数据库设计
1.数据规范化
1.1什么是范式?
建立科学的,规范的数据库就需要满足一些规则来优化数据的设计和存储,这些规则就成为范式。
1.2三大范式
第一范式(1NF):第一范式每一列不可再拆分,成为原子性。
第二范式(2NF):第二范式就是在满足第一范式的基础上所有列完全依赖于主键列,
第三范式(3NF):第三范式就是满足第二范式的前提下,表中的每一列都直接依赖于主键,而不是通过其他的列来间接依赖于主键。
DQL:查询语句
1.排序查询
order by 排序字段1 排序方式1,排序字段2 排序方式2
升序:ASC (默认的)
降序:DESC
2.聚合函数:将一列数据作为一个整体,进项纵向的计算
count:计算个数 count(*)
Max:计算最大值
Min:计算最小值
sum:计算和
avg:计算平均值
注意:聚合函数的计算,排除null值 (解决方案 IFNULL函数)
3.分组查询
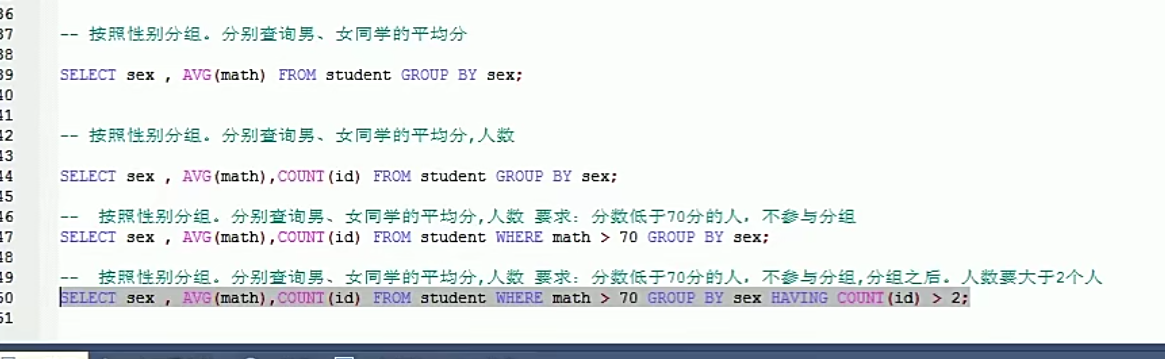
group by 分组字段;
where 和having的区别?
(1)where在分组之前进行限定,如果不满足条件,则不参与分组。having在分组之后进行限定,如果不满足条件,则不会被查询出来
(2)where后不可以跟聚合函数,having后面可以进行聚合函数的判断。
4.分页查询
limit 开始的索引,每页查询的条数;
公式:开始的索引=(当前的页码-1)*每页显示的条数
约束:


数据库的备份和还原:
1.命令行
备份:mysqldump -u用户名 -p密码 数据库 >保存的路径
还原:登录,创建,使用,执行文件 (source 文件路径)
多表查询和事务:
多表查询分为内连接,内连接分为隐式内连接,显示内连接
外连接查询 :左外连接,右外连接
子查询
内连接
//查询员工表的名称,性别。部门表的名称
隐式内连接:SELECT
t1.name
t1.gender
t2.name
FROM
emp t1,
dept t2,
WHERE t1.'dept_id'=t2.'id'
显示内连接
SELECT 字段列表 from 表名1 {inner} join 表名2 on条件
内连接查询注意:
1.从哪些表中查询数据
2.条件是什么
3.查询哪些字段
外连接
1.左外连接
select 字段列表 from 表1 left join 表2 on 条件
查询的是左表所有数据以及其交集部分
2.右外连接
select 字段列表 from 表1 right join 表2 on 条件
查询的是右表所有数据以及其交集部分
子查询


模糊查询的4中用法:
1,%:表示任意0个或多个字符。可匹配任意类型和长度的字符,有些情况下若是中文,请使用两个百分号(%%)表示。
比如 SELECT * FROM [user] WHERE u_name LIKE '%三%'
将会把u_name为“张三”,“张猫三”、“三脚猫”,“唐三藏”等等有“三”的记录全找出来。
另外,如果需要找出u_name中既有“三”又有“猫”的记录,请使用and条件
SELECT * FROM [user] WHERE u_name LIKE '%三%' AND u_name LIKE '%猫%'
若使用 SELECT * FROM [user] WHERE u_name LIKE '%三%猫%'
虽然能搜索出“三脚猫”,但不能搜索出符合条件的“张猫三”。
2,_: 表示任意单个字符。匹配单个任意字符,它常用来限制表达式的字符长度语句:
比如 SELECT * FROM [user] WHERE u_name LIKE '_三_'
只找出“唐三藏”这样u_name为三个字且中间一个字是“三”的;
再比如 SELECT * FROM [user] WHERE u_name LIKE '三__'; 只找出“三脚猫”这样name为三个字且第一个字是“三”的;
3,[ ]:表示括号内所列字符中的一个(类似正则表达式)。指定一个字符、字符串或范围,要求所匹配对象为它们中的任一个。
比如 SELECT * FROM [user] WHERE u_name LIKE '[张李王]三' 将找出“张三”、“李三”、“王三”(而不是“张李王三”);
如 [ ] 内有一系列字符(01234、abcde之类的)则可略写为“0-4”、“a-e”
SELECT * FROM [user] WHERE u_name LIKE '老[1-9]' 将找出“老1”、“老2”、……、“老9”;
4,[^ ] :表示不在括号所列之内的单个字符。其取值和 [] 相同,但它要求所匹配对象为指定字符以外的任一个字符。
比如 SELECT * FROM [user] WHERE u_name LIKE '[^张李王]三' 将找出不姓“张”、“李”、“王”的“赵三”、“孙三”等;
SELECT * FROM [user] WHERE u_name LIKE '老[^1-4]'; 将排除“老1”到“老4”,寻找“老5”、“老6”、……
事务
1.事务的基本介绍
概念:如果一个包含多个步骤的业务操作,被事务管理,那么这些操作要么同时成功,要么同时失败
操作:(1)开启事务:start transaction;
(2)回滚:rollback;
(3)提交:commit;
示例:
4.Mysqi数据库中事务默认自动提交

2.事务的四大特征
* 原子性:是不可分割的最小操作单位,要么同时成功,要么同时失败
* 持久性:当事务提交或回滚后,数据库会持久化的保存数据
* 隔离性:多个事务之间,相互独立
* 一致性:事务操作前后,数据总量不变
3.事务的隔离级别
概念:*概念∶多个事务之间隔离的,相互独立的。但是如果多个事务操作同一批数据,则会引发一些问题,设置不同的隔离级别就可以解决这些问题。
*存在问题:1.脏读:一个事务,读取到另一个事务中没有提交的数据
2.不可重复读(虚读):在同一个事务中,两次读取到的数据不一样。
3.3.幻读∶一个事务操作(DNL)数据表中所有记录,另一个事务添加了一条数据,则第一个事务查询不到自己的修改。
*隔离级别∶1. read uncommitted :读未提交 *产生的问题:脏读、不可重复读、幻读
2. read committed !读已提交(oracle)*产生的问题:不可重复读、幻读
3. repeatable read :可重复读(MysQL默认)*产生的问题:幻读
4. serializable :串行化 *可以解决所有的问题
*注意:隔离级别从小到大安全性越来越高,但是效率越来越低
*数据库查询隔离级别∶select @@tx_isolation;
*数据库设置隔离级别∶*set global transaction isolation level级别字符串;



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· Docker 太简单,K8s 太复杂?w7panel 让容器管理更轻松!