
Redis--主从,哨兵,cluster模式介绍
redis提供了三种模式来构建高性能、高可用性和可扩展性的数据存储集群,分别是主从复制模式(Master-Slave Replication),哨兵模式(Sentinel Mode),集群模式(Cluster Mode)。
| 特性/配置 | 主从 | 哨兵 | cluster |
| 主要目的 | 数据备份与读写分离 | 高可用性与故障自动切换 | 高并发与数据分散处理 |
| 架构 | 一主多从 | 监控主从 | 多主多从,数据分片 |
| 数据复制 | 主节点到从节点 | 监控并管理主从复制 | 每个主节点管理自己的数据集 |
| 故障转移机制 | 手动 | 自动故障转移 | 自动处理节点故障 |
| 适用场景 | 增加读取性能和数据冗余备份 | 关键应用的高可用性 | 大规模应用的高性能需求 |
一、主从复制模式(Master-Slave Replication)
Redis的主从复制是一种数据复制机制,通过将主节点的数据复制到从节点上,实现数据的冗余备份和读取性能的提升。
- 主节点(Master):主节点是数据的源头,负责处理所有的写操作(包括写入、更新和删除)。主节点将写操作记录在自己的命令日志(command log)中,并将这些命令发送给从节点进行复制。
- 从节点(Slave):从节点是主节点的副本,负责处理读操作。从节点通过与主节点进行数据同步,复制主节点的命令日志并执行,以保持与主节点的数据一致性。
1.1 同步过程
-
快照同步(Snapshot Sync):
- 初始同步:当从节点刚刚被配置为主节点的从节点时,它会发起一次完整的初始同步。主节点会执行一个后台进程,将自己的数据生成快照文件,并发送给从节点。从节点接收到快照文件后,将其加载到自己的内存中,成为一个与主节点数据完全一致的副本。
- 增量同步:在初始同步完成后,主节点会将自己的写操作记录在命令日志中,并将这些命令发送给从节点。从节点接收到命令日志后,会按照顺序执行这些命令,保持与主节点的数据一致性。
-
命令传播(Command Propagation):
- 主节点将写操作命令发送给从节点。这些命令以累计的方式发送,从而保证从节点按照正确的顺序执行命令,保持与主节点的数据一致。
- 从节点接收到命令后,会先将命令记录在自己的命令缓冲区(command buffer)中,然后再按照顺序执行这些命令。
-
追赶主节点(Catching Up):
- 如果从节点与主节点的连接中断,从节点会尝试重新连接主节点,并请求从上次同步中断的位置继续进行同步。
- 当从节点重新连接到主节点后,主节点会将断点位置之后的命令发送给从节点,使其追赶主节点的数据更新。
-
读写分离:
- 主节点负责写操作,从节点负责读操作。当客户端发起读请求时,可以选择连接到从节点进行读取,从而减轻主节点的负载,并提高整体的读取性能。
主节点发送快照文件,从节点执行命令期间(初始同步期间),主节点有写入的话,会如何?
主节点会将这些写入操作记录在自己的命令日志(command log)中,同时按照正常的处理流程执行这些写入操作,然后等初始同步完成,再将这些命令发送给从节点。这意味着在初始同步期间,主节点会同时进行快照同步和命令传播两个过程。
需要注意的是,在初始同步期间,从节点无法立即获取主节点的最新写入操作。只有在初始同步完成后,从节点才能开始进行增量同步,追赶主节点的更新。因此,在初始同步期间,从节点的数据可能不是最新的,但它会通过增量同步尽快追赶主节点的数据更新。
主节点直接将写操作命令发送给从节点执行吗?
主节点通过发送复制命令(replication command)或发送复制流(replication stream)的方式将数据传输给从节点。
-
复制命令(Replication Commands):主节点将写操作命令封装成复制命令,然后通过网络将该命令发送给从节点。从节点接收到复制命令后,解析命令并执行,以使从节点的数据与主节点保持一致。
-
复制流(Replication Stream):自Redis 6.0版本起,Redis引入了新的复制机制,称为复制流。主节点将写操作命令打包成复制流,然后通过网络将复制流传输给从节点。从节点接收到复制流后,解析流中的命令并执行,以实现从节点的数据更新。
主节点是先执行写操作,再将写操作命令发送给从节点?
是否先执行写操作取决于redis的同步复制策略,分为同步复制和异步复制。
在同步复制中,主节点在执行写操作之前会先发送命令给从节点,然后等待至少一个从节点确认接收到该命令后才继续执行。
在异步复制中,主节点接收到写操作后,通常会先执行该命令,然后再将命令发送给从节点。
1.2 复制模式
当涉及到Redis主从复制时,有两种常见的复制模式:同步复制和异步复制。
-
同步复制(Synchronous Replication):
- 工作原理:在同步复制模式下,主节点在执行写操作之前会等待至少一个从节点确认接收到该命令后才继续执行。主节点会将写操作命令发送给从节点,并等待从节点的回复确认。
- 数据一致性:同步复制保证主节点和从节点的数据完全一致,因为主节点会等待从节点确认后才继续执行。这意味着在同步复制模式下,从节点的数据与主节点的数据保持一致。
- 优点:
- 数据一致性:主节点和从节点之间的数据是完全一致的,不会出现数据丢失或不一致的情况。
- 缺点:
- 性能影响:主节点在等待从节点的确认期间会有一定的延迟,可能会影响主节点的性能和响应时间。
- 容错性:如果等待确认的从节点无法及时响应,主节点的写操作将被阻塞,这可能会导致主节点的可用性下降。
-
异步复制(Asynchronous Replication):
- 工作原理:在异步复制模式下,主节点将写操作命令发送给从节点,但不等待从节点的确认。主节点发送命令后即可继续处理其他命令,不会阻塞在复制过程上。
- 数据一致性:异步复制下,从节点的数据可能会有一定的延迟,因为主节点不会等待从节点的确认。从节点会尽快按顺序执行接收到的命令,但无法保证与主节点实时一致。
- 优点:
- 性能和响应时间:主节点不需要等待从节点的确认,因此可以获得更好的性能和响应时间。
- 容错性:即使从节点无法及时响应或发生故障,主节点的写操作不会受到阻塞或影响。
- 缺点:
- 数据一致性:从节点的数据可能会有一定的延迟,与主节点的数据不是实时一致的。
- 数据丢失:如果从节点发生故障或延迟严重,写操作可能会在从节点上丢失。
选择复制模式:修改配置文件后重启redis生效
vim redis.conf #异步复制,默认 replica-write-transmitting no #同步复制 replica-write-transmitting yes
命令行动态设置
CONFIG SET replica-write-transmitting no
1.2.1 异步复制下如何减少数据丢失
因为性能的原因,使用redis主从时,大多是选择异步复制的方式(哨兵模式也默认使用这种方式),即主节点将写操作命令发送给从节点,但不等待从节点的确认,这也是官方默认的方式,但这会带来数据丢失的风险。
比如主节点执行写操作后,将写操作发送给从节点时,主节点异常故障,从节点未收到该写操作命令,在主节点恢复后,该数据将丢失;或者主从之间通信有问题,从节点一直为同步,但主节点依旧不断写入,当主节点异常重启后,数据丢失。
解决方案有两个:
1、数据持久化,将数据同步到磁盘上,在重启后读取磁盘数据,详见:https://www.cnblogs.com/Xinenhui/p/18129667
2、设置参数,规定同步的策略:
- min-replicas-to-write:设置从节点最小可用数,从节点小于这个数时,主节点将不再接受写入请求,0为不限制;redis5.0版本之前名称为min-slaves-to-write
- min-replicas-max-lag:设置主节点收到ping回复的秒数,主节点每秒ping一次从节点,需收到从节点回复,当超时为收到时,则认为该从节点不可用,当可用从节点低于min-replicas-to-write设置的值时,主节点停止写入请求;redis5.0版本之前名称为min-replicas-to-write
min-replicas-to-write 1 min-replicas-max-lag 10
注:redis各版本参数变更:https://docs.aws.amazon.com/zh_cn/AmazonElastiCache/latest/red-ug/ParameterGroups.Redis.html#ParameterGroups.Redis.7
1.3 主从模式集群搭建
redis下载安装可看这个:https://www.cnblogs.com/Xinenhui/p/18112893
主节点配置:
