
Hadoop综合大作业加上以前漏掉的作业
1.启动hadoop
2.Hdfs上创建文件夹并查看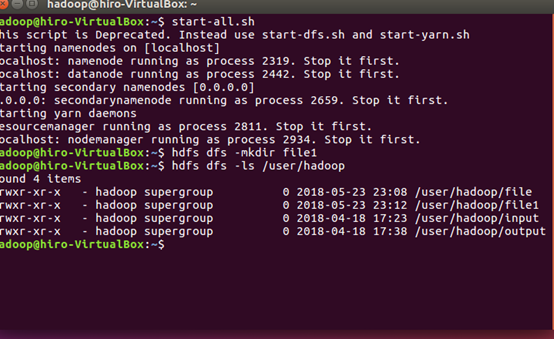
上传英文词频统计文本至hdfs
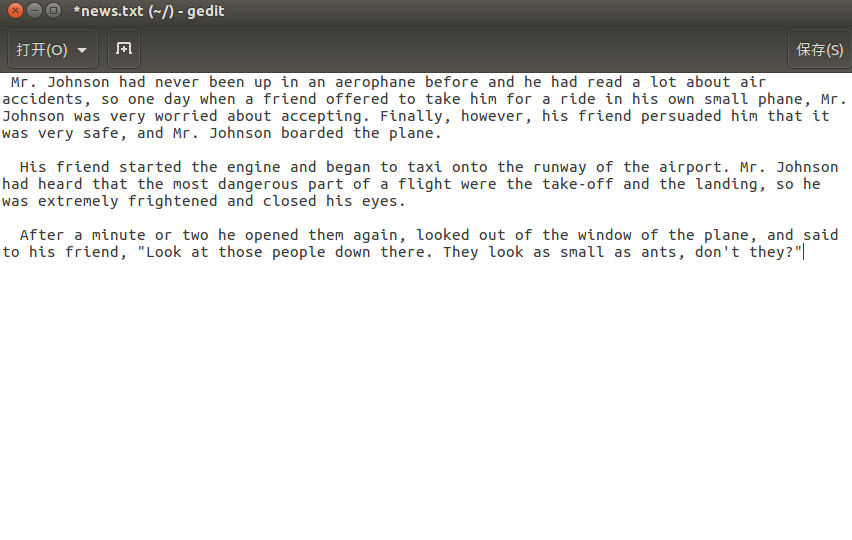
启动Hive
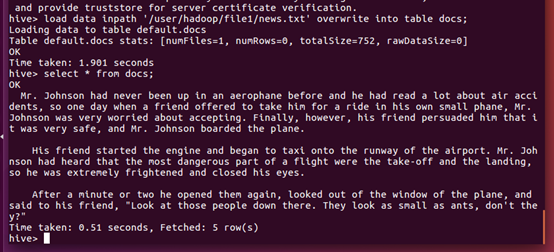
导入文件内容到表docs并查看
进行词频统计,结果放在表t_word_count2里
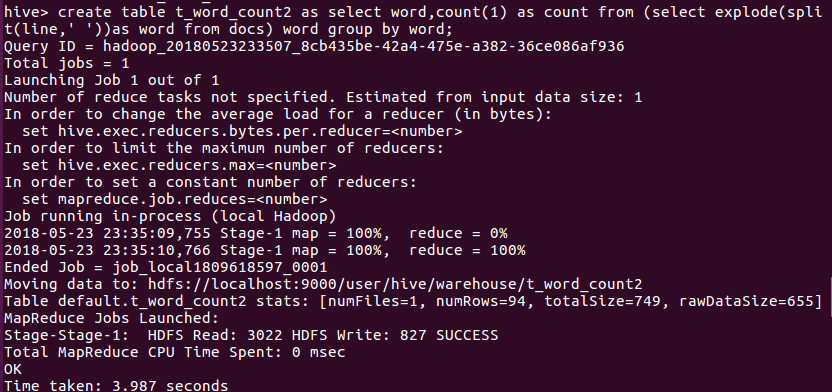
查看统计结果

hive基本操作与应用
通过hadoop上的hive完成WordCount
启动hadoop
ssh localhost
cd /usr/local/hadoop
./sbin/start-dfs.sh
cd /usr/local/hive/lib
service mysql start
start-all.sh
Hdfs上创建文件夹
hdfs dfs -mkdir test1 hdfs dfs -ls /user/hadoop
上传文件至hdfs
hdfs dfs -put ./try.txt test1 hdfs dfs -ls /user/hadoop/test1
启动Hive
hive
创建原始文档表
create table docs(line string)
用HQL进行词频统计,结果放在表word_count里
create table word_count as select word,count(1) as count from (select explode(split(line," ")) as word from docs) word group by word order by word;
导入文件内容到表docs并查看
load data inpath '/user/hadoop/tese1/try.txt' overwrite into table docs
select * from docs爬虫大作业
f = open("C:/Users/ZD/PycharmProjects/test/test.txt", 'w+', encoding='utf8')
import jieba
import requests
from bs4 import BeautifulSoup
def songlist(url):
res = requests.get(url)
res.encoding = 'UTF-8'
soup = BeautifulSoup(res.text, 'html.parser')
songname = soup.select('.song')
for i in songname[1:]:
url = i.select('a')[0].attrs['href']
songread(url)
def songread(url):
f = open("C:/Users/ZD/PycharmProjects/test/test.txt", 'w+', encoding='utf8')
res = requests.get(url)
res.encoding = 'UTF-8'
soup = BeautifulSoup(res.text, 'html.parser')
song = soup.select('.lrcItem')
for i in song:
f.write(i.text)
songlist('http://www.kuwo.cn/geci/a_336/?')
