比较:
var f func(int) int if f != nil { f(3) }但是函数值之间是不可比较的,也不能用函数值作为 map 的 key。
5.3 匿名函数
相当于函数字面量,它属于一种表达式
strings.Map(func(r rune) rune { return r + 1 }, "HAL-9000")
匿名函数访问完整的词法环境。也就是被创建时所在词法块内变量均被引用捕获
这意味着在函数中定义的内部函数可以引用该函数的变量,如下例所示:
// squares返回一个匿名函数。
// 该匿名函数每次被调用时都会返回下一个数的平方。
func squares() func() int {
var x int
return func() int {
x++
return x * x
}
}
func main() {
f := squares()
fmt.Println(f()) // "1"
fmt.Println(f()) // "4"
fmt.Println(f()) // "9"
fmt.Println(f()) // "16"
}
squares 的例子证明,函数值不仅仅是一串代码,还记录了状态。在 squares 中定义的匿名内部函数可以访问和更新 squares 中的局部变量,这意味着匿名函数和 squares 中,存在变量引用。这就是函数值属于引用类型和函数值不可比较的原因。Go 使用闭包(closures)技术实现函数值,Go 程序员也把函数值叫做闭包。
通过这个例子,我们看到变量的生命周期不由它的作用域决定:squares 返回后,变量 x 仍然隐式的存在于 f 中。
这种有闭包的语言都会有以下这种问题:
var rmdirs []func()
dirs := tempDirs()
for i := 0; i < len(dirs); i++ {
os.MkdirAll(dirs[i], 0755) // OK
rmdirs = append(rmdirs, func() {
os.RemoveAll(dirs[i]) // NOTE: incorrect!
})
}
新建的匿名函数引用了易变的变量,而非取循环变量值用于匿名函数中
所以我们可能需要这样:
var rmdirs []func()
dirs := tempDirs()
for i := 0; i < len(dirs); i++ {
idx := i // NOTE
os.MkdirAll(dirs[i], 0755) // OK
rmdirs = append(rmdirs, func() {
os.RemoveAll(dirs[idx]) // NOTE
})
}
还有一种手段是新建一个与循环变量同名的局部变量作为副本。
for i := 0; i < len(dirs); i++ {
i := i
// ...
}
虽然这看起来很奇怪,但却很有用。
5.4 变长参数
函数的最后一个参数可以是变长的,其类型为 ...type。
func myFunc(a, b, arg ...int) {}
规则非常简单:
- 一个变长的参数本质是个 slice,所以可以用 len,range 等等东西处理
- 将一个 slice 解包成多参数,在后面加
...,比如args... - 同样的,使用
args...解出来的多参数不能作为更长多参数列表的一部分 - 变长参数可以作为对应类型的 slice 进行二次传递
示例:
package main
import "fmt"
func main() {
x := min(1, 3, 2, 0)
fmt.Printf("The minimum is: %d\n", x)
slice := []int{7, 9, 3, 5, 1}
x = min(slice...)
fmt.Printf("The minimum in the slice is: %d", x)
}
func min(s ...int) int {
if len(s)==0 {
return 0
}
min := s[0]
for _, v := range s {
if v < min {
min = v
}
}
return min
}
func F1(s ...string) {
F2(s...)
F3(s)
}
func F2(s ...string) { }
func F3(s []string) { }
5.5 deferred 函数
用于延迟调用函数。当一个函数调用被 deferred,则该调用会在包含 defer 语句的函数返回之前被执行
defer fun(args)
-
不论函数正常 return 还是 panic 导致异常结束,defer 均会执行
但是,如果函数中执行了
os.Exit,defer 不会执行 -
defer 函数如果有返回值,会被忽略
-
函数的参数在 defer 语句出现时即被确定,是传值并非变量引用
如果用匿名函数 defer,其内部依然与闭包同,引用捕获当前词法域的变量
-
有多条 defer 时,每条 defer 将一个函数调用压栈,最后从栈顶依次取出执行。即 FILO 规则
-
return 语句并非是原子的。当某函数运行到 return 时,流程是:
- 保存返回值到返回变量
- 执行所有 defer
- 结束函数
所以 defer 匿名函数可以在返回前修改具名返回值
func DeferShow() { fmt.Println("Out:", deferValueParam()) } func deferValueParam() (ret int) { ret = 0 defer func() { // 会直接修改栈中对应的返回值 ret += 10 fmt.Println("Defer Ret:", ret) }() ret = 5 fmt.Println("Ret:", ret) return } // Ret: 5 // Defer Ret: 15 // Out: 15
通常用 defer 来保证成对操作的执行
5.6 panic & recover
使用 panic 表达一个严重异常。panic() 支持一个任意类型的参数
在多层嵌套的函数中一旦有 panic 被触发,程序就会开始逐层执行 defer 然后回溯,最后在栈顶崩溃(该过程称为 panicking)
go 还提供了一种恢复办法,即使用 recover
recover() 函数是内置函数。程序在 panicking 过程中一旦遇到 recover 被调用即停止 panicking。recover 在 panicking 过程中被调用,返回 panic 的参数;其他时候返回 nil
下面是一个例子:
package main
import "fmt"
func badCall() {
panic("bad end")
}
func test() {
defer func() {
if e := recover(); e != nil {
fmt.Printf("Panicing %s\r\n", e)
}
}()
badCall()
fmt.Printf("After bad call\r\n") // <-- would not reach
}
func main() {
fmt.Printf("Calling test\r\n")
test()
fmt.Printf("Test completed\r\n")
