
树链剖分(学习笔记)
P3384 【模板】重链剖分/树链剖分 - 洛谷
简介:
树剖,也就是树链剖分。跟名字一样,就是将一棵树给剖分成链,这样树上操作就变为了链上的操作,通常树剖常与数据结构(如线段树)出场,这些数据结构用来维护链上信息。所以树剖能让你的代码暴涨 \(1k\) (总之就是非常毒瘤) 。同时它还可以解决 \(lca\) 问题,且码量较少。
前置知识:
3.\(dfs\) 序
概念:
这里主要是以重链剖分为主:
- 重儿子:对于每一个非叶子节点,它的儿子中儿子数量最多的那一个儿子 为该节点的重儿子。
- 轻儿子:对于每一个非叶子节点,它的儿子中 非重儿子 的剩下所有儿子即为轻儿子。
- 重边:连接任意两个重儿子的边叫做重边。
- 轻边:剩下的即为轻边。
- 重链:相邻重边连起来的 连接一条重儿子 的链叫重链。
- 对于叶子节点,若其为轻儿子,则有一条以自己为起点的长度为1的链。
- 每一条重链以轻儿子为起点。
实现:
1.变量声明:
那我们要处理出什么参数:
f[u]\(u\) 节点的父亲节点。d[u]\(u\) 节点的深度。siz[u]以 \(u\) 为根节点的子树大小。son[u]\(u\) 节点的重儿子。top[u]\(u\) 节点所在重链的最上方的节点编号(轻儿子的就是他自己)。id[u]\(u\) 节点在树剖后的链上的编号,也就是 \(dfs\) 序。
2.第一遍 \(dfs\) :
第一遍 \(dfs\) 我们要先预处理出来所有节点的父亲节点,深度,和子树大小,同时找到所有重儿子。
只需要在树上 \(dfs\) 每遍历一个点就给他赋值,在递归遍历其儿子。在遍历完之后该子树大小就所有儿子的子树大小加上一。同是判断大小是否最大,若最大,就将重儿子改为它。
void dfs1(int u,int fa,int depth){
f[u]=fa;
d[u]=depth;
siz[u]=1;
for(auto v:e[u]){
if(v==fa){
continue;
}
dfs1(v,u,depth+1);
siz[u]+=siz[v];
if(siz[v]>siz[son[u]]){
son[u]=v;
}
}
}
3.第二遍 \(dfs\) :
第二遍 \(dfs\) 就要处理出树剖的链了。
同样 \(dfs\) ,但维护一个顶端点编号,这样在 \(dfs\) 时遍历重链时可以修改其 \(top[u]\) 并且给所有点赋值一个新的编号和对应编号的权值。
int cnt;
void dfs2(int u,int t){
top[u]=t;
id[u]=++cnt;
w2[cnt]=w1[u];
if(!son[u]){
return;
}
dfs2(son[u],t);
for(auto v:e[u]){
if(v!=son[u] && v!=f[u]){
dfs2(v,v);
}
}
}
操作:
首先先看看在这样树剖后的树是什么样的:
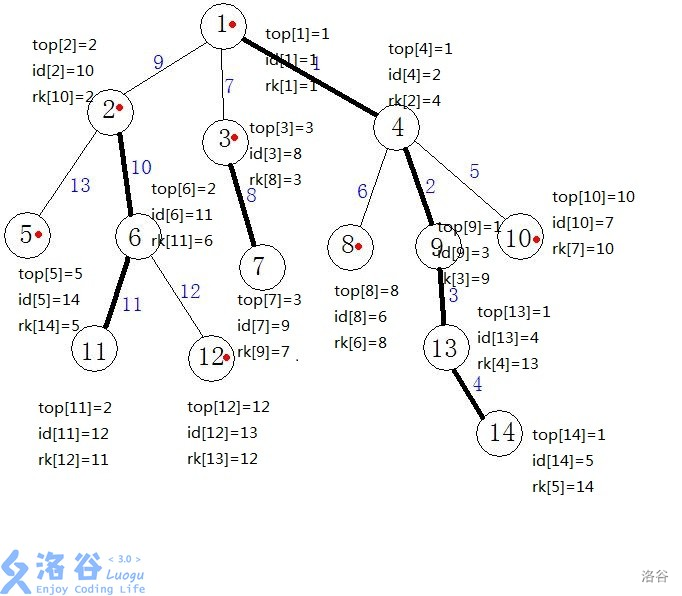
可以发现新编的的号有一下两个性质:
- 一条重链上的编号是连续的。
- 一个子树的编号是连续的。
由于都是连续的,所以我们可以用线段树来维护,这样对树上一条路径和一颗子树的维护就变成了线段树的区间维护。
先随便搓一个区间和的线段树:
#define lc p<<1
#define rc p<<1|1
struct tree{
int sum,lazy;
}tr[4*N];
void push_down(int p,int l,int r){
if(!tr[p].lazy)return;
int mid=(l+r)>>1;
tr[lc].lazy+=tr[p].lazy;
tr[lc].sum+=(mid-l+1)*tr[p].lazy;
tr[rc].lazy+=tr[p].lazy;
tr[rc].sum+=(r-mid)*tr[p].lazy;
tr[lc].sum%=P;
tr[rc].sum%=P;
tr[p].lazy=0;
}
void build(int p,int l,int r){
if(l==r){
tr[p].sum=w2[l]%P;
return;
}
int mid=(l+r)>>1;
build(lc,l,mid);
build(rc,mid+1,r);
tr[p].sum=(tr[lc].sum+tr[rc].sum)%P;
}
void add(int p,int l,int r,int ll,int rr,int k){
if(l>=ll && r<=rr){
tr[p].sum+=(r-l+1)*k;
tr[p].lazy+=k;
tr[p].sum%=P;
return;
}
push_down(p,l,r);
int mid=(l+r)>>1;
