Flume 详解&实战
Flume
1. 概述
Flume是一个高可用,高可靠,分布式的海量日志采集、聚合和传输的系统。Flume基于流式架构,灵活简单。
Flume的作用
- Flume最主要的作用就是,实时读取服务器本地磁盘的数据,将数据写入到HDFS
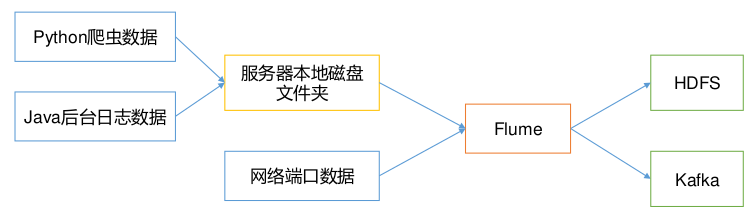
Flume的特性
- 有一个简单、灵活的基于流的数据流结构
- 具有负载均衡机制和故障转移机制
- 一个简单可扩展的数据模型
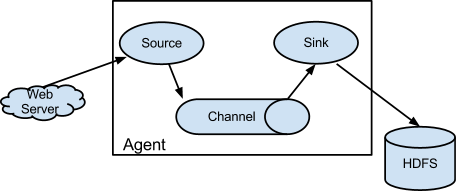
三大核心组件
Agent 是一个 JVM 进程,它以事件的形式将数据从源头送至目的
Agent 主要有 3 个部分组成,Source、Channel、Sink
-
source 数据源
从外界采集各种类型数据,将数据传递给channel
类型很多:文件、目录、端口、Kafka等
Exec Source:实现文件监控,注意tail -F和tail -f的区别,前者根据文件名后者根据文件描述进行跟踪NetCat TCP/UDP Source:采集指定端口(tcp、udp)的数据Spooling Directory Source:采集文件夹里新增的文件Kafka Source:从Kafka消息队列中采集数据
-
channel 临时存储数据的管道
接受Source发出的数据,临时存储,Channel 是位于 Source 和 Sink 之间的缓冲区。因此,Channel 允许 Source 和 Sink 运作在不同的速率上。Channel 是线程安全的,可以同时处理几个 Source 的写入操作和几个Sink 的读取操作。
类型很多:内存、文件、内存+文件、JDBC等
Memory Channel:使用内存作为数据的存储- 速度快,有丢失风险
File Channel:使用文件来作为数据的存储- 效率不高,没有丢失风险
Spillable Memory Channel:使用内存和文件作为数据存储即先存到内存中,如果内存中数据达到阈值再flush到文件中
-
sink 采集数据的传送目的
从channel中读取数据并存储到指定目的地
Sink的表现形式:控制台、HDFS、Kafka等
- Channel中的数据直到进入目的地才会被删除,当Sink写入失败后,可以自动重写,不会造成数据丢失
Logger Sink:将数据作为日志处理HDFS Sink:将数据传输到HDFS中Kafka Sink:将数据发送到Kafka消息队列中
-
Event
传输单元,Flume 数据传输的基本单元,以 Event 的形式将数据从源头送至目的地。Event 由 Header 和 Body 两部分组成,Header 用来存放该 event 的一些属性,为 K-V 结构,Body 用来存放该条数据,形式为字节数组。

2. 入门案例
2.1 监控端口数据官方案例
案例需求:使用 Flume 监听一个端口,收集该端口数据,并打印到控制台。
需求分析

实现步骤
-
安装 netcat 工具
sudo yum install -y nc -
判断 44444 端口是否被占用
sudo netstat -nlp | grep 44444 -
在 flume 目录下创建 job 文件夹并进入 job 文件夹
mkdir job cd job -
创建 Flume Agent 配置文件 flume-netcat-logger.conf,添加如下内容
vim flume-netcat-logger.conf# Name the components on this agent # a1是当前agent的名字,名字在单台flume里要保持唯一 # 可以配置多个sources sinks channels a1.sources = r1 a1.sinks = k1 a1.channels = c1 # Describe/configure the source a1.sources.r1.type = netcat a1.sources.r1.bind = localhost a1.sources.r1.port = 44444 # Describe the sink a1.sinks.k1.type = logger # Use a channel which buffers events in memory a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 # Bind the source and sink to the channel # sources可以对应多个channel # 一个sink只能绑定一个channel a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1
-
先开启 flume 监听端口
# 第一种写法 bin/flume-ng agent --conf conf/ --name a1 --conf-file job/flume-netcat-logger.conf -Dflume.root.logger=INFO,console # 第二种写法 bin/flume-ng agent -c conf/ -n a1 -f job/flume-netcat-logger.conf -Dflume.root.logger=INFO,console参数
--conf/-c:表示配置文件存储在 conf/目录--name/-n:表示给 agent 起名为 a1--conf-file/-f:flume 本次启动读取的配置文件是在 job 文件夹下的 flume-telnet.conf文件-Dflume.root.logger=INFO,console:-D表示 flume 运行时动态修改 flume.root.logger 参数属性值,并将控制台日志打印级别设置为 INFO 级别。日志级别包括:log、info、warn、error
-
使用 netcat 工具向本机的 44444 端口发送内容
nc localhost 44444 -
在 Flume 监听页面观察接收数据情况

2.2 实时监控单个追加文件
案例需求:实时监控 Hive 日志,并上传到 HDFS 中
需求分析
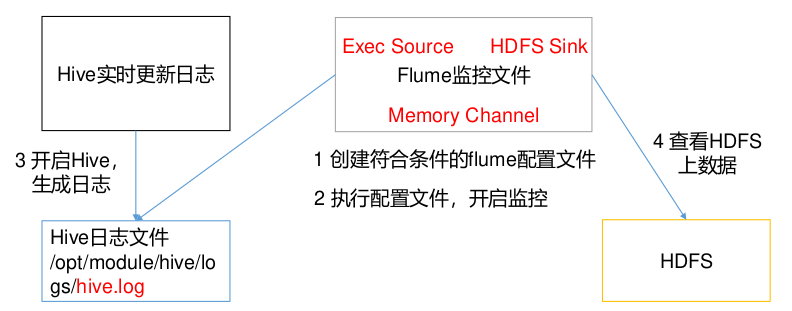
实现步骤
-
Flume 要想将数据输出到 HDFS,依赖 Hadoop 相关 jar 包
-
job包内创建 flume-file-hdfs.conf 文件
vim flume-file-hdfs.conf注:要想读取 Linux 系统中的文件,就得按照 Linux 命令的规则执行命令。由于 Hive日志在 Linux 系统中所以读取文件的类型选择:exec 即 execute 执行的意思。表示执行Linux 命令来读取文件。
# Name the components on this agent a2.sources = r2 a2.sinks = k2 a2.channels = c2 # Describe/configure the source # 此路径是运行flume机器上的本地路径,因此hive运行机器要与flume保持一致 a2.sources.r2.type = exec a2.sources.r2.command = tail -F /opt/hive-3.1.3/logs/hive.log # Describe the sink a2.sinks.k2.type = hdfs a2.sinks.k2.hdfs.path = hdfs://node1:8020/flume/%Y%m%d/%H #上传文件的前缀 a2.sinks.k2.hdfs.filePrefix = logs- #是否按照时间滚动文件夹 a2.sinks.k2.hdfs.round = true #多少时间单位创建一个新的文件夹 a2.sinks.k2.hdfs.roundValue = 1 #重新定义时间单位 a2.sinks.k2.hdfs.roundUnit = hour #是否使用本地时间戳 a2.sinks.k2.hdfs.useLocalTimeStamp = true #积攒多少个 Event 才 flush 到 HDFS 一次 a2.sinks.k2.hdfs.batchSize = 100 #设置文件类型,可支持压缩 a2.sinks.k2.hdfs.fileType = DataStream #多久生成一个新的文件 a2.sinks.k2.hdfs.rollInterval = 60 #设置每个文件的滚动大小 a2.sinks.k2.hdfs.rollSize = 134217700 #文件的滚动与 Event 数量无关 a2.sinks.k2.hdfs.rollCount = 0 # Use a channel which buffers events in memory a2.channels.c2.type = memory a2.channels.c2.capacity = 1000 a2.channels.c2.transactionCapacity = 100 # Bind the source and sink to the channel a2.sources.r2.channels = c2 a2.sinks.k2.channel = c2注意:对于所有与时间相关的转义序列,Event Header 中必须存在以 “timestamp”的key(除非 hdfs.useLocalTimeStamp 设置为 true,此方法会使用 TimestampInterceptor 自动添加 timestamp)

-