}
Calling test
Panicing bad end
Test completed
6 方法
6.1 上手
go 采用了奇特手段为类型添加方法,它不是 “类型包含了方法”,而是 “方法注入了类型”
type Point struct{ X, Y float64 }
// traditional function
func Distance(p, q Point) float64 {
return math.Hypot(q.X-p.X, q.Y-p.Y)
}
// same thing, but as a method of the Point type
func (p Point) Distance(q Point) float64 {
return math.Hypot(q.X-p.X, q.Y-p.Y)
}
在一个函数名字前添加的这个 (p Point),称为接收器(receiver)。带有接收器的函数就是某类型的成员函数。
需要注意的是
- 接收器中只能有一个变量
- 如果你不需要使用成员变量,可以使用
(_ Point)或者(Point)
和其他语言不同的,go 允许你给几乎所有类型加入方法,不仅仅是自定义的 struct,可以是 int,string,bool,数组/slice,map[key]value,等等的别名类
- 接口类不能作为 receiver,因为接口是一个抽象定义,但是方法是具体实现
- 不能给指针添加方法,但是 receiver 可以是
*type类型,这意味着你以引用方式捕获这个type类型变量而非传值 - 类型声明和类型方法定义必须在同一个 package 中。不允许给外部 package 中的类再添加方法。但是如果你在此包中声明它的别名,就可以给这个别名类添加方法
- 接收器声明不能写成
(a []int)或者是(m map[int]int),接收器变量类型只能是命名类型;不能写成(v int)或者(s string),因为int、string等类型在外部 package 中被定义 - 使用 embedded struct 不仅会引入成员变量,还会引入该类的方法
- 如果声明类 A 的别名类 B,那么 B 中只保留 A 的成员变量和 A 中 embedding struct 的方法,B 中没有声明于 A 上的方法
package main
import (
"fmt"
"time"
)
type myTime struct {
time.Time //anonymous field
}
func (t myTime) first3Chars() string {
return t.Time.String()[0:3]
}
func main() {
m := myTime{time.Now()}
// 调用匿名 Time 上的 String 方法
fmt.Println("Full time now:", m.String())
// 调用 myTime.first3Chars
fmt.Println("First 3 chars:", m.first3Chars())
}
/* Output:
Full time now: Mon Oct 24 15:34:54 Romance Daylight Time 2011
First 3 chars: Mon
*/
6.2 方法值
我们经常选择一个方法,并且在同一个表达式里执行,比如常见的 p.Distance() 形式,实际上将其分成两步来执行也是可能的。p.Distance 叫作“选择器”,选择器会返回一个方法“值”:一个将方法(Point.Distance)绑定到特定接收器变量的函数。这个函数可以不通过指定其接收器即可被调用;即调用时不需要指定接收器(译注:因为已经在前文中指定过了),只要传入函数的参数即可:
p := Point{1, 2}
q := Point{4, 6}
distanceFromP := p.Distance // method value
fmt.Println(distanceFromP(q)) // "5"
var origin Point // {0, 0}
fmt.Println(distanceFromP(origin)) // "2.23606797749979", sqrt(5)
scaleP := p.ScaleBy // method value
scaleP(2) // p becomes (2, 4)
scaleP(3) // then (6, 12)
scaleP(10) // then (60, 120)
即取出某对象的成员函数后,该函数已经绑定了此对象
下面例子中的 time.AfterFunc 这个函数的功能是在指定的延迟时间之后来执行一个(译注:另外的)函数。且这个函数操作的是一个 Rocket 对象 r
type Rocket struct { /* ... */ }
func (r *Rocket) Launch() { /* ... */ }
r := new(Rocket)
time.AfterFunc(10 * time.Second, func() { r.Launch() })
直接用方法“值”传入 AfterFunc 的话可以更为简短:
time.AfterFunc(10 * time.Second, r.Launch)
你也可以用 T.f(其中 T 是类名而非对象名)。此时调用该函数需要同时给出接收器对象和参数,即原来的方法都需要在第一个位置先给出接收器对象
下面是两个例子
p := Point{1, 2}
q := Point{4, 6}
distance := Point.Distance // method expression
fmt.Println(distance(p, q)) // "5"
fmt.Printf("%T\n", distance) // "func(Point, Point) float64"
scale := (*Point).ScaleBy
scale(&p, 2)
fmt.Println(p) // "{2 4}"
fmt.Printf("%T\n", scale) // "func(*Point, float64)"
type Point struct{ X, Y float64 }
func (p Point) Add(q Point) Point { return Point{p.X + q.X, p.Y + q.Y} }
func (p Point) Sub(q Point) Point { return Point{p.X - q.X, p.Y - q.Y} }
type Path []Point
func (path Path) TranslateBy(offset Point, add bool) {
var op func(p, q Point) Point
if add {
op = Point.Add
} else {
op = Point.Sub
}
for i := range path {
// Call either path[i].Add(offset) or path[i].Sub(offset).
path[i] = op(path[i], offset)
}
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号