
Kubernetes--简述
官方文档:https://kubernetes.io/docs/home/
一、概述
Kubernetes 是一个可移植、可扩展的开源平台,用于管理容器化的工作负载和服务,方便进行声明式配置和自动化。
Kubernetes可以提供:
- 服务发现和负载均衡:Kubernetes 可以使用 DNS 名称或自己的 IP 地址来暴露容器。 如果进入容器的流量很大, Kubernetes 可以负载均衡并分配网络流量,从而使部署稳定。
- 存储编排:Kubernetes 允许自动挂载选择的存储系统,例如本地存储、公共云提供商等。
- 自动部署和回滚:可以使用 Kubernetes 描述已部署容器的所需状态, 它可以以受控的速率将实际状态更改为期望状态。 例如,可以自动化 Kubernetes 来为部署创建新容器, 删除现有容器并将它们的所有资源用于新容器。
- 自动调度:Kubernetes 的调度器会根据容器定义的 CPU 和内存资源,结合集群的当前状态,自动计算并选择最佳节点来运行容器,从而充分利用资源。
- 自我修复:Kubernetes 将重新启动失败的容器、替换容器、杀死不响应用户定义的运行状况检查的容器, 并且在准备好服务之前不将其通告给客户端。
- 密钥与配置管理:Kubernetes 允许存储和管理敏感信息,例如密码、OAuth 令牌和 SSH 密钥。 可以在不重建容器镜像的情况下部署和更新密钥和应用程序配置,也无需在堆栈配置中暴露密钥。
- 批处理执行:除了服务外,Kubernetes 还可以管理你的批处理和 CI(持续集成)工作负载,如有需要,可以替换失败的容器。
- 水平扩缩:使用简单的命令、用户界面或根据 CPU 使用率自动对应用进行扩缩容。
- IPv4/IPv6 双栈:为 Pod(容器组)和 Service(服务)分配 IPv4 和 IPv6 地址。
- 可扩展性设计:在不改变上游源代码的情况下为Kubernetes 集群添加功能。
注:批处理(Batch Processing) 指的是处理一组任务或作业的方式,这些任务通常是一次性、短期的计算任务。Kubernetes 提供了特定的资源类型来管理这类作业,主要包括 Job 和 CronJob。
1.1 Kubernetes 的历史背景

传统部署
早期,各个组织是在物理服务器上运行应用程序。 由于无法限制在物理服务器中运行的应用程序资源使用,因此会导致资源分配问题。
例如,如果在同一台物理服务器上运行多个应用程序, 则可能会出现一个应用程序占用大部分资源的情况,而导致其他应用程序的性能下降。
一种解决方案是将每个应用程序都运行在不同的物理服务器上, 但是当某个应用程序资源利用率不高时,剩余资源无法被分配给其他应用程序, 而且维护许多物理服务器的成本很高。
因此,虚拟化技术被引入了。
虚拟化部署:
虚拟化技术允许在单个物理服务器的 CPU 上运行多台虚拟机(VM)。 虚拟化能使应用程序在不同 VM 之间被彼此隔离,且能提供一定程度的安全性, 因为一个应用程序的信息不能被另一应用程序随意访问。
虚拟化技术能够更好地利用物理服务器的资源,并且因为可轻松地添加或更新应用程序, 而因此可以具有更高的可扩缩性,以及降低硬件成本等等的好处。 通过虚拟化,可以将一组物理资源呈现为可丢弃的虚拟机集群。
每个 VM 是一台完整的计算机,在虚拟化硬件之上运行所有组件,包括其自己的操作系统。
容器部署:
容器类似于 VM,但是更宽松的隔离特性,使容器之间可以共享操作系统(OS)。 因此,容器比起 VM 被认为是更轻量级的。且与 VM 类似,每个容器都具有自己的文件系统、CPU、内存、进程空间等。
由于它们与基础架构分离,因此可以跨云和 OS 发行版本进行移植。
容器因具有许多优势而变得流行起来,例如:
- 敏捷应用程序的创建和部署:与使用 VM 镜像相比,提高了容器镜像创建的简便性和效率。
- 持续开发、集成和部署:通过快速简单的回滚(由于镜像不可变性), 提供可靠且频繁的容器镜像构建和部署。
- 关注开发与运维的分离:在构建、发布时创建应用程序容器镜像,而不是在部署时, 从而将应用程序与基础架构分离。
- 可观察性:不仅可以显示 OS 级别的信息和指标,还可以显示应用程序的运行状况和其他指标信号。
- 跨开发、测试和生产的环境一致性:在笔记本计算机上也可以和在云中运行一样的应用程序。
- 跨云和操作系统发行版本的可移植性:可在 Ubuntu、RHEL、CoreOS、本地、 Google Kubernetes Engine 和其他任何地方运行。
- 以应用程序为中心的管理:提高抽象级别,从在虚拟硬件上运行 OS 到使用逻辑资源在 OS 上运行应用程序。
- 松散耦合、分布式、弹性、解放的微服务:应用程序被分解成较小的独立部分, 并且可以动态部署和管理, 而不是在一台大型单机上整体运行。
- 资源隔离:可预测的应用程序性能。
- 资源利用:高效率和高密度。
1.2 核心概念
Kubernetes 是一个强大的容器编排平台,具有许多核心概念和组件。
| 概念 | 描述 | 功能 |
|---|---|---|
| Pod | Pod 是 Kubernetes 中的最小部署单元,表示一个或多个容器的集合,它们共享存储、网络和配置。 | Pods 内的容器可以共享文件系统和网络,适合运行密切相关的应用程序。 |
| Pods | Pods 是 Pod 的复数形式,表示多个 Pod | 通常用于描述一组 Pod 或在命令行中指定多个 Pod |
| Node | Node 是 Kubernetes 集群中的一个工作机器,可以是物理或虚拟机。 | 每个 Node 上运行一个或多个 Pods,包含运行 Pods 所需的所有组件(如 kubelet、容器运行时等)。 |
| Service | Service 是一种抽象,定义了一组 Pods 的访问策略,提供稳定的网络接口。 | 通过 Service,用户可以使用 DNS 名称访问 Pods,而无需关心 Pods 的 IP 地址变化。它支持负载均衡和服务发现。 |
| Deployment | Deployment 是用于声明式管理 Pods 和 ReplicaSets 的资源。 | 自动化 Pods 的部署、升级和回滚,确保系统在更新时保持可用性。 |
| ReplicaSet | ReplicaSet 确保指定数量的 Pod 实例在运行,在1.2 版本引入,以替代早期的 Replication Controller。 | 用于扩展和缩减 Pods 的数量,确保 Pods 的高可用性。 |
| Namespace | Namespace 是 Kubernetes 的逻辑隔离机制,用于在同一集群中管理多个环境(如开发、测试和生产)。 | 通过 Namespace,可以在同一集群中使用相同的资源名称而不会冲突。 |
| ConfigMap | 用于存储配置信息以供 Pods 使用。 | 允许将配置信息从镜像中分离,便于管理和更新。 |
| Secret | 用于存储敏感信息(如密码、令牌等)。 | 提供安全的方式来传递敏感数据给 Pods。 |
| Volume | Volume 是 Kubernetes 中用于持久化存储的抽象。 | 提供跨容器共享数据的能力,支持多种存储类型,如本地存储、NFS、云存储等。 |
| Cluster | Cluster 是 Kubernetes 的核心概念,由多个 Node 组成。 | 提供一个统一的计算资源池,便于管理和调度。 |
| Ingress | Ingress 是用于管理外部访问 Kubernetes 服务的 API 对象。 | 提供 HTTP 和 HTTPS 路由到集群内服务的能力,支持负载均衡、SSL/TLS 终端等功能。 |
| Controller | Controller 是 Kubernetes 的控制循环,用于监控集群状态并执行所需的操作。 | 通过对比实际状态与期望状态,自动调整资源以确保系统稳定。 |
1.3 Kubernetes 组件
Kubernetes 的架构采用了一种主从设备模型,其中 Master Node 负责集群的管理和调度,而 Worker Node 则执行用户的应用程序。这个设计使得 Kubernetes 能够有效地进行容器编排和资源管理。
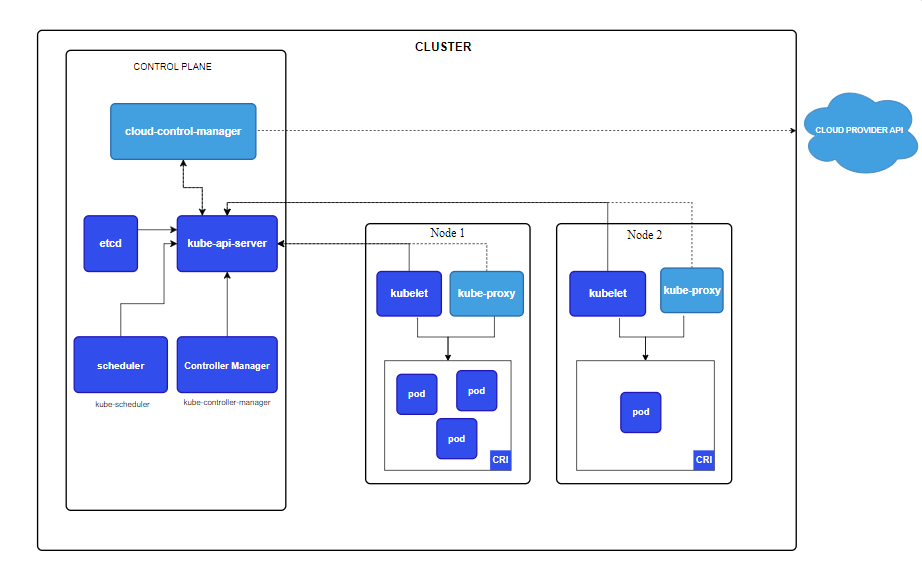
1.3.1 控制平面组件
控制平面组件会为集群做出全局决策,比如资源的调度以及检测和响应集群事件。
控制平面组件可以在集群中的任何节点上运行。 然而,一般情况下,控制平面组件都安装在Master 节点上,因为控制平面需要处理集群的管理和协调任务,集中在 Master 节点上可以提高管理效率。
| 组件 | 描述 |
|---|---|
| kube-apiserver | 整个集群的入口,负责处理所有的 API 请求、管理集群状态、进行认证和授权。 |
| etcd | 一致且高可用的键值存储,用作 Kubernetes 所有集群数据的后台数据库,负责存储集群状态和配置数据。 |
| kube-scheduler(调度器) | 接受来自kube-apiserver的任务,根据集群的资源情况和预定义的调度策略,将 Pods 调度到合适的 Node 上。 |
| kube-controller-manager(控制器管理器) | 负责管理集群中的各类控制器,确保集群的实际状态与期望状态保持一致。通过不断监测和调整 Kubernetes 资源的状态,来实现自动化管理和自愈能力,例如创建、更新或删除资源。 |
| cloud-controller-manager(云控制器管理器) | 专门用于与云提供商的 API 进行交互,将集群的云特有功能与 Kubernetes 的核心功能分离,使得 Kubernetes 可以在多种云环境中灵活运行。 |
1.3.2 节点组件
节点组件会在每个节点上(通常是Worker Node)运行,负责维护运行的 Pod 并提供 Kubernetes 运行时环境。
| 组件 | 描述 |
|---|---|
| kubelet | 负责管理 Pods 和容器的生命周期。作为 Kubernetes 的主要代理,通过与 Kubernetes API 服务器和容器运行时的交互,确保集群中容器的正常运行和高效管理。 |
| kube-proxy | 负责实现网络代理和负载均衡。在每个工作节点上运行,确保服务的网络流量能够正确地路由到相应的 Pods。用户也可选择其他的网络代理插件。 |
| Container runtime(容器运行时) | 是 Kubernetes 集群中用于运行和管理容器的组件。它负责容器的创建、启动、停止、删除以及维护容器的生命周期。 |
1.3.3 插件(Addons)
在 Kubernetes 中,插件(Addons) 是增强集群功能的组件,它们通常提供附加的功能和服务,如监控、日志管理、网络管理和存储等。
| 组件 | 描述 |
|---|---|
| DNS | 用于提供服务发现和名称解析功能。Kubernetes 内置的 DNS 功能使得 Pods 和服务可以通过 DNS 名称轻松互相访问,而不需要使用 IP 地址。 |
| Dashboard | 基于 Web 的用户界面,用于管理和监控 Kubernetes 集群。提供了一种直观的方式来查看集群的状态、管理资源以及执行各种操作。 |
| Flannel | 网络插件,简化容器网络的设置,提供跨主机网络,其他如Calico: 提供网络策略和网络安全功能;Weave Net: 提供容器间的网络连接,支持网络策略。 |
| Prometheus | 监控插件,用于监控和报警,支持多种数据来源。 |
| Persistent Volumes(PV) | 存储插件,处理持久化存储的管理和挂载。 |
1.4 应用
在 Kubernetes 中,应用可以分为有状态应用和无状态应用。
1.4.1 无状态应用
无状态应用是指不依赖于任何特定的会话数据或用户状态。每次请求都是独立的,服务器不需要存储会话信息。
特点:
- 可扩展性: 无状态应用可以轻松扩展,因为任何请求都可以被任何实例处理。
- 容错性: 如果某个实例失败,其他实例可以无缝接管请求。
- 易于部署: 更新和横向扩展简单,不需要考虑数据一致性问题。
示例:
- Web 服务器(如 Nginx、Apache)
- API 服务
- 静态文件托管
Kubernetes 资源: 通常使用 Deployment 资源来管理无状态应用。
1.4.2 有状态应用
有状态应用是指需要保持会话信息或数据状态。每个实例的状态是独立的,可能会影响应用的行为。
特点:
- 状态管理: 有状态应用需要管理和保存状态信息,通常需要持久化存储。
- 复杂性: 部署和管理较复杂,需要考虑数据一致性、故障恢复等。
- 数据迁移: 实例间的数据迁移和共享可能需要额外的配置。
示例:
- 数据库(如 MySQL、PostgreSQL、MongoDB)
- 缓存服务(如 Redis、Memcached)
- 消息队列(如 RabbitMQ、Kafka)
Kubernetes 资源: 通常使用 StatefulSet 资源(kube-controller-manager里的一个控制器)来管理有状态应用,以便提供稳定的网络身份和持久化存储。
1.5 YAML文件
在 Kubernetes 中,YAML 文件用于定义和配置各种资源,如 Pods、Services、Deployments、ReplicaSets 等。
语法规则:
- 大小写敏感,且资源类型通常使用大写(如
Pod、Service),而其他键如apiVersion、kind、metadata等使用小写。 - 层级:使用缩进表示层级关系,相同层级的元素左侧对齐。
- 缩进:使用空格进行缩进,不能使用制表符(Tab),通常每一级缩进使用两个空格。
- 键值对:使用冒号
:分隔键和值。值可以是字符串、数字、布尔值、列表或对象。 - 数据类型:支持字符串,数字,布尔,列表等
- 注释:使用
#来添加注释,注释在行内或单独一行均可。 - 分隔符:- - - 为可选的分隔符 ,当需要在一个文件中定义多个结构的时候需要使用。
- 特殊字符:如果值包含特殊字符(如冒号、空格等),需要用引号括起来。
每个 YAML 文件通常由以下几个部分组成:
- apiVersion: 指定资源的 API 版本。
- kind: 定义资源的类型(如 Pod、Service、Deployment 等)。
- metadata: 描述资源的元数据,如名称、标签和注释。
- spec: 资源的具体配置,定义资源的期望状态。
1.5.1 apiVersion
在 Kubernetes 中,apiVersion 字段用于指定资源的 API 版本,帮助 Kubernetes 确定如何处理该资源,因此,选择合适的 apiVersion 是非常重要的。使用不兼容的版本可能导致资源创建失败或不按预期工作。
apiVersion 字段通常由两个部分组成:
- 组(Group): 表示资源所属的 API 组。
- 版本(Version): 表示该组的版本号。
例如,apps/v1 由组 apps 和版本 v1 组成。
常见的 API 组和版本(更多请看官方文档):