运行flume
bin/flume-ng agent --conf conf/ --name a2 --conf-file job/flume-file-hdfs.conf -
开启 Hadoop 和 Hive 并操作 Hive 产生日志
sbin/start-dfs.sh sbin/start-yarn.sh bin/hive
2.3 实时监控目录下多个新文件
案例需求:使用 Flume 监听整个目录的文件,并上传至 HDFS
需求分析:
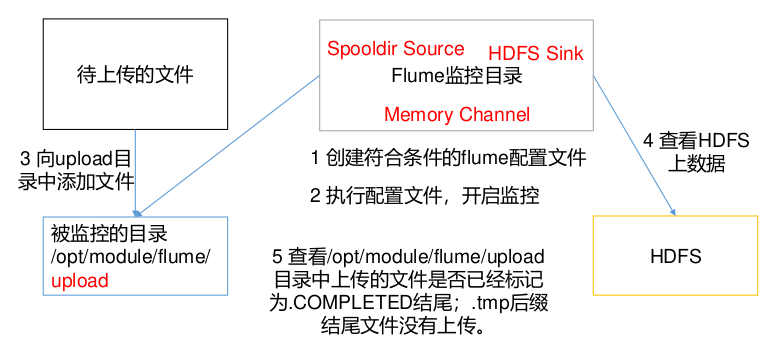
实现步骤
-
创建配置文件 flume-dir-hdfs.conf
a3.sources = r3 a3.sinks = k3 a3.channels = c3 # Describe/configure the source a3.sources.r3.type = spooldir a3.sources.r3.spoolDir = /opt/flume-1.9.0/upload a3.sources.r3.fileSuffix = .COMPLETED a3.sources.r3.fileHeader = true #忽略所有以.tmp 结尾的文件,不上传 a3.sources.r3.ignorePattern = ([^ ]*\.tmp) # Describe the sink a3.sinks.k3.type = hdfs a3.sinks.k3.hdfs.path = hdfs://node1:8020/flume/upload/%Y%m%d/%H #上传文件的前缀 a3.sinks.k3.hdfs.filePrefix = upload- #是否按照时间滚动文件夹 a3.sinks.k3.hdfs.round = true #多少时间单位创建一个新的文件夹 a3.sinks.k3.hdfs.roundValue = 1 #重新定义时间单位 a3.sinks.k3.hdfs.roundUnit = hour #是否使用本地时间戳 a3.sinks.k3.hdfs.useLocalTimeStamp = true #积攒多少个 Event 才 flush 到 HDFS 一次 a3.sinks.k3.hdfs.batchSize = 100 #设置文件类型,可支持压缩 a3.sinks.k3.hdfs.fileType = DataStream #多久生成一个新的文件 a3.sinks.k3.hdfs.rollInterval = 60 #设置每个文件的滚动大小大概是 128M a3.sinks.k3.hdfs.rollSize = 134217700 #文件的滚动与 Event 数量无关 a3.sinks.k3.hdfs.rollCount = 0 # Use a channel which buffers events in memory a3.channels.c3.type = memory a3.channels.c3.capacity = 1000 a3.channels.c3.transactionCapacity = 100 # Bind the source and sink to the channel a3.sources.r3.channels = c3 a3.sinks.k3.channel = c3
-
启动监控文件夹命令
bin/flume-ng agent --conf conf/ --name a3 --conf-file job/flume-dir-hdfs.conf说明:在使用 Spooling Directory Source 时,不要在监控目录中创建并持续修改文件;上传完成的文件会以.COMPLETED 结尾;被监控文件夹每 500 毫秒扫描一次文件变动
-
向 upload 文件夹中添加文件
在/opt/module/flume 目录下创建 upload 文件夹
向 upload 文件夹中添加文件
-
查看 HDFS 上的数据
2.4 实时监控目录下的多个追加文件
Exec source 适用于监控一个实时追加的文件,不能实现断点续传;Spooldir Source适合用于同步新文件,但不适合对实时追加日志的文件进行监听并同步;而 Taildir Source适合用于监听多个实时追加的文件,并且能够实现断点续传。
案例需求:使用 Flume 监听整个目录的实时追加文件,并上传至 HDFS
需求分析:
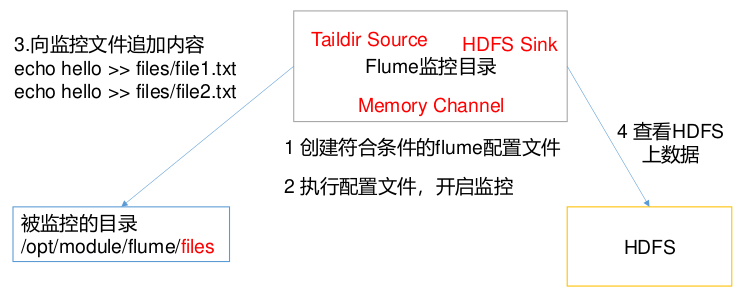
实现步骤
-
创建配置文件 flume-taildir-hdfs.conf
vim flume-taildir-hdfs.confa3.sources = r3 a3.sinks = k3 a3.channels = c3 # Describe/configure the source a3.sources.r3.type = TAILDIR a3.sources.r3.positionFile = /opt/flume-1.9.0/tail_dir.json a3.sources.r3.filegroups = f1 f2 a3.sources.r3.filegroups.f1 = /opt/flume-1.9.0/files/.*file.* a3.sources.r3.filegroups.f2 = /opt/flume-1.9.0/files2/.*log.* # Describe the sink a3.sinks.k3.type = hdfs a3.sinks.k3.hdfs.path = hdfs://node1:8020/flume/upload2/%Y%m%d/%H #上传文件的前缀 a3.sinks.k3.hdfs.filePrefix = upload- #是否按照时间滚动文件夹 a3.sinks.k3.hdfs.round = true #多少时间单位创建一个新的文件夹 a3.sinks.k3.hdfs.roundValue = 1 #重新定义时间单位 a3.sinks.k3.hdfs.roundUnit = hour #是否使用本地时间戳 a3.sinks.k3.hdfs.useLocalTimeStamp = true #积攒多少个 Event 才 flush 到 HDFS 一次 a3.sinks.k3.hdfs.batchSize = 100 #设置文件类型,可支持压缩 a3.sinks.k3.hdfs.fileType = DataStream #多久生成一个新的文件 a3.sinks.k3.hdfs.rollInterval = 60 #设置每个文件的滚动大小大概是 128M a3.sinks.k3.hdfs.rollSize = 134217700 #文件的滚动与 Event 数量无关 a3.sinks.k3.hdfs.rollCount = 0 # Use a channel which buffers events in memory a3.channels.c3.type = memory a3.channels.c3.capacity = 1000 a3.channels.c3.transactionCapacity = 100 # Bind the source and sink to the channel a3.sources.r3.channels = c3 a3.sinks.k3.channel = c3
-
启动监控文件夹命令
bin/flume-ng agent --conf conf/ --name a3 --conf-file job/flume-taildir-hdfs.conf -
向 files 文件夹中追加内容
在/opt/module/flume 目录下创建 files 文件夹
向 upload 文件夹中添加文件
-
查看 HDFS 上的数据
Taildir 说明
Taildir Source 维护了一个 json 格式的 position File,其会定期的往 position File中更新每个文件读取到的最新的位置,因此能够实现断点续传。 Position File 的格式如下:
{"inode":2496272,"pos":12,"file":"/opt/module/flume/files/file1.txt"}
{"inode":2496275,"pos":12,"file":"/opt/module/flume/files/file2.txt"}