bind bind 0.0.0.0 -::1 port 6379 #关闭保护模式,要是配置里没有指定bind和密码,开启该参数后,redis只会本地进行访问 protected-mode no #日志文件 logfile "/home/redis-7.2.4/logs/redis.log" #启用守护进程 daemonize yes
从节点配置:
bind 0.0.0.1 -::1 port 6379 protected-mode no #设置主节点ip,端口信息,也可用replicaof(redis5.0版本后推荐使用) slaveof 10.xx.xx.252 6379 #如果主节点使用了密码,那么从节点也要添加密码配置 #masterauth xxx logfile "/home/redis-7.2.4/logs/redis.log" daemonize yes #从节点只读 slave-read-only yes
启动服务后,连接redis,查看状态
主节点:
[root@test1 redis-7.2.4]# redis-cli -h 10.xx.xx.252 -p 6379 10.xx.xx.252:6379> INFO replication # Replication role:master connected_slaves:1 slave0:ip=10.xx.xx.221,port=6379,state=online,offset=266,lag=1 master_failover_state:no-failover master_replid:bdb2cf87afec3d2c9d22b9b104bfaf9bfb365633 master_replid2:0000000000000000000000000000000000000000 master_repl_offset:266 second_repl_offset:-1 repl_backlog_active:1 repl_backlog_size:1048576 repl_backlog_first_byte_offset:1 repl_backlog_histlen:266 10.xx.xx.252:6379>
从节点:
[root@test2 ~]# redis-cli -h 10.xx.xx.221 -p 6379 10.xx.xx.221:6379> INFO replication # Replication role:slave master_host:10.xx.xx.252 master_port:6379 master_link_status:up master_last_io_seconds_ago:0 master_sync_in_progress:0 slave_read_repl_offset:154 slave_repl_offset:154 slave_priority:100 slave_read_only:1 replica_announced:1 connected_slaves:0 master_failover_state:no-failover master_replid:bdb2cf87afec3d2c9d22b9b104bfaf9bfb365633 master_replid2:0000000000000000000000000000000000000000 master_repl_offset:154 second_repl_offset:-1 repl_backlog_active:1 repl_backlog_size:1048576 repl_backlog_first_byte_offset:15 repl_backlog_histlen:140 10.xx.xx.221:6379>
同步测试
登录主节点上新增键值对:
set t1 2
登录从节点上查看:
10.xx.xx.221:6379> get t1 "2" 10.xx.xx.221:6379> set t1 3 (error) READONLY You can't write against a read only replica. 10.xx.xx.221:6379>
新增从节点:同之前的从节点一样配置,然后启动服务就行,redis会根据配置自动连接到主节点并成为主从复制的一部分。
断开从节点:登录上从节点,执行命令 SLAVEOF NO ONE ,从节点将不再与任何主节点进行复制,并且它将成为一个独立的 Redis 服务器。
主节点切换:主节点故障的话,从一台从节点中,修改配置,重启服务使之成为主节点,其余从节点也要统一修改配置,在重启服务。
从节点支持写操作:修改从节点配置文件 slave-read-only no 支持写操作,默认为yes,即只读。
二、哨兵模式(Sentinel Mode)
Redis Sentinel(哨兵)是一种用于实现高可用性的 Redis 部署模式。它通过监控主节点和自动故障转移来确保系统的可用性,并提供故障恢复的能力。
在 Redis Sentinel 模式中,有以下关键角色:
-
主节点(Master):处理所有写操作和读操作的节点。
-
从节点(Slave):复制主节点的数据,并提供读操作的能力。从节点可以有多个。
-
哨兵节点(Sentinel):负责监控主节点和从节点的健康状态,以及执行故障转移操作。哨兵节点可以有多个,它们形成一个集群。
注:哨兵节点最少3个,且集群数量为奇数,因要避免单点,且故障转移中涉及到选举,避免产生平局。
2.1 异常节点自动替换
从节点异常
哨兵节点会定期向主节点发送 INFO 命令,获取从节点的信息,包括复制偏移量、连接数等。通过分析从节点的响应,哨兵节点可以判断从节点的健康状态。
当从节点被标记为下线(S_DOWN 状态)时(主观下线),哨兵会通知其他哨兵节点,共同确认从节点的下线状态,以避免误判。多个哨兵确认从节点不健康时(客观下线),哨兵节点会将其从主节点的复制列表中移除,并将其从其他从节点的复制列表中移除。这样,异常从节点将不再接收主节点的复制数据,并且不再被其他从节点复制。当从节点状态恢复,哨兵节点会将其重新添加到主节点的复制列表中,并将其作为其他从节点的复制源。这样,从节点可以继续复制主节点的数据。
主节点异常
哨兵节点会通过向主节点发送名为 "PING" 的命令来进行心跳检测。如果在一定的超时时间内没有收到主节点的心跳响应,哨兵节点将判定主节点为下线状态(主观下线)。
当主节点被标记为下线(S_DOWN 状态)时,哨兵节点会通知其他哨兵节点,共同确认主节点的下线状态,当超过多个哨兵确认主节点不健康时(客观下线),会进行一次选举,在从节点中,选出一个作为主节点,并同时修改其余从节点的配置文件,将新的主节点作为数据同步的来源,然后重新启动服务,完成切换。
选举新主节点
根据从节点的优先级、复制进度、运行ID 号来选出新主节点
从节点优先级由从节点的配置文件设置,通常为 redis.conf ,优先级高的会成为新主节点。
slave-priority 100
当有从节点优先级一样时,复制进度最靠前的从节点胜出。
什么是复制进度?主从架构中,主节点会将写操作同步给从节点,在这个过程中,主节点会用 master_repl_offset(复制偏移量) 记录当前的最新写操作在 repl_backlog_buffer 中的位置,而从节点会用 slave_repl_offset 这个值记录当前的复制进度
如果某个从节点的 slave_repl_offset 最接近 master_repl_offset,说明它的复制进度是最靠前的,于是就可以将它选为新主节点。
当复制进度也一致时,运行ID号小的从节点胜出。
每个从节点都有一个编号,这个编号就是 ID 号,是用来唯一标识从节点的。
主从切换过程(命令)
当选举出新主节点时,哨兵会向被选中的从节点发送 SLAVEOF no one 命令,让这个从节点解除从节点的身份,将其变为新主节点。
在发送 SLAVEOF no one 命令之后,哨兵会以每秒一次的频率向被升级的从节点发送 INFO 命令(没进行故障转移之前,INFO 命令的频率是每十秒一次),并观察命令回复中的角色信息,当被升级节点的角色信息从原来的 slave 变为 master 时,哨兵就知道被选中的从节点已经顺利升级为主节点了。
然后,哨兵向所有的从节点发送 SLAVEOF 命令,让它们成为新主节点的从节点。
当旧主节点重新上线时,哨兵会发送 SLAVEOF 命令,让它成为新主节点的从节点。
所以,在 Redis Sentinel 模式下,当进行主从切换时,哨兵节点不会直接修改主从节点的配置文件信息。主从切换是由哨兵节点自动执行的,它会通过发送命令来告知主从节点进行切换操作,而不是修改配置文件。
2.2 哨兵集群的组成
在配置哨兵集群的信息时,哨兵配置中,只需要填写主节点的相关信息,如:
sentinel monitor <master-name> <ip> <redis-port> <quorum>
哨兵节点信息以及从节点信息都没填,那么它们之间是如何互相发现及互相通信的呢?