core(v1): 不属于任何组的资源,如 Pods、Services、Namespaces 等。版本为 v1。
apiVersion: v1
kind: Pod
apps(v1): 包含与应用程序相关的资源,如 Deployments、ReplicaSets 和 StatefulSets。
apiVersion: apps/v1
kind: Deployment
batch(v1): 包含与批处理相关的资源,如 Jobs 和 CronJobs。
apiVersion: batch/v1
kind: Job
networking(v1): 包含与网络相关的资源,如 Ingress 和 NetworkPolicies。
apiVersion: networking.k8s.io/v1
kind: Ingress
rbac.authorization.k8s.io(v1): 包含与角色和权限相关的资源,如 Roles 和 RoleBindings。
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
1.5.2 实例
定义一个yaml文件 my-deployment.yaml
apiVersion: apps/v1 kind: Deployment metadata: name: my-deployment spec: replicas: 3 selector: matchLabels: app: my-app template: metadata: labels: app: my-app spec: containers: - name: my-container image: nginx:latest ports: - containerPort: 80
详解:
apiVersion: apps/v1 # 指定使用的 API 版本。在这里,apps/v1 表示这是一个 Deployment 类型的资源,属于 Kubernetes 的应用相关 API kind: Deployment # 定义资源的类型,Deployment用于管理 Pods 的副本 metadata: # 此部分包含资源的元数据 name: my-deployment # 资源的名称,自定义 spec: # 定义资源的期望状态 replicas: 3 # 指定要运行的 Pods 副本数,即运行3个容器 selector: # 用于选择与 Deployment 关联的 Pods matchLabels: # 定义选择器的标签。在这里,选择所有具有标签 app: my-app 的 Pods app: my-app # 标签,自定义 template: # 定义 Pods 的模板,用于创建新的 Pods metadata: # 包含 Pods 的元数据 labels: # 为模板中的 Pods 定义标签。在这里,所有由此 Deployment 创建的 Pods 都会被标记为 app: my-app app: my-app # 标签名,自定义 spec: # 定义 Pods 的具体配置 containers: # 列出 Pods 中的容器 - name: my-container # 容器的名称,自定义 image: nginx:latest # 容器所使用的基础Docker镜像,其他有CentOS,busybox,Ubuntu等 ports: # 列出容器暴露的端口 - containerPort: 80 # 指定容器内部的端口号
运行这个文件来创建一个Deployment,运行3个nginx容器,端口开放80
kubectl apply -f my-deployment.yaml
查看
# 查看 Deployment kubectl get deployments # 查看 Deployment 详细信息 kubectl describe deployment my-deployment # 查看 Pods kubectl get pods # 查看 Pod 详细信息 kubectl describe pod <pod-name> # 删除 kubectl delete deployment my-deployment
1.6 kubectl
kubectl 是 Kubernetes 的命令行工具,用于管理 Kubernetes 集群和其资源。它提供了一组命令,允许用户与 Kubernetes API 进行交互,从而执行各种操作,如创建、更新、删除和获取资源的状态。
主要功能:
-
管理集群资源:使用
kubectl可以创建、更新和删除 Pods、Deployments、Services 等各种 Kubernetes 资源。 -
查看资源状态:可以通过命令查看集群中各个资源的状态和详细信息,例如 Pods、Nodes、Namespaces 等。
-
调试和排错:提供命令用于查看日志、执行命令、进入容器等,帮助用户调试和维护应用程序。
- 配置管理:支持管理 Kubernetes 配置文件(如 kubeconfig),以便连接到不同的集群。
- 集成 CI/CD 工具:
kubectl可用于自动化和持续集成/持续部署(CI/CD)流程,方便与其他工具集成。
常用命令:
# 查看集群信息 kubectl cluster-info # 查看 Pods kubectl get pods # 创建资源 kubectl apply -f my-resource.yaml # 删除资源 kubectl delete pod my-pod # 查看 Pod 日志 kubectl logs my-pod # 进入容器 kubectl exec -it my-pod -- /bin/sh
kubectl apply -f 和kubectl create -f 和 kubectl replace -f:
在 Kubernetes 中,kubectl apply -f、kubectl create -f 和 kubectl replace -f 是用于管理资源的三种命令,适用于不同的场景,在大多数情况下,使用 kubectl apply -f 是最佳实践。
| 命令 | 创建新资源 | 更新现有资源 | 适用场景 |
|---|---|---|---|
kubectl apply -f |
是 | 是 | 日常工作流、CI/CD、团队协作 |
kubectl create -f |
是 | 否 | 确定资源不存在时的初始化设置 |
kubectl replace -f |
否 | 是 | 需要完全替换现有资源的情况 |
二、集群搭建
详见:https://www.cnblogs.com/Xinenhui/p/13931380.html
或者参考官方文档:https://kubernetes.io/zh-cn/docs/setup/production-environment/tools/
三、各概念简述
3.1 Pod
Pod 是 Kubernetes 中的最小可部署单元,通常包含一个或多个容器,这些容器共享存储、网络和运行环境。
共享网络: Pod 内的所有容器共享同一个 IP 地址和端口空间,可以通过 localhost 互相通信。
共享存储: Pod 可以挂载存储卷,所有容器都可以访问同一数据。
3.1.1 为什么有了容器还需要pod?
这是源自于pod的设计思想与使用目的。
Pod 的设计思想强调容器间的紧密协作、资源共享和统一的生命周期管理,旨在提高容器化应用的可维护性、灵活性和可扩展性。通过将多个相关的容器组合在同一个 Pod 中,Kubernetes 提供了一种高效的方式来构建和管理现代云原生应用。
设计思想:
- 多容器协作
- 紧密关联:Pod 允许在同一个环境中运行多个容器,这些容器通常是紧密相关的功能模块。通过将它们组合在一起,Pod 促进了容器之间的高效协作。
- 共享资源
- 网络命名空间:Pod 内的所有容器共享相同的网络命名空间,意味着它们可以使用相同的 IP 地址和端口进行通信。这种设计减少了网络延迟,提高了通信效率。
- 共享存储:Pod 可以定义一个或多个 Volume,所有容器可以挂载这些 Volume,从而实现数据的共享。
- 生命周期管理
- 统一管理:Pod 提供了一个统一的生命周期管理机制,所有容器可以一起启动、停止和重启,确保它们在相同状态下运行。这简化了运维管理,减少了复杂性。
- 可扩展性与弹性
- 横向扩展:Pod 作为一个整体,可以方便地进行扩展和缩减,支持动态负载变化的需求。
- 容错性:Kubernetes 可以监控 Pod 的健康状态,当 Pod 发生故障时,可以自动重启或替换它,确保服务的高可用性。
使用目的:
- 运行多个相关服务:Pod 适合运行多个相互依赖的服务,例如一个 Web 服务器和一个反向代理或缓存服务。通过将它们放在同一个 Pod 中,可以简化服务间的通信和协作。
- 提供基础设施功能:使用 Sidecar 模式,Pod 可以运行基础设施服务(如日志收集、监控等),使应用容器专注于业务逻辑,而将其他功能交给 Sidecar 容器处理。
- 处理数据流:在数据处理场景中,可以将数据提取、处理和存储的多个容器组合在同一个 Pod 中,简化数据流动和处理逻辑。
- 支持微服务架构:在微服务架构中,Pod 可以作为一个微服务的基本单元,使得每个微服务可以独立开发、部署和扩展,同时保留紧密的协作能力。
- 运行批处理任务:Pod 也可以用于运行批处理作业,使用 Init 容器来设置环境,业务容器来执行任务,实现定时任务或一次性任务的处理。
Sidecar 模式:Sidecar 模式是一种强大的设计模式,在微服务架构和容器化环境中广泛使用。通过将附加功能与主应用容器分离,Sidecar 提高了系统的灵活性、可维护性和可扩展性。它使得开发者能够专注于业务逻辑,同时利用 Sidecar 提供的基础设施服务。
Init 容器:Init 容器是在应用容器启动之前运行的特殊容器,用于执行初始化任务,如执行配置、数据迁移、依赖检查等任务,确保主应用容器在启动前处于正确状态。
例一:成组调度
现在k8s集群上有两个节点:node-1上有3GB可用内存,node-2上有2GB可用内存。
启动一个服务,需要运行三个模块,用三个容器来运行,这三个容器一定要运行在同一台机器上,否则会出问题,而三个容器的内存配额都是1GB。
执行创建容器的命令后,前两个容器都调度到了node-2上,但此时,node-2已没有内存可以再运行第三个容器了,这个服务也因缺少第三个容器而启动失败。
这就是一个典型的成组调度(gang scheduling)没有被妥善处理的例子,而有了pod,这个问题就可避免。
因为Kubernetes 项目的调度器,是统一按照 Pod 而非容器的资源需求进行计算的,在调度时,自然就会去选择可用内存等于 3 GB 的 node-1 节点进行绑定,而根本不会考虑 node-2。
例二:war包与web服务器
有一个 Java Web 应用的 WAR 包,它需要被放在 Tomcat 的 webapps 目录下运行起来,如果使用容器,有两种方式:
1、把 WAR 包直接放在 Tomcat 镜像的 webapps 目录下,做成一个新的镜像运行起来。但如果要更新 WAR 包的内容,或者要升级 Tomcat 镜像,就要重新制作一个新的发布镜像,非常麻烦。
2、只发布Tomcat容器,这个容器的 webapps 目录,声明一个 hostPath 类型的 Volume,从而把宿主机上的 WAR 包挂载进 Tomcat 容器当中运行起来。但宿主机需先准备好这个WAR包的目录,因为不知道容器在哪个节点上运行,所以还得独立维护一套分布式存储系统。
使用pod的话,可以运行两个容器,第一个是Init 容器,只用于打包WAR包,然后拷贝到挂载卷上退出;第二个容器为运行Tomcat,声明了挂载这个卷到自己的 webapps 目录下。
所以,等 Tomcat 容器启动时,它的 webapps 目录下就一定会存在 sample.war 文件:这个文件正是 WAR 包容器启动时拷贝到这个 Volume 里面的,而这个 Volume 是被这两个容器共享的。
3.1.2 Pause 容器
在 Kubernetes 中,每个 Pod 通常会包含一个特殊的容器,称为 Pause 容器(根容器),也被称为 基础设施容器。用户通常不需要直接管理 Pause 容器,它在 Pod 创建时自动启动,用户只需关注业务容器。
Pause 容器是一个轻量级的容器,通常是一个只包含基本工具的 Linux 镜像,用于创建 Pod 的网络命名空间和其他基础设施功能。如 gcr.io/google_containers/pause。
查看:由于 Pause 容器是 Kubernetes 默认生成的,因此它不会在 Pod 定义中显式列出。但是可以通过查看 Pod 的网络命名空间来间接确认其存在。
3.1.2.1 功能
网络命名空间
- 共享网络: Pause 容器创建并持有 Pod 的网络命名空间,后续启动的容器通过Join Network Namespace 的方式加入这个网络命名空间,所以在同一 Pod 中的业务容器能共享这一网络命名空间,这意味着它们可以通过
localhost互相通信。 - IP 地址分配: Pause 容器使得 Pod 拥有一个单独的 IP 地址,该地址被分配给整个 Pod,而不是单个容器。
资源管理
- 资源隔离: Pause 容器提供了一个基础设施层,帮助 Kubernetes 管理 Pod 中的容器资源。Pod 的生命周期与 Pause 容器相绑定。
- 容器状态管理: 当 Kubernetes 需要检查 Pod 的状态时,它可以通过 Pause 容器来管理和跟踪 Pod 的健康状态。
注:在pod里,Pause 容器是最先启动的,并且一直运行,直到pod被删除。
3.1.2.2 与业务容器的关系
- 紧密耦合: 用户业务容器是 Pod 中的主要应用容器,通常执行实际的业务逻辑。它们与 Pause 容器紧密耦合,共享网络和存储资源。
- 容器间协作: 通过共享 Pause 容器的网络命名空间,用户业务容器能够高效地进行数据交换和通信。
3.1.3 资源限制
在 Kubernetes 中,可以为 Pod 设置资源限制,以确保应用程序在运行时不会消耗过多的资源。资源限制主要包括 CPU 和内存。
资源请求(Requests): 表示容器启动时所需的最低资源量。如果节点没有足够的资源满足请求,该 Pod 将不会被调度到该节点。
资源限制(Limits): 表示容器可以使用的最大资源量。如果容器尝试使用超过这个限制的资源,会终止这个容器。
示例
apiVersion: v1 kind: Pod metadata: name: my-pod spec: containers: - name: my-container image: nginx resources: requests: memory: "64Mi" # 请求的内存 cpu: "250m" # 请求的 CPU limits: memory: "128Mi" # 限制的内存 cpu: "500m" # 限制的 CPU
内存单位:
- B: 字节
- Ki: Kibibyte(1024 字节)