注:Linux 中储存文件元数据的区域就叫做 inode,每个 inode 都有一个号码,操作系统用 inode 号码来识别不同的文件,Unix/Linux 系统内部不使用文件名,而使用 inode 号码来识别文件。
3. Flume进阶
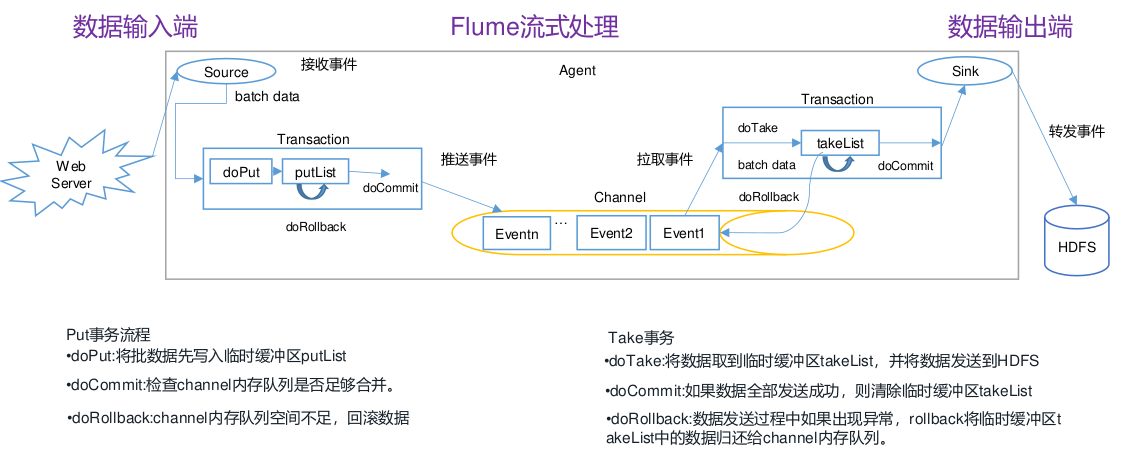
3.1 Flume事务
3.2 Agent内部原理
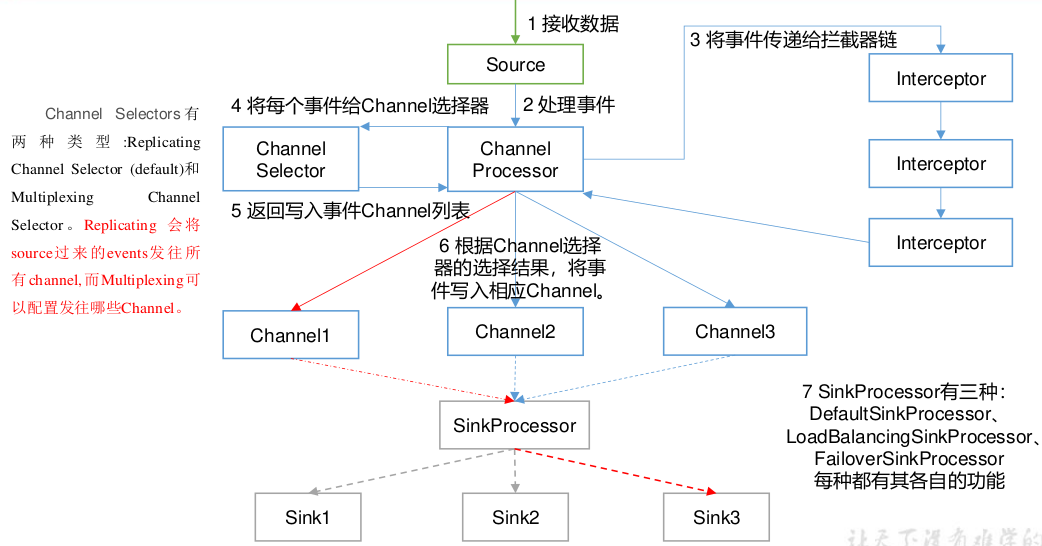
重要组件
1)ChannelSelector:Source发往多个Channel的策略设置
-
ChannelSelector 的作用就是选出 Event 将要被发往哪个 Channel。其共有两种类型,分别是 Replicating(复制)和 Multiplexing(多路复用)。
-
ReplicatingSelector 会将同一个 Event 发往所有的 Channel,Multiplexing 会根据相应的原则,将不同的 Event 发往不同的 Channel。
2)SinkProcessor:Sink发送数据的策略设置
- SinkProcessor共 有 三 种 类 型 , 分 别 是DefaultSinkProcessor 、LoadBalancingSinkProcessor 和 FailoverSinkProcessor
- DefaultSinkProcessor对应的是单个的Sink
- LoadBalancingSinkProcessor 和FailoverSinkProcessor 对应的是 Sink Group
- LoadBalancingSinkProcessor 可以实现负载均衡的功能,FailoverSinkProcessor 可以错误恢复的功能。
3.3 Flume拓扑结构
-
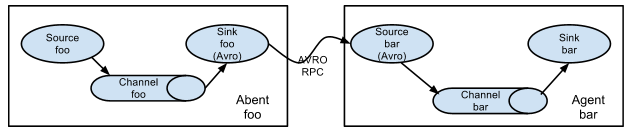
简单串联
这种模式是将多个 flume 顺序连接起来了,从最初的 source 开始到最终 sink 传送的目的存储系统。此模式不建议桥接过多的 flume 数量, flume 数量过多不仅会影响传输速率,而且一旦传输过程中某个节点 flume 宕机,会影响整个传输系统。
-
复制和多路复用
Flume 支持将事件流向一个或者多个目的地。这种模式可以将相同数据复制到多个channel 中,或者将不同数据分发到不同的 channel 中,sink 可以选择传送到不同的目的地。
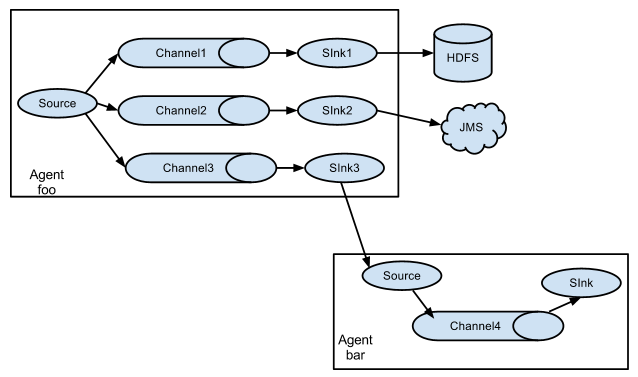
-
负载均衡和故障转移
Flume 支持使用将多个 sink 逻辑上分到一个 sink 组,sink 组配合不同的 SinkProcessor可以实现负载均衡和错误恢复的功能。
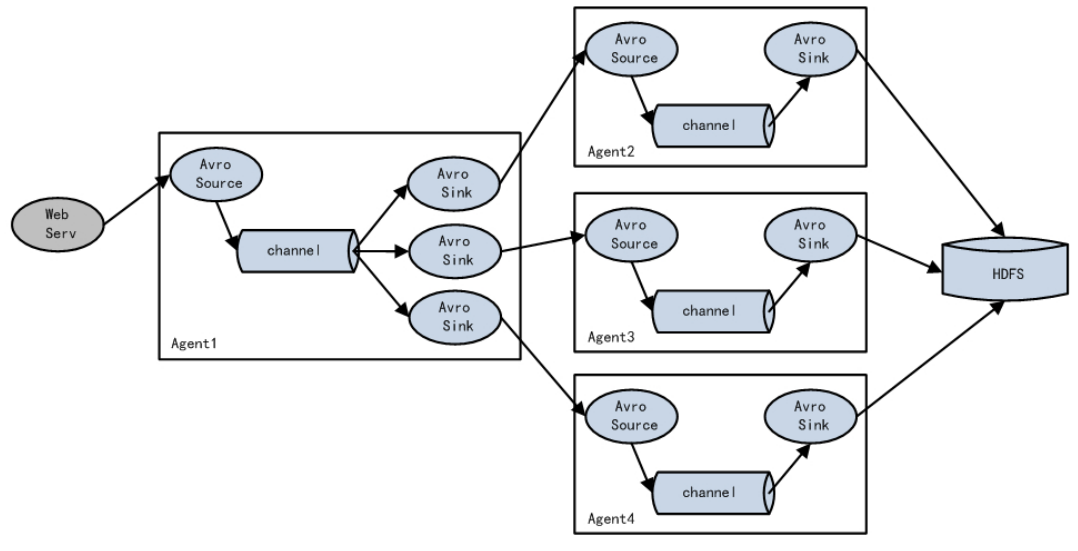
-
聚合
这种模式是我们最常见的,也非常实用,日常 web 应用通常分布在上百个服务器,大者甚至上千个、上万个服务器。产生的日志,处理起来也非常麻烦。用 flume 的这种组合方式能很好的解决这一问题,每台服务器部署一个 flume 采集日志,传送到一个集中收集日志的flume,再由此 flume 上传到 hdfs、hive、hbase 等,进行日志分析。
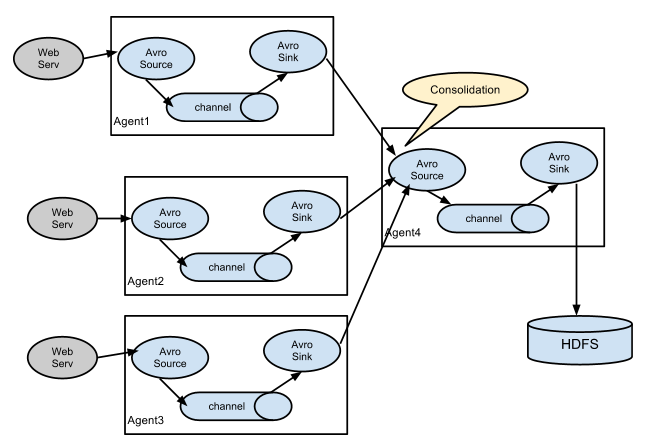
4. Flume企业开发案例
注:使用 jps -ml 查看 Flume 进程。
4.1 复制和多路复用
案例需求
- 使用 Flume-1 监控文件变动,Flume-1 将变动内容传递给 Flume-2,Flume-2 负责存储到 HDFS。同时 Flume-1 将变动内容传递给 Flume-3,Flume-3 负责输出到 LocalFileSystem。
需求分析
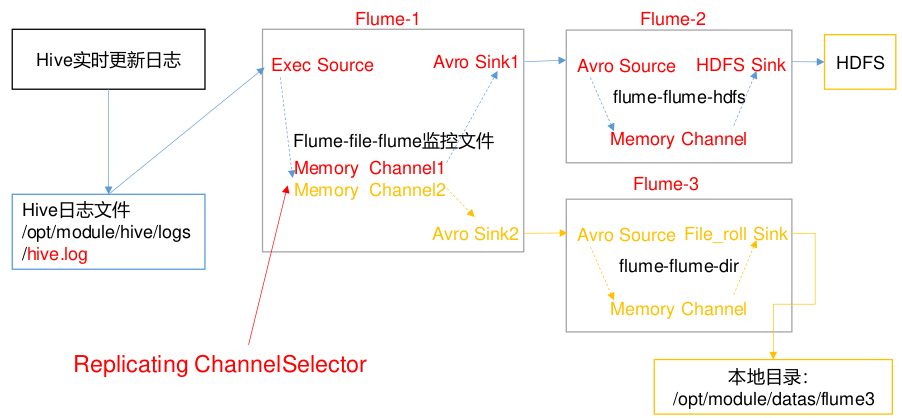
实现步骤
-
准备工作
在job内创建group1文件夹,用于存放配置文件
-
创建flume-file-flume.conf
配置一个接收日志文件的source和两个channel、两个sink,分别输送给hdfs和本地文件
# Name the components on this agent a1.sources = r1 a1.sinks = k1 k2 a1.channels = c1 c2 # 将数据流复制给所有 channel # 默认选择器就是复制,可以不需要 a1.sources.r1.selector.type = replicating # Describe/configure the source a1.sources.r1.type = exec a1.sources.r1.command = tail -F /opt/hive-3.1.3/logs/hive.log a1.sources.r1.shell = /bin/bash -c # Describe the sink # sink 端的 avro 是一个数据发送者 a1.sinks.k1.type = avro a1.sinks.k1.hostname = node1 a1.sinks.k1.port = 4141 a1.sinks.k2.type = avro a1.sinks.k2.hostname = node1 a1.sinks.k2.port = 4142 # Describe the channel a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 a1.channels.c2.type = memory a1.channels.c2.capacity = 1000 a1.channels.c2.transactionCapacity = 100 # Bind the source and sink to the channel a1.sources.r1.channels = c1 c2 a1.sinks.k1.channel = c1 a1.sinks.k2.channel = c2 -
创建 flume-flume-hdfs.conf
配置上级 Flume 输出的 Source,输出是到 HDFS 的 Sink
# Name the components on this agent a2.sources = r1 a2.sinks = k1 a2.channels = c1 # Describe/configure the source # source 端的 avro 是一个数据接收服务 a2.sources.r1.type = avro a2.sources.r1.bind = node1 a2.sources.r1.port = 4141 # Describe the sink a2.sinks.k1.type = hdfs a2.sinks.k1.hdfs.path = hdfs://node1:8020/flume2/%Y%m%d/%H #上传文件的前缀 a2.sinks.k1.hdfs.filePrefix = flume2- #是否按照时间滚动文件夹 a2.sinks.k1.hdfs.round = true #多少时间单位创建一个新的文件夹 a2.sinks.k1.hdfs.roundValue = 1 #重新定义时间单位 a2.sinks.k1.hdfs.roundUnit = hour #是否使用本地时间戳 a2.sinks.k1.hdfs.useLocalTimeStamp = true #积攒多少个 Event 才 flush 到 HDFS 一次 a2.sinks.k1.hdfs.batchSize = 100 #设置文件类型,可支持压缩 a2.sinks.k1.hdfs.fileType = DataStream #多久生成一个新的文件 a2.sinks.k1.hdfs.rollInterval = 30 #设置每个文件的滚动大小大概是 128M a2.sinks.k1.hdfs.rollSize = 134217700 #文件的滚动与 Event 数量无关 a2.sinks.k1.hdfs.rollCount = 0 # Describe the channel a2.channels.c1.type = memory a2.channels.c1.capacity = 1000 a2.channels.c1.transactionCapacity = 100 # Bind the source and sink to the channel a2.sources.r1.channels = c1 a2.sinks.k1.channel = c1 -
创建 flume-flume-dir.conf
配置上级 Flume 输出的 Source,输出是到本地目录的 Sink