f = open("C:/Users/ZD/PycharmProjects/test/test.txt", 'r', encoding='utf8')
str = f.read()
f.close()
wordList = jieba.cut(str)
wordList = list(jieba.cut(str))
wordDic = {}
for i in set(wordList):
wordDic[i] = wordList.count(i)
sort_word = sorted(wordDic.items(), key=lambda d: d[1], reverse=True)
for i in range(60):
print(sort_word[i])
fo = open("C:/Users/ZD/PycharmProjects/test/test1.txt", 'w', encoding='utf8')
for i in range(60):
fo.write(sort_word[i][0] + '\n')
fo.close()
熟悉常用的HDFS操作
- 在本地Linux文件系统的“/home/hadoop/”目录下创建一个文件txt,里面可以随意输入一些单词.
cd /usr/local/hadoop
touch text.txt - 在本地查看文件位置(ls)
ls -al
- 在本地显示文件内容
cat text.txt
- 使用命令把本地文件系统中的“txt”上传到HDFS中的当前用户目录的input目录下。
./sbin/start-dfs.sh
./bin/hdfs dfs -mkdir -p /user/hadoop ./bin/hdfs dfs -mkdir input ./bin/hdfs dfs -put ./test.txt input - 查看hdfs中的文件(-ls)
./sbin/start-dfs.sh
- 显示hdfs中该的文件内容
./bin/hdfs dfs -ls input ./bin/hdfs dfs -cat input/test.txt
- 删除本地的txt文件并查看目录
cd rm test.txt
- 从hdfs中将txt下载地本地原来的位置。
./bin/hdfs dfs -get input/test.txt ~/test.txt
- 从hdfs中删除txt并查看目录
./bin/hdfs dfs -rm news.txt
./bin/hdfs dfs -ls input
- 向HDFS中上传任意文本文件,如果指定的文件在HDFS中已经存在,由用户指定是追加到原有文件末尾还是覆盖原有的文件;
if $(hdfs dfs -test -e text.txt); then $(hdfs dfs -appendToFile local.txt text.txt); else $(hdfs dfs -copyFromLocal -f local.txt text.txt); fi
- 从HDFS中下载指定文件,如果本地文件与要下载的文件名称相同,则自动对下载的文件重命名;
if $(hdfs dfs -test -e file:///usr/hadoop/text.txt); then $(hdfs dfs -copyToLocal text.txt ./text2.txt); else $(hdfs dfs -copyToLocal text.txt ./text.txt); fi
- 将HDFS中指定文件的内容输出到终端中;
hdfs dfs -cat text.txt
- 显示HDFS中指定的文件的读写权限、大小、创建时间、路径等信息;
hdfs dfs -ls -h text.txt
- 给定HDFS中某一个目录,输出该目录下的所有文件的读写权限、大小、创建时间、路径等信息,如果该文件是目录,则递归输出该目录下所有文件相关信息;
hdfs dfs -ls -R -h /user/hadoop
- 提供一个HDFS内的文件的路径,对该文件进行创建和删除操作。如果文件所在目录不存在,则自动创建目录;
if $(hdfs dfs -test -d dir1/dir2); then $(hdfs dfs -touchz dir1/dir2/filename); else $(hdfs dfs -mkdir -p dir1/dir2 && hdfs dfs -touchz dir1/dir2/filename); fi hdfs dfs -rm dir1/dir2/filename
- 提供一个HDFS的目录的路径,对该目录进行创建和删除操作。创建目录时,如果目录文件所在目录不存在则自动创建相应目录;删除目录时,由用户指定当该目录不为空时是否还删除该目录;
创建目录:hdfs dfs -mkdir -p dir1/dir2 删除目录:hdfs dfs -rmdir dir1/dir2 强制删除目录:hdfs dfs -rm -R dir1/dir2
- 向HDFS中指定的文件追加内容,由用户指定内容追加到原有文件的开头或结尾;
追加到文件末尾:hdfs dfs -appendToFile local.txt text.txt 追加到文件开头: hdfs dfs -get text.txt cat text.txt >> local.txt hdfs dfs -copyFromLocal -f text.txt text.txt
- 删除HDFS中指定的文件;
hdfs dfs -rm text.txt
- 删除HDFS中指定的目录,由用户指定目录中如果存在文件时是否删除目录;
删除目录:hdfs dfs -rmdir dir1/dir2 强制删除目录:hdfs dfs -rm -R dir1/dir2
- 在HDFS中,将文件从源路径移动到目的路径。
-
hdfs dfs -mv text.txt text2.txt
- 向HDFS中上传任意文本文件,如果指定的文件在HDFS中已经存在,由用户指定是追加到原有文件末尾还是覆盖原有的文件;
数据结构化与保存