哨兵节点之间是通过 Redis 的发布者/订阅者机制来相互发现的。
在主从集群中,主节点上有一个名为 __sentinel__:hello 的频道,不同哨兵就是通过它来相互发现,实现互相通信的。
如下图,哨兵 A 把自己的 IP 地址和端口的信息发布到 __sentinel__:hello 频道上,哨兵 B 和 C 订阅了该频道。那么此时,哨兵 B 和 C 就可以从这个频道直接获取哨兵 A 的 IP 地址和端口号。然后,哨兵 B、C 可以和哨兵 A 建立网络连接。通过这个方式,哨兵 B 和 C 也可以建立网络连接,这样一来,哨兵集群就形成了。
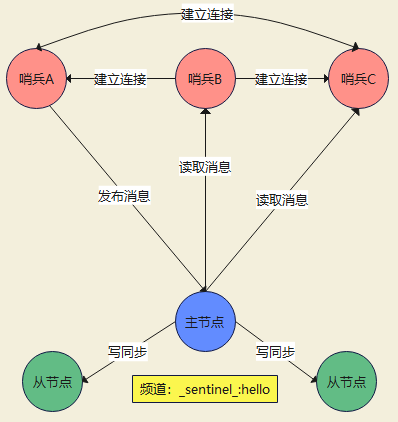
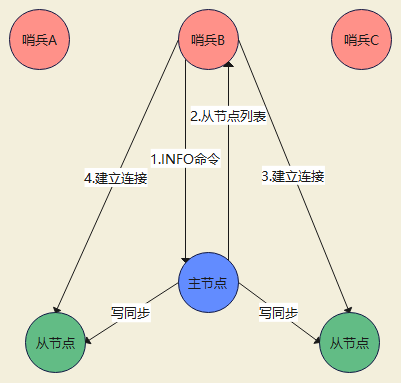
哨兵集群通过向主节点发送INFO命令,获取从节点信息。
如下图所示,哨兵 B 给主节点发送 INFO 命令,主节点接受到这个命令后,就会把从节点列表返回给哨兵。接着,哨兵就可以根据从节点列表中的连接信息,和每个从节点建立连接,并在这个连接上持续地对从节点进行监控。哨兵 A 和 C 可以通过相同的方法和从节点建立连接。
2.3 脑裂如何减少数据丢失
在 Redis 主从架构中,部署方式一般是「一主多从」,主节点提供写操作,从节点提供读操作。
如果主节点的网络突然发生了问题,它与所有的从节点都失联了,但是此时的主节点和客户端的网络是正常的,这个客户端并不知道 Redis 内部已经出现了问题,还在照样的向这个失联的主节点写数据(过程A),此时这些数据被主节点缓存到了缓冲区里,因为主从节点之间的网络问题,这些数据都是无法同步给从节点的。
这时,哨兵也发现主节点失联了,它就认为主节点挂了(但实际上主节点正常运行,只是网络出问题了),于是哨兵就会在从节点中选举出一个 leeder 作为主节点,这时集群就有两个主节点了 —— 脑裂出现了。
这时候网络突然好了,哨兵因为之前已经选举出一个新主节点了,它就会把旧主节点降级为从节点(A),然后从节点(A)会向新主节点请求数据同步,因为第一次同步是全量同步的方式,此时的从节点(A)会清空掉自己本地的数据,然后再做全量同步。所以,之前客户端在过程 A 写入的数据就会丢失了,也就是集群产生脑裂数据丢失的问题。
解决方法:设置参数,规定当主节点发现与从节点断联太多时,停止写入,详细参考本文的1.2.1 异步复制下如何减少数据丢失
2.4 搭建哨兵模式集群
1.按照本文1.3中主从模式集群搭建的方法,先搭建一个一主两从架构的集群,可在配置中设置好从节点优先级,并启动服务。
2.修改哨兵配置文件 sentinel.conf ,这个配置文件默认在redis的安装目录下,即跟 redis.conf 同目录,所有哨兵节点的配置要一致
protected-mode no #是否启用保护模式,在保护模式下,Redis Sentinel 将只接受来自本地回环地址的连接 port 26379 #哨兵监听的端口 daemonize yes #是否以守护进程(daemon)模式运行,守护进程模式是指 Redis Sentinel 在后台运行,并将标准输入、输出和错误重定向到日志文件中。默认不开启 pidfile /var/run/redis-sentinel.pid #pid文件 loglevel notice #日志输出的级别 logfile "./logs/sentinel.log" #日志文件 dir /home/redis-7.2.4 #哨兵节点使用的工作目录,用于存储日志文件和临时文件 sentinel monitor mymaster 127.0.0.1 6379 2 #设置哨兵节点要监控的 Redis 主节点信息,<master-name> 是主节点的名称,<quorum> 是用于决策故障转移的最小投票数 sentinel down-after-milliseconds mymaster 30000 #设置哨兵节点在多少毫秒之后认定主节点不可达,并将其标记为下线 acllog-max-len 128 #设置访问控制列表(ACL)日志的最大长度,当达到最大长度时,旧的日志条目将会被新的日志条目替换 sentinel parallel-syncs mymaster 1 #设置故障转移过程中同时进行同步的从节点数量,用于加速故障转移过程 sentinel failover-timeout mymaster 180000 #故障转移的超时时间,单位毫秒,当主节点被判定为不可用时,Redis Sentinel 在等待多长时间后触发故障转移 sentinel deny-scripts-reconfig yes #禁止通过执行脚本来修改哨兵配置,以增加安全性 SENTINEL resolve-hostnames no #是否解析主机名,no为直接使用配置中指定的 IP 地址 SENTINEL announce-hostnames no #是否向其他 Sentinel 节点和 Redis 客户端公告主机名信息 SENTINEL master-reboot-down-after-period mymaster 0 #设置主节点在下线后自动重启的时间间隔,0为禁用自动重启,立即触发故障转移,单位秒 #sentinel auth-pass <master-name> <password> #配置连接主节点所需的密码 #sentinel announce-ip <ip> #设置哨兵节点向其他节点宣告的IP地址 #sentinel announce-port <port> #设置哨兵节点向其他节点宣告的端口号
3.启动哨兵服务
redis-sentinel /home/redis-7.2.4/sentinel.conf
4.查看进程
[root@test3 redis-7.2.4]# ps -ef | grep redis root 5755 1 0 16:00 ? 00:00:00 redis-server 0.0.0.0:6379 root 5791 1 0 16:01 ? 00:00:00 redis-sentinel *:26379 [sentinel] root 5808 444 0 16:01 pts/0 00:00:00 grep --color redis [root@test3 redis-7.2.4]#
5.连接哨兵,查看主节点信息
[root@test3 redis-7.2.4]# redis-cli -p 26379 127.0.0.1:26379> SENTINEL MASTER mymaster 1) "name" 2) "mymaster" 3) "ip" 4) "10.xx.xx.252" 5) "port" 6) "6379" 7) "runid" 8) "a449a80ad0a9ffa46bb09b4b0ee43ed98a75a7c2" 9) "flags" 10) "master" 11) "link-pending-commands" 12) "0" 13) "link-refcount" 14) "1" 15) "last-ping-sent" 16) "0" 17) "last-ok-ping-reply" 18) "969" 19) "last-ping-reply" 20) "969" 21) "down-after-milliseconds" 22) "30000" 23) "info-refresh" 24) "9239" 25) "role-reported" 26) "master" 27) "role-reported-time" 28) "139709" 29) "config-epoch" 30) "0" 31) "num-slaves" 32) "2" 33) "num-other-sentinels" 34) "2" 35) "quorum" 36) "2" 37) "failover-timeout" 38) "180000" 39) "parallel-syncs" 40) "1"
查看从节点信息