# Name the components on this agent a3.sources = r1 a3.sinks = k1 a3.channels = c2 # Describe/configure the source a3.sources.r1.type = avro a3.sources.r1.bind = node1 a3.sources.r1.port = 4142 # Describe the sink a3.sinks.k1.type = file_roll a3.sinks.k1.sink.directory = /opt/data/flume3 # Describe the channel a3.channels.c2.type = memory a3.channels.c2.capacity = 1000 a3.channels.c2.transactionCapacity = 100 # Bind the source and sink to the channel a3.sources.r1.channels = c2 a3.sinks.k1.channel = c2提示:输出的本地目录必须是已经存在的目录,如果该目录不存在,并不会创建新的目录。
-
执行配置文件
要先启动后两个配置文件,因为后两个是第一个配置文件的sink的服务端
bin/flume-ng agent -c conf/ -n a3 -f job/group1/flume-flume-dir.conf bin/flume-ng agent -c conf/ -n a2 -f job/group1/flume-flume-hdfs.conf bin/flume-ng agent -c conf/ -n a1 -f job/group1/flume-file-flume.conf -
启动Hadoop和hive
4.2 负载均衡和故障转移
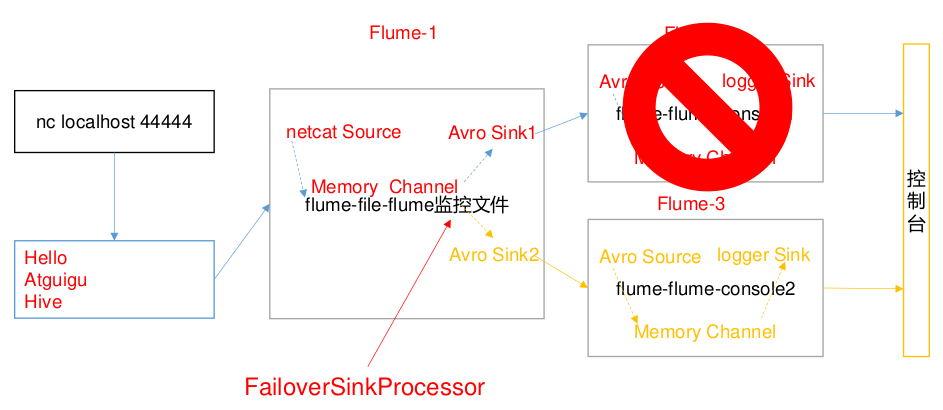
案例需求
- 使用 Flume1 监控一个端口,其 sink 组中的 sink 分别对接 Flume2 和 Flume3,采FailoverSinkProcessor,实现故障转移的功能。
需求分析
实现步骤
-
job 目录下创建 group2 文件夹,用于存放配置文件
-
创建 flume-netcat-flume.conf
配置 1 个 netcat source 和 1 个 channel、1 个 sink group(2 个 sink),分别输送给flume-flume-console1 和 flume-flume-console2
# Name the components on this agent a1.sources = r1 a1.channels = c1 a1.sinkgroups = g1 a1.sinks = k1 k2 # Describe/configure the source a1.sources.r1.type = netcat a1.sources.r1.bind = localhost a1.sources.r1.port = 44444 # 故障转移 a1.sinkgroups.g1.processor.type = failover a1.sinkgroups.g1.processor.priority.k1 = 5 a1.sinkgroups.g1.processor.priority.k2 = 10 a1.sinkgroups.g1.processor.maxpenalty = 10000 # 负载均衡(开启这段就要注释故障转移) # a1.sinkgroups.g1.processor.type = failover # sink拉取数据失败后,下次退避一段时间,默认最大退避时间30s # a1.sinkgroups.g1.processor.backoff = true # Describe the sink a1.sinks.k1.type = avro a1.sinks.k1.hostname = node1 a1.sinks.k1.port = 4141 a1.sinks.k2.type = avro a1.sinks.k2.hostname = node1 a1.sinks.k2.port = 4142 # Describe the channel a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 # Bind the source and sink to the channel a1.sources.r1.channels = c1 a1.sinkgroups.g1.sinks = k1 k2 a1.sinks.k1.channel = c1 a1.sinks.k2.channel = c1 -
创建 flume-flume-console1.conf
配置上级 Flume 输出的 Source,输出是到本地控制台
# Name the components on this agent a2.sources = r1 a2.sinks = k1 a2.channels = c1 # Describe/configure the source a2.sources.r1.type = avro a2.sources.r1.bind = node1 a2.sources.r1.port = 4141 # Describe the sink a2.sinks.k1.type = logger # Describe the channel a2.channels.c1.type = memory a2.channels.c1.capacity = 1000 a2.channels.c1.transactionCapacity = 100 # Bind the source and sink to the channel a2.sources.r1.channels = c1 a2.sinks.k1.channel = c1 -
创建 flume-flume-console2.conf
配置上级 Flume 输出的 Source,输出是到本地控制台
# Name the components on this agent a3.sources = r1 a3.sinks = k1 a3.channels = c1 # Describe/configure the source a3.sources.r1.type = avro a3.sources.r1.bind = node1 a3.sources.r1.port = 4142 # Describe the sink a3.sinks.k1.type = logger # Describe the channel a3.channels.c1.type = memory a3.channels.c1.capacity = 1000 a3.channels.c1.transactionCapacity = 100 # Bind the source and sink to the channel a3.sources.r1.channels = c1 a3.sinks.k1.channel = c1 -
执行配置文件
分别开启对应配置文件: flume-flume-console2, flume-flume-console1, flume-netcat-flume
bin/flume-ng agent -c conf/ -n a3 -f job/group2/flume-flume-console2.conf -Dflume.root.logger=INFO,console bin/flume-ng agent -c conf -n a2 -f job/group2/flume-flume-console1.conf -Dflume.root.logger=INFO,console bin/flume-ng agent -c conf/ -n a1 -f job/group2/flume-netcat-flume.conf -
使用 netcat 工具向本机的 44444 端口发送内容
nc localhost 44444 -
查看 Flume2 及 Flume3 的控制台打印日志
-
将 Flume2 kill,观察 Flume3 的控制台打印情况
4.3 聚合
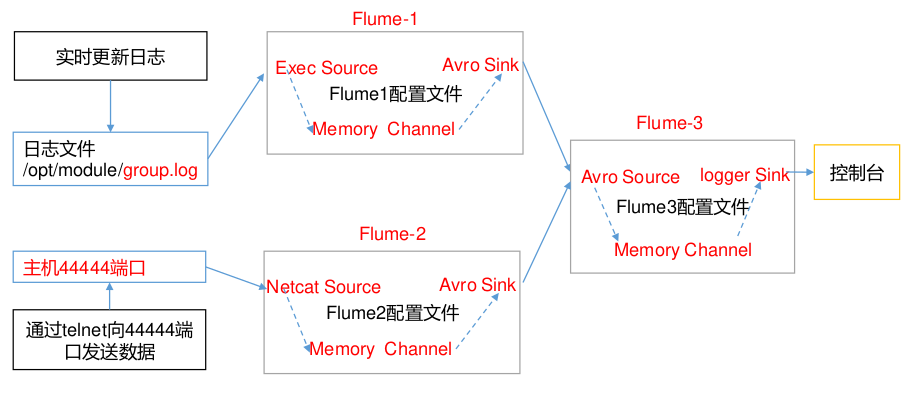
案例需求
-
node1 上的 Flume-1 监控文件/opt/module/group.log
-
node2 上的 Flume-2 监控某一个端口的数据流
-
Flume-1 与 Flume-2 将数据发送给 node3 上的 Flume-3,Flume-3 将最终数据打印到控制台
需求分析
实现步骤
-
准备工作
分发 Flume到node2,node3在 node1、node2 以及 node3 的/XXX/job 目录下创建一个group3 文件夹
-
创建 flume1-logger-flume.conf
配置 Source 用于监控 group.log 文件,配置 Sink 输出数据到下一级 Flume
