Elasticsearch全文搜索引擎(一)-定义、安装、查询原理、数据结构、基本使用
1.下载软件
2.什么是Elasticsearch?
Elastic(富有弹性的)search(查询),简称ES,它是使用java开发的一个软件,我们启动这个软件,本质上就是开启了一个java的服务,这个服务中有很多可以访问的控制器路径,每个路径功能不同,我们可以向它发送请求获得响应。
Elasticsearch是一个基于Lucene的搜索服务器,Lucene是核心技术,Elasticsearch是完整的应用,用电脑作为比喻,Lucene就像是芯片,而Elasticsearch就像是用芯片打造的完整电脑,开箱即用!市面上和它功能类似的软件有:solr和MongoDB。
3.为什么需要Elasticsearch
ES的核心作用是搜索,使用ES做搜索的原因是因为数据库模糊查询效率太低。
关系型数据库无论mysql还是oracle还是DB2都有一个缺陷,在数据库表模糊查询指定内容时,会引起全表搜索,严重影响查询效率。数据库按id查询,效率非常高;按具体内容查询(非模糊查询),创建索引的前提下,速度也很快,但是关系型数据库在进行模糊查询(前模糊:查询内容前是%或者_)时,不能启动索引,所以无法利用索引加速,只能全表搜索。一张千万级别的表,如果进行一次模糊查询,响应时间在20秒以上,如果数据量再大,一次查询可能需要1分钟以上。
我们学习的ES就能弥补数据库的缺陷,完成高效率的模糊查询,大数据量数据库中,ES模糊查询速度是关系型数据库的100倍以上!
-
ES是java开发的,需要java的环境变量才能运行,主要配置了JAVA_HOME即可;
-
任何语言都可以使用ES进行高效查询;
-
ES支持分布式部署,支持高并发、高可用、高性能。
4.ES查询原理
