微服务(六)-实现搜索功能、Kafka和消息队列、zookeeper、AOP、熔断器Hystrix、服务降级、网站限流原理
1 达内知道实现搜索功能
我们希望实现用户登录之后,在首页输入搜索关键字之后,点击搜索按钮,跳转到搜索结果页,页面中分页显示所有搜索结果。
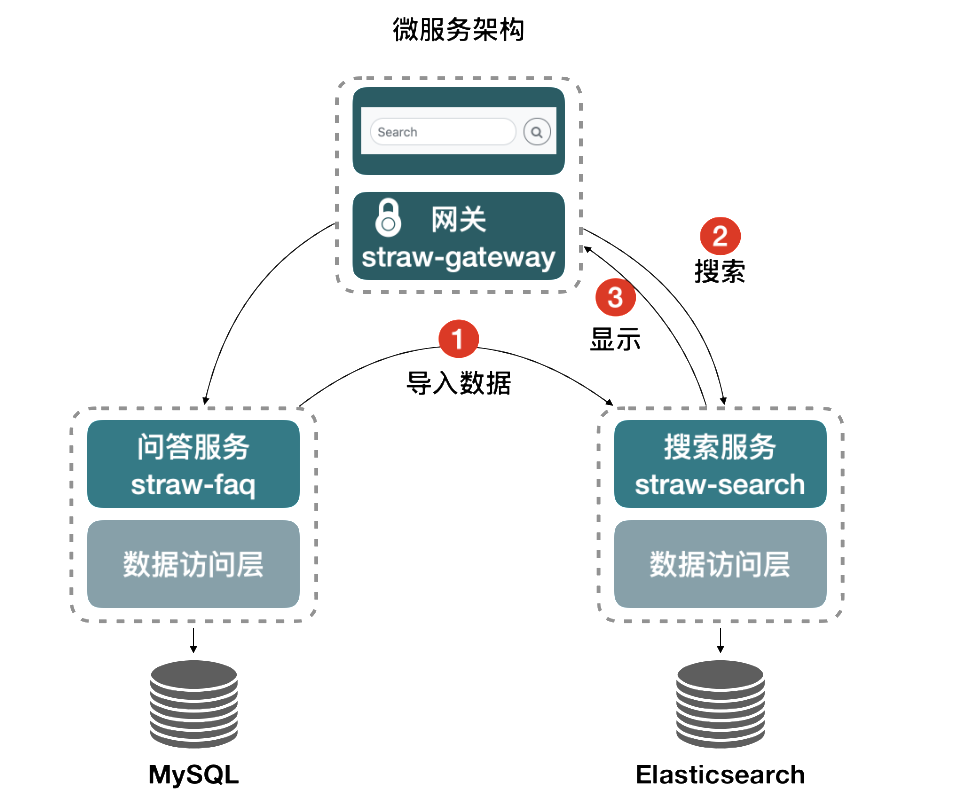
实现完整效果的业务流程为:
-
将mysql数据库中question表中的所有数据同步到ES
-
根据用户输入的搜索关键字,到ES中查询匹配的问题
-
分页显示在搜索结果页面
-
重构学生发布问题的方法,将学生发布到数据库的问题同时新增到ES
1.2 配置knows-search模块
添加能够注册到Nacos的依赖:
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
</dependency>
<dependency>
<groupId>cn.tedu</groupId>
<artifactId>knows-commons</artifactId>
</dependency>
application.properties文件添加Nacos的位置,注册到注册中心:
spring.cloud.nacos.discovery.server-addr=localhost:8848
SpringBoot启动类添加注册到Nacos的注解和Ribbon的支持:
1.3 同步数据到ES
实际开发中,这个同步过程数据量可能很大,我们需要分批分次的从数据中查询然后增加到ES中,所以操作上是分页查询,循环向ES中新增,分页查询所有问题是faq模块的内容,需要编写Rest接口。分页查询当前数据库中所有数据的总页数也是faq模块的Rest接口,只有确定了总页数,才能确定循环新增到ES的次数。全查所有问题Mybatis Plus提供了方法,直接从业务逻辑层开始。
转到Faq模块
IQuestionService接口添加方法:
// 分页查询所有问题,用于同步到ES
PageInfo<Question> getQuestions(
Integer pageNum, Integer pageSize);
QuestionServiceImpl实现类方法:
然后编写控制层(Rest接口):QuestionController
//根据页码分页查询所有问题,只需要获得该页内容就行
可以发同步测试:
(1)http://localhost:8001/v2/questions/page?pageNum=1&pageSize=8
(2)http://localhost:8001/v2/questions/page/count?pageSize=8
faq模块的准备工作完成。
转到search模块:
创建一个QuestionVo类,将查询到的数据保存到ES中,QuestionVo和数据库实体类Question属性一致,可以直接复制到search模块,修改如下:
package cn.tedu.knows.search.vo;
import cn.tedu.knows.commons.model.Tag;
import com.baomidou.mybatisplus.annotation.IdType;
import com.baomidou.mybatisplus.annotation.TableField;
import com.baomidou.mybatisplus.annotation.TableId;
import com.baomidou.mybatisplus.annotation.TableName;
import lombok.Data;
import lombok.EqualsAndHashCode;
import lombok.experimental.Accessors;
import org.springframework.data.annotation.Id;
import org.springframework.data.annotation.Transient;
import org.springframework.data.elasticsearch.annotations.DateFormat;
import org.springframework.data.elasticsearch.annotations.Document;
import org.springframework.data.elasticsearch.annotations.Field;
import org.springframework.data.elasticsearch.annotations.FieldType;
import java.io.Serializable;
import java.time.LocalDate;
import java.time.LocalDateTime;
import java.util.List;
/**
* <p>
*
* </p>
*
* @author tedu.cn
* @since 2021-08-23
*/