# Name the components on this agent a1.sources = r1 a1.sinks = k1 a1.channels = c1 # Describe/configure the source a1.sources.r1.type = exec a1.sources.r1.command = tail -F /opt/data/group.log a1.sources.r1.shell = /bin/bash -c # Describe the sink a1.sinks.k1.type = avro a1.sinks.k1.hostname = node3 a1.sinks.k1.port = 4141 # Describe the channel a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 # Bind the source and sink to the channel a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1 -
创建 flume2-netcat-flume.conf
配置 Source 监控端口 44444 数据流,配置 Sink 数据到下一级 Flume# Name the components on this agent a2.sources = r1 a2.sinks = k1 a2.channels = c1 # Describe/configure the source a2.sources.r1.type = netcat a2.sources.r1.bind = node2 a2.sources.r1.port = 44444 # Describe the sink a2.sinks.k1.type = avro a2.sinks.k1.hostname = node3 a2.sinks.k1.port = 4141 # Use a channel which buffers events in memory a2.channels.c1.type = memory a2.channels.c1.capacity = 1000 a2.channels.c1.transactionCapacity = 100 # Bind the source and sink to the channel a2.sources.r1.channels = c1 a2.sinks.k1.channel = c1 -
创建 flume3-flume-logger.conf
配置 source 用于接收 flume1 与 flume2 发送过来的数据流,最终合并后 sink 到控制台# Name the components on this agent a3.sources = r1 a3.sinks = k1 a3.channels = c1 # Describe/configure the source a3.sources.r1.type = avro a3.sources.r1.bind = node3 a3.sources.r1.port = 4141 # Describe the sink a3.sinks.k1.type = logger # Describe the channel a3.channels.c1.type = memory a3.channels.c1.capacity = 1000 a3.channels.c1.transactionCapacity = 100 # Bind the source and sink to the channel a3.sources.r1.channels = c1 a3.sinks.k1.channel = c1 -
执行配置文件
分别开启对应配置文件:flume3-flume-logger.conf,flume2-netcat-flume.conf,flume1-logger-flume.confbin/flume-ng agent -c conf/ -n a3 -f job/group3/flume3-flume-logger.conf -Dflume.root.logger=INFO,console bin/flume-ng agent -c conf/ -n a2 -f job/group3/flume2-netcat-flume.conf bin/flume-ng agent -c conf/ -n a1 -f job/group3/flume1-logger-flume.conf -
在 node1 上向/opt/dara 目录下的 group.log 追加内容
echo 'hello' > group.log -
在node2 上向 44444 端口发送数据
nc node2 44444
5. 自定义组件
5.1 自定义Interceptor
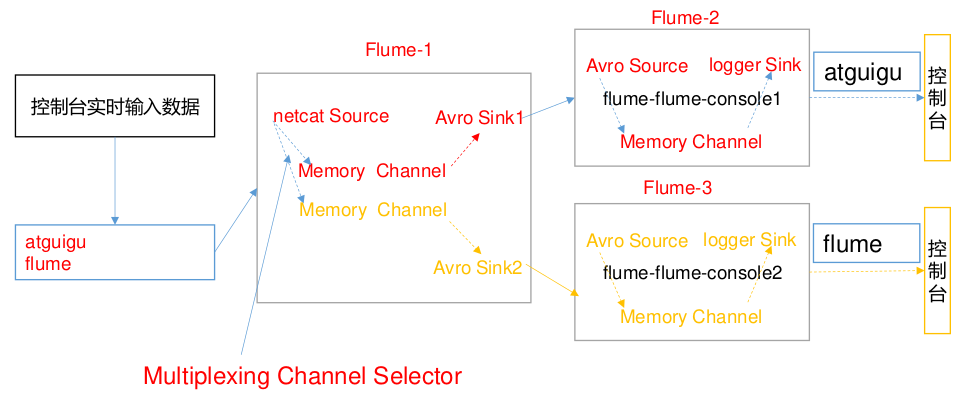
案例需求
- 使用 Flume 采集服务器本地日志,需要按照日志类型的不同,将不同种类的日志发往不同的分析系统。
需求分析
- 在实际的开发中,一台服务器产生的日志类型可能有很多种,不同类型的日志可能需要发送到不同的分析系统。此时会用到 Flume 拓扑结构中的 Multiplexing 结构, Multiplexing的原理是,根据 event 中 Header 的某个 key 的值,将不同的 event 发送到不同的 Channel中,所以我们需要自定义一个 Interceptor,为不同类型的 event 的 Header 中的 key 赋予不同的值。
实现步骤
-
准备工作
创建一个 maven 项目,并引入以下依赖。
<dependency> <groupId>org.apache.flume</groupId> <artifactId>flume-ng-core</artifactId> <version>1.9.0</version> </dependency>定义 CustomInterceptor 类并实现 Interceptor 接口
import org.apache.flume.Context; import org.apache.flume.Event; import org.apache.flume.interceptor.Interceptor; import java.util.ArrayList; import java.util.List; import java.util.Map; public class multiLoads implements Interceptor { //声明一个存放事件的集合 private List<Event> addHeaderEvents; @Override public void initialize() { //初始化存放事件的集合 addHeaderEvents = new ArrayList<>(); } //单个事件拦截 @Override public Event intercept(Event event) { //1.获取事件中的头信息 Map<String, String> headers = event.getHeaders(); //2.获取事件中的 body 信息 String body = new String(event.getBody()); //3.根据 body 中是否有"atguigu"来决定添加怎样的头信息 if (body.contains("atguigu")) { //4.添加头信息 headers.put("type", "atguigu"); } else { //4.添加头信息 headers.put("type", "other"); } return event; } //批量事件拦截 @Override public List<Event> intercept(List<Event> events) { //1.清空集合 addHeaderEvents.clear(); //2.遍历 events for (Event event : events) { //3.给每一个事件添加头信息 addHeaderEvents.add(intercept(event)); } //4.返回结果 return addHeaderEvents; } @Override public void close() { } public static class Builder implements Interceptor.Builder { @Override public Interceptor build() { return new multiLoads(); } @Override public void configure(Context context) { } } } -
编辑配置文件
flume1.conf 放到 node1的group4文件中
配置 1 个 netcat source,1 个 sink group( 2 个 avro sink),并配置相应的 ChannelSelector 和 interceptor