- Mi: Mebibyte(1024 KiB)
- Gi: Gibibyte(1024 MiB)
- Ti: Tebibyte(1024 GiB)
cpu单位:
- 核(Core): 通常表示为
1,代表一个完整的 CPU 核心。 - 毫核(milli-core): 使用
m表示,表示一个 CPU 核心的千分之一。
3.1.4 镜像拉取
在yaml文件里,可以定义容器镜像拉取的策略。
- Always: 每次启动 Pod 时都拉取镜像。适用于需要确保使用最新版本的镜像。
- IfNotPresent: 只有在本地不存在镜像时才拉取,默认策略。
- Never: 不拉取镜像,假设镜像已经在节点上。适用于开发或测试环境
默认情况下,Kubernetes 从 Docker Hub 或指定的私有镜像仓库拉取镜像;如果镜像名称中包含仓库地址(如 my-registry/my-image:tag),Kubernetes 将从该地址拉取。
如果镜像是私有的,Kubernetes 会使用相应的凭证进行身份验证;这些凭证通常存储在 Kubernetes 中的 Secret 对象中,并与 ServiceAccount 绑定。
如果拉取镜像失败,Kubernetes 将根据 Pod 的配置重试拉取。如果多次失败,Pod 将进入 ImagePullBackOff 状态;管理员可以通过检查 Pod 的事件或使用 kubectl describe pod <pod-name> 命令来查看具体错误信息。
示例
apiVersion: v1 kind: Pod metadata: name: my-nginx-pod labels: app: nginx spec: containers: - name: nginx-container image: nginx:latest # 使用最新的 Nginx 镜像 imagePullPolicy: Always # 每次都拉取镜像 ports: - containerPort: 80
3.1.5 重启策略
在 Kubernetes 中,Pod 的重启策略(restartPolicy)决定了容器在失败后的处理方式。
- Always:无论容器的退出状态如何,Kubernetes 始终会重启该容器。通常用于长时间运行的服务,如 Web 应用或数据库。
- OnFailure:仅在容器以非零状态退出时(表示失败)重启容器。适合批处理任务或需要在失败后重新尝试的场景。
- Never:无论容器的退出状态如何,Kubernetes 都不会重启该容器。适用于一次性任务或批处理作业,通常与
Job资源一起使用。
示例
apiVersion: v1 kind: Pod metadata: name: always-restart-pod spec: restartPolicy: Always # 设置重启策略 containers: - name: my-container image: my-image:latest
3.1.6 Pod的类型
- 单容器 Pod
- 定义: 每个 Pod 只包含一个容器。
- 场景: 适用于简单的应用程序,易于管理和监控。大多数情况下,用户会创建这种类型的 Pod。
- 多容器 Pod
- 定义: 一个 Pod 包含多个容器,这些容器紧密协作。
- 类型:
- Sidecar 模式: 通过辅助容器提供附加功能,例如日志收集、监控等。
- Init Containers: 在主容器启动之前执行初始化任务,用于设置环境或预处理。
- 代理模式: 代理容器处理主应用与外部的通信。
- DaemonSet Pods
- 定义: 这种 Pod 确保在每个节点上运行一个 Pod 副本。
- 场景: 适用于需要在每个节点上运行某些服务的情况,例如监控代理或日志收集器。
- Job Pods
- 定义: 用于执行一次性的任务或批处理作业。
- 场景: 适用于需要完成某项任务后退出的应用,例如数据处理或数据库迁移。
- CronJob Pods
- 定义: 类似于 Job,但按照预定的时间表定期创建 Pods。
- 场景: 适用于定期任务,例如备份、报告生成等。
- StatefulSet Pods
- 定义: 用于管理有状态应用的 Pods,确保每个 Pod 有一个唯一的身份和持久化存储。
- 场景: 适用于数据库和其他需要稳定网络身份和持久存储的应用。
- Replication Controller / ReplicaSet Pods
- 定义: 确保指定数量的 Pod 副本在任何时候都在运行。
- 场景: 适用于负载均衡和高可用性的需求。
- Namespace-specific Pods
- 定义: Pods 可以在不同的 Namespace 中创建,以实现逻辑隔离。
- 场景: 适合多租户环境或不同开发、测试、生产环境的隔离。
3.1.7 调度
Kubernetes 中的 Pod 调度是将 Pods 分配到适当节点的过程。调度器负责根据多种因素(如资源需求、节点可用性、亲和性规则等)来决定 Pods 的运行位置。
调度过程一般分为两个步骤:
过滤阶段:调度器会根据条件过滤出不符合要求的节点
- 资源需求: 检查节点是否有足够的 CPU、内存等资源。
- 节点亲和性: 检查 Pods 是否有特定的节点亲和性或反亲和性要求。
- 污点和容忍: 处理节点的污点和 Pods 的容忍度。
- Pod 反亲和性: 确保 Pods 不会被调度到不允许的节点上。
优先级阶段:在过滤出可用的节点后,调度器会根据优先级评分,选择最合适的节点,优先级包括
- 最少使用资源: 选择当前资源使用最少的节点。
- 节点亲和性: 优先选择符合 Pods 亲和性规则的节点。
- 均衡负载: 尽量将 Pods 均匀分布到各个节点上。
调度方式
- 自动调度:使用控制器(如RS,DaemonSet)创建的 Pods 会由 Kubernetes 自动调度到最适合的节点,后文介绍
- 手动调度:通过在 Pod 定义中直接指定
nodeName字段或nodeSelector字段,将 Pod 调度到特定节点 - 其他调度:如亲和性调度,污点和容忍等
3.1.7.1 标签
Kubernetes 中的标签(Labels)是用于组织和选择对象(如 Pods、节点等)的关键机制。标签是附加到对象上的键值对,用于标识和分类这些对象,以便于管理和查询。
1. 标签的基本概念
- 键值对: 标签由一个键(Key)和一个值(Value)组成,格式为
key: value。 - 多元性: 同一个对象可以有多个标签,标签的组合可以提供更丰富的上下文信息。
2. 标签的用途
- 选择器: 可以使用标签选择器(Label Selector)来选择特定的对象。例如,可以选择所有具有某个特定标签的 Pods。
- 分组: 标签用于将相关的资源分组,以便进行管理和查询。
- 调度: 节点标签可以帮助调度器将 Pods 调度到适当的节点上。
- 服务发现: 通过标签,Kubernetes 服务可以选择一组 Pods 进行负载均衡。
3. 标签的格式
- 键: 必须小写字母、数字、下划线(_)、连字符(-)和点(.),且不能以点(.)开头或结尾,最大长度为 63 个字符。
- 值: 可以是任意字符,但最大长度为 63 个字符,且可以为空。
4. 标签选择器
标签选择器用于根据标签选择对象,主要有以下两种类型:
- 等值选择器: 选择具有特定键值对的对象。
- 集合选择器: 选择具有特定键的对象,并且值在给定的集合中。
为pod打标签:
apiVersion: v1 kind: Pod metadata: name: my-pod labels: app: my-app environment: production spec: containers: - name: my-container image: my-image:latest
使用命令行
# 查看 kubectl get pods --show-labels # 创建 kubectl label pods my-pod app=my-app # 覆盖已有标签 kubectl label pods my-pod environment=staging --overwrite # 删除 kubectl label pods my-pod environment-
为node打标签
apiVersion: v1 kind: Node metadata: name: my-node labels: disktype: ssd zone: us-west-1a
使用命令行
kubectl label nodes my-node disktype=ssd
3.1.7.2 NodeName
在 Kubernetes 中,使用 nodeName 字段可以将 Pod 直接调度到特定的节点,nodeName 是 Pod 的一个属性,允许用户在 Pod 的配置中指定要在哪个节点上运行。
注意事项:
- 跳过调度器: 使用
nodeName时,Kubernetes 调度器会跳过调度过程,直接将 Pod 绑定到指定的节点。 - 节点状态: 确保指定的节点处于可用状态(NotReady 状态的节点无法调度 Pods)。
- 资源分配: 仍然需要确保指定节点有足够的资源来满足 Pod 的需求(如 CPU 和内存)。
适用场景:
- 硬件依赖: 当应用需要特定硬件(如特定型号的 GPU)时,可以将其调度到具备该硬件的节点。
- 网络配置: 对于需要特定网络配置的 Pods,可以指定在具有相应网络设置的节点上运行。
实例
apiVersion: v1 kind: Pod metadata: name: my-pod spec: nodeName: my-node # 指定要调度的节点名称 containers: - name: my-container image: my-image:latest
3.1.7.3 NodeSelector
NodeSelector 是 Pod 规格中的一个字段,允许用户指定节点的标签,以便将 Pods 调度到具有特定标签的节点上。适用于需要特定资源或特征的 Pods,例如要求在 SSD 存储节点上运行的数据库 Pods。
如果没有节点满足 NodeSelector 的条件,Pod 将不会被调度,状态会保持为 Pending。除了标签匹配外,确保目标节点有足够的资源(如 CPU、内存)来满足 Pod 的需求。
先为节点打上标签
kubectl label nodes my-node disktype=ssd
yaml文件里选择这个标签
apiVersion: v1 kind: Pod metadata: name: my-pod spec: nodeSelector: disktype: ssd # 指定节点标签 containers: - name: my-container image: my-image:latest
删除标签
kubectl get nodes --show-labels kubectl label nodes <node-name> <label-key>-
3.1.7.4 Taint(污点)
Taint 是节点的一种属性,用于标识节点不适合某些 Pods。通过在节点上设置污点,可以阻止 Pods 被调度到这些节点,除非它们具有相应的容忍度。
Taint 由三个部分构成:
- Key: 污点的名称,通常是一个字符串
- Value: 污点的具体值,通常是一个字符串
- Effect: 污点的效应,可以是以下三种之一:
NoSchedule: 不允许没有容忍度的 Pods 调度到该节点。PreferNoSchedule: 尽量不调度没有容忍度的 Pods 到该节点,但不是强制的。NoExecute: 不允许没有容忍度的 Pods 在该节点上运行,如果已在运行,会被驱逐。
为节点添加污点
kubectl taint nodes node1 key=value:NoSchedule
删除污点
kubectl describe nodes <node-name>
kubectl taint nodes <node-name> <key>:<value>:<effect>-
污点使用 Key-Value 的组合的原因:
重要的原因:
1. 灵活性
- 多样性: 通过使用 Key 和 Value 的组合,可以为同一个 Key 定义多个不同的情况。例如,可以有多个污点,如:
key: "maintenance", value: "true"key: "maintenance", value: "false"
2. 语义清晰
- 上下文信息: Key 提供了污点的上下文,而 Value 则提供了具体的状态或条件。例如,
key: "diskPressure"表示与磁盘压力相关,而value: "true"则表明当前存在磁盘压力。这样的组合使得污点的意义更加清晰。
3. 兼容性与扩展性
- 兼容性: 使用 Key-Value 对的设计与 Kubernetes 的标签(Labels)和选择器(Selectors)一致,确保了系统的一致性和可预测性。
- 扩展性: 如果将来需要添加新的条件或状态,只需在现有的 Key 下添加新的 Value,而不需要修改整体的设计。
4. 逻辑判断
- 条件表达: 通过这种设计,可以更容易地表达逻辑条件。例如,可以通过组合不同的 Key 和 Value 来实现复杂的调度策略,便于 Kubernetes 调度器在做决策时进行更细致的判断。
3.1.7.5 Toleration(容忍)
Toleration 是 Pods 的一种属性,用于声明它们可以容忍哪些污点。具有相应容忍度的 Pods 可以被调度到带有特定污点的节点上。
Toleration 也由三个部分构成:
- key: 污点的名称
- operator: 指定如何比较 Toleration 的 Key 和污点的 Key
Equal: 表示 Toleration 的 Key 和污点的 Key 必须完全相等Exists: 表示只需要污点的 Key 存在,而不关心其值。这是一个更宽松的匹配方式
- value: 表示污点的具体值
- 当使用
Equal操作符时,需要指定一个值 - 当使用
Exists操作符时,value字段可以省略
- 当使用
- effect: 污点的效应
- TolerationSeconds(可选): 表示容忍的有效时间(以秒为单位),时间过后将被驱逐
实例
apiVersion: v1 kind: Pod metadata: name: my-pod spec: tolerations: - key: "key" operator: "Equal" value: "value" effect: "NoSchedule" - key: "diskPressure" operator: "Exists" effect: "NoExecute" tolerationSeconds: 3600 # 允许 Pods 在带有 diskPressure 污点的节点上运行 1 小时 containers: - name: my-container image: my-image:latest
3.1.7.6 亲和性调度
Kubernetes 中的亲和性(Affinity)调度机制允许用户更灵活地控制 Pods 的调度行为,从而实现更高效的资源利用和负载均衡。亲和性主要分为两类:节点亲和性(Node Affinity)和 Pod 亲和性(Pod Affinity/Anti-Affinity)。
3.1.7.6.1 节点亲和性(Node Affinity)
节点亲和性允许根据节点的标签选择 Pods 的调度节点,可以看做NodeSelector的升级版,它支持强制性和软性亲和性。
必需亲和性(Required Node Affinity):Pods 只能被调度到满足条件的节点上。如果没有符合条件的节点,Pod 将处于 Pending 状态。用 requiredDuringSchedulingIgnoredDuringExecution 表示
可选亲和性(Preferred Node Affinity):Pods 尽量被调度到满足条件的节点上,但不是强制的。如果没有符合条件的节点,Pod 仍然可以被调度到其他节点。用 preferredDuringSchedulingIgnoredDuringExecution 表示
组成:
nodeAffinity: 定义节点亲和性preferredDuringSchedulingIgnoredDuringExecution: 表示这是软亲和性nodeSelectorTerms: 定义选择条件matchExpressions: 使用表达式进行匹配- key: 需要匹配的标签名称
- operator: 匹配操作符,支持以下几种:
- In: 匹配值在指定列表中
- NotIn: 匹配值不在指定列表中
- Exists: 只需存在指定的标签,值不重要
- DoesNotExist: 标签不存在
values: 标签的值
实例
apiVersion: v1 kind: Pod metadata: name: my-pod spec: affinity: nodeAffinity: # 亲和性配置 requiredDuringSchedulingIgnoredDuringExecution: # 硬亲和性 nodeSelectorTerms: # 定义节点选择条件 - matchExpressions: # 使用表达式进行匹配 - key: disktype # 要匹配的节点标签 operator: In # 表示节点的 disktype 标签的值必须在指定的值列表中 values: # 只有当节点的 disktype 标签值为 ssd 时,Pod 才能被调度到该节点 - ssd preferredDuringSchedulingIgnoredDuringExecution: # 软亲和 - weight: 1 preference: matchExpressions: - key: zone operator: In values: # 选择多个标签值 - us-west-1a - us-west-1b containers: - name: my-container image: my-image:latest
3.1.7.6.2 Pod 亲和性(Pod Affinity/Anti-Affinity)
Pod 亲和性机制允许将 Pods 调度到有运行着的满足条件的 Pods 所在的拓扑域上,Pod 亲和性分为两种类型:Pod 亲和性和Pod 反亲和性。
拓扑域:是 Kubernetes 中的一种概念,用于定义资源的分布范围。它用于指示 Pods 或节点的分布情况,确保在特定的物理或逻辑范围内进行调度。通常通过节点标签来实现。
常见的拓扑域包括:
- 节点(Node): 指定 Pods 必须在同一个节点上运行。
- 机架(Rack): 指定 Pods 必须在同一个机架上。
- 可用区(Availability Zone): 指定 Pods 必须在同一个可用区内。
- 区域(Region): 指定 Pods 必须在同一个区域内。
Pod 亲和性(Pod Affinity)
将 Pods 调度到与特定标签的 Pods 一起运行的节点上
apiVersion: v1 kind: Pod metadata: name: my-app-pod spec: affinity: podAffinity: # 定义 Pods 之间的亲和性 requiredDuringSchedulingIgnoredDuringExecution: # 硬亲和性,Pods 只能被调度到满足条件的节点上。 labelSelector: # 指定要匹配的 Pods 标签 matchLabels: app: my-app topologyKey: "kubernetes.io/hostname" # 指定用于分布 Pods 的拓扑键,这里使用 kubernetes.io/hostname,意味着 Pods 将被调度到同一节点上 containers: - name: my-container image: my-image:latest
Pod 反亲和性(Pod Anti-Affinity)
确保 Pods 不会被调度到与特定标签的 Pods 一起运行的节点上
apiVersion: v1 kind: Pod metadata: name: my-other-app-pod spec: affinity: podAntiAffinity: # 定义 Pods 之间的反亲和性 preferredDuringSchedulingIgnoredDuringExecution: # 表示这是软反亲和性,Pods 尽量不被调度到满足条件的节点上,但不是强制的。 podAffinityTerm: # 定义反亲和性条件 labelSelector: matchLabels: app: my-app topologyKey: "kubernetes.io/hostname" containers: - name: my-other-container image: my-other-image:latest
3.1.8 健康检查
在 Kubernetes 中,Pod 健康检查(Health Checks)用于确保应用程序的健康状态,以便 Kubernetes 可以自动管理和恢复不健康的 Pods。
健康检查类型主要有存活探针(Liveness Probe)和就绪探针(Readiness Probe)以及启动探针(Startup Probe)。
| 探针类型 | 启动探针 | 就绪探针 | 存活探针 |
|---|---|---|---|
| 目的 | 检查应用程序是否完成启动 | 检查容器是否准备好接受流量 | 检查容器是否仍在运行 |
| 探针失败 | Kubernetes 将认为容器启动失败,可能会重启该容器 | Kubernetes 将停止向该 Pod 发送流量,但容器仍然处于运行状态 | Kubernetes 会重启容器 |
| 适用场景 | 适用于有复杂启动过程的应用,确保这些应用在准备好之后才开始接受流量。 | 适合于一般应用的健康检查,确保在应用完成初始化后能够处理请求 | 适用于需要自动重启的服务 |
三种健康检查方法:命令行(exec)、HTTP GET(httpGet) 和 TCP Socket(tcpSocket)
| 方法 | exec | httpGet | tcpSocket |
|---|---|---|---|
| 定义 | 在容器内执行命令 | 通过 HTTP GET 请求检查健康状态 | 通过 TCP 连接检查健康状态 |
| 适用场景 | 需要通过特定命令检查健康状态的场景,灵活性高 | 基于 HTTP 协议的服务,直接请求接口,如 Web 应用 | 网络服务和数据库等需要检查端口可用性的场景 |
示例
apiVersion: v1 kind: Pod metadata: name: my-app spec: containers: - name: my-container image: my-image:latest # 存活探针配置 livenessProbe: # 使用命令行检查容器健康状态 exec: command: - cat # 要执行的命令 - /tmp/healthy # 健康文件的路径 initialDelaySeconds: 15 # 容器启动后等待15秒再进行检查 periodSeconds: 10 # 每10秒检查一次 timeoutSeconds: 5 # 如果命令在5秒内没有返回,视为失败 failureThreshold: 3 # 允许连续失败3次后重启容器 # 就绪探针配置 readinessProbe: # 使用HTTP GET请求检查容器是否准备好 httpGet: path: /healthz # 健康检查的HTTP路径 port: 8080 # 要检查的端口 initialDelaySeconds: 5 # 容器启动后等待5秒再进行检查 periodSeconds: 10 # 每10秒检查一次 timeoutSeconds: 3 # 如果请求在3秒内没有响应,视为失败 failureThreshold: 2 # 允许连续失败2次后将Pod标记为不就绪 # 启动探针配置 startupProbe: # 使用TCP Socket检查容器启动状态 tcpSocket: port: 8080 # 要检查的TCP端口 initialDelaySeconds: 10 # 容器启动后等待10秒再进行检查 periodSeconds: 5 # 每5秒检查一次 timeoutSeconds: 3 # 如果连接在3秒内没有成功,视为失败 failureThreshold: 5 # 允许连续失败5次后认为启动失败
3.1.9 生命周期
Pod 的生命周期是由多个阶段组成的,每个阶段对应一种状态,Pod 的状态反映了其当前的运行情况和健康状况。
| 状态值 | 描述 |
|---|---|
| Pending(待定) | Pod 被创建,但还未被调度到某个节点上。这可能是因为没有可用的资源,或是调度器正在寻找合适的节点。 |
| Running(运行中) | Pod 已经被调度到节点上,并且至少有一个容器正在运行。此时,Pod 的所有容器可能都在运行,或者有些容器正在启动(Initializing)。 |
| Succeeded(成功) | Pod 中的所有容器都已成功退出,并且不会再重新启动。通常用于批处理作业。 |
| Failed(失败) | Pod 中的容器退出并且至少有一个容器以失败状态结束(非零退出代码)。这意味着容器未能成功执行其任务。 |
| Unknown(未知) | 对于 Kubernetes 系统,Pod 的状态无法确定。这通常是因为无法与 Pod 所在节点通信。 |
Pod 的生命周期也涉及多个事件
| 事件 | 描述 |
|---|---|
| 创建 | Pod 被定义并提交到 Kubernetes API |
| 调度 | Kubernetes 调度器决定将 Pod 调度到哪个节点 |
| 启动 | 容器开始启动,执行初始化过程 |
| 健康检查 | Kubernetes 执行探针检查(活跃探针、就绪探针、启动探针) |
| 终止 | Pod 被请求删除,容器开始退出过程 |
| 删除 | Pod 从 Kubernetes 集群中删除 |
每个 Pod 内的容器也有其独立的状态,主要包括:
- Waiting(等待中): 容器正在等待某些条件满足,例如依赖的容器尚未启动或镜像尚未下载。
- Running(运行中): 容器正在运行,没有错误。
- Terminated(已终止): 容器已终止运行,包含以下信息:
- Exit Code: 容器的退出代码(0 表示成功,非零表示失败)。
- Reason: 终止原因(如 OOMKilled、Error、Completed)。
生命周期示意图

3.1.9.1 终止过程
在 Kubernetes 中,Pod 的终止过程是一个重要的生命周期管理环节。当 Pod 被请求删除时,Kubernetes 会依照一定步骤执行终止操作,以确保容器的优雅关闭和资源的合理释放。
1. 发送终止信号
- 信号类型: Kubernetes 会向 Pod 中的每个容器发送
SIGTERM信号。这是一个请求容器优雅关闭的信号。 - 目的: 容器接收到此信号后,可以进行清理工作,例如保存状态、释放资源等。
2. 初始延迟
preStop钩子: 如果容器配置了preStop钩子,Kubernetes 会在发送SIGTERM信号后,执行该钩子中的命令。- 延迟时间: 容器有一个默认的时间(默认为 30 秒)来完成其清理操作。如果容器在此时间内正常退出,Pod 将顺利终止。
3. 容器终止
- 优雅退出: 容器在接收到
SIGTERM后,可以执行必要的清理工作,并最终退出。 - 强制终止: 如果容器在指定的时间内未能正常退出,Kubernetes 将发送
SIGKILL信号,强制终止容器。
4. 更新 Pod 状态
- 状态转换: 一旦所有容器都已终止,Pod 的状态将更新为
Succeeded或Failed,具体取决于容器的退出代码。 - 资源释放: Kubernetes 会清理与 Pod 相关的资源(如网络、存储等),并将其标记为已删除。
5. Pod 删除
- 从调度状态中移除: 最后,Pod 会从 Kubernetes 集群中完全删除,所有相关的资源也会被释放。
配置preStop 钩子
apiVersion: v1 kind: Pod metadata: name: my-app spec: containers: - name: my-container image: my-image:latest lifecycle: # 在容器的定义中添加 lifecycle 字段 preStop: # 在 lifecycle 中定义 preStop 钩子 exec: # 使用 exec 类型来指定要执行的命令 command: - /bin/sh - -c - echo "Cleaning up before shutdown..." && sleep 5 ports: - containerPort: 8080
3.2 挂载卷(Volume)
在容器中的文件在磁盘上是临时存放的,当容器关闭时这些临时文件也会被一并清除。这给容器中运行的特殊应用程序带来一些问题。
首先,当容器崩溃时,kubelet 将重新启动容器,容器中的文件将会丢失——因为容器会以干净的状态重建。
其次,当在一个 Pod 中同时运行多个容器时,常常需要在这些容器之间共享文件。
因此,Kubernetes 抽象出 Volume 对象来解决这两个问题。
Kubernetes Volume卷具有明确的生命周期——与包裹它的 Pod 相同。 因此,Volume比 Pod 中运行的任何容器的存活期都长,在容器重新启动时数据也会得到保留。 当然,当一个 Pod 不再存在时,Volume也将不再存在。更重要的是,Kubernetes 可以支持许多类型的Volume卷,Pod 也能同时使用任意数量的Volume卷。
使用卷时,Pod 声明中需要提供卷的类型 (.spec.volumes 字段)和卷挂载的位置 (.spec.containers.volumeMounts 字段).
3.2.1 Volume类型
| 类型 | 描述 | |
|---|---|---|
| emptyDir | 在 Pod 生命周期内创建的空目录;当 Pod 被删除时,数据会丢失 | 适用于临时数据存储,如缓存文件或中间数据 |
| hostPath | 允许将主机文件系统的目录挂载到 Pod 中 | 用于访问主机文件系统的特定目录,适合调试或特定的系统管理任务 |
| NFS (Network File System) | 允许通过网络共享存储,多个 Pod 可以同时访问同一个 NFS 服务器上的目录 | 适用于需要共享数据的多个 Pod,如日志存储或共享配置 |
| PersistentVolume (PV) 和 PersistentVolumeClaim (PVC) | PV 是集群中的持久存储资源,而 PVC 是用户对存储的请求 | 适用于需要持久化存储的应用,如数据库和文件存储 |
| ConfigMap | 用于存储非敏感的配置信息,可以将其挂载为文件或环境变量 | 适合动态配置应用程序的环境变量或配置文件 |
| Secret | 用于存储敏感信息(如密码、令牌等),可以以文件或环境变量的形式挂载 | 适合存储密码、API 密钥等敏感数据 |
| Downward API | 提供 Pod 的元数据(如名称、UID 等),可以作为环境变量或文件挂载到容器中 | 适合需要访问 Pod 元数据的应用 |
| GitRepo | 允许将 Git 仓库挂载为 Volume,容器可以直接访问代码 | 用于开发环境或临时访问存储在 Git 中的资源 |
| Azure Disk / AWS EBS / GCE Persistent Disk | 各种云提供商的持久化存储,允许在云环境中使用持久化卷 | 适合在云环境中运行的应用,提供高可用性和持久性 |
| Projected Volume | 允许将多个 Volume 类型(如 ConfigMap、Secret、Downward API)组合在一起 | 适合需要组合多种动态信息的复杂应用 |
3.2.2 emptyDir
当 Pod 指定到某个节点上时,首先创建的是一个 emptyDir 卷,并且只要 Pod 在该节点上运行,卷就一直存在,卷最初是空的。
尽管 Pod 中每个容器挂载 emptyDir 卷的路径可能相同也可能不同,但是这些容器都可以读写 emptyDir 卷中相同的文件。
如果Pod中有多个容器,其中某个容器重启,不会影响emptyDir 卷中的数据。当 Pod 因为某些原因被删除时,emptyDir 卷中的数据也会永久删除。
注意:容器崩溃并不会导致 Pod 被从节点上移除,因此容器崩溃时 emptyDir 卷中的数据是安全的。
示例:
创建一个 Pod,其中包含两个容器:一个用于写入文件,另一个用于读取文件。它们共享一个 emptyDir Volume。
apiVersion: v1 kind: Pod metadata: name: emptydir-example spec: containers: - name: writer image: busybox command: ["sh", "-c", "echo 'Hello, World!' > /data/message.txt; sleep 3600"] volumeMounts: - mountPath: /data name: emptydir-volume - name: reader image: busybox command: ["sh", "-c", "cat /data/message.txt; sleep 3600"] volumeMounts: - mountPath: /data name: emptydir-volume volumes: - name: emptydir-volume emptyDir: {}
3.2.3 hostPath
hostPath 卷是 Kubernetes 中的一种卷类型,允许容器直接访问节点文件系统中的特定路径。
除了必需的 path 属性之外,还可以选择性地为 hostPath 卷指定 type 属性。type 属性用于指示所提供路径的类型,以便更好地管理和验证卷的使用。如果指定的路径属性跟设置的不一致,Kubernetes 会返回错误。
| type值 | 描述 |
|---|---|
| File | 指定路径是一个普通文件 |
| Directory | 指定路径是一个目录 |
| Socket | 指定路径是一个 Unix 域套接字 |
| BlockDevice | 指定路径是一个块设备 |
| CharDevice | 指定路径是一个字符设备 |
示例:
创建一个pod,将宿主机的 /path/on/host 目录挂载至容器内的/data上
apiVersion: v1 kind: Pod metadata: name: hostpath-example spec: containers: - name: app-container image: busybox command: ["sh", "-c", "echo 'Hello from hostPath!' > /data/message.txt; sleep 3600"] volumeMounts: - mountPath: /data name: hostpath-volume volumes: - name: hostpath-volume hostPath: path: /path/on/host type: Directory
3.2.4 Secret
在 Kubernetes 中,Secret 是一种用于存储敏感信息的对象,比如密码、OAuth 令牌、SSH 密钥等。使用 Secret 可以安全地管理和使用敏感数据,而不需要将其硬编码在 Pod 定义中。
Secret 对象以 base64 编码的形式存储,提供了一定程度的安全性。虽然它并不加密,但可以防止敏感信息在 YAML 文件中以明文形式暴露。另外,可以通过环境变量、卷或其他方式将 Secret 注入到容器中。而且可以更新 Secret,而不需要重启使用它的 Pod。
3.2.4.1 创建Secret
命令行创建
kubectl 创建新资源 资源类型 通用的Secret,可存储任意类型数据 Secret名称 直接创建一个键值对
# kubectl 创建新资源 资源类型 通用的Secret,可存储任意类型数据 Secret名称 直接创建一个键值对 kubectl create secret generic my-secret --from-literal=password=mysecretpassword
如果Secret是一个文件或目录,则
# 文件 kubectl create secret generic my-secret --from-file=password=my-password.txt # 目录 kubectl create secret generic my-config --from-file=config/
yaml文件创建
apiVersion: v1 kind: Secret metadata: name: my-secret type: Opaque data: password: bXlzZWNyZXRwYXNzd29yZA== # "mysecretpassword" 的 base64 编码 config1.properties: | Y29uZmlnMSA9IHZhbHVlMQ== # "cat my-password.txt | base64"的编码,使用 | 符号表示将多行文本作为一个键的值。将文件创建成Secret
3.2.4.2 查看Secret
# 查看所有 Secrets kubectl get secrets # 查看特定 Secret 的详细信息 kubectl describe secret my-secret # 查看 Secret 的 YAML 输出 kubectl get secret my-secret -o yaml # 查看 Secret 的原始数据 kubectl get secret my-secret -o jsonpath="{.data}" # 解码 Secret 数据 kubectl get secret my-secret -o jsonpath="{.data.password}" | base64 --decode # 在命名空间中查看 Secrets kubectl get secrets -n my-namespace
3.2.4.3 使用Secret
作为环境变量(Secret必须是具体的键值对)
当 Pod 启动时,Kubernetes 会根据 name 字段查找名为 my-secret 的 Secret 对象,一旦找到了 my-secret,Kubernetes 会检查该 Secret 中是否存在名为 password 的键,如果找到了,Kubernetes 将该键对应的值(经过 base64 解码)作为环境变量 MY_PASSWORD 的值。
apiVersion: v1 kind: Pod metadata: name: secret-env-example spec: containers: - name: app-container image: busybox command: ["sh", "-c", "echo Password is $MY_PASSWORD; sleep 3600"] env: - name: MY_PASSWORD valueFrom: secretKeyRef: name: my-secret key: password
作为卷挂载
apiVersion: v1 kind: Pod metadata: name: secret-volume-example spec: containers: - name: app-container image: busybox command: ["sh", "-c", "cat /etc/secret-volume/password; sleep 3600"] volumeMounts: - name: secret-volume mountPath: /etc/secret-volume volumes: - name: secret-volume secret: secretName: my-secret
3.2.4.4 更新,删除Secret
更新:可以通过 kubectl edit secret my-secret 或 kubectl apply -f secret.yaml 更新 Secret。
删除:使用 kubectl delete secret my-secret 删除 Secret。
3.2.5 ConfigMap
在 Kubernetes 中,ConfigMap 是一种用于存储非敏感的配置信息的对象,例如应用程序配置、环境变量、命令行参数等。通过使用 ConfigMap,可以将配置与应用程序代码分离,从而提高灵活性和可维护性。
ConfigMap的用法跟Secret基本一样,故本章节不做过多介绍。
3.2.5.1 创建
使用命令行
kubectl create configmap my-config --from-literal=key1=value1 --from-literal=key2=value2
使用yaml文件
apiVersion: v1 kind: ConfigMap metadata: name: my-config data: key1: value1 key2: value2
3.2.5.2 查看
#查看所有 ConfigMaps kubectl get configmaps #查看特定 ConfigMap 的详细信息 kubectl describe configmap my-config
3.2.5.3 使用
作为环境变量(必须是具体的键值对)
apiVersion: v1 kind: Pod metadata: name: configmap-env-example spec: containers: - name: app-container image: busybox command: ["sh", "-c", "echo Key1 is $KEY1; sleep 3600"] env: - name: KEY1 valueFrom: configMapKeyRef: name: my-config key: key1
作为卷挂载
apiVersion: v1 kind: Pod metadata: name: configmap-volume-example spec: containers: - name: app-container image: busybox command: ["sh", "-c", "cat /etc/config/config.properties; sleep 3600"] volumeMounts: - name: config-volume mountPath: /etc/config volumes: - name: config-volume configMap: name: my-config
3.2.5.4 更新,删除
直接使用 kubectl 更新
#使用 --from-file 或 --from-literal 创建一个新的 ConfigMap,并使用 --dry-run 和 -o yaml 生成更新的 YAML,然后使用 kubectl apply 更新现有的 ConfigMap。 kubectl create configmap my-config --from-file=new-config.properties --dry-run=client -o yaml | kubectl apply -f - #直接编辑现有的 ConfigMap kubectl edit configmap my-config
通过 YAML 文件更新
apiVersion: v1 kind: ConfigMap metadata: name: my-config data: key1: updated_value1 key2: value2
保存更改后,使用以下命令应用更新:
kubectl apply -f configmap.yaml
注:更新 ConfigMap 后,依赖该 ConfigMap 的 Pod 不会自动重启,可以手动重启 Pod 以使更改生效。
kubectl rollout restart deployment my-deployment
删除
kubectl delete configmap my-config
3.2.6 PV,PVC
Kubernetes 中的 PersistentVolume (PV) 和 PersistentVolumeClaim (PVC) 是用于管理持久化存储的核心概念。它们帮助用户在容器中持久化数据,确保数据在 Pod 生命周期之外的持久性。
PersistentVolume (PV):
- 定义:PV 是集群中的一块存储资源,通常由管理员预先配置。它代表了一个具体的存储实现,可以是网络存储、云存储或本地存储。
- 特性:PV 的生命周期独立于使用它的 Pod,即使 Pod 被删除,PV 仍然存在。PV 可以通过 YAML 文件进行配置,定义存储的类型、容量、访问模式等。
PersistentVolumeClaim (PVC):
- 定义:PVC 是用户对 PV 的请求。用户通过 PVC 指定所需的存储资源,例如存储大小和访问模式。
- 特性:PVC 可以与符合要求的 PV 自动绑定,也可以通过指定特定的 PV 进行绑定。用户只需关注他们需要的存储,而不需要了解底层存储的细节。
自动绑定:Kubernetes 控制器会自动查找符合 PVC 请求的 PV,并将其绑定到 PVC。当 PVC 被创建时,Kubernetes 会检查是否有可用的 PV 满足 PVC 的要求。如果找到匹配的 PV,Kubernetes 会将 PVC 的 spec.volumeName 字段(自动填充,yaml文件中无需设置)设置为该 PV 的名称,从而实现绑定。
注:虽然可以直接再pod里使用pv,但不推荐,这样会破坏资源的抽象和管理能力;更推荐通过pvc来使用pv。
创建pv
kubectl apply -f pv.yaml
yaml文件
