

[CVPR2017] Visual Translation Embedding Network for Visual Relation Detection 论文笔记
http://www.ee.columbia.edu/ln/dvmm/publications/17/zhang2017visual.pdf
Visual Translation Embedding Network for Visual Relation Detection Hanwang Zhang† , Zawlin Kyaw‡ , Shih-Fu Chang† , Tat-Seng Chua‡ †Columbia University, ‡National University of Singapore
亮点
- 视觉关系预测问题的分析与化简:把一种视觉关系理解为在特征空间从主语到宾语的一种变换,很有效、很直白
- 实验设计的很棒,从多角度进行了分析对比:语言空间划分,多任务对物体检测的提升,零次学习等。
现有工作
- Mature visual detection [16, 35]
- Burgeoning visual captioning and question answering [2, 4]
- directly bridge the visual model (e.g., CNN) and the language model (e.g., RNN), but fall short in modeling and understanding the relationships between objects.
- poor generalization ability
- Visual Relation Detection: a visual relation as a subject-predicate-object triplet
- joint models, a relation triplet is considered as a unique class [3, 9, 33, 37].
- the long-tailed distribution is an inherent defect for scalability.
- separate model
- modeling the large visual variance of predicates is challenging.
- language priors to boost relation detection
主要思想
Translation Embedding 视觉关系预测的难点主要是:对于N个物体和R种谓语,有N^2R种关系,是一个组合爆炸问题。解决这个问题常用的办法是:
- 估计谓语,不估计关系,缺点:对于不同的主语、宾语,图像视觉差异巨大
受Translation Embedding (TransE) 启发,文章中将视觉关系看作在特征空间上从主语到宾语的一种映射,在低维空间上关系元组可看作向量变换,例如person+ride ≈ bike.
Knowledge Transfer in Relation 物体的识别和谓语的识别是互惠的。通过使用类别名、位置、视觉特征三种特征和端对端训练网络,使物体和谓语之前的隐含关系在网络中能够学习到。
算法
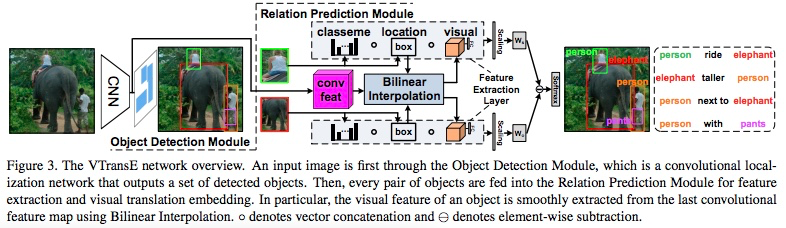
Visual Translation Embedding

Loss function

Feature Extraction Layer
classname + location + visual feature 不同的特征对不同的谓语(动词、介词、空间位置、对比)都有不一样的作用
Bilinear Interpolation
In order to achieve object-relation knowledge transfer, the relation error should be back-propagated to the object detection network and thus refines the objects. We replace the RoI pooling layer with bilinear interpolation [18]. It is a smooth function of two inputs:

结果
Translation embeding: +18%
object detection +0.6% ~ 0.3%
State-of-art:
- Phrase Det. +3% ~ 6%
- Relation Det. +1%
- Retrieval -1% ~ 2%
- Zero-shot phrase detection
- Phrase Det. -0.7% (without language prior)
- Relation Det. -1.4%
- Retrieval +0.2%
问题
- 两个物体之间可能有多种关系,比如person ride elephant,同时也存在person short elephant但是文章中的方法无法表示多样化的关系
- 没有使用语言先验知识,使用多模态信息可能会有所提升


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通