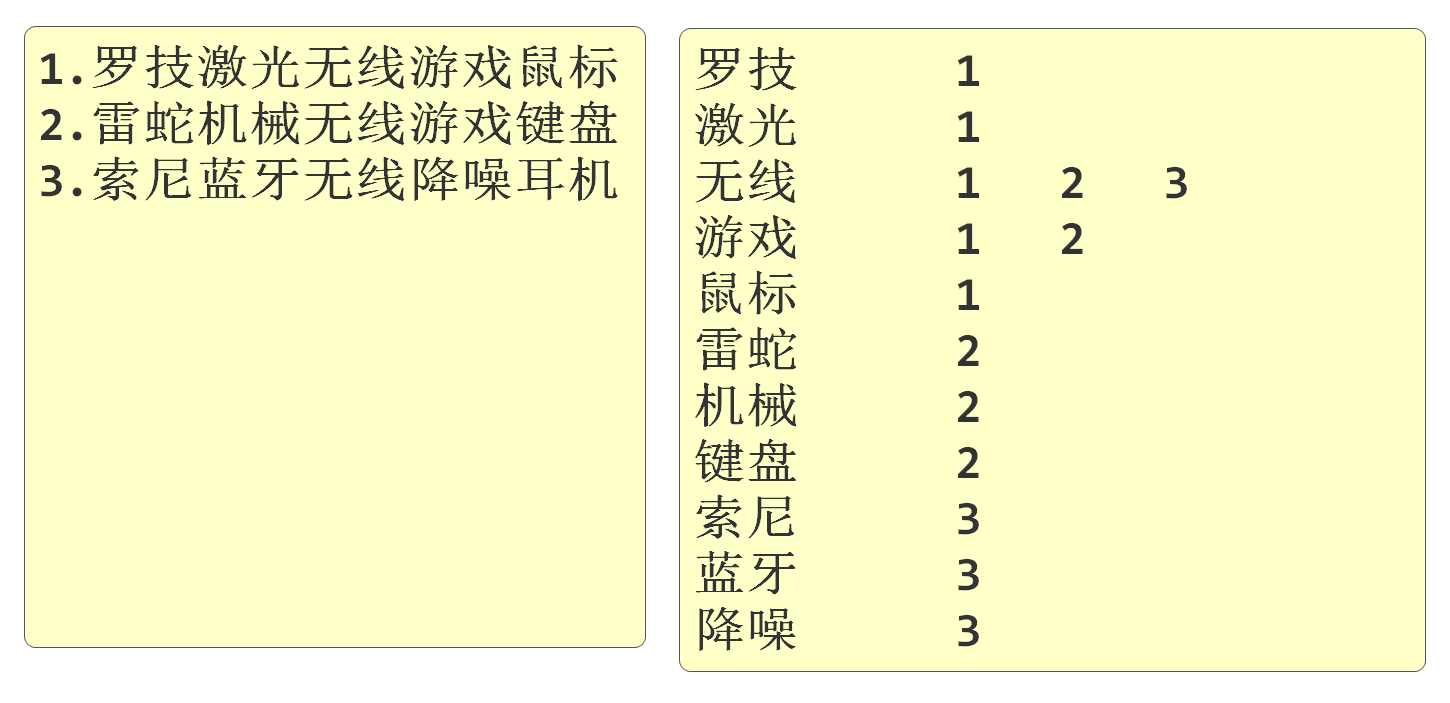
ES的查询原理是按分词建立索引,根据要保存的内容先分词,然后按照分词的结果建立索引。搜索时按索引搜索,以提高查询速度,我们将这样的数据库称之为"全文搜索引擎"。
ES是将数据库中的数据单独复制出一份,由ES操作,也保存在硬盘上,能够保证一般查询速度在毫秒级别。
索引库创建示意图如下:
5.ES的安装
官方下载链接:https://www.elastic.co/cn/downloads/past-releases#elasticsearch
将下载的280兆的压缩包解压,解压之后进入目录:
双击elasticsearch.bat文件可以启动ES:
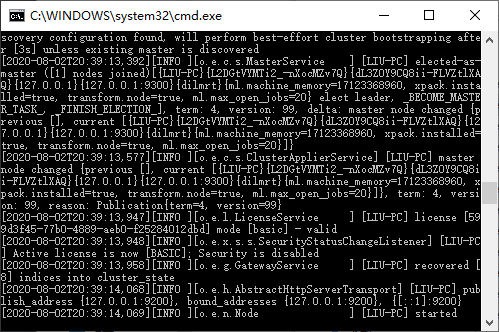
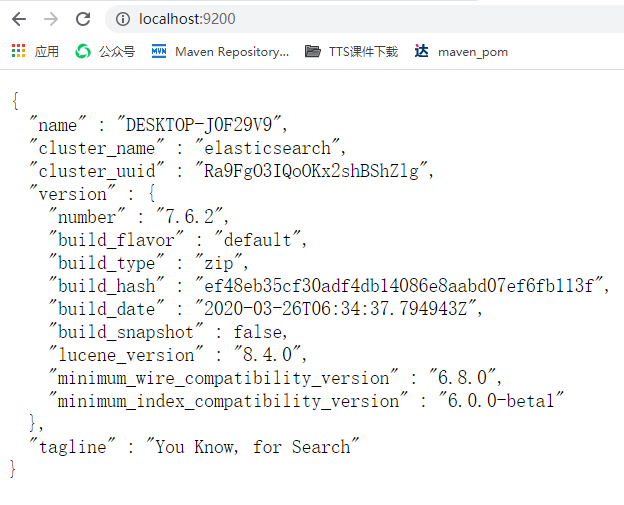
这个窗口不能关,一关ES就停止了,我们可以通过在浏览器输入地址:http://localhost:9200进行测试,启动成功页面如下:
其他系统启动如下:
mac系统启动:
tar -xvf elasticsearch-7.6.2-darwin-x86_64.tar.gz
cd elasticsearch-7.6.2/bin
./elasticsearch
linux:
tar -xvf elasticsearch-7.6.2-linux-x86_64.tar.gz
cd elasticsearch-7.6.2/bin
./elasticsearch
6.ES基本使用
在knows项目上单击右键,创建搜索模块knows-search,用于测试ES和后续的搜索功能。
父子相认:knows的pom.xml
<module>knows-search</module>
knows-search的pom.xml
刷新maven!