127.0.0.1:26379> SENTINEL SLAVES mymaster 1) 1) "name" 2) "10.xx.xx.190:6379" 3) "ip" 4) "10.xx.xx.190" 5) "port" 6) "6379" 7) "runid" 8) "9ea0750b87555614ba7a79a5aea7da279b55e12a" 9) "flags" 10) "slave" 11) "link-pending-commands" 12) "0" 13) "link-refcount" 14) "1" 15) "last-ping-sent" 16) "0" 17) "last-ok-ping-reply" 18) "661" 19) "last-ping-reply" 20) "661" 21) "down-after-milliseconds" 22) "30000" 23) "info-refresh" 24) "7719" 25) "role-reported" 26) "slave" 27) "role-reported-time" 28) "168348" 29) "master-link-down-time" 30) "0" 31) "master-link-status" 32) "ok" 33) "master-host" 34) "10.86.124.252" 35) "master-port" 36) "6379" 37) "slave-priority" 38) "200" 39) "slave-repl-offset" 40) "146492" 41) "replica-announced" 42) "1" 2) 1) "name" 2) "10.xx.xx.221:6379" 3) "ip" 4) "10.xx.xx.221" 5) "port" 6) "6379" 7) "runid" 8) "e29f1314fcd3eb04a71560dcad1c68107148e0de" 9) "flags" 10) "slave" 11) "link-pending-commands" 12) "0" 13) "link-refcount" 14) "1" 15) "last-ping-sent" 16) "0" 17) "last-ok-ping-reply" 18) "661" 19) "last-ping-reply" 20) "661" 21) "down-after-milliseconds" 22) "30000" 23) "info-refresh" 24) "7719" 25) "role-reported" 26) "slave" 27) "role-reported-time" 28) "168349" 29) "master-link-down-time" 30) "0" 31) "master-link-status" 32) "ok" 33) "master-host" 34) "10.86.124.252" 35) "master-port" 36) "6379" 37) "slave-priority" 38) "100" 39) "slave-repl-offset" 40) "146492" 41) "replica-announced" 42) "1" 127.0.0.1:26379>
6.故障转移测试
关闭主节点的redis服务
[root@test1 redis-7.2.4]# kill 599066
再次查看master节点信息,221这台从节点配置,优先级比190的高,所以221变成了主节点
127.0.0.1:26379> SENTINEL MASTER mymaster 1) "name" 2) "mymaster" 3) "ip" 4) "10.xx.xx.221" 5) "port" 6) "6379" 7) "runid" 8) "e29f1314fcd3eb04a71560dcad1c68107148e0de" 9) "flags" 10) "master" 11) "link-pending-commands" 12) "0" 13) "link-refcount" 14) "1" 15) "last-ping-sent" 16) "0" 17) "last-ok-ping-reply" 18) "591" 19) "last-ping-reply" 20) "591" 21) "down-after-milliseconds" 22) "30000" 23) "info-refresh" 24) "2638" 25) "role-reported" 26) "master" 27) "role-reported-time" 28) "2774" 29) "config-epoch" 30) "1" 31) "num-slaves" 32) "2" 33) "num-other-sentinels" 34) "2" 35) "quorum" 36) "2" 37) "failover-timeout" 38) "180000" 39) "parallel-syncs" 40) "1" 127.0.0.1:26379>
查看从节点信息,可以看到之前的主节点变成了从节点,状态变成了 s_down,slave,disconnected
127.0.0.1:26379> SENTINEL SLAVES mymaster 1) 1) "name" 2) "10.xx.xx.190:6379" 3) "ip" 4) "10.xx.xx.190" 5) "port" 6) "6379" 7) "runid" 8) "9ea0750b87555614ba7a79a5aea7da279b55e12a" 9) "flags" 10) "slave" 11) "link-pending-commands" 12) "0" 13) "link-refcount" 14) "1" 15) "last-ping-sent" 16) "0" 17) "last-ok-ping-reply" 18) "413" 19) "last-ping-reply" 20) "413" 21) "down-after-milliseconds" 22) "30000" 23) "info-refresh" 24) "1775" 25) "role-reported" 26) "slave" 27) "role-reported-time" 28) "72128" 29) "master-link-down-time" 30) "0" 31) "master-link-status" 32) "ok" 33) "master-host" 34) "10.85.229.221" 35) "master-port" 36) "6379" 37) "slave-priority" 38) "200" 39) "slave-repl-offset" 40) "222736" 41) "replica-announced" 42) "1" 2) 1) "name" 2) "10.xx.xx.252:6379" 3) "ip" 4) "10.xx.xx.252" 5) "port" 6) "6379" 7) "runid" 8) "" 9) "flags" 10) "s_down,slave,disconnected" 11) "link-pending-commands" 12) "3" 13) "link-refcount" 14) "1" 15) "last-ping-sent" 16) "72128" 17) "last-ok-ping-reply" 18) "72128" 19) "last-ping-reply" 20) "72128" 21) "s-down-time" 22) "42087" 23) "down-after-milliseconds" 24) "30000" 25) "info-refresh" 26) "0" 27) "role-reported" 28) "slave" 29) "role-reported-time" 30) "72128" 31) "master-link-down-time" 32) "0" 33) "master-link-status" 34) "err" 35) "master-host" 36) "?" 37) "master-port" 38) "0" 39) "slave-priority" 40) "100" 41) "slave-repl-offset" 42) "0" 43) "replica-announced" 44) "1" 127.0.0.1:26379>
三、集群模式(Cluster Mode)
Redis Cluster 是 Redis 的分布式解决方案,集群通过分片(sharding)模式来对数据进行管理,并具备分片间数据复制、故障转移和流量调度的能力。
关键特性及相关概念:
- 分布式架构:Redis Cluster将数据分布在多个节点上,每个节点负责管理一部分数据槽位。集群中总共有16384个槽位,每个槽位对应一个数据片段。通过将数据分布在多个节点上,可以实现数据的负载均衡和横向扩展。
- 主从复制:在Redis Cluster中,每个主节点可以有一个或多个从节点。主节点负责处理客户端请求和写入操作,而从节点则复制主节点的数据,并提供读取操作。主从复制机制实现了数据的冗余备份和故障恢复。
- 故障转移:当主节点发生故障时,Redis Cluster可以自动进行故障转移。会从主节点的从节点中选举出一个新的主节点,接替故障节点的角色,并继续提供服务。故障转移过程是自动的,不需要人工干预。
- 握手阶段:当客户端连接到Redis Cluster时,会进行一次握手阶段,通过集群的节点间通信,客户端会获取到集群的拓扑结构信息,包括节点的IP地址和端口号,以及槽位的分配情况。这样客户端就可以直接与正确的节点进行通信。
- 槽位迁移:在Redis Cluster中,槽位的分配是动态的。当节点加入或离开集群时,槽位会进行重新分配和迁移。槽位迁移是逐个槽位进行的,节点之间会进行数据传输和同步,以保证数据的一致性。
- 客户端路由:Redis Cluster提供了客户端路由功能,客户端可以根据数据的Key来计算槽位,并将请求发送到对应的节点。客户端路由可以实现请求的负载均衡,以及自动发现和适应集群拓扑变化。
注:创建集群时至少需要3个主节点。
