

[CVPR 2017] Semantic Autoencoder for Zero-Shot Learning论文笔记
Semantic Autoencoder for Zero-Shot Learning,Elyor Kodirov Tao Xiang Shaogang Gong,Queen Mary University of London, UK,{e.kodirov, t.xiang, s.gong}@qmul.ac.uk
亮点
- 通过对耦学习提升零次学习系统的性能(类似CycleGan)
- 结构非常简洁,且可直接求解,速度非常快
- 有效应用到其他相关任务(监督聚类)上,证明了范化性能
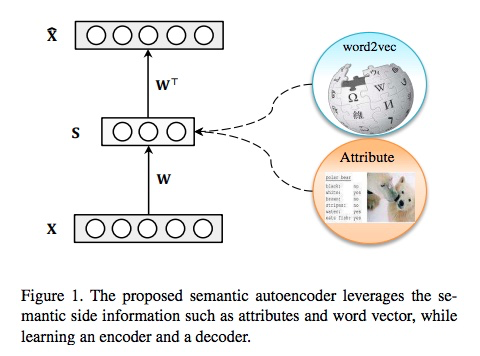
方法
Linear autoencoder

Model Formulation

which is a well-known Sylvester equation which can be solved efficiently by the Bartels-Stewart algorithm (matlab sylvester).
零次学习:基于以上算法有两种测试的方法:
- 将一个未知的类别特征样本xi通过W映射到语义空间(属性)si,通过比较语义空间的距离找到离它最近的类别(无训练样本),即为它的标签
- 将所有无训练数据类别的语义特征S通过WT映射到特征空间X,通过比较一个未知类别的样本xi和映射到特征空间的类别中心X的距离,找到离它最近的类别,即为它的标签
- 以上两种算法得到结果的准确度基本相同。
监督聚类:在这个问题中,语义空间即为类别标签空间(one-hot class label)。所有测试数据被影射到训练类别标签空间,然后使用k-means聚合
与已有模型的关系:零度学习已有模型一般学习一个满足以下条件的影射:
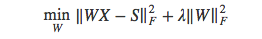
或者,在[54]中将属性影射到特征空间,学习目标变为,
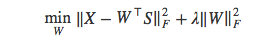
文中的算法结合了这两者,而且由于W*=WT,在对耦学习中W不可能太大(否则,x乘以两个范数很大的的矩阵无法恢复原来的初始值),正则化项可以被忽略。
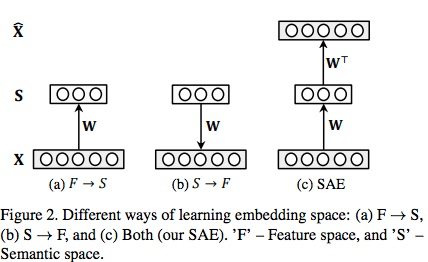
实验
零次学习
数据集:Semantic word vector representation is used for large-scale datasets (ImNet-1 and ImNet-2). We train a skip-gram text model on a corpus of 4.6M Wikipedia documents to obtain the word2vec2 [38, 37] word vectors.
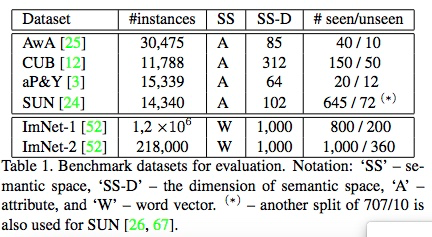
特征:除 ImNet-1用AlexNet提取外,其他均使用了GoogleNet
结果:
- Our SAE model achieves the best results on all 6 datasets.
- On the smallscale datasets, the gap between our model’s results to the strongest competitor ranges from 3.5% to 6.5%.
- On the large-scale datasets, the gaps are even bigger: On the largest ImNet-2, our model improves over the state-of-the-art SS-Voc [22] by 8.8%.
- Both the encoder and decoder projection functions in our SAE model (SAE (W) and SAE (WT) respectively) can be used for effective ZSL.
- The encoder projection function seems to be slightly better overall.
- Measures how well a zero-shot learning method can trade-off between recognising data from seen classes and that of unseen classes
- Holding out 20% of the data samples from the seen classes and mixing them with the samples from the unseen classes.
- On AwA, our model is slightly worse than the SynCstruct [13].
- However, on the more challenging CUB dataset, our method significantly outperforms the competitors.
聚类
数据集: A synthetic dataset and Oxford Flowers-17 (848 images)
结果:
- On computational cost, our model (93s) is more expensive than MLCA (39%) but much better than all others (hours~days).
- Achieves the best clustering accuracy


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通