我们先不编写代码,先通过http client(http客户端)文件向ES发送请求,执行基本操作。
打开方式如下:在knows-search项目上点击右键,New,选择HTTP Request,文件名为esdemo:
在创建出来的文件中编写一些代码如下:
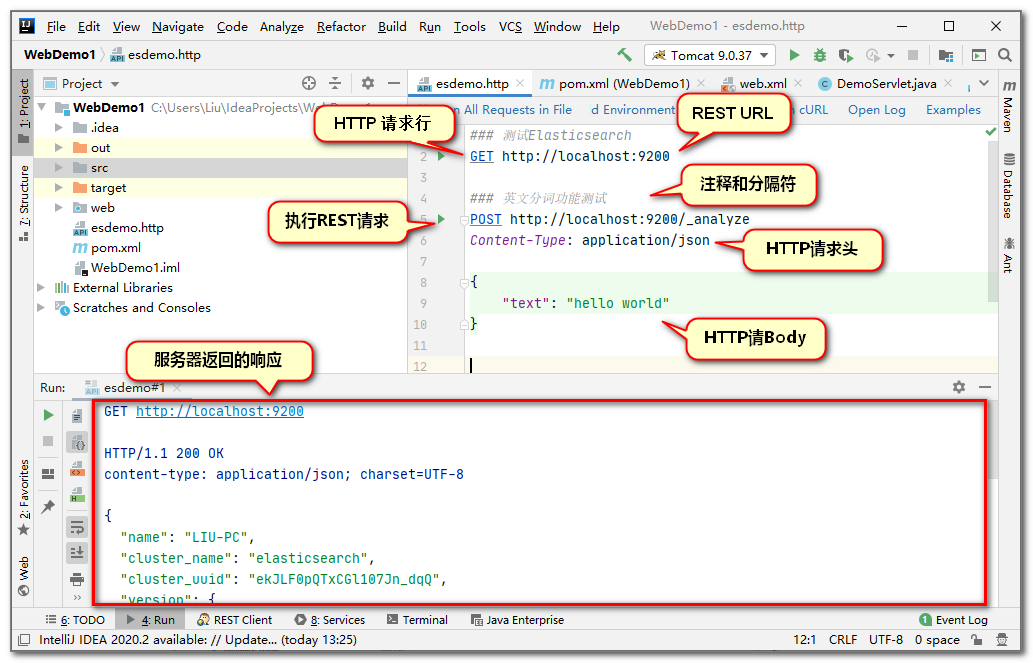
测试代码如下:
### 这是分割符,也是注释,要求每次发送请求之前必须编写
### 基本测试(测试是否启动成功)
GET http://localhost:9200
### 必须写分隔符(三个#),英文分词功能测试,下面的换行一定要有,这是格式要求
POST http://localhost:9200/_analyze
Content-Type: application/json
{
"text": "Hello World",
"analyzer": "standard"
}
### 必须写三个#做分割符, 中文分词功能测试,下面的换行一定要有,这是格式要求
POST http://localhost:9200/_analyze
Content-Type:application/json
{
"text":"我觉得北京天安门是非常值得去的",
"analyzer":"standard"
}
(1)GET http://localhost:9200测试结果
GET http://localhost:9200
HTTP/1.1 200 OK
content-type: application/json; charset=UTF-8
{
"name": "CJN-PC",
"cluster_name": "elasticsearch",
"cluster_uuid": "ddKkYhODTM-IH83OHA8MPw",
"version": {
"number": "7.6.2",
"build_flavor": "default",
"build_type": "zip",
"build_hash": "ef48eb35cf30adf4db14086e8aabd07ef6fb113f",
"build_date": "2020-03-26T06:34:37.794943Z",
"build_snapshot": false,
"lucene_version": "8.4.0",
"minimum_wire_compatibility_version": "6.8.0",
"minimum_index_compatibility_version": "6.0.0-beta1"
},
"tagline": "You Know, for Search"
}
Response code: 200 (OK); Time: 326ms; Content length: 531 bytes
(2)英文分词功能测试
POST http://localhost:9200/_analyze
HTTP/1.1 200 OK
content-type: application/json; charset=UTF-8
{
"tokens": [
{
"token": "hello",
"start_offset": 0,
"end_offset": 5,
"type": "<ALPHANUM>",
"position": 0
},
{
"token": "world",
"start_offset": 6,
"end_offset": 11,
"type": "<ALPHANUM>",
"position": 1
}
]
}
Response code: 200 (OK); Time: 61ms; Content length: 179 bytes
(3)中文分词功能测试
POST http://localhost:9200/_analyze
HTTP/1.1 200 OK
content-type: application/json; charset=UTF-8
{
"tokens": [
{
"token": "我",
"start_offset": 0,
"end_offset": 1,
"type": "<IDEOGRAPHIC>",
"position": 0
},
{
"token": "觉",
"start_offset": 1,
"end_offset": 2,
"type": "<IDEOGRAPHIC>",
"position": 1
},
{
"token": "得",
"start_offset": 2,
"end_offset": 3,
"type": "<IDEOGRAPHIC>",
"position": 2
},
{
"token": "北",
"start_offset": 3,
"end_offset": 4,
"type": "<IDEOGRAPHIC>",
"position": 3
},
{
"token": "京",
"start_offset": 4,
"end_offset": 5,
"type": "<IDEOGRAPHIC>",
"position": 4
},
{
"token": "天",
"start_offset": 5,
"end_offset": 6,