if(ll<=mid)add(lc,l,mid,ll,rr,k);
if(rr>mid)add(rc,mid+1,r,ll,rr,k);
tr[p].sum=(tr[lc].sum+tr[rc].sum)%P;
}
int query(int p,int l,int r,int ll,int rr){
if(ll<=l && rr>=r){
return tr[p].sum;
}
push_down(p,l,r);
int mid=(l+r)>>1;
int res=0;
if(ll<=mid)res+=query(lc,l,mid,ll,rr);
if(rr>mid)res+=query(rc,mid+1,r,ll,rr);
res%=P;
return res;
}
那再来分析每个操作
对于操作一:
1 x y z,表示将树从 \(x\) 到 \(y\) 结点最短路径上所有节点的值都加上 \(z\)。我们可以像倍增求 \(lca\) 一样往上跳,根据重链向上跳,知道跳到两个节点所在重链为同一个。跳的时候先跳小的,在跳大的。对于每跳一次,就将该链上的所有节点加 \(z\),及该区间加 \(z\)。最后在修改两点在同一条重链上的位置差。
void addpath(int u,int v,int k){ while(top[u]!=top[v]){ if(d[top[u]]<d[top[v]])swap(u,v); add(1,1,n,id[top[u]],id[u],k); u=f[top[u]]; } if(d[u]>d[v]){ swap(u,v); } add(1,1,n,id[u],id[v],k); }
对于操作二:
2 x y,表示求树从 \(x\) 到 \(y\) 结点最短路径上所有节点的值之和。与操作一相似,都是往上跳,只是改为了查询。
int querypath(int u,int v){ int res=0; while(top[u]!=top[v]){ if(d[top[u]]<d[top[v]])swap(u,v); res+=query(1,1,n,id[top[u]],id[u]); res%=P; u=f[top[u]]; } if(d[u]>d[v])swap(u,v); res+=query(1,1,n,id[u],id[v]); res%=P; return res; }
对于操作三:
3 x z,表示将以 \(x\) 为根节点的子树内所有节点值都加上 \(z\)。对于一颗子树,只需要修改这个子树根节点编号到往后子树大小的区间即可。因为子树的编号是连续的。
void addson(int u,int k){ add(1,1,n,id[u],id[u]+siz[u]-1,k); }
对于操作四:
4 x表示求以 \(x\) 为根节点的子树内所有节点值之和。与操作三一样。
int queryson(int u){ return query(1,1,n,id[u],id[u]+siz[u]-1); }
注意: 例题需要取模,注意取模。
完整代码:
#include<bits/stdc++.h>
#define lc p<<1
#define rc p<<1|1
using namespace std;
const int N=1e5+10;
int P,n,m;
int f[N],d[N],siz[N],son[N],top[N],id[N];
int w1[N],w2[N];
struct tree{
int sum,lazy;
}tr[4*N];
vector<int>e[N];
void dfs1(int u,int fa,int depth){
f[u]=fa;
d[u]=depth;
siz[u]=1;
for(auto v:e[u]){
if(v==fa){
continue;
}
dfs1(v,u,depth+1);
siz[u]+=siz[v];
if(siz[v]>siz[son[u]]){
son[u]=v;
}
}
}
int cnt;
void dfs2(int u,int t){
top[u]=t;
id[u]=++cnt;
w2[cnt]=w1[u];
if(!son[u]){
return;
}
dfs2(son[u],t);
for(auto v:e[u]){
if(v!=son[u] && v!=f[u]){
dfs2(v,v);
}
}
}
void push_down(int p,int l,int r){
if(!tr[p].lazy)return;
int mid=(l+r)>>1;
tr[lc].lazy+=tr[p].lazy;
tr[lc].sum+=(mid-l+1)*tr[p].lazy;
tr[rc].lazy+=tr[p].lazy;
tr[rc].sum+=(r-mid)*tr[p].lazy;