# Name the components on this agent a1.sources = r1 a1.sinks = k1 k2 a1.channels = c1 c2 # Describe/configure the source a1.sources.r1.type = netcat a1.sources.r1.bind = localhost a1.sources.r1.port = 44444 a1.sources.r1.interceptors = i1 a1.sources.r1.interceptors.i1.type = com.flume.multiLoads$Builder a1.sources.r1.selector.type = multiplexing a1.sources.r1.selector.header = type a1.sources.r1.selector.mapping.atguigu = c1 a1.sources.r1.selector.mapping.other = c2 # Describe the sink a1.sinks.k1.type = avro a1.sinks.k1.hostname = node2 a1.sinks.k1.port = 4141 a1.sinks.k2.type=avro a1.sinks.k2.hostname = node3 a1.sinks.k2.port = 4242 # Use a channel which buffers events in memory a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 # Use a channel which buffers events in memory a1.channels.c2.type = memory a1.channels.c2.capacity = 1000 a1.channels.c2.transactionCapacity = 100 # Bind the source and sink to the channel a1.sources.r1.channels = c1 c2 a1.sinks.k1.channel = c1 a1.sinks.k2.channel = c2flume2.conf 放到node2的group4文件夹中
配置一个 avro source 和一个 logger sink
a1.sources = r1 a1.sinks = k1 a1.channels = c1 a1.sources.r1.type = avro a1.sources.r1.bind = node2 a1.sources.r1.port = 4141 a1.sinks.k1.type = logger a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 a1.sinks.k1.channel = c1 a1.sources.r1.channels = c1flume3.conf 放到node3的group4文件夹中
配置一个 avro source 和一个 logger sink
a1.sources = r1 a1.sinks = k1 a1.channels = c1 a1.sources.r1.type = avro a1.sources.r1.bind = node3 a1.sources.r1.port = 4242 a1.sinks.k1.type = logger a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 a1.sinks.k1.channel = c1 a1.sources.r1.channels = c1 -
分别在 node1,node2,node3上启动 flume 进程,注意先后顺序,先node3/node2 再node1
bin/flume-ng agent -c conf/ -n a1 -f job/group4/flume3.conf -Dflume.root.logger=INFO,console bin/flume-ng agent -c conf/ -n a1 -f job/group4/flume2.conf -Dflume.root.logger=INFO,console bin/flume-ng agent -c conf/ -n a1 -f job/group4/flume1.conf -
在 node1 使用 netcat 向 localhost:44444 发送字母和数字
nc localhost 44444
5.2 自定义source
介绍
-
Source 是负责接收数据到 Flume Agent 的组件。Source 组件可以处理各种类型、各种格式的日志数据,包括 avro、thrift、exec、jms、spooling directory、netcat、sequencegenerator、syslog、http、legacy。官方提供的 source 类型已经很多,但是有时候并不能满足实际开发当中的需求,此时我们就需要根据实际需求自定义某些 source。
-
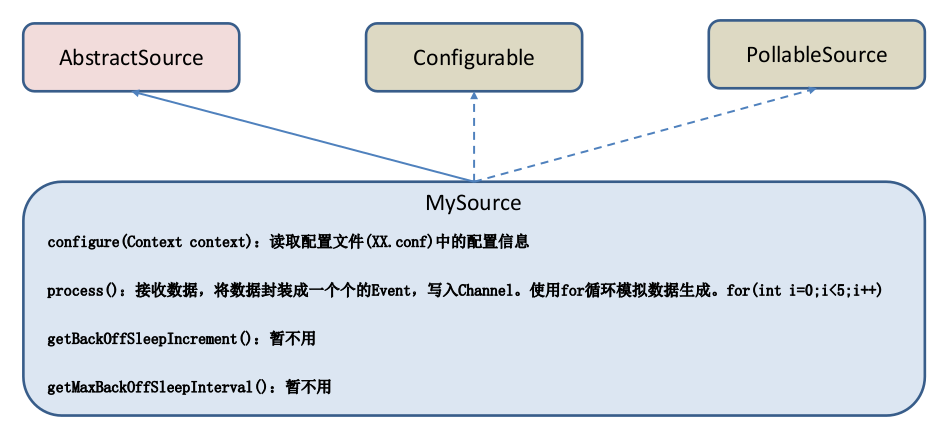
官方也提供了自定义 source 的接口:https://flume.apache.org/FlumeDeveloperGuide.html#source 根据官方说明自定义MySource 需要继承 AbstractSource 类并实现 Configurable 和 PollableSource 接口。
-
实现相应方法:
-
getBackOffSleepIncrement() //backoff 步长
-
getMaxBackOffSleepInterval() //backoff 最长时间
-
configure(Context context)//初始化 context(读取配置文件内容)
-
process()//获取数据封装成 event 并写入 channel,这个方法将被循环调用。
-
-
使用场景:读取 MySQL 数据或者其他文件系统
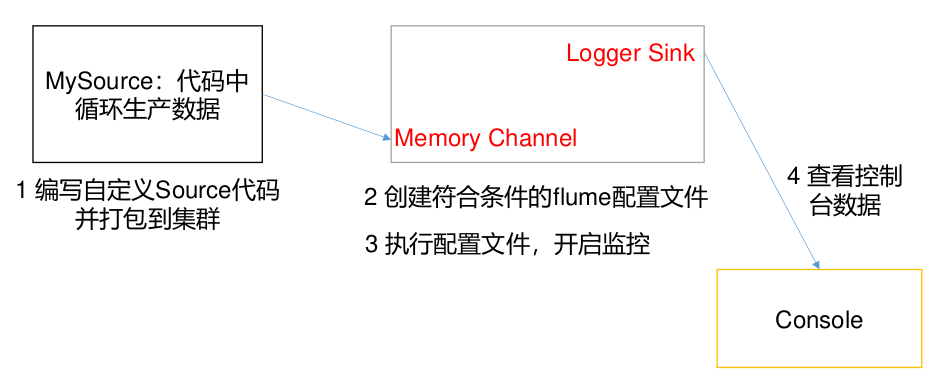
需求
使用 flume 接收数据,并给每条数据添加前缀,输出到控制台。前缀可从 flume 配置文件中配置。
自定义Source需求
编码
-
构建maven项目,导入依赖
<dependency> <groupId>org.apache.flume</groupId> <artifactId>flume-ng-core</artifactId> <version>1.9.0</version> </dependency> -
编写代码
import org.apache.flume.Context; import org.apache.flume.EventDeliveryException; import org.apache.flume.PollableSource; import org.apache.flume.conf.Configurable; import org.apache.flume.event.SimpleEvent; import org.apache.flume.source.AbstractSource; import java.util.HashMap; public class MySource extends AbstractSource implements Configurable, PollableSource { //定义配置文件将来要读取的字段 private Long delay; private String field; //初始化配置信息 @Override public void configure(Context context) { delay = context.getLong("delay"); // 默认值是hello field = context.getString("field", "Hello!"); } @Override public Status process() throws EventDeliveryException { try { //创建事件头信息 HashMap<String, String> hearderMap = new HashMap<>(); //创建事件 SimpleEvent event = new SimpleEvent(); //循环封装事件 for (int i = 0; i < 5; i++) { //给事件设置头信息 event.setHeaders(hearderMap); //给事件设置内容 event.setBody((field + i).getBytes()); //将事件写入 channel getChannelProcessor().processEvent(event); Thread.sleep(delay); } } catch (Exception e) { e.printStackTrace(); return Status.BACKOFF; } return Status.READY; } @Override public long getBackOffSleepIncrement() { return 0; } @Override public long getMaxBackOffSleepInterval() { return 0; } } -