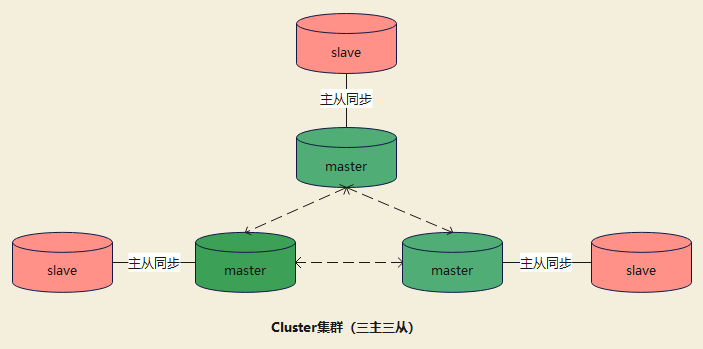
3.1 哈希槽
在Redis Cluster中,哈希槽(Hash Slot)是用来对数据进行分片的单元。Redis Cluster将数据划分为16384个哈希槽,每个槽位对应一个数据片段。哈希槽的范围是从0到16383。槽位的数量是固定的,不会随着集群的扩展或缩减而改变。
cluster通过对Key应用哈希函数(如CRC16)计算出一个哈希值,将哈希值与16384进行模运算(hash % 16384)得到槽位编号,槽位编号确定了数据属于哪个槽位。
注:初始化时,哈希槽必须全部被分配,若有一个槽位没有正常分配,集群会直接报错,无法启动。
哈希槽的划分:
在 Redis Cluster 中,每个键根据其键名进行哈希计算,并被映射到这些哈希槽中的一个。
- 初始状态:当创建一个 Redis Cluster 时,所有的哈希槽都是未分配的状态,没有任何键被映射到特定的哈希槽上。
- 添加节点:当添加主节点到 Redis Cluster 时,每个主节点会负责处理一部分哈希槽。Redis Cluster 会根据主节点的数量平均分配哈希槽。例如,如果有 3 个主节点,每个主节点将负责处理大约 1/3 的哈希槽。
- 哈希槽迁移:当节点加入或离开集群时,集群会自动进行哈希槽的迁移。迁移的目的是将哈希槽从一个节点转移给另一个节点,以实现数据的均衡分布。迁移过程中,集群会自动将相关的键从一个节点复制到另一个节点,并在迁移完成后更新映射关系。
- 当添加新节点时:集群会将一部分哈希槽从现有节点迁移到新节点上。
- 当删除节点时:集群会将被删除节点上负责的哈希槽迁移到其他节点上,确保数据的可用性。
- 客户端请求路由:一旦哈希槽分配完成,客户端的请求将根据键名的哈希值被路由到相应的节点。集群会根据请求中的键名计算哈希值,并将请求发送到负责该哈希槽的节点上进行处理。
手动划分哈希槽:
- 连接到 Redis Cluster: redis-cli -c -h <cluster_host> -p <cluster_port>
- 获取节点信息: CLUSTER NODES
- 执行哈希槽分配命令: CLUSTER ADDSLOTS <slot> [slot ...] NODE <node_id>
- 检查哈希槽分配: CLUSTER SLOTS
哈希槽的映射:
在 Redis Cluster 中,哈希槽(slots)与键的映射是通过对键名进行哈希计算来实现的。Redis 使用 CRC16 算法对键名进行哈希计算,并将计算结果对 16384(2^14)取模,得到对应的哈希槽。
- 哈希计算:对于要存储到 Redis Cluster 的每个键,使用 CRC16 算法对键名进行哈希计算。这个哈希计算过程会生成一个 16 位的无符号整数。
- 取模运算:将哈希计算结果对 16384(2^14)取模,得到一个范围在 0 到 16383 的整数。这个结果就是键对应的哈希槽。如:哈希计算结果为 12345,那么对 16384 取模的结果为 12345 % 16384 = 12345,键就被映射到哈希槽 12345。
-
哈希槽分配:根据哈希槽的映射结果,将键存储在相应的哈希槽中。Redis Cluster 中的每个主节点都负责处理一部分哈希槽,主节点会根据哈希槽的分配情况进行数据存储和处理。
注:哈希槽的划分和映射是 Redis Cluster 在集群创建、主节点加入或离开时自动完成的,不需要手动操作。只有在特殊情况下,如手动划分哈希槽或进行特定的数据迁移时,才需要关注和操作哈希槽的映射关系。
注:哈希槽只分布在主节点上,从节点上没有哈希槽。
3.2 主从复制
在 Redis Cluster 中,主从节点数据的复制是通过主从复制(master-slave replication)实现的。每个主节点(master)可以有一个或多个从节点(slave),主节点负责处理客户端的写操作,并将写操作的结果复制到从节点上。从节点只负责处理客户端的读操作,并复制主节点的数据。原理详见本文第一章
3.3 集群间节点通信/心跳检测
分布式存储集群需要提供维护节点元数据信息(节点信息,节点数据,节点状态等)的机制,常见的有集中式和P2P方式。
- 集中式元数据维护方式:在集中式方式中,有一个中心化的元数据管理节点(通常称为元数据服务器或元数据中心),负责管理和维护系统的元数据信息。其他节点通过与元数据服务器的交互来获取和更新元数据。
- 优点:集中式元数据管理方便集中控制和维护,元数据的一致性和准确性相对容易保证。对于一些需要集中决策或控制的操作,集中式方式更为适用。
- 缺点:集中式元数据服务器可能成为系统的单点故障,一旦元数据服务器发生故障,整个系统的元数据访问和更新都会受到影响。此外,集中式方式的可扩展性和容错性可能较差。
- P2P元数据维护方式:在P2P方式中,每个节点都具有一份或部分的元数据信息,并通过节点之间的相互通信来交换和同步元数据。所有节点都是对等的,没有中心化的元数据管理节点。
- 优点:P2P方式避免了中心化的单点故障,提高了系统的容错性和可用性。每个节点都具有元数据信息的副本,可以快速获取和更新元数据,减少了对中心节点的依赖。
- 缺点:P2P方式的元数据一致性较难保证,节点之间的同步和通信需要额外的开销。同时,P2P方式可能在某些操作上缺乏集中控制和决策的能力。
而cluster使用的是P2P方式,采用gossip协议实现。
gossip协议
gossip协议工作原理:
-
节点选择:
-
- 每个节点在固定的时间间隔内选择一些其他节点来进行通信(集群中的每个节点都会单独开辟一个TCP通道, 用于节点之间彼此通信, 通信端口号在基础端口上加10000)。选择的节点可以是随机选择或基于某种算法进行选择。
-
-
信息交换:
-
- 节点之间进行信息交换,发送包含节点的状态和其他信息的消息。这些信息可以包括节点的IP地址、端口号、槽位分配情况、故障检测信息等。
-
-
消息传播:
-
- 接收到消息的节点会将消息传播给其他节点,从而实现信息在整个集群中的扩散。
- 每个节点会维护一份已知的节点列表,将收到的消息发送给列表中的其他节点。
-
-
故障检测:
-
- 节点通过Gossip协议实时地了解其他节点的状态,包括存活、故障或重新上线等。
- 当节点检测到其他节点故障时,会将该信息传播给集群中的其他节点,以便进行故障转移和恢复操作。
-
-
节点状态更新:
-
- 当节点接收到其他节点的消息时,会更新自己维护的节点状态信息。
- 节点可能会更新其他节点的状态、增加或删除节点,以反映整个集群的最新状态。
-
Gossip协议的优点之一是它的去中心化性质,每个节点都可以主动地向其他节点传播信息,无需集中的协调者。这种去中心化的设计使得Gossip协议具有较好的可扩展性和容错性,能够适应大规模分布式系统中的节点动态变化和故障情况。
消息类型
常用的Gossip消息可分为: ping消息、 pong消息、 meet消息、 fail消息等。
- ping:ping 消息是用于探测其他节点是否存活和可达的消息。当一个节点发送 Ping 消息给其他节点时,它期望收到 Pong 消息作为回复,以确认目标节点的存活状态。
- pong:pong 消息是对 Ping 消息的回复,用于确认节点的存活状态。当一个节点收到 Ping 消息时,会发送 Pong 消息给发送方,表明自己是存活的。
- meet:meet 消息是用于节点之间建立联系和发现新节点的消息。当一个节点想要加入到分布式系统中时,它可以发送 Meet 消息给一个已知的节点,请求与其建立联系。通过 Meet 消息的交换,新节点可以与现有节点建立连接并进一步扩展整个集群。
- fail:fail 消息是用于通知其他节点某个节点的故障或不可用状态的消息。当一个节点检测到另一个节点发生故障时,它可以发送 Fail 消息给其他节点,以便其他节点能够感知到该节点的状态,并采取相应的措施,如从集群中移除故障节点。
消息格式
所有的消息格式划分为: 消息头和消息体。
消息头包含发送节点自身状态数据, 接收节点根据消息头就可以获取到发送节点的相关数据,如:
typedef struct { char sig[4]; /* 信号标示 */ uint32_t totlen; /* 消息总长度 */ uint16_t ver; /* 协议版本*/ uint16_t type; /* 消息类型,用于区分meet,ping,pong等消息 */ uint16_t count; /* 消息体包含的节点数量, 仅用于meet,ping,ping消息类型*/ uint64_t currentEpoch; /* 当前发送节点的配置纪元 */ uint64_t configEpoch; /* 主节点/从节点的主节点配置纪元 */ uint64_t offset; /* 复制偏移量 */ char sender[CLUSTER_NAMELEN]; /* 发送节点的nodeId */ unsigned char myslots[CLUSTER_SLOTS/8]; /* 发送节点负责的槽信息 */ char slaveof[CLUSTER_NAMELEN]; /* 如果发送节点是从节点, 记录对应主节点的nodeId */ uint16_t port; /* 端口号 */ uint16_t flags; /* 发送节点标识,区分主从角色, 是否下线等 */ unsigned char state; /* 发送节点所处的集群状态 */ unsigned char mflags[3]; /* 消息标识 */ union clusterMsgData data /* 消息正文 */; } clusterMsg;
