[翻译] Kubernetes 101: Pods, Nodes, Containers, and Clusters
[翻译] Kubernetes 101: Pods, Nodes, Containers, and Clusters
Kubernetes 正迅速成为在云中部署和管理软件的新标准, Kubernetes 的功能虽然很强大。也学习难度同样也很大,作为一个新手,如果直接去看官方的文档, 可能会觉得很难理解。 kubernetes 由许多不同的部分组成,很难判断哪些部分与您的用例相关,这篇博文将提供一个 Kubernetes 的简化视图,它将尝试站在一个比较高的角度对 kubernetes 最重要的一些组件 (components) 以及它们如何组合在一起的做一个概述。
首先,让我们看看硬件 (hardware) 是如何表示的
Hardware
nodes
tes.png)
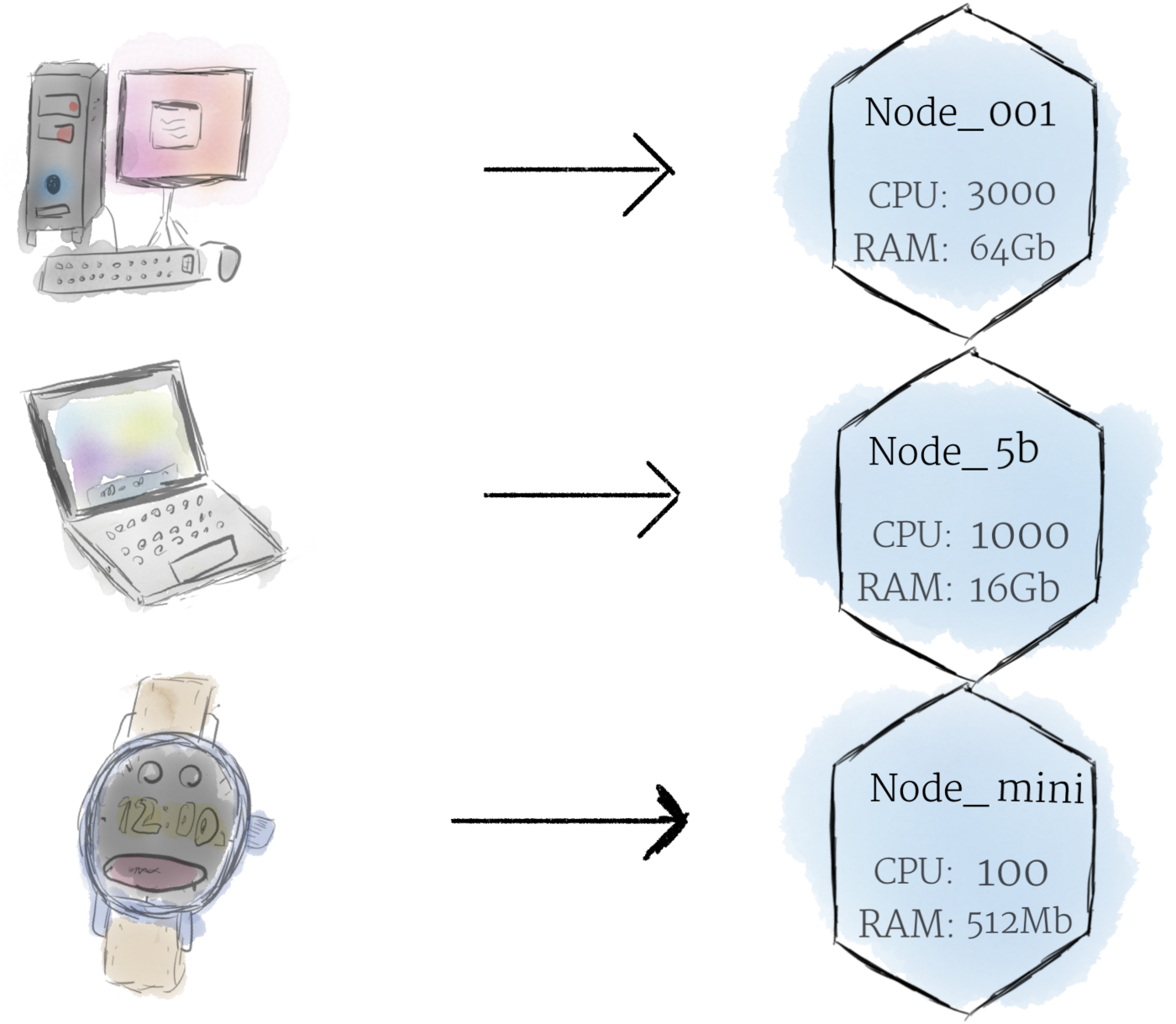
Node 是 Kubernetes 中计算硬件的最小单位。 它代表集群中的一台机器。在大多数生产系统中,Node 可能是数据中心中的物理机,也可能是托管在 Google Cloud Platform 等云提供商上的虚拟机。理论上,你可以用几乎任何东西制作一个 Node。
Node 我们对机器 (machine) 的一层抽象。现在,我们不必关系任何一台机器的独特特性,可以简单地将每台机器视为一组可以利用的 CPU 和 RAM 资源。 这样, Kubernetes 集群中的任何机器都可以被其他机器所取代。
The Cluster
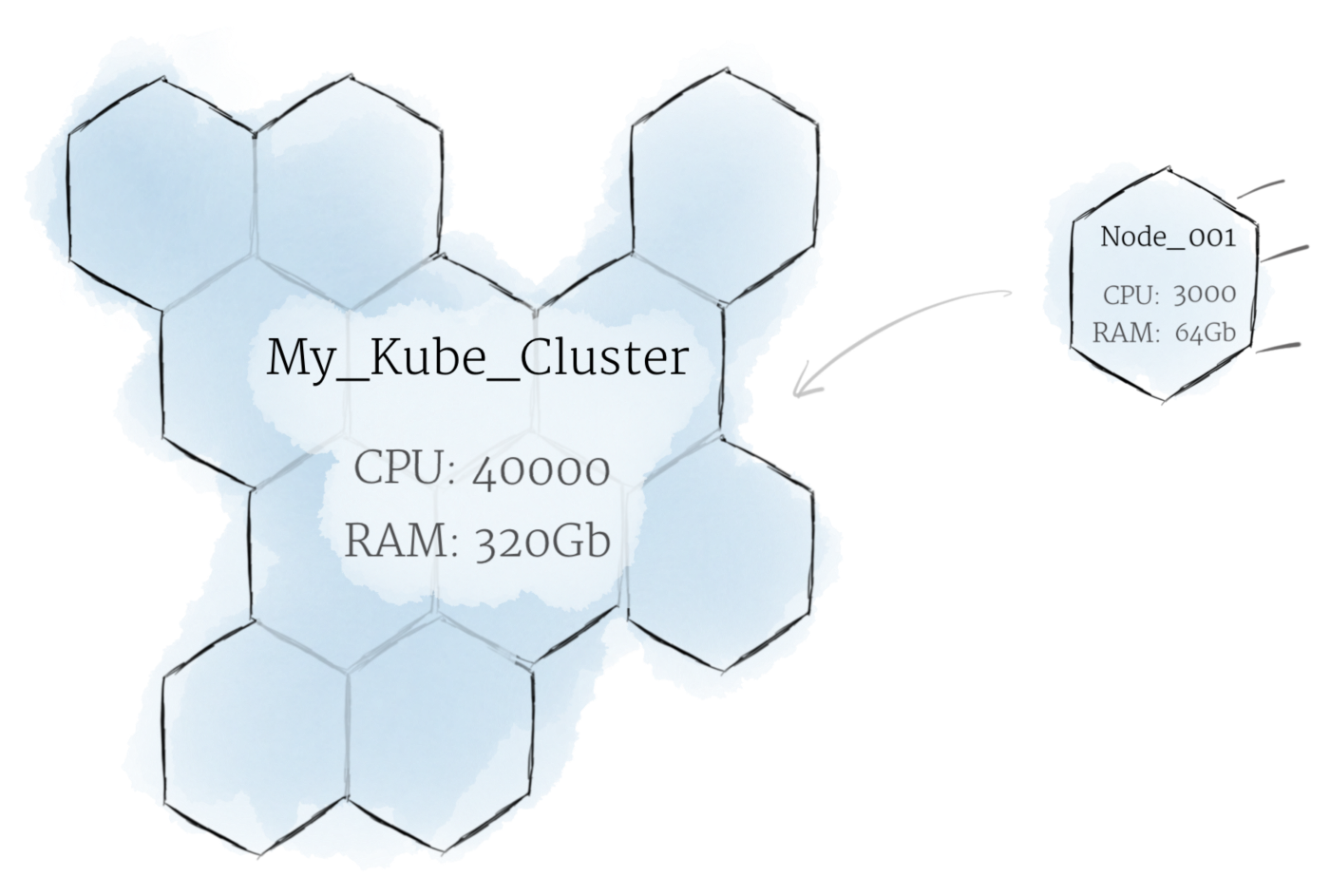
尽管使用单个 node 可能就够了,但这不是 Kubernetes 的方式。 一般来说,您应该将 cluster 视为一个整体,而不是担心单个 node 的状态。
在 Kubernetes 中,node 将它们的资源集中在一起以形成一个更强大的机器。 当您将程序部署到 cluster上时,Kubernetes 会智能地为您将工作分配到各个 node。 如果添加或删除任何 node,cluster 将根据需要来调整工作。 对于程序或程序员来说,不需要关心代码到底在那台机器上执行。
这种类似蜂巢的系统可能会让您想起《星际迷航》中的 Borg, 事实上, Borg 正是 Kubernetes 所基于的内部 Google 项目的名称。
Persistent Volumes
因为在 cluster 上运行的程序不能保证在特定 node 上运行,所以无法将数据保存到某个 node 的文件系统中。如果某个 program 尝试将数据保存到某个文件以备后用,但随后这个 program 被发配到新的 node 上去执行,则该文件将不再位于这个 program 预期的位置。为此,与 node 相关联的传统本地存储只能充当数据的临时缓存,而不能被用于持久化数据。
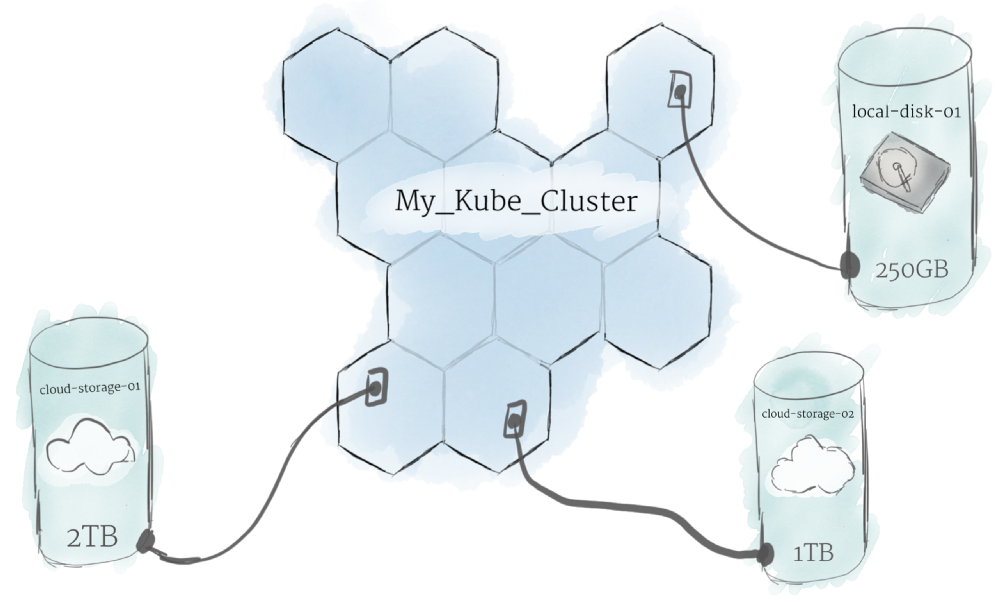
Kubernetes 使用 Persistent Volumes 来持久化数据。 虽然所有 node 的 CPU 和 RAM 资源都由 cluster 有效地汇集和管理,但 persistent file storage 不是。 相反,local or cloud driver 可以作为 Persistent Volume 附加到集群。 