配置文件
打包——将写好的代码打包,并放到 flume 的 lib 目录下
创建配置文件mysource.conf
# Name the components on this agent a1.sources = r1 a1.sinks = k1 a1.channels = c1 # Describe/configure the source # 改写全限定名 a1.sources.r1.type = XXX.XXX.MySource a1.sources.r1.delay = 1000 # 自定义后缀是什么 # a1.sources.r1.field = world # Describe the sink a1.sinks.k1.type = logger # Use a channel which buffers events in memory a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 # Bind the source and sink to the channel a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1 -
开启任务
bin/flume-ng agent -c conf/ -f job/mysource.conf -n a1 -Dflume.root.logger=INFO,console
5.3 自定义sink
介绍
-
Sink 不断地轮询 Channel 中的事件且批量地移除它们,并将这些事件批量写入到存储或索引系统、或者被发送到另一个 Flume Agent。
-
Sink 是完全事务性的。在从 Channel 批量删除数据之前,每个 Sink 用 Channel 启动一个事务。批量事件一旦成功写出到存储系统或下一个 Flume Agent,Sink 就利用 Channel 提交事务。事务一旦被提交,该 Channel 从自己的内部缓冲区删除事件。
-
Sink 组件目的地包括 hdfs、logger、avro、thrift、ipc、file、null、HBase、solr、自定义。官方提供的 Sink 类型已经很多,但是有时候并不能满足实际开发当中的需求,此时我们就需要根据实际需求自定义某些 Sink。
-
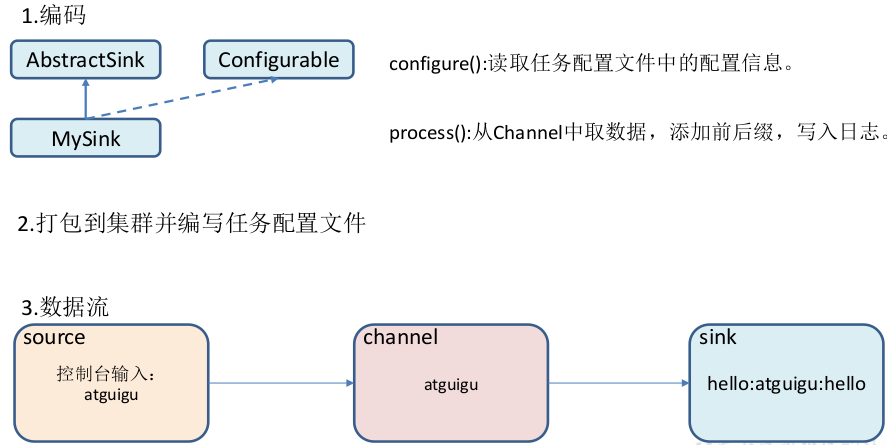
官方也提供了自定义 sink 的接口:https://flume.apache.org/FlumeDeveloperGuide.html#sink 根 据 官 方 说 明自定义MySink 需要继承 AbstractSink 类并实现 Configurable 接口。
-
实现相应方法:
- configure(Context context) //初始化 context(读取配置文件内容)
- process() //从 Channel 读取获取数据(event),这个方法将被循环调用。
-
使用场景:读取 Channel 数据写入 MySQL 或者其他文件系统。
需求
使用 flume 接收数据,并在 Sink 端给每条数据添加前缀和后缀,输出到控制台。前后缀可在 flume 任务配置文件中配置
编写
-
编码
import org.apache.flume.*; import org.apache.flume.conf.Configurable; import org.apache.flume.sink.AbstractSink; import org.slf4j.Logger; import org.slf4j.LoggerFactory; public class MySink extends AbstractSink implements Configurable { //创建 Logger 对象 private static final Logger LOG = LoggerFactory.getLogger(AbstractSink.class); private String prefix; private String suffix; @Override public Status process() throws EventDeliveryException { //声明返回值状态信息 Status status; //获取当前 Sink 绑定的 Channel Channel ch = getChannel(); //获取事务 Transaction txn = ch.getTransaction(); //声明事件 Event event; //开启事务 txn.begin(); //读取 Channel 中的事件,直到读取到事件结束循环 while (true) { event = ch.take(); if (event != null) { break; } } try { //处理事件(打印) LOG.info(prefix + new String(event.getBody()) + suffix); //事务提交 txn.commit(); status = Status.READY; } catch (Exception e) { //遇到异常,事务回滚 txn.rollback(); status = Status.BACKOFF; } finally { //关闭事务 txn.close(); } return status; } @Override public void configure(Context context) { //读取配置文件内容,有默认值 prefix = context.getString("prefix", "hello:"); //读取配置文件内容,无默认值 suffix = context.getString("suffix"); } } -
打包和配置文件
将写好的代码打包,并放到 flume 的 lib 目录
创建配置文件
# Name the components on this agent a1.sources = r1 a1.sinks = k1 a1.channels = c1 # Describe/configure the source a1.sources.r1.type = netcat a1.sources.r1.bind = localhost a1.sources.r1.port = 44444 # Describe the sink a1.sinks.k1.type = XXX.XXX.MySink a1.sinks.k1.prefix = atguigu: a1.sinks.k1.suffix = :atguigu # Use a channel which buffers events in memory a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 # Bind the source and sink to the channel a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1 -
开启任务
bin/flume-ng agent -c conf/ -f job/mysink.conf -n a1 -Dflume.root.logger=INFO,console -
测试
nc localhost 44444
-
关闭进程,ctrl+c进程无法退出
# 先获取进程的pid jps -l # 15445 org.apache.flume.node.Application # 杀死进程 kill -9 15445
6. 事务源码
**Transaction **
public interface Transaction {
enum TransactionState { Started, Committed, RolledBack, Closed }
/**
* <p>Starts a transaction boundary for the current channel operation. If a
* transaction is already in progress, this method will join that transaction
* using reference counting.</p>
* <p><strong>Note</strong>: For every invocation of this method there must
* be a corresponding invocation of {@linkplain #close()} method. Failure
* to ensure this can lead to dangling transactions and unpredictable results.