每个消息体包含该节点的多个clusterMsgDataGossip结构数据, 用于信息交换,如:
typedef struct { char nodename[CLUSTER_NAMELEN]; /* 节点的nodeId */ uint32_t ping_sent; /* 最后一次向该节点发送ping消息时间 */ uint32_t pong_received; /* 最后一次接收该节点pong消息时间 */ char ip[NET_IP_STR_LEN]; /* IP */ uint16_t port; /* port*/ uint16_t flags; /* 该节点标识, */ } clusterMsgDataGossip;
3.4 请求路由
客户端直连 Redis 服务,进行读写操作时,Key 对应的 Slot 可能并不在当前直连的节点上,要经过“重定向”才能转发到正确的节点。
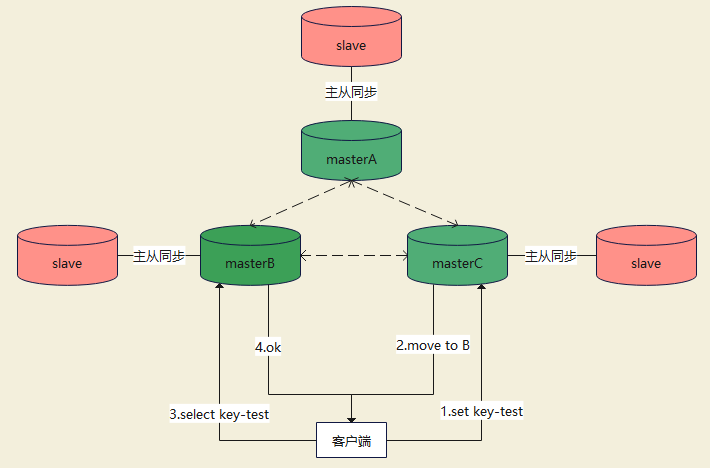
3.5 故障转移
故障节点发现与自动替换:
-
故障节点检测:每个节点通过 Gossip 协议与其他节点进行周期性的消息交换。当一个节点在一定时间内( cluster-node-timeout )没有收到来自主节点的消息时,它会将该主节点标记为疑似下线(pfail状态,即主观下线)。
-
疑似下线节点确认:节点向其他节点发送确认消息,询问它们是否也认为该主节点处于疑似下线状态。
-
多数派确认:如果大多数节点都确认了该主节点的疑似下线状态,那么该主节点会被标记为fail状态(客观下线)。
-
故障转移决策:客观下线的主节点会触发故障转移决策。集群中的其他节点会根据一定的算法和规则,从该主节点的从节点中选举出一个新的主节点。
-
新主节点选举:新的主节点会被选举并接管故障主节点的槽。选举过程中通常采用 Raft 算法或者其他一致性算法来保证选举的正确性和一致性。
-
数据重平衡:一旦新的主节点选举完成,集群会开始进行数据重平衡,将原先属于故障主节点的槽重新分配给新的主节点,并确保数据的一致性。
注:只有主节点参与故障发现决策,因为只有负责某个槽的主节点才能准确地了解该槽中的数据状态,才能提供准确的信息进行切换,其他从节点虽然存储了主节点的数据副本,但它们并不了解数据槽的具体分布情况。
注:实际应用中, cluster-node-timeout 不可设置过小,防止网络延迟或服务抖动而进行频繁的主从切换。
当一个从节点故障时,集群仅将该从节点标记为下线(FAIL状态),主节点仍正常服务请求。此时需人工干预,恢复或新增从节点实例,避免主节点无从节点可用。
当主节点故障,且无从节点可替换时,该主节点负责的槽位(slots)对应的数据会不可用(CLUSTERDOWN 错误或 MOVED 重定向失败),但集群整体仍可能保持部分可用。
3.6 cluster集群搭建(三主三从)
3.6.1 安装redis
六台实例下载安装好redis,可参照:https://www.cnblogs.com/Xinenhui/p/18112893
3.6.2 修改redis配置
六台实例配置都一样(不使用默认的日志目录要创建)
bind 0.0.0.0 -::1 protected-mode no port 6379 tcp-backlog 511 timeout 0 tcp-keepalive 300 daemonize yes pidfile /var/run/redis_6379.pid loglevel notice logfile "./logs/redis.log" databases 16 always-show-logo no set-proc-title yes proc-title-template "{title} {listen-addr} {server-mode}" locale-collate "" stop-writes-on-bgsave-error yes rdbcompression yes rdbchecksum yes dbfilename dump.rdb rdb-del-sync-files no dir /home/redis-7.2.4 replica-serve-stale-data yes replica-read-only yes repl-diskless-sync yes repl-diskless-sync-delay 5 repl-diskless-sync-max-replicas 0 repl-diskless-load disabled repl-disable-tcp-nodelay no replica-priority 100 acllog-max-len 128 lazyfree-lazy-eviction no lazyfree-lazy-expire no lazyfree-lazy-server-del no replica-lazy-flush no lazyfree-lazy-user-del no lazyfree-lazy-user-flush no oom-score-adj no oom-score-adj-values 0 200 800 disable-thp yes appendonly no appendfilename "appendonly.aof" appenddirname "appendonlydir" appendfsync everysec no-appendfsync-on-rewrite no auto-aof-rewrite-percentage 100 auto-aof-rewrite-min-size 64mb aof-load-truncated yes aof-use-rdb-preamble yes aof-timestamp-enabled no
#开启集群功能,此redis实例作为集群的一个节点,否则,它是一个普通的单一的redis实例 cluster-enabled yes
#集群节点的配置文件,在dir的目录下 cluster-config-file nodes-6379.conf
#集群节点之间通信的超时时间,单位毫秒 cluster-node-timeout 15000 slowlog-log-slower-than 10000 slowlog-max-len 128 latency-monitor-threshold 0 notify-keyspace-events "" hash-max-listpack-entries 512 hash-max-listpack-value 64 list-max-listpack-size -2 list-compress-depth 0 set-max-intset-entries 512 set-max-listpack-entries 128 set-max-listpack-value 64 zset-max-listpack-entries 128 zset-max-listpack-value 64 hll-sparse-max-bytes 3000 stream-node-max-bytes 4096 stream-node-max-entries 100 activerehashing yes client-output-buffer-limit normal 0 0 0 client-output-buffer-limit replica 256mb 64mb 60 client-output-buffer-limit pubsub 32mb 8mb 60 hz 10 dynamic-hz yes aof-rewrite-incremental-fsync yes rdb-save-incremental-fsync yes jemalloc-bg-thread yes
3.6.3 启动redis服务
redis-server /home/redis-7.2.4/redis.conf
查看进程
[root@test1 redis-7.2.4]# ps -ef | grep redis root 78569 1 0 17:01 ? 00:00:00 redis-server 0.0.0.0:6379 [cluster] root 78580 483691 0 17:01 pts/1 00:00:00 grep --color redis
3.6.4 创建集群
创建时要确保所有节点都没有数据,且并没有与其他节点通信过,不然会报错:
[ERR] Node 10.xx.xx.252:6379 is not empty. Either the node already knows other nodes (check with CLUSTER NODES) or contains some key in database 0.