tr[lc].sum%=P;
tr[rc].sum%=P;
tr[p].lazy=0;
}
void build(int p,int l,int r){
if(l==r){
tr[p].sum=w2[l]%P;
return;
}
int mid=(l+r)>>1;
build(lc,l,mid);
build(rc,mid+1,r);
tr[p].sum=(tr[lc].sum+tr[rc].sum)%P;
}
void add(int p,int l,int r,int ll,int rr,int k){
if(l>=ll && r<=rr){
tr[p].sum+=(r-l+1)*k;
tr[p].lazy+=k;
tr[p].sum%=P;
return;
}
push_down(p,l,r);
int mid=(l+r)>>1;
if(ll<=mid)add(lc,l,mid,ll,rr,k);
if(rr>mid)add(rc,mid+1,r,ll,rr,k);
tr[p].sum=(tr[lc].sum+tr[rc].sum)%P;
}
int query(int p,int l,int r,int ll,int rr){
if(ll<=l && rr>=r){
return tr[p].sum;
}
push_down(p,l,r);
int mid=(l+r)>>1;
int res=0;
if(ll<=mid)res+=query(lc,l,mid,ll,rr);
if(rr>mid)res+=query(rc,mid+1,r,ll,rr);
res%=P;
return res;
}
void addpath(int u,int v,int k){
while(top[u]!=top[v]){
if(d[top[u]]<d[top[v]])swap(u,v);
add(1,1,n,id[top[u]],id[u],k);
u=f[top[u]];
}
if(d[u]>d[v]){
swap(u,v);
}
add(1,1,n,id[u],id[v],k);
}
int querypath(int u,int v){
int res=0;
while(top[u]!=top[v]){
if(d[top[u]]<d[top[v]])swap(u,v);
res+=query(1,1,n,id[top[u]],id[u]);
res%=P;
u=f[top[u]];
}
if(d[u]>d[v])swap(u,v);
res+=query(1,1,n,id[u],id[v]);
res%=P;
return res;
}
void addson(int u,int k){
add(1,1,n,id[u],id[u]+siz[u]-1,k);
}
int queryson(int u){
return query(1,1,n,id[u],id[u]+siz[u]-1);
}
int main(){
int r;
scanf("%d%d%d%d",&n,&m,&r,&P);
for(int i=1;i<=n;i++){
scanf("%d",&w1[i]);
}
for(int i=1;i<=n-1;i++){
int x,y;
scanf("%d%d",&x,&y);
e[x].push_back(y);
e[y].push_back(x);
}
dfs1(r,0,1);
dfs2(r,r);
build(1,1,n);
for(int i=1;i<=m;i++){
int op;
scanf("%d",&op);
if(op==1){
int x,y,z;
scanf("%d%d%d",&x,&y,&z);
addpath(x,y,z);
}
if(op==2){
int x,y;
scanf("%d%d",&x,&y);
printf("%d\n",querypath(x,y));
}
if(op==3){
int x,z;
scanf("%d%d",&x,&z);
addson(x,z);
}
if(op==4){
int x;
scanf("%d",&x);
printf("%d\n",queryson(x));
}
}
}
求 \(lca\) :
也是往上跳,跳到同一个重链上, \(lca\) 就是高的那个。
int lca(int u,int v){
while(top[u]!=top[v]){
if(d[top[u]]<d[top[v]])
swap(u,v);
u=f[top[u]];
}
if(depth[u]<depth[v])return u;
return v;
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号