1. 将新闻的正文内容保存到文本文件。
2. 将新闻数据结构化为字典的列表:
- 单条新闻的详情-->字典news
- 一个列表页所有单条新闻汇总-->列表newsls.append(news)
- 所有列表页的所有新闻汇总列表newstotal.extend(newsls)
3. 安装pandas,用pandas.DataFrame(newstotal),创建一个DataFrame对象df.
4. 通过df将提取的数据保存到csv或excel 文件。
5. 用pandas提供的函数和方法进行数据分析:
- 提取包含点击次数、标题、来源的前6行数据
- 提取‘学校综合办’发布的,‘点击次数’超过3000的新闻。
- 提取'国际学院'和'学生工作处'发布的新闻。
import requests
from bs4 import BeautifulSoup
from datetime import datetime
import re
import pandas
#获取点击次数
def getClickCount(newsUrl):
newId=re.search('\_(.*).html',newsUrl).group(1).split('/')[1]
clickUrl="http://oa.gzcc.cn/api.php?op=count&id={}&modelid=80".format(newId)
clickStr = requests.get(clickUrl).text
count = re.search("hits'\).html\('(.*)'\);", clickStr).group(1)
return count
#获取新闻详情
def getNewsDetail(newsurl):
resd=requests.get(newsurl)
resd.encoding='utf-8'
soupd=BeautifulSoup(resd.text,'html.parser')
news={}
news['title']=soupd.select('.show-title')[0].text
# news['newsurl']=newsurl
info=soupd.select('.show-info')[0].text
news['dt']=datetime.strptime(info.lstrip('发布时间:')[0:19],'%Y-%m-%d %H:%M:%S')
news['click'] = int(getClickCount(newsurl))
if info.find('来源')>0:
news['source'] =info[info.find('来源:'):].split()[0].lstrip('来源:')
else:
news['source']='none'
if info.find('作者:') > 0:
news['author'] = info[info.find('作者:'):].split()[0].lstrip('作者:')
else:
news['author'] = 'none'
# news['content']=soupd.select('.show-content')[0].text.strip()
#获取文章内容并写入到文件中
content=soupd.select('.show-content')[0].text.strip()
writeNewsContent(content)
return news
def getListPage(listPageUrl):
res=requests.get(listPageUrl)
res.encoding='utf-8'
soup=BeautifulSoup(res.text,'html.parser')
newsList=[]
for news in soup.select('li'):
if len(news.select('.news-list-title'))>0:
a=news.select('a')[0].attrs['href']
newsList.append(getNewsDetail(a))
return (newsList)
#数据写入文件
def writeNewsContent(content):
f=open('gzccNews.txt','a',encoding='utf-8')
f.write(content)
f.close()
def getPageNumber():
ListPageUrl="http://news.gzcc.cn/html/xiaoyuanxinwen/"
res=requests.get(ListPageUrl)
res.encoding='utf-8'
soup=BeautifulSoup(res.text,'html.parser')
n = int(soup.select('.a1')[0].text.rstrip('条'))//10+1
return n
newsTotal=[]
firstPage='http://news.gzcc.cn/html/xiaoyuanxinwen/'
newsTotal.extend(getListPage(firstPage))
n=getPageNumber()
for i in range(n,n+1):
listUrl= 'http://news.gzcc.cn/html/xiaoyuanxinwen/{}.html'.format(i)
newsTotal.extend(getListPage(listUrl))
df=pandas.DataFrame(newsTotal)
# df.to_excel("news.xlsx")
# print(df.head(6))
# print(df[['author','click','source']])
# print(df[df['click']>3000])
sou=['国际学院','学生工作处']
print(df[df['source'].isin(sou)])