解决方案:登录redis,执行 FLUSHDB 清空数据,执行 CLUSTER NODES 命令,检查节点的状态。确保节点没有已知的其他节点
自动创建集群
--cluster-replicas 1 表示每个主节点都有一个从节点,这样集群就会自动创建成3主3从的架构,随机分配主从节点,平均分配哈希槽
redis-cli --cluster create --cluster-replicas 1 10.xx.xx.252:6379 10.xx.xx.221:6379 10.xx.xx.190:6379 10.xx.xx.94:6379 10.xx.xx.137:6379 10.xx.xx.95:6379
详细过程:
>>> Performing hash slots allocation on 6 nodes... #开始执行哈希槽分配 Master[0] -> Slots 0 - 5460 Master[1] -> Slots 5461 - 10922 Master[2] -> Slots 10923 - 16383 Adding replica 10.xx.xx.137:6379 to 10.xx.xx.252:6379 #自动分配主从节点 Adding replica 10.xx.xx.95:6379 to 10.xx.xx.221:6379 Adding replica 10.xx.xx.94:6379 to 10.xx.xx.190:6379 M: 48b848005b5eef9552f3a59c237ace1c4c0ce01e 10.xx.xx.252:6379 #主节点 slots:[0-5460] (5461 slots) master M: f75f27995766f867a08131c01dc8a0c4ef5b1782 10.xx.xx.221:6379 slots:[5461-10922] (5462 slots) master M: 6062a5b909bfbd0257a2f43ad9acaa5a32d75dd4 10.xx.xx.190:6379 slots:[10923-16383] (5461 slots) master S: bb61761df4ce565b37025f83b5db573617c504e3 10.xx.xx.94:6379 replicates 6062a5b909bfbd0257a2f43ad9acaa5a32d75dd4 S: 2109e1e63c79cf20273b890b951781ef50054f88 10.xx.xx.137:6379 replicates 48b848005b5eef9552f3a59c237ace1c4c0ce01e S: 1b729c4cf58c7e1d9d24d62f415fac1f6d58a25f 10.xx.xx.95:6379 replicates f75f27995766f867a08131c01dc8a0c4ef5b1782 Can I set the above configuration? (type 'yes' to accept): yes #确认是否接受这样的分配结果 >>> Nodes configuration updated >>> Assign a different config epoch to each node >>> Sending CLUSTER MEET messages to join the cluster Waiting for the cluster to join >>> Performing Cluster Check (using node 10.xx.xx.252:6379) M: 48b848005b5eef9552f3a59c237ace1c4c0ce01e 10.xx.xx.252:6379 slots:[0-5460] (5461 slots) master 1 additional replica(s) M: f75f27995766f867a08131c01dc8a0c4ef5b1782 10.xx.xx.221:6379 slots:[5461-10922] (5462 slots) master 1 additional replica(s) S: bb61761df4ce565b37025f83b5db573617c504e3 10.xx.xx.94:6379 slots: (0 slots) slave replicates 6062a5b909bfbd0257a2f43ad9acaa5a32d75dd4 S: 2109e1e63c79cf20273b890b951781ef50054f88 10.xx.xx.137:6379 slots: (0 slots) slave replicates 48b848005b5eef9552f3a59c237ace1c4c0ce01e S: 1b729c4cf58c7e1d9d24d62f415fac1f6d58a25f 10.xx.xx.95:6379 slots: (0 slots) slave replicates f75f27995766f867a08131c01dc8a0c4ef5b1782 M: 6062a5b909bfbd0257a2f43ad9acaa5a32d75dd4 10.xx.xx.190:6379 slots:[10923-16383] (5461 slots) master 1 additional replica(s) [OK] All nodes agree about slots configuration. >>> Check for open slots... >>> Check slots coverage... [OK] All 16384 slots covered.
查看集群状态和节点
redis-cli --cluster check 10.xx.xx.252:6379
redis-cli cluster nodes
登录集群:加上-c参数,以集群模式登录,不然登录的单机,无法使用;登录主从节点都可以
redis-cli -c -h 10.xx.xx.221 -p 6379
插入数据:会根据插入的数据跳转到计算出哈希槽后的对应的master节点,master节点存入数据后,其对应的slave节点就会进行数据同步;查询也会跳转至相应的master节点上
10.xx.xx.95:6379> set name jer -> Redirected to slot [5798] located at 10.xx.xx.221:6379 OK 10.xx.xx.221:6379>
查询数据:
10.xx.xx.221:6379> get name
手动创建
先创建主节点
redis-cli --cluster create 10.xx.xx.95:6379 10.xx.xx.137:6379 10.xx.xx.94:6379
为主节点添加从节点
redis-cli --cluster add-node <new-node-ip>:<new-node-port> <existing-node-ip>:<existing-node-port> --cluster-slave --cluster-master-id <master-node-id>
3.6.5 扩容节点
扩容主节点:输入新节点ip跟端口号,后面接集群中任意一节点的ip和端口号
redis-cli --cluster add-node <new-node-ip>:<new-node-port> 10.xx.xx.252:6379
新主节点哈希槽为0,需要重新分配哈希槽,这里使用自动平均分配槽位
redis-cli --cluster rebalance 10.xx.xx.252:6379
再次查看集群
redis-cli cluster nodes
扩容从节点:
随机分配主节点: --cluster-slave 表示该节点为从节点
redis-cli --cluster add-node <new-node-ip>:<new-node-port> <existing-node-ip>:<existing-node-port> --cluster-slave
扩容指定主节点的从节点:后面接主节点的id,主节点id为 redis-cli cluster nodes 输出第一列
redis-cli --cluster add-node <new-node-ip>:<new-node-port> <existing-node-ip>:<existing-node-port> --cluster-slave --cluster-master-id <master-node-id>
3.6.6 删除节点
删除从节点:
redis-cli --cluster del-node <existing-node-ip>:<existing-node-port> <node-id-to-remove>
删除主节点:
删除主节点前要迁移槽位,不然会报错:
[ERR] Node 10.xx.xx.94:6379 is not empty! Reshard data away and try again.