apiVersion: v1 kind: PersistentVolume metadata: name: my-pv spec: capacity: storage: 5Gi # 存储容量 accessModes: - ReadWriteOnce # 访问模式 persistentVolumeReclaimPolicy: Retain # 回收策略 hostPath: # 存储类型,这里是本地存储 path: /data/pv
回收策略:
- Retain: PV 保留数据,管理员需要手动清理。
- Recycle: PV 被清理并重新标记为可用(已废弃)。
- Delete: PV 和其数据一并删除,通常与云存储服务一起使用。
pv使用云存储
apiVersion: v1 kind: PersistentVolume metadata: name: my-aws-ebs-pv spec: capacity: storage: 10Gi accessModes: - ReadWriteOnce persistentVolumeReclaimPolicy: Delete storageClassName: my-aws-ebs awsElasticBlockStore: volumeID: aws://us-west-2a/vol-12345678 # 替换为卷 ID fsType: ext4
创建pvc
kubectl apply -f pvc.yaml
yaml文件
apiVersion: v1 kind: PersistentVolumeClaim metadata: name: my-pvc spec: accessModes: - ReadWriteOnce # 访问模式 resources: requests: storage: 5Gi # 请求的存储容量
查看
kubectl get pv kubectl get pvc
在pod中使用pvc
kubectl apply -f pod.yaml
yaml文件
apiVersion: v1 kind: Pod metadata: name: my-pod spec: containers: - name: my-container image: nginx volumeMounts: - mountPath: /usr/share/nginx/html # 容器内的挂载路径 name: my-volume volumes: - name: my-volume persistentVolumeClaim: claimName: my-pvc # 绑定的 PVC 名称
3.2.7 NFS
在 Kubernetes 中,使用 NFS(网络文件系统)作为数据卷(Volume)可以实现多个 Pod 之间的数据共享。NFS 卷允许多个 Pod 读取和写入同一存储空间,非常适合需要共享数据的应用场景。
apiVersion: v1 kind: Pod metadata: name: my-nfs-pod spec: containers: - name: my-container image: nginx volumeMounts: - mountPath: /usr/share/nginx/html # 容器内挂载路径 name: my-nfs-volume volumes: - name: my-nfs-volume nfs: server: 192.168.1.100 # NFS 服务器的 IP 地址 path: /mnt/nfs_share # NFS 服务器导出的路径
3.3 NameSpace(命名空间)
在 Kubernetes 中,命名空间(Namespace) 是一种用于将集群资源分隔开来的机制。它允许多个用户或团队在同一个 Kubernetes 集群中共存,避免资源冲突和名称冲突。
使用命名空间可以将不同团队或项目的资源分开,便于管理和监控;也可以通过角色和角色绑定(RBAC)对不同命名空间中的资源进行权限控制。
默认命名空间:
- default: 主要用于没有指定命名空间的资源。
- kube-system: 用于 Kubernetes 系统组件的资源(如 kube-dns、kube-proxy 等)。
- kube-public: 允许所有用户访问的命名空间,通常用于公共资源。
- kube-node-lease: 用于节点租约的命名空间,支持节点的心跳机制。
创建
命令行:
kubectl create namespace my-namespace
yaml文件
apiVersion: v1 kind: Namespace metadata: name: my-namespace --- apiVersion: v1 kind: ResourceQuota metadata: name: my-quota namespace: my-namespace spec: hard: requests.cpu: "4" # 最大请求 CPU 总量 requests.memory: "8Gi" # 最大请求内存总量 limits.cpu: "8" # 最大限制 CPU 总量 limits.memory: "16Gi" # 最大限制内存总量 --- apiVersion: v1 kind: LimitRange metadata: name: my-limit-range namespace: my-namespace spec: limits: - default: cpu: "500m" # 默认请求的 CPU memory: "256Mi" # 默认请求的内存 defaultRequest: cpu: "250m" # 默认限制的 CPU memory: "128Mi" # 默认限制的内存 type: Container --- apiVersion: v1 kind: Pod metadata: name: my-pod namespace: my-namespace spec: containers: - name: my-container image: nginx resources: requests: cpu: "300m" # 请求的 CPU memory: "200Mi" # 请求的内存 limits: cpu: "500m" # 限制的 CPU memory: "400Mi" # 限制的内存
应用
kubectl apply -f your-file.yaml
3.4 RABC(Role-Based Access Control,基于角色访问控制)
RBAC 是 Kubernetes 中的一种权限管理机制,用于控制用户或服务账户对集群资源的访问权限。
RBAC使用rbac.authorization.k8s.io API Group 来实现授权决策,允许管理员通过 Kubernetes API 动态配置策略,要启用RBAC,需要在 apiserver 中添加参数--authorization-mode=RBAC,如果使用的kubeadm安装的集群,1.6 版本以上的都默认开启了RBAC,可以通过查看 Master 节点上 apiserver 的静态Pod定义文件:
$ cat /etc/kubernetes/manifests/kube-apiserver.yaml ... - --authorization-mode=Node,RBAC ...
如果是二进制的方式搭建的集群,添加这个参数过后,记得要重启 apiserver 服务。
基本概念:
-
Role(角色): 定义了一组权限,指定哪些操作可以在特定资源上执行。角色可以在特定命名空间中定义,也可以在整个集群范围内定义(ClusterRole)。
-
RoleBinding(角色绑定): 将角色与用户、用户组或服务账户关联,授权他们使用该角色定义的权限。
-
ClusterRole(集群角色): 类似于 Role,但作用于整个集群,而不仅仅是某个命名空间。
-
ClusterRoleBinding(集群角色绑定): 将集群角色与用户、用户组或服务账户关联,授权他们在整个集群中使用该角色定义的权限。
操作类型:
- get: 获取资源的详细信息
- list: 列出资源集合
- watch: 监视资源的变化(实时更新)
- create: 创建新资源
- update: 更新现有资源
- patch: 对现有资源进行部分更新
- delete: 删除资源
- deletecollection: 删除资源集合
- exec: 在 Pod 中执行命令(通常与容器相关)
- attach: 附加到 Pod 的容器
- portforward: 转发请求到 Pod 的端口
- proxy: 通过 API 服务器代理请求
3.4.1 用户
在 Kubernetes 中,用户是指能够与 Kubernetes API 进行交互的主体。用户可以是个人、团队或服务账户。
用户的来源:
-
静态用户: 通过证书或 kubeconfig 文件管理的用户。这些用户通常通过 Kubernetes 集群外部的身份验证机制(如 LDAP、Active Directory)进行验证。
-
服务账户(ServiceAccount): Kubernetes 为 Pod 创建的专用用户,通常用于 Pod 内部与 Kubernetes API 进行交互。服务账户由 Kubernetes 自动管理。
-
外部身份提供者: 使用 OAuth、OpenID Connect 等外部身份提供者集成,允许用户通过这些服务进行身份验证。
用户的用途:
-
权限控制: 用户通过 RBAC 可以被授权对 Kubernetes 资源执行特定操作,如查看、创建、更新或删除资源。
-
资源访问: 用户可以通过 kubectl 命令或其他工具与 Kubernetes API 交互,管理应用程序和集群资源。
-
审计和合规: 通过监控用户活动,Kubernetes 可以记录用户对资源的访问和操作,帮助实现审计和合规要求。
适用场景:
- 安全性优先: 如果安全性是首要考虑,推荐使用 X.509 证书。
- 简化管理: 如果希望简化管理,尤其是在容器化应用中,使用服务账户是一个好选择。
- 企业集成: 如果需要与现有企业身份管理系统集成,使用外部身份提供者是合适的。
3.4.2 创建用户
3.4.2.1 使用X.509 证书
生成私钥和证书签名请求
# 创建私钥haimaxy.key openssl genrsa -out haimaxy.key 2048 # 创建证书签名请求文件haimaxy.csr;要确保在-subj参数中指定用户名和组(CN表示用户名,O表示组) openssl req -new -key haimaxy.key -out haimaxy.csr -subj "/CN=haimaxy/O=youdianzhis" # 生成证书文件,设置有效期500天;使用kubeadm安装的集群,CA相关证书位于/etc/kubernetes/pki/目录下面 openssl x509 -req -in haimaxy.csr -CA /etc/kubernetes/pki/ca.crt -CAkey /etc/kubernetes/pki/ca.key -CAcreateserial -out haimaxy.crt -days 500 # 创建新的用户凭证 kubectl config set-credentials haimaxy --client-certificate=haimaxy.crt --client-key=haimaxy.key # 设置上下文,以便使用此凭证连接到特定集群 kubectl config set-context haimaxy-context --cluster=kubernetes --namespace=kube-system --user=haimaxy
3.4.2.2 使用服务账户
# 创建账户
kubectl create serviceaccount my-service-account
3.4.2.3 使用外部身份提供者
配置 API 服务器: 在 API 服务器启动时,添加以下参数:
--oidc-issuer-url=https://<your-issuer> --oidc-client-id=<your-client-id> --oidc-client-secret=<your-client-secret>
在外部系统中管理用户: 使用外部身份提供者(如 LDAP、OAuth)管理用户和权限。
3.4.3 角色
3.4.3.1 rules规则
在 Kubernetes 的 RBAC(基于角色的访问控制)中,rules 是定义权限的核心部分。每个角色(Role)或集群角色(ClusterRole)都包含一组规则,描述了可以对哪些资源执行哪些操作。
rules包含字段:
- apiGroups:描述资源所属的 API 组。可以是空字符串 "",表示核心 API 组(如 Pod、Service 等)。
- resources:指定可以访问的资源类型。资源可以是单个资源或资源的集合。
- verbs:定义用户可以对指定资源执行的操作。
- resourceNames:限制可以操作的资源名称。只有在指定了资源名称时,用户才能执行指定操作。
示例
apiVersion: rbac.authorization.k8s.io/v1 kind: Role metadata: name: pod-editor namespace: default rules: - apiGroups: [""] # 核心 API 组 resources: ["pods"] # 访问 pods 资源 verbs: ["get", "list", "create", "update", "delete"] # 允许的操作 - apiGroups: ["apps"] # apps API 组 resources: ["deployments"] # 访问 deployments 资源 verbs: ["get", "list", "create", "update"] # 允许的操作
3.4.3.2 创建角色
创建一个名为 pod-reader 的角色,允许对 default 命名空间中的 Pod 执行 get 和 list 操作
apiVersion: rbac.authorization.k8s.io/v1 kind: Role metadata: name: pod-reader namespace: default # 指定角色的命名空间 rules: - apiGroups: [""] resources: ["pods"] verbs: ["get", "list"]
创建一个名为 pod-reader-cluster 的集群角色,允许对所有命名空间中的 Pod 执行 get 和 list 操作
apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: name: pod-reader-cluster # 集群角色名称 rules: - apiGroups: [""] resources: ["pods"] verbs: ["get", "list"]
查看
# 查看角色 kubectl get roles -n default # 查看集群角色 kubectl get clusterroles
3.4.4 角色绑定
角色绑定
apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: pod-reader-binding namespace: default subjects: - kind: User name: my-user # 绑定的用户名称 apiGroup: rbac.authorization.k8s.io roleRef: kind: Role name: pod-reader # 角色名称 apiGroup: rbac.authorization.k8s.io
集群角色绑定
apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: name: pod-reader-cluster-binding subjects: - kind: User name: my-user # 绑定的用户名称 apiGroup: rbac.authorization.k8s.io roleRef: kind: ClusterRole name: pod-reader-cluster # 集群角色名称 apiGroup: rbac.authorization.k8s.io