这个过程类似于将外部硬盘驱动器插入 cluster。 Persistent Volumes 提供了一个可以 mount 到 cluster 的文件系统,而无需与任何特定 node 相关联。
Software
Containers
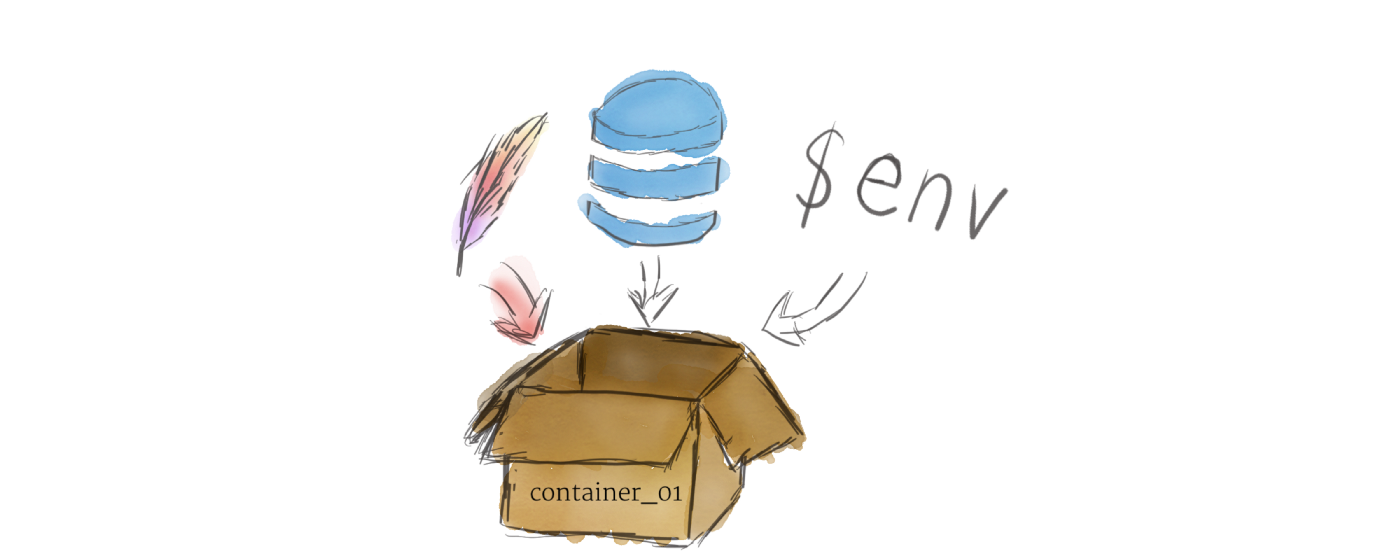
在 Kubernetes 上运行的程序被打包为 Linux Containers。 Container 是一个被广泛接受的标准,因此已经有许多预构建的 image 可以部署在 Kubernetes 上。
Containerization (容器化) 允许您创建 self-contained 的 Linux 执行环境。 任何程序及其所有依赖项都可以捆绑到一个文件中,然后在互联网上共享。 任何人都可以下载 container 并将其部署在他们的基础设施上。并且可以通过编程的方式创建 container,从而形成强大的 CI 和 CD pipeline。