迁移槽位
[root@test5 redis-7.2.4]# redis-cli --cluster reshard 10.xx.xx.221:6379 # 开始迁移槽位 ... How many slots do you want to move (from 1 to 16384)? 5461 # 迁移槽位的数量 What is the receiving node ID? f75f27995766f867a08131c01dc8a0c4ef5b1782 # 迁移到哪个主节点,填写其id Source node #1: bb61761df4ce565b37025f83b5db573617c504e3 # 从哪个主节点开始迁移,填写其id Source node #2: done # 结束位置 ... Do you want to proceed with the proposed reshard plan (yes/no)? yes # 是否接受这样的分配结果
迁移完后,原主节点因为没有槽位就变成了从节点,原主节点及其从节点都变成了,增加槽位的主节点的从节点,即增加槽位的主节点变成了一主三从;这样,就可以删除这个节点了
redis-cli --cluster del-node <existing-node-ip>:<existing-node-port> <node-id-to-remove>
然后可以再平均分配槽位
redis-cli --cluster rebalance 10.xx.xx.252:6379
3.6.7 手动切换主从节点
登录上从节点,执行 cluster failover 进行切换,或者 cluster failover force 强制切换;当集群所有主节点都故障时,可执行 cluster failover takeover 快速恢复集群。
3.6.8 故障测试
从节点异常
kill掉一从节点进程(或者使用 redis-cli shutdown 停止),再使用 redis-cli cluster nodes 查看,发现该从节点已标记为异常,其他无变化
1b729c4cf58c7e1d9d24d62f415fac1f6d58a25f 10.xx.xx.95:6379@16379 slave,fail f75f27995766f867a08131c01dc8a0c4ef5b1782 1712720017247 1712720014000 2 disconnected
check集群状态:
[root@test1 redis-7.2.4]# redis-cli --cluster check 10.xx.xx.190:6379 Could not connect to Redis at 10.xx.xx.95:6379: Connection refused
主节点异常
kill掉一主节点的进程,发现其从节点升级为了主节点,原主节点状态异常
6062a5b909bfbd0257a2f43ad9acaa5a32d75dd4 10.xx.xx.190:6379@16379 master,fail - 1712720559910 1712720557898 3 disconnected bb61761df4ce565b37025f83b5db573617c504e3 10.xx.xx.94:6379@16379 master - 0 1712720607000 7 connected 10923-16383
再启动原主节点,变成了从节点,其主节点是原来的从节点, redis-cli cluster nodes 命令输出中,如果是salve,会在后一列输出其主节点的id,对比id可知晓主从节点分布
[root@test5 redis-7.2.4]# redis-cli cluster nodes 6062a5b909bfbd0257a2f43ad9acaa5a32d75dd4 10.85.xx.xx:6379@16379 slave bb61761df4ce565b37025f83b5db573617c504e3 0 1712720830000 7 connected bb61761df4ce565b37025f83b5db573617c504e3 10.xx.xx.94:6379@16379 master - 0 1712720831526 7 connected 10923-16383
没有从节点的主节点异常
kill掉没有从节点的主节点进程(该节点的从节点进程已关闭),整个集群将不可用,因为槽位没有全部正常分配,报错如下:
10.xx.xx.190:6379> get name (error) CLUSTERDOWN The cluster is down
查看集群状态:
[root@test3 redis-7.2.4]# redis-cli cluster nodes 676351c775954255779a16c8e28ae6a7cd69da9e 10.xx.xx.221:6379@16379 master,fail - 1712821695540 1712821692000 2 disconnected 5461-10922
集群节点未覆盖所有插槽,报错:
[root@test3 redis-7.2.4]# redis-cli --cluster check 10.xx.xx.252:6379 ... [ERR] Not all 16384 slots are covered by nodes.
此时无法重新平均分配槽位,会报错:
[root@test3 redis-7.2.4]# redis-cli --cluster rebalance 10.xx.xx.252:6379 ... [ERR] Not all 16384 slots are covered by nodes. *** Please fix your cluster problems before rebalancing
所以,确保集群中每个主节点至少有一个正常状态的从节点,否则当主节点异常时,会导致整个集群不可用(cluster-require-full-coverage为yes时)。
3.7 cluster-require-full-coverage
在 Redis 集群(Cluster 模式)中,配置参数 cluster-require-full-coverage 决定了集群是否要求所有 16384 个哈希槽(slots)全部在线才能提供服务。
- yes:redis 5.0及以上版本默认为yes;如果任意哈希槽未分配(未绑定到任何节点)或对应的主节点故障且无副本接替,集群会标记自身为 FAIL 状态,拒绝所有读写请求,即集群不可用。
- no:即使部分哈希槽不可用(例如主节点故障且无副本),集群仍保持 OK 状态,允许客户端访问其他在线的哈希槽。
应用场景:
- yes:强一致性场景: 要求所有数据必须完整可用,例如金融交易系统。需确保每个主节点至少有一个从节点,避免单点故障。
- no:高可用性优先: 允许部分数据不可用,但保障集群整体服务能力,例如缓存场景。
客户端行为:
-
智能客户端:客户端会缓存集群的槽位分布信息。当尝试访问故障槽位时,会收到
MOVED或ASK错误,需更新路由表并重试。若参数为yes,客户端会直接收到CLUSTERDOWN错误。 -
非智能客户端:可能因连接失败或未处理重定向逻辑而报错。
配置:
在 Redis 配置文件(redis.conf)中设置:
cluster-require-full-coverage no
在运行时动态修改(需谨慎,可能影响业务):
redis-cli config set cluster-require-full-coverage no
3.8 当一个主节点故障且没有从节点可以接替时
3.8.1 优先恢复集群可用性
1、尝试恢复原主节点
-
目标:优先尝试恢复原主节点,保留最新数据。
-
操作:
-
检查原主节点故障原因(如进程崩溃、机器宕机等),修复硬件或网络问题。
-
重启原主节点的 Redis 服务。
-
执行
CLUSTER MEET命令将其重新加入集群: redis-cli -h <健康节点IP> -p <端口> CLUSTER MEET <原主节点IP> <原主节点端口> - 集群会自动将原主节点重新标记为在线,并恢复其负责的槽位。
-
-
优点:数据无损失,恢复速度快。
-
缺点:依赖原主节点可修复。
2、手动添加新节点接替故障主节点
-
目标:若原主节点无法恢复,引入新节点接管槽位。
-
操作:
-
启动一个新 Redis 实例作为临时节点。
-
将新节点加入集群: redis-cli --cluster add-node <新节点IP:端口> <集群中健康节点IP:端口>
- 将新节点手动设置为故障主节点的从节点(需原主节点 ID): redis-cli -h <新节点IP> -p <端口> CLUSTER REPLICATE <原主节点ID>
- 触发故障转移,将新节点提升为主节点: redis-cli -h <新节点IP> -p <端口> CLUSTER FAILOVER TAKEOVER
- 重新分配槽位给新节点(若自动分配失败): redis-cli --cluster reshard <健康节点IP:端口> --cluster-from <原主节点ID> --cluster-to <新节点ID> --cluster-slots <槽位数> --cluster-yes
-
-
优点:快速恢复槽位可用性。
-
缺点:若原主节点数据未持久化,新节点可能丢失故障前的数据。
3、强制移除故障主节点
-
目标:若原主节点彻底无法恢复,且数据可接受丢失。
-
操作:
-
从集群中强制移除故障主节点: redis-cli --cluster del-node <健康节点IP:端口> <故障主节点ID>
-
将故障主节点负责的槽位分配给其他健康主节点: redis-cli --cluster reshard <健康节点IP:端口> --cluster-slots <槽位数> --cluster-yes
-
-
优点:立即恢复集群可用性。
-
缺点:故障主节点的数据永久丢失。
3.8.2 最大限度保留数据
1、从原主节点的持久化文件恢复
-
目标:利用 RDB/AOF 文件恢复数据到新节点。
-
操作:
-
找到原主节点的数据目录,备份
dump.rdb或appendonly.aof文件。 -
启动一个新 Redis 实例,将备份文件复制到其数据目录。
-
启动新实例并验证数据完整性。
-
将新节点加入集群并分配槽位(参考上文 “手动添加新节点” 步骤)。
-
-
优点:保留故障前的数据。
-
缺点:依赖原主节点的持久化文件,可能丢失最后一次持久化后的数据。
2、从其他节点的副本恢复
-
目标:若其他节点的副本中存在部分数据(如旧快照)。
-
操作:
-
从其他节点的 RDB/AOF 文件中提取属于故障槽位的键。
-
将提取的键导入到新节点。
-
将新节点加入集群并分配槽位。
-
-
优点:部分恢复数据。
-
缺点:操作复杂,数据可能不一致。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号