查看
# 查看特定命名空间中的角色绑定 kubectl get rolebindings -n <namespace> # 查看所有集群角色绑定 kubectl get clusterrolebindings # 查看角色绑定详情 kubectl describe rolebinding <rolebinding-name> -n <namespace> # 查看集群角色绑定详情 kubectl describe clusterrolebinding <clusterrolebinding-name>
3.4.5 创建角色,绑定用户,运行pod示例
用户需先创建,yaml文件如下
apiVersion: rbac.authorization.k8s.io/v1 kind: Role metadata: name: pod-manager namespace: default # 指定角色的命名空间 rules: - apiGroups: [""] resources: ["pods"] verbs: ["get", "list", "create", "delete", "update"] # 允许的操作 --- apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: pod-manager-binding namespace: default # 角色绑定的命名空间 subjects: - kind: User name: my-user # 绑定的用户名称 apiGroup: rbac.authorization.k8s.io roleRef: kind: Role name: pod-manager # 角色名称 apiGroup: rbac.authorization.k8s.io --- apiVersion: v1 kind: Pod metadata: name: my-limited-pod namespace: default # Pod 所在命名空间 spec: containers: - name: my-container image: nginx # 使用 Nginx 镜像 ports: - containerPort: 80 resources: limits: # 设置资源限制 memory: "128Mi" # 限制内存使用 cpu: "500m" # 限制 CPU 使用 requests: memory: "64Mi" # 请求的内存 cpu: "250m" # 请求的 CPU
运行
kubectl apply -f role-binding-and-limited-pod.yaml
查看
kubectl get pods -n default kubectl describe pod my-limited-pod -n default
3.5 Service
在 Kubernetes 中,Service 是一个重要的资源,用于定义一组 Pod 的访问策略。通过代理模式提供稳定的网络访问,允许 Pods 之间的通信和外部访问。Service 充当一个抽象层,管理 Pods 的访问方式,确保流量的负载均衡和高可用性。
Service有且只有一个算法 RB 轮询,且只提供4层负载均衡能力,根据源 IP 和目标 IP 以及端口来决定流量的转发;不能按主机名、路径或其他 HTTP 头信息进行流量分发,限制了更复杂的应用场景(如根据请求内容将流量路由到不同的服务)。
3.5.1 工作原理
-
虚拟 IP 地址:
- Service 分配一个虚拟 IP 地址(Cluster IP),这个 IP 地址用于访问与 Service 关联的 Pods。用户或其他 Pods 通过这个 IP 地址来访问服务,而不需要关注后端 Pods 的具体 IP。
-
选择器:
- Service 使用标签选择器(Selector)来确定哪些 Pods 属于该 Service。选择器将流量路由到符合条件的 Pods。
-
负载均衡:
- 当请求到达 Service 的虚拟 IP 地址时,Kubernetes 会使用 kube-proxy 组件来将流量分配到后端 Pods。kube-proxy 可以使用不同的代理模式(如 iptables、ipvs 等)来实现负载均衡。
-
代理模式:
- iptables: 使用 Linux 内核的 iptables 规则,将流量转发到后端 Pods。
- ipvs: 使用 IP Virtual Server,提供更高效的负载均衡和更复杂的调度策略。
- 用户空间: 在早期版本中使用的模式,但现在较少使用。
3.5.2 类型
ClusterIP
- 描述: 默认类型,Service 只在集群内部可访问。外部无法直接访问。
- 适用场景: 适用于内部通信的服务。
apiVersion: v1 kind: Service metadata: name: my-clusterip-service # Service 名称 spec: type: ClusterIP selector: app: myapp # 选择器,用于选择与之关联的 Pods ports: - port: 80 # Service 的端口 targetPort: 8080 # 转发到 Pods 的端口
NodePort
- 描述: Service 在每个节点上分配一个端口,外部可以通过
<NodeIP>:<NodePort>访问。 - 适用场景: 适用于需要外部访问的服务。
apiVersion: v1 kind: Service metadata: name: my-nodeport-service spec: type: NodePort selector: app: myapp ports: - port: 80 targetPort: 8080 nodePort: 30000 # 指定 NodePort,范围是 30000-32767
LoadBalancer
- 描述: 在支持的云提供商中,Service 会自动创建一个外部负载均衡器,并分配一个公共 IP 地址。
- 适用场景: 适用于需要高可用和公共访问的服务。
apiVersion: v1 kind: Service metadata: name: my-loadbalancer-service spec: type: LoadBalancer selector: app: myapp ports: - port: 80 targetPort: 8080
Headless Service
- 描述:
clusterIP: None,不分配虚拟 IP 地址,直接返回与 Pods 相关的 IP 地址。 - 适用场景: 适用于需要直接访问特定 Pods 的场景,如 StatefulSet。
apiVersion: v1 kind: Service metadata: name: my-headless-service spec: clusterIP: None # 设置为 None,表示这是一个无头服务 selector: app: myapp ports: - port: 80 targetPort: 8080
3.5.3 sevice与Ingress的区别
| Service | Ingress | |
|---|---|---|
| 主要用途 | 主要用于在集群内部提供稳定的网络访问 | 主要用于管理来自外部的 HTTP(S) 流量,并将其路由到集群内部的 Service |
| 流量管理 | 将流量负载均衡地分发到其选择的 Pods 上,确保高可用性 | 根据请求的主机名和路径进行复杂的路由,并支持 SSL/TLS 终止 |
| 工作方式 | 提供四种不同的工作类型 | 通过 Ingress Controller 处理外部请求,并将其根据定义的规则转发到相应的 Service |
| 负载均衡 | 只提供 L4 负载均衡,基于 IP 和端口进行流量分发 | 提供 L7 负载均衡,支持基于 HTTP 请求内容的路由 |
| 适用场景 | 适用于内部组件之间的通信或简单的外部访问 | 适用于需要复杂路由策略的场景,如 Web 应用和微服务架构 |
3.6 Ingress
在Kubernetes集群中,Ingress作为集群内服务对外暴露的访问接入点,几乎承载着集群内服务访问的所有流量。Ingress是Kubernetes中的一个资源对象,用来管理集群外部访问集群内部服务的方式。可以通过Ingress资源来配置不同的转发规则,从而实现根据不同的规则设置访问集群内不同的Service所对应的后端Pod。
Ingress资源仅支持配置HTTP流量的规则,无法配置一些高级特性,例如负载均衡的算法、Sessions Affinity等,这些高级特性都需要在Ingress Controller中进行配置。
主要功能
-
基于请求的路由:Ingress 可以根据请求的主机名和路径将流量路由到不同的服务。例如,可以将
/api路径的请求发送到一个服务,而将/web路径的请求发送到另一个服务。 -
SSL/TLS 终止:Ingress 可以处理 HTTPS 流量,支持 SSL/TLS 终止。这意味着可以在 Ingress 级别处理加密,而不需要在后端服务中处理。
-
负载均衡:Ingress 提供 L7 负载均衡能力,可以将流量分配到后端服务的多个实例。
-
外部访问:通过 Ingress,可以轻松地将外部流量路由到集群内的多个服务,而不必为每个服务单独暴露端口。
组件
Ingress 通常由两个主要组件组成:
-
Ingress 资源:定义了请求路由规则、路径和后端服务。
-
Ingress Controller:负责处理 Ingress 资源中的路由规则。Ingress Controller 可以是 NGINX、Traefik、HAProxy 等,具体选择取决于需求和环境。
3.6.1 实例
实例场景
- API 服务: 运行在
my-api-service上,监听端口 80。 - Web 服务: 运行在
my-web-service上,监听端口 80。 - 主机名: 使用
myapp.example.com来访问应用。
Ingress 配置
apiVersion: networking.k8s.io/v1 kind: Ingress metadata: name: my-ingress # Ingress 的名称,用于标识这个资源 annotations: # 用于配置 Ingress Controller 的特定行为 nginx.ingress.kubernetes.io/rewrite-target: /$2 # NGINX 注解,重写目标 spec: rules: # 定义路由规则 - host: myapp.example.com # 指定主机名,只有匹配该主机名的请求会被处理 http: # HTTP 路由规则 paths: # 定义多个路径及其对应的后端服务 - path: /api(/|$)(.*) # 匹配以 /api 开头的路径 pathType: Prefix # 指定路径匹配类型,这里使用 Prefix 表示匹配以指定路径开头的所有请求 backend: # 定义后端服务 service: # 指定目标服务的名称和端口 name: my-api-service # 路由到的 API 服务名称 port: number: 80 # 后端服务的入向端口 - path: /web(/|$)(.*) # 匹配以 /web 开头的路径 pathType: Prefix backend: service: name: my-web-service # 路由到的 Web 服务 port: number: 80
效果
- 请求: http://myapp.example.com/api/users 将被路由到 my-api-service
- 请求: http://myapp.example.com/web/home 将被路由到 my-web-service
pathType类型
- Prefix:匹配以指定路径开头的所有请求
- Exact:精确匹配指定路径,只有完全匹配的请求才会被路由
- ImplementationSpecific:由特定的 Ingress Controller 实现,匹配的行为依赖于具体的实现
3.6.2 SSL/TLS 配置
在 Kubernetes 中,配置 SSL/TLS 是指为 Ingress 资源设置加密,以便安全地处理 HTTP(S) 流量。SSL(Secure Sockets Layer)和 TLS(Transport Layer Security)是用于加密互联网通信的协议,使得数据在传输过程中保持安全,防止被窃听或篡改。
证书与私钥可以通过CA或者自签名证书(开发测试环境)获取,获取后创建 Kubernetes Secret:
kubectl create secret tls my-tls-secret --cert=path/to/tls.crt --key=path/to/tls.key
包含 SSL/TLS 配置的 Ingress 示例
apiVersion: networking.k8s.io/v1 kind: Ingress metadata: name: my-secure-ingress spec: tls: - hosts: - myapp.example.com # 指定需要使用 SSL 的主机名 secretName: my-tls-secret # 之前创建的 Secret 名称 rules: - host: myapp.example.com http: paths: - path: / pathType: Prefix backend: service: name: my-web-service port: number: 80
3.7 StatefulSet(有状态应用)
StatefulSet 是 Kubernetes 中用于管理有状态应用的控制器。它提供了一种机制,用于部署和管理有状态服务,确保每个 Pod 在生命周期内具有唯一的、稳定的身份和存储。
主要特点
-
稳定的网络身份:每个 StatefulSet 中的 Pod 都有一个唯一的标识符(如
myapp-0,myapp-1),且其网络标识符在 Pod 重启后保持不变。这使得应用能够依赖于稳定的网络地址。 -
持久化存储:StatefulSet 可以与持久卷(Persistent Volume)结合使用,为每个 Pod 提供稳定的存储。即使 Pod 被重建,存储仍然保持不变。
-
顺序部署和缩放:Pods 的创建、删除和更新是按顺序进行的。Kubernetes 会确保 Pods 以特定的顺序启动和终止,这对于某些有状态应用(如数据库)至关重要。
-
有序的滚动更新:StatefulSet 支持有序滚动更新,确保在更新过程中,Pods 按照顺序逐个更新,直到所有 Pods 更新完成。
使用场景
StatefulSet 适用于需要保持状态的应用,例如:
- 数据库(如 MySQL、PostgreSQL)
- 分布式文件系统(如 Ceph、HDFS)
- 消息队列(如 Kafka、RabbitMQ)
另外,StatefulSet 通常与 Headless Service 一起使用,以便更好地管理有状态应用。
主要原因:
-
稳定的 DNS 名称:每个 Pod 在 StatefulSet 中都有一个固定的 DNS 名称,格式为
<statefulset-name>-<index>.<service-name>,这使得其他 Pods 可以通过 DNS 直接访问特定的 Pod。 -
直接 Pod 通信:Headless Service 允许 Pods 之间直接通信,而不经过负载均衡。这对于需要直接访问特定实例的有状态应用(如数据库集群)非常重要。
-
有序性:StatefulSet 中的 Pods 按照特定顺序启动和停止,使用 Headless Service 可以确保其他组件能够以可预测的方式访问这些 Pods。
-
应用场景:适用于需要 Pod 之间直接交互的场景,例如分布式数据库(如 Cassandra、ZooKeeper)或其他有状态服务。
示例