可以将多个程序添加到单个 container 中,但如果可以,最好每个 container 只执行一个进程。 有许多小的 container 比一个大的 container 要好。 如果每个 container 都有一个紧密的焦点,更新就会更容易部署,问题也更容易诊断。
Pods
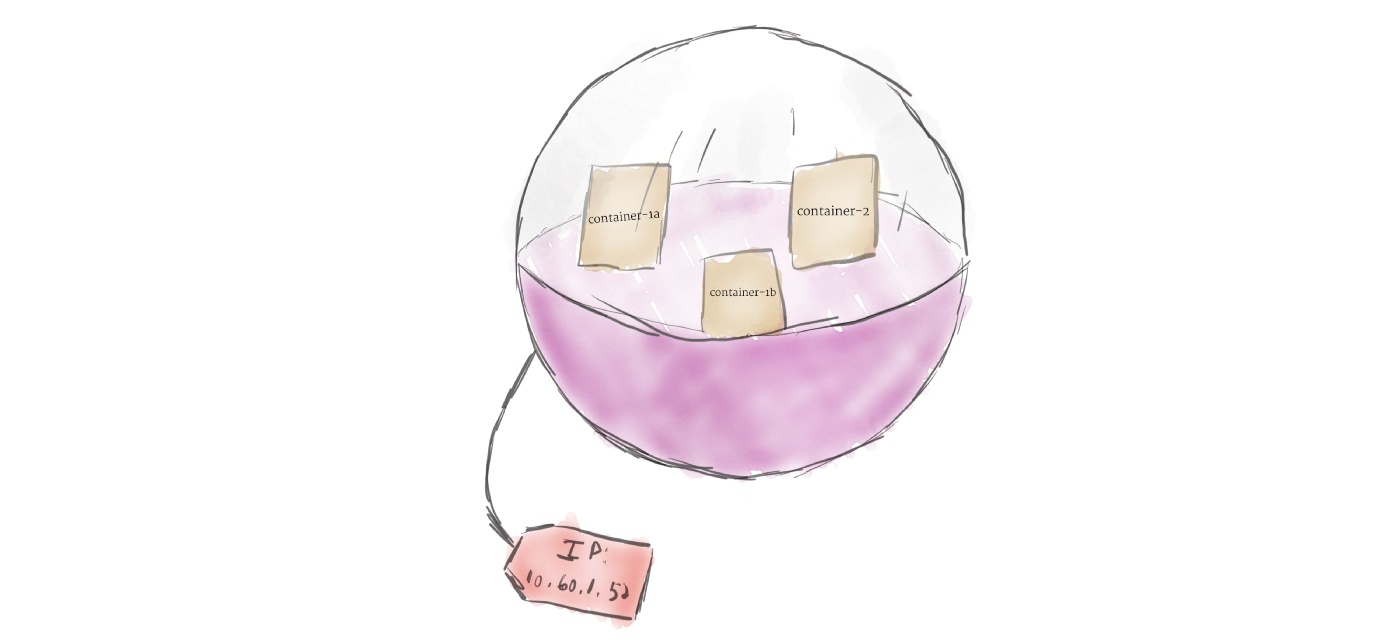
与您过去可能使用过的其他系统不同,Kubernetes 不直接运行 container; 相反,它将一个或多个 container 包装到一个称为 pod 的更高级别的结构中。 同一个 Pod 中的任何 container 都将共享相同的 resource 和 local network。 同一 Pod 中的不同 container 可以互相通信,就像它们在同一台机器上一样,同时保持与其他容器的隔离度。
Pod 是 Kubernetes 中的 unit of replication (复制单元)。 如果您的应用程序变得太流行以至于单个 Pod 实例无法承载负载,则可以配置 Kubernetes 以根据需要将 Pod 的 replicas 部署到集群。 即使在没有高负载的情况下,在生产系统中, 也应该运行多个 pod 副本,以实现负载平衡和故障抵抗。