* </p>
*/
void begin();
/**
* Indicates that the transaction can be successfully committed. It is
* required that a transaction be in progress when this method is invoked.
*/
void commit();
/**
* Indicates that the transaction can must be aborted. It is
* required that a transaction be in progress when this method is invoked.
*/
void rollback();
/**
* <p>Ends a transaction boundary for the current channel operation. If a
* transaction is already in progress, this method will join that transaction
* using reference counting. The transaction is completed only if there
* are no more references left for this transaction.</p>
* <p><strong>Note</strong>: For every invocation of this method there must
* be a corresponding invocation of {@linkplain #begin()} method. Failure
* to ensure this can lead to dangling transactions and unpredictable results.
* </p>
*/
void close();
}
rollback方法的实践方法
protected void doRollback() {
int takes = takeList.size();
synchronized (queueLock) {
Preconditions.checkState(queue.remainingCapacity() >= takeList.size(),
"Not enough space in memory channel " +
"queue to rollback takes. This should never happen, please report");
while (!takeList.isEmpty()) {
// take操作有回滚不会丢失
// 写回原队列
queue.addFirst(takeList.removeLast());
}
// put操作直接清除了,没有回滚,可能会导致丢失
// 但是TAILDIR模式下的put,不会丢失,因为只有成功doCommit才会使得文件的记录信息改变
// netcat会直接丢失
putList.clear();
}
putByteCounter = 0;
takeByteCounter = 0;
queueStored.release(takes);
channelCounter.setChannelSize(queue.size());
}
Commit方法的实践方法
protected void doCommit() throws InterruptedException {
int remainingChange = takeList.size() - putList.size();
if (remainingChange < 0) {
if (!bytesRemaining.tryAcquire(putByteCounter, keepAlive, TimeUnit.SECONDS)) {
throw new ChannelException("Cannot commit transaction. Byte capacity " +
"allocated to store event body " + byteCapacity * byteCapacitySlotSize +
"reached. Please increase heap space/byte capacity allocated to " +
"the channel as the sinks may not be keeping up with the sources");
}
if (!queueRemaining.tryAcquire(-remainingChange, keepAlive, TimeUnit.SECONDS)) {
bytesRemaining.release(putByteCounter);
throw new ChannelFullException("Space for commit to queue couldn't be acquired." +
" Sinks are likely not keeping up with sources, or the buffer size is too tight");
}
}
int puts = putList.size();
int takes = takeList.size();
synchronized (queueLock) {
if (puts > 0) {
while (!putList.isEmpty()) {
if (!queue.offer(putList.removeFirst())) {
throw new RuntimeException("Queue add failed, this shouldn't be able to happen");
}
}
}
putList.clear();
takeList.clear();
}
bytesRemaining.release(takeByteCounter);
takeByteCounter = 0;
putByteCounter = 0;
queueStored.release(puts);
if (remainingChange > 0) {
queueRemaining.release(remainingChange);
}
if (puts > 0) {
channelCounter.addToEventPutSuccessCount(puts);
}
if (takes > 0) {
channelCounter.addToEventTakeSuccessCount(takes);
}
channelCounter.setChannelSize(queue.size());
}
7. Flume优化
7.1 内存调整
调整Flume进程的内存大小,建议设置1G-2G,太小的话会导致频繁GC
jstat -gcutil 15445 1000
# 显示15445java进程,1s的内存变化
S0区 S1区 Eden区 Old区 元空间 YoungGC执行次数 执行时间 FullGC次数 时间 总的GC时间
S0 S1 E O M CCS YGC YGCT FGC FGCT GCT
0.00 0.00 0.00 65.35 95.16 89.45 309440 205.624 3 0.040 205.664
6.25 0.00 0.00 65.35 95.16 89.45 309556 205.690 3 0.040 205.729
6.25 0.00 0.00 65.68 95.16 89.45 309674 205.749 3 0.040 205.788
0.00 6.25 0.00 65.68 95.16 89.45 309790 205.816 3 0.040 205.856
6.25 0.00 0.00 65.76 95.16 89.45 309907 205.881 3 0.040 205.921
0.00 6.25 0.00 66.01 95.16 89.45 310023 205.944 3 0.040 205.984
0.00 6.25 0.00 66.01 95.16 89.45 310139 206.008 3 0.040 206.048
6.25 0.00 0.00 66.01 95.16 89.45 310254 206.074 3 0.040 206.114
0.00 6.25 0.00 66.34 95.16 89.45 310371 206.134 3 0.040 206.174
0.00 6.25 0.00 66.34 95.16 89.45 310488 206.192 3 0.040 206.232
如果YGC执行次数增加的很快,可以适当增加运行内存
修改conf文件夹内的flume-env.sh文件
# Xms是起始内存 Xmx是最大内存
export JAVA_OPTS="-Xms100m -Xmx2000m -Dcom.sun.management.jmxremote"
7.2 日志配置
启动多个Flume进程是,建议修改配置区分日志文件
修改配置多个conf文件夹,并修改的log4.properties文件
运行flume进程时,指定某一个conf文件
# 修改日志记录的级别
flume.root.logger=INFO,LOGFILE
# 修改日志放置的文件,不用改
flume.log.dir=./logs
# 修改日志文件的名称
flume.log.file=flume.log
7.3 Flume进程监控
Flume是一个单进程程序,会存在单点故障,所以需要有一个监控机制,发现Flume进行Down掉之后,需要重启
- 通过Shell脚本实现Flume进程监控以及自动重启
配置文件
molist.conf
# 这里的example名称要保证能用ps -ef | grep example定位到进程
example=startExample.sh
启动脚本
startExample.sh
#!/bin/bash
flume_path=/XXX/XXX
nohup ${flume_path}/bin/flume-ng agent -c ${flume_path}/conf -n a1 -f ${flume_path}/XXX/XXX.conf &
监控脚本
monList.sh
#!/bin/bash
monlist=`cat molist.conf`
echo "===start check==="
for item in ${monlist}
do
# 设置字段分隔符
OLD_IFS=$IFS
IFS="="
# 把一行内容转成多列[数组]
arr=($item)
# 获取等号左边的内容
name=${arr[0]}
# 获取等号右边的内容
script=${arr[1]}
echo "time is:"`date +"%Y-%m-%d %H:%M:%S"`"check"$name
if [ `jps -m|grep $name | wc -l` -eq 0 ]
then
echo `date +"%Y-%m-%d %H:%M:%S"`$name "is none"
sh -x ./${script}
fi
done
可以设置crontab定时调度monlist.sh脚本

 浙公网安备 33010602011771号
浙公网安备 33010602011771号