apiVersion: v1 kind: Service metadata: name: my-service # Headless Service 的名称 spec: clusterIP: None # 设置为 None,表示这是一个无头服务 selector: app: myapp # 选择器用于匹配 Pods ports: - port: 80 targetPort: 8080 # 将流量转发到容器的 8080 端口 --- apiVersion: apps/v1 kind: StatefulSet metadata: name: my-statefulset # StatefulSet 的名称 spec: serviceName: "my-service" # 关联的 Headless Service 名称 replicas: 3 # Pod 副本数 selector: matchLabels: app: myapp # 标签选择器 template: metadata: labels: app: myapp # Pod 模板中的标签 spec: containers: - name: myapp-container image: myapp-image # 容器镜像 ports: - containerPort: 8080 # 容器监听的端口 volumeMounts: # 持久卷挂载 - name: myapp-storage mountPath: /data # 持久卷挂载路径 volumeClaimTemplates: # 为每个 Pod 创建持久卷声明 - metadata: name: myapp-storage # PVC 的名称 spec: accessModes: ["ReadWriteOnce"] # 访问模式 resources: requests: storage: 1Gi # 请求的存储大小
创建出来的三个pod名称为 my-statefulset-0、my-statefulset-1 、 my-statefulset-2 ,可以通过 http://my-statefulset-0.my-service 直接访问pod。
3.8 控制器
控制器是一种循环控制系统,它定期检查集群状态,并根据需要做出调整。控制器通常运行在 Kubernetes API 服务器之上,负责监控特定资源的状态。
工作原理
每个控制器都遵循类似的工作流程:
- 获取状态: 定期从 Kubernetes API 服务器获取当前状态。
- 对比状态: 将当前状态与期望状态进行对比。
- 采取行动: 如果发现不一致,控制器会采取必要措施来修正实际状态,通常通过创建、更新或删除资源。
- 循环进行: 控制器持续重复上述步骤,以确保状态一致性。
常见的控制器
| 控制器 | 描述 |
|---|---|
| ReplicaSet | 确保指定数量的 Pod 副本在运行。如果某些 Pod 失败或被删除,ReplicaSet 控制器会创建新的 Pod 以维持期望的副本数。 |
| Deployment | 管理 Pod 的声明式更新,确保应用的无缝升级和回滚。Deployment 控制器会创建和管理 ReplicaSet。 |
| StatefulSet | 管理有状态应用程序的部署和扩展,确保 Pod 的顺序性和稳定性。StatefulSet 提供持久化存储和稳定的网络身份。 |
| DaemonSet | 确保在集群中每个节点上运行一个 Pod 副本,适用于需要在每个节点上进行资源监控或日志收集的场景。 |
| Job | 管理一次性任务,确保指定数量的 Pod 成功完成其任务后自动终止。适用于批处理作业。 |
| CronJob | 定期运行 Job,支持定时调度任务,类似于 Unix/Linux 的 cron 服务。 |
此外,Kubernetes 允许用户创建自定义控制器,以满足特定需求。这通常涉及到:
- 使用 Kubernetes 客户端库: 开发自定义控制器,使用 Kubernetes API 进行资源管理。
- 实现自定义逻辑: 根据业务需求实现特定的状态管理和资源控制逻辑。
3.8.1 ReplicaSet
ReplicaSet 是 Kubernetes 中的一种控制器,用于管理多个相同的 Pod 副本,以确保在任何时候都有指定数量的 Pod 在运行。它是 Kubernetes 中扩展性和高可用性的重要组成部分。
主要功能:
-
确保副本数量:
ReplicaSet确保指定数量的 Pod 副本在运行。如果某个 Pod 因故障而停止,ReplicaSet会自动创建新的 Pod 以替代它。 -
负载均衡:通过管理多个 Pod,
ReplicaSet可以帮助分散流量,提高应用程序的可用性和响应能力。 -
声明式管理:用户可以通过定义所需状态(例如,Pod 的副本数)来管理应用,Kubernetes 将自动调整实际状态以匹配所需状态。
apiVersion: apps/v1 kind: ReplicaSet # 表示资源的类型,这里是 ReplicaSet metadata: name: my-replicaset # ReplicaSet 的名称 spec: replicas: 3 # 设置所需的副本数 selector: # 用于选择哪些 Pod 属于这个 ReplicaSet matchLabels: # 标签选择器 app: my-app # 只有具有 app: my-app 标签的 Pod 会被该 ReplicaSet 管理 template: metadata: # metadata 中的 labels 必须与 selector 中的标签匹配,以确保 ReplicaSet 能正确管理这些 Pod labels: app: my-app # Pod 的标签 spec: containers: - name: my-container image: my-image:latest # 指定容器镜像 ports: - containerPort: 80
相关命令
# 创建 kubectl apply -f my-replicaset.yaml # 查看当前的 ReplicaSet 状态 kubectl get rs # 查看由 ReplicaSet 管理的 Pod kubectl get pods -l app=my-app # 更新 ReplicaSet 的副本数,会自动创建/删除Pod kubectl scale rs my-replicaset --replicas=5 # 删除 ReplicaSet kubectl delete rs my-replicaset
注:虽然 ReplicaSet 可以独立使用,但通常建议使用 Deployment 来管理 ReplicaSet,因为 Deployment 提供了更高级的功能,如滚动更新和回滚。
3.8.2 Deployment
Deployment 是 Kubernetes 中用于管理应用程序的高层次抽象,它提供了一种声明式的方法来定义和更新应用程序的 Pod 及其副本。Deployment 可以自动管理应用的滚动更新、回滚和扩展等功能,是 Kubernetes 中最常用的资源类型之一。
创建 Deployment 时,Kubernetes 会根据在 Deployment 中指定的 Pod 模板和副本数自动生成 ReplicaSet,Deployment 对 Pod 的所有操作都是通过 ReplicaSe来执行。
主要功能:
-
声明式管理:通过定义所需的状态(如 Pod 副本数、容器镜像等),Kubernetes 会自动调整实际状态以匹配所需状态。
-
滚动更新:可以无缝地更新应用程序,Kubernetes 会逐步替换旧版本 Pod 为新版本,确保在更新过程中保持可用性。
-
回滚功能:如果更新后的应用出现问题,可以快速回滚到先前的版本。
-
自我修复:Deployment 会监控 ReplicaSet 的状态,确保所需数量的 Pod 始终在运行。如果某个 Pod 失败,ReplicaSet 会自动创建新 Pod 以替代它。
3.8.2.1 创建
使用yaml创建
kubectl apply -f nginx-deployment.yaml
yaml文件内容
apiVersion: apps/v1 kind: Deployment # 资源类型,这里是 Deployment metadata: name: nginx-deployment spec: replicas: 3 # 设置所需的副本数 selector: matchLabels: app: nginx # 用于选择 Pod 的标签 template: metadata: labels: app: nginx # Pod 的标签 spec: containers: - name: nginx image: nginx:latest # 指定容器镜像 ports: - containerPort: 80 # 容器监听的端口
查看
# 查看 Deployment 状态 kubectl get deployments # 查看由 Deployment 管理的 Pod kubectl get pods -l app=nginx
2.8.2.2 更新
2.8.2.2.1 更新pod数量
- 增加副本数:通过RS创建新的Pod实例
- 减少副本数:通过RS删除多余的Pod实例
通过命令行修改
# 修改deployment类型,名称nginx-deployment的副本数为5 kubectl scale deployment/nginx-deployment --replicas=5
通过yaml文件修改:先修改完yaml文件,然后执行命令
kubectl apply -f nginx-deployment.yaml
监控状态
kubectl rollout status deployment/nginx-deployment
kubectl get pods -l app=nginx
2.8.2.2.2 更新配置
当更新配置(如更改容器镜像版本或其他配置参数)时,Kubernetes 会自动创建一个新的 ReplicaSet,由这个RS逐步创建新的Pod,并逐步将流量从旧的 Pod 切换到新的 Pod,最后旧的RS及Pod实例都会被替换。
使用命令行
# 替换nginx的版本 kubectl set image deployment/nginx-deployment nginx=nginx:1.21.6
通过yaml文件修改:先修改完yaml文件,然后执行命令
kubectl apply -f nginx-deployment.yaml
监控状态
kubectl rollout status deployment/nginx-deployment
kubectl get pods -l app=nginx
2.8.2.3 回滚
Kubernetes 会自动维护 Deployment 的历史版本信息。每次更新 Deployment 时,Kubernetes 会记录当前的状态,以便在需要时进行回滚。
回滚时也会创建一个新的 ReplicaSet,该 ReplicaSet 会基于选择的历史版本的 Pod 模板,然后旧的 ReplicaSet 会逐步被替换,Kubernetes 会按滚动更新的方式,逐步将流量切换到新的 Pod。
查看历史版本
kubectl rollout history deployment/nginx-deployment
回滚到上一个版本
kubectl rollout undo deployment/nginx-deployment
回滚到指定版本
kubectl rollout undo deployment/nginx-deployment --to-revision=2
3.8.3 DaemonSet
DaemonSet 是 Kubernetes 中的一种控制器,用于确保在集群中的每个节点上都运行一个 Pod 实例。它特别适合于需要在每个节点上运行的服务,例如日志收集、监控代理、网络插件等。
当有新的节点加入 Kubernetes 集群后,该 Pod 会自动地在新节点上被创建出来,而当旧节点被删除后,它上面的 Pod 也相应地会被回收掉,结合nodeSelector、affinity 和 tolerations 等机制可以选择性地在特定节点上运行 DaemonSet。
示例
apiVersion: apps/v1 kind: DaemonSet metadata: name: nginx-daemonset spec: selector: matchLabels: app: nginx template: metadata: labels: app: nginx spec: containers: - name: nginx image: nginx:latest ports: - containerPort: 80
创建
kubectl apply -f nginx-daemonset.yaml
查看
kubectl get daemonsets
删除
kubectl delete daemonset nginx-daemonset
3.8.4 Job
在 Kubernetes 中,Job 是一种用于管理一次性任务的控制器。它确保指定数量的 Pod 成功地终止,使得适合于处理批处理作业、数据处理、定时任务等场景。
特点:
- 一次性任务:Job 用于处理需要一次性执行的任务,而不是长期运行的服务
- 成功终止:Job 会确保指定数量的 Pod 成功完成并终止。如果 Pod 失败,Kubernetes 会自动重启并重新尝试,直到达到成功的要求
- 并发控制:可以设置并发策略,控制同时运行的 Pod 数量
示例
apiVersion: batch/v1 kind: Job metadata: name: example-job spec: completions: 1 # 完成的 Pod 数量 parallelism: 1 # 并发运行的 Pod 数量 template: spec: containers: - name: example-container image: example-image command: ["echo", "Hello, Kubernetes!"] restartPolicy: OnFailure # 失败时重启
相关命令
# 查看 kubectl get jobs # 查看 Job 创建的 Pod kubectl get pods --selector=job-name=example-job # 删除 kubectl delete job example-job
3.8.5 CronJob
在 Kubernetes 中,CronJob 是一种用于定期执行任务的控制器,类似于 Linux 的 cron 作业。它允许用户在指定的时间间隔内自动创建和管理 Job,非常适合于定时任务和周期性处理。
特点:
- 定时任务:CronJob 可以根据预定的时间表运行 Job,如每日、每周或每小时等。
- 自动创建 Job:CronJob 会根据设定的时间表自动创建 Job,并确保在指定时间运行。
- 并发控制:可以设置并发策略,控制同时运行的 Job 数量。
使用场景:
- 数据备份:定期备份数据库或文件
- 报告生成:定期生成并发送报告
- 清理任务:定期清理过期的资源或数据
示例
apiVersion: batch/v1 kind: CronJob metadata: name: hello-cronjob spec: schedule: "*/1 * * * *" # 每分钟执行 successfulJobsHistoryLimit: 3 # 保留成功执行的 Job 的数量 failedJobsHistoryLimit: 1 # 保留失败执行的 Job 的数量 jobTemplate: spec: parallelism: 1 # 同时运行的 Job 数量 completions: 1 # 需要成功完成的 Job 数量 template: spec: containers: - name: hello image: busybox command: ["echo", "Hello, Kubernetes!"] restartPolicy: OnFailure # 失败时重启
相关命令
# 创建 kubectl apply -f hello-cronjob.yaml # 查看 kubectl get cronjobs # 查看由 CronJob 创建的 Job kubectl get jobs # 删除 kubectl delete cronjob example-cronjob

 浙公网安备 33010602011771号
浙公网安备 33010602011771号