Pod 可以容纳多个 container ,但您应该尽可能限制自己。 由于 Pod 是动态伸缩 (scaled up and down) 的基本单元 ,因此 Pod 中的所有 container 都必须一起扩展。 这会导致资源浪费和昂贵的账单。 因此,pods 应该尽可能小,通常只包含一个主进程及其紧密耦合的辅助 containers (这些辅助 containers 通常被称为“side-cars”)
Deployments
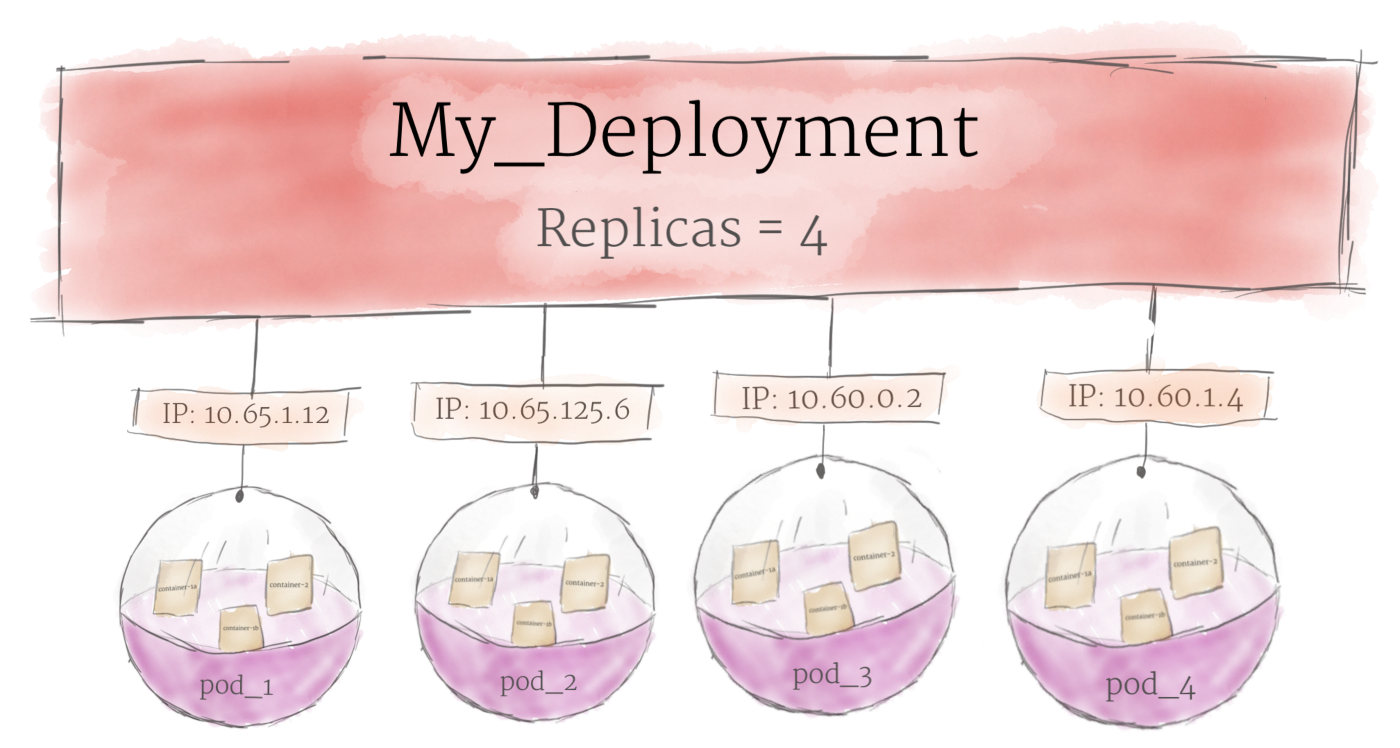
尽管 Pod 是 Kubernetes 中的基本计算单元,但它们通常不会直接在 cluster 上启动。 相反,Pod 通常由另外一层抽象来管理:Deployment。
Deployment 的主要功能是声明在同一时刻, 应该运行的 Pod 副本的数量。 当一个 Deployment 被添加到 cluster 中时,它会自动启动指定数量的 pod,然后监控它们。 如果某个 pod 挂了,Deployment 将自动重新创建一个新的 Pod。
使用 Deployment 后,就不用需要我们手动处理 Pod 了。 只需声明系统所期望的状态,Deployment 就会自动为您管理。
Ingress
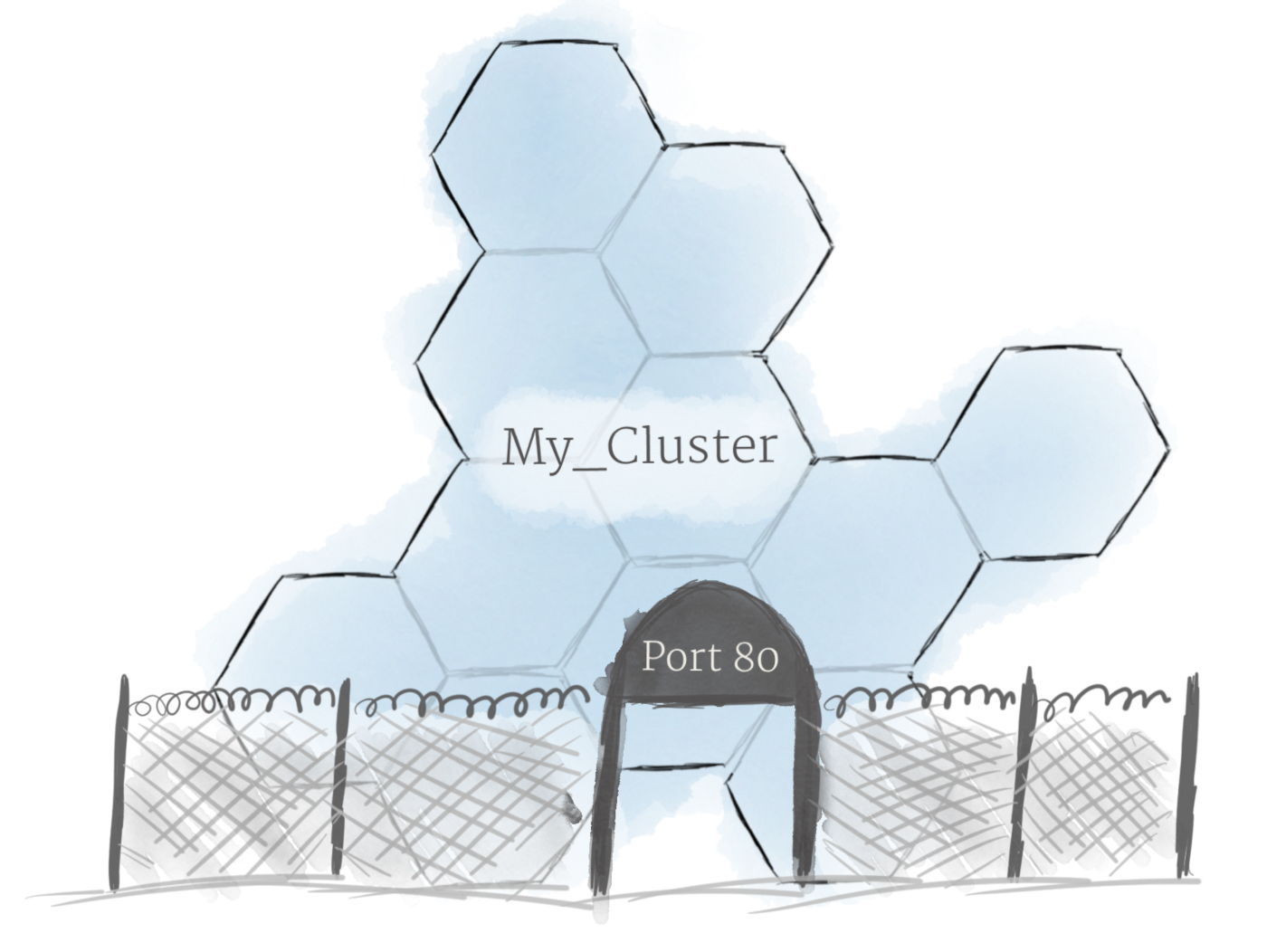
在知道上述的概念后,就可以创建 node cluster,并将 Pod 部署到 cluster 上了。 然而,还有最后一个问题需要解决:允许外部流量进入您的应用程序。
默认情况下,Kubernetes 对 Pod 和外部世界进行了隔离。 如果要与运行在 Pod 中的服务进行通信,则必须开辟通信通道。 这被称为 Ingress。
有多种方法可以将 Ingress 添加到您的 cluster。 最常见的方法是添加 Ingress Controller 或 LoadBalancer。 这两个选项之间该如何权衡超出了本文的范围,但您必须意识到 Ingress 是您在试验 Kubernetes 之前需要处理的事情。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号