

python爬取入门——爬取中技网技术需求并存储入mysql数据库
一、打开中技网网站
右键检查,找到可以进入二级网页即各个需求详情的入口,如图
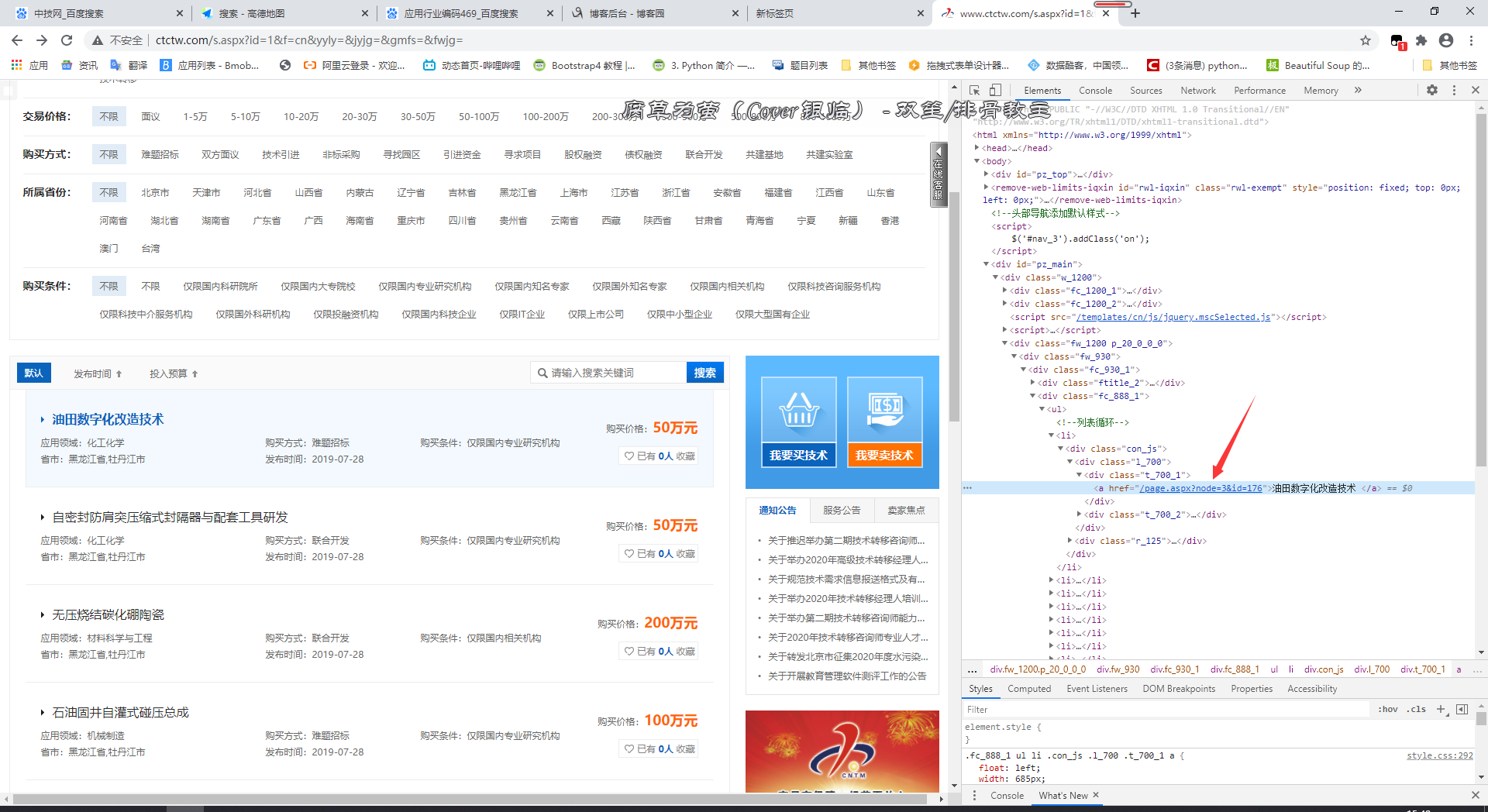
通过观察发现,这些二级网址包含在class名为con_js的div中,而里面只有一个a标签,因而可以用BeautifulSoup中soup.find_all(class_='conjs')获取这些div,然后遍历直接获取a标签的href属性,即soup[i].a['href']
二、进入详情网页
可以发现我们要爬的大部分信息都在class=ft_886_1这个div中,根据每个标签的class寻找即可,详细介绍在第一个class为ft_930_2的标签中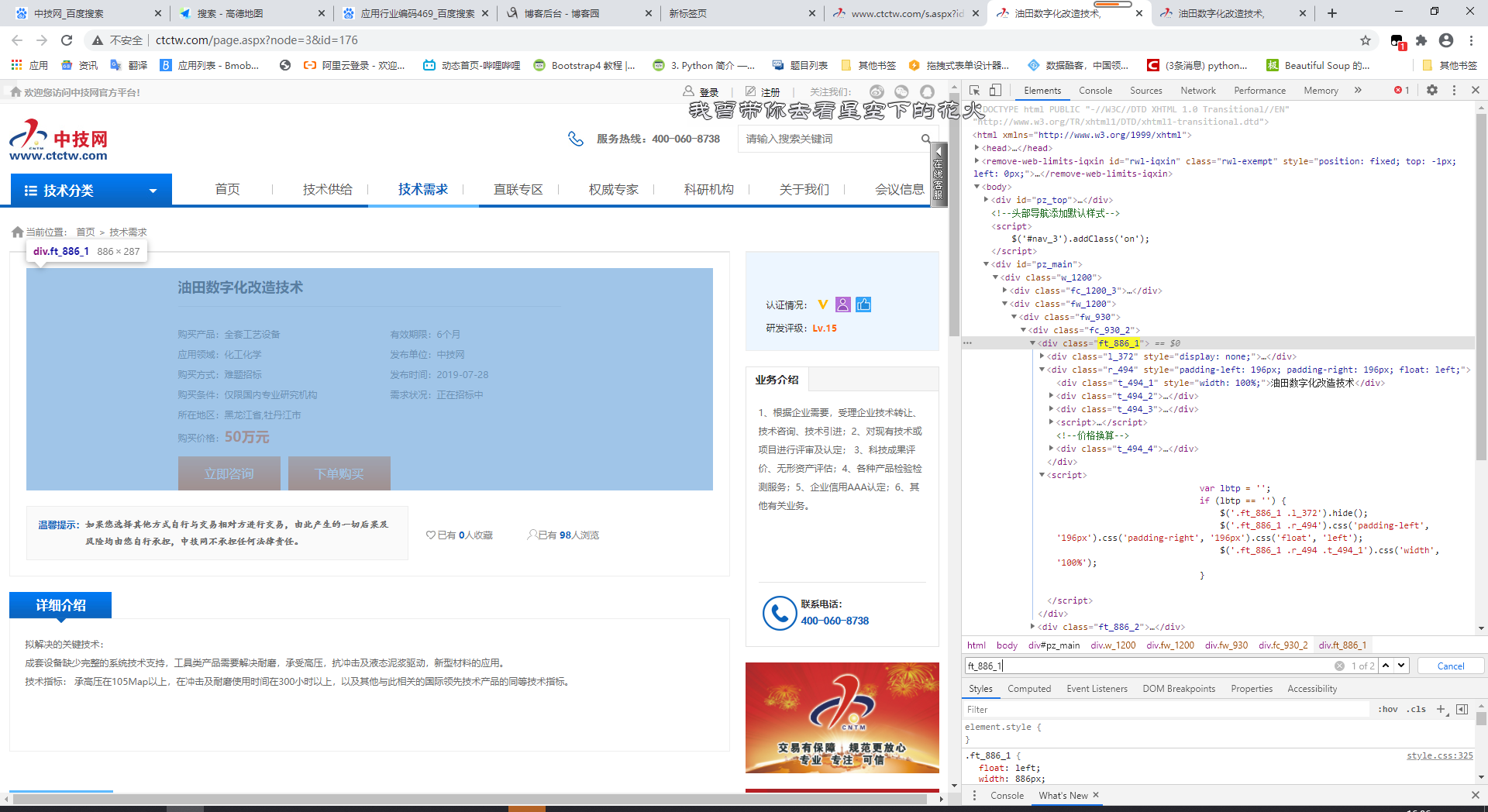
三、存入数据库
下载MySQLdb模块并安装,参考https://blog.csdn.net/weixin_42840933/article/details/85274313
数据库连接
db = MySQLdb.connect("localhost", "root", "root", "db_mtest", charset='utf8')
获取游标
cursor = db.cursor()
执行sql
cursor.execute(sql)
db.commit()
四、代码
import urllib.request from io import BytesIO import gzip from bs4 import BeautifulSoup import re import MySQLdb def getHtmls(url): headers = {'User-Agent': 'User-Agent:Mozilla/5.0'} datal=urllib.request.Request(url,headers=headers) response=urllib.request.urlopen(datal) print ('state code',response.getcode()) data=response.read() str=data.decode('utf-8') soup=BeautifulSoup(str[1:]) return soup def getMessage(soup): items=soup.find_all(class_='con_js') db = MySQLdb.connect("localhost", "root", "root", "db_mtest", charset='utf8') cursor = db.cursor() #进入二级网址 for item in items: secsoup=getHtmls('http://www.ctctw.com'+str(item.a['href'])) #获取主要信息 #标题 msoup=secsoup.find(class_='r_494') #小项 smsoupitems=msoup.find(class_='t_494_2').find_all(class_='bt') print(msoup.find(class_='t_494_1').text) sql = 'insert into zjwsj values(null,\'' + str(msoup.find(class_='t_494_1').text) + '\'' for sit in smsoupitems: sql=sql+',\''+str(sit.text).split(":")[1]+'\'' print(sit.text) #详细介绍 strs=secsoup.find_all(class_='ft_930_2')[0] print((strs.text).strip()) sql=sql+',\''+(strs.text).strip()+'\')' try: print(sql) cursor.execute(sql) db.commit() except : db.rollback() if __name__=='__main__': for i in range(13): try: getMessage(getHtmls('http://www.ctctw.com/list.aspx?node=3&f=cn&page='+str(i+1))) except: getMessage(getHtmls('http://www.ctctw.com/list.aspx?node=3&f=cn&page=' + str(i + 1)))