"type": "<IDEOGRAPHIC>",
"position": 5
},
{
"token": "安",
"start_offset": 6,
"end_offset": 7,
"type": "<IDEOGRAPHIC>",
"position": 6
},
{
"token": "门",
"start_offset": 7,
"end_offset": 8,
"type": "<IDEOGRAPHIC>",
"position": 7
},
{
"token": "是",
"start_offset": 8,
"end_offset": 9,
"type": "<IDEOGRAPHIC>",
"position": 8
},
{
"token": "非",
"start_offset": 9,
"end_offset": 10,
"type": "<IDEOGRAPHIC>",
"position": 9
},
{
"token": "常",
"start_offset": 10,
"end_offset": 11,
"type": "<IDEOGRAPHIC>",
"position": 10
},
{
"token": "值",
"start_offset": 11,
"end_offset": 12,
"type": "<IDEOGRAPHIC>",
"position": 11
},
{
"token": "得",
"start_offset": 12,
"end_offset": 13,
"type": "<IDEOGRAPHIC>",
"position": 12
},
{
"token": "去",
"start_offset": 13,
"end_offset": 14,
"type": "<IDEOGRAPHIC>",
"position": 13
},
{
"token": "的",
"start_offset": 14,
"end_offset": 15,
"type": "<IDEOGRAPHIC>",
"position": 14
}
]
}
Response code: 200 (OK); Time: 98ms; Content length: 1258 bytes
"analyzer" : "standard"是默认的分词器,可以省略。我们发现默认的分词器对中文分词是失败的,所以我们需要设置一个识别中文的分词器,安装ik插件(上面下载好的4.7M的插件,注意插件版本一定要与软件版本一致)以获得识别中文的分词器。
-
在elasticsearch-7.6.2\plugins路径下新建ik文件夹;
-
将ik插件中的内容(8个文件)复制进去
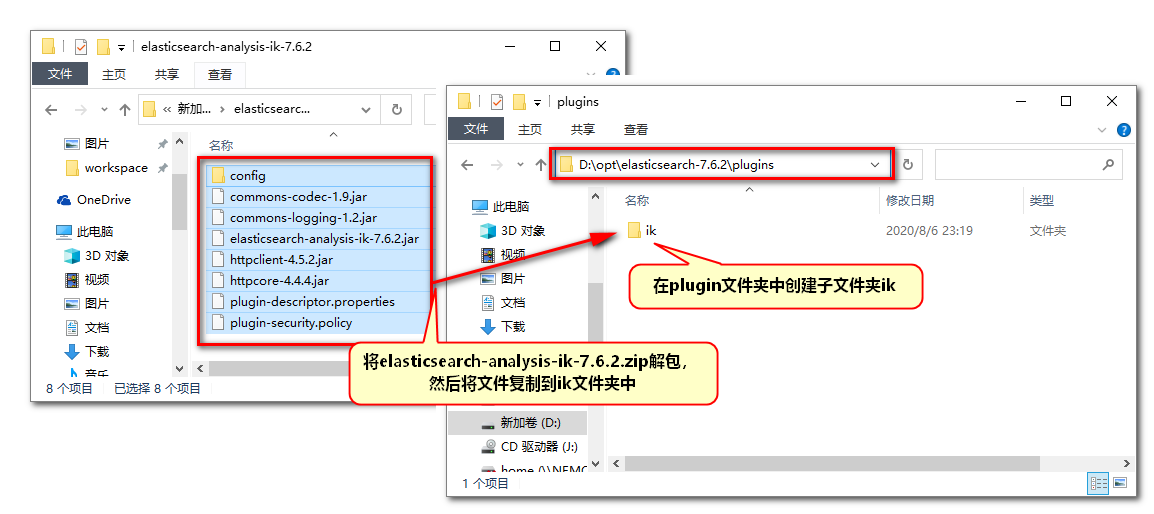
因为修改了配置,所以要重启ES软件,如果启动成功,修改分词器,再次运行分词测试:
(1) "analyzer":"ik_max_word"分词器
### 必须写三个#做分割符, 中文分词功能测试
POST http://localhost:9200/_analyze
Content-Type:application/json
{
"text":"我觉得北京天安门是非常值得去的",
"analyzer":"ik_max_word"
}
输出结果:
POST http://localhost:9200/_analyze
HTTP/1.1 200 OK
content-type: application/json; charset=UTF-8
{
"tokens": [
{
"token": "我",
"start_offset": 0,
"end_offset": 1,
"type": "CN_CHAR",
"position": 0
},
{
"token": "觉得",
"start_offset": 1,
"end_offset": 3,
"type": "CN_WORD",
"position": 1
},
{
"token": "北京",
"start_offset": 3,
"end_offset": 5,
"type": "CN_WORD",
"position": 2
},
{
"token": "天安门",
"start_offset": 5,
"end_offset": 8,
"type": "CN_WORD",
"position": 3
},
{
"token": "天安",
"start_offset": 5,
"end_offset": 7,
"type": "CN_WORD",
"position": 4
},
{
"token": "门",
"start_offset": 7,
"end_offset": 8,
"type": "CN_CHAR",
"position": 5
},
{
"token": "是非",
"start_offset": 8,
"end_offset": 10,
"type": "CN_WORD",
"position": 6
},
{
"token": "非常",
"start_offset": 9,
"end_offset": 11,
"type": "CN_WORD",
"position": 7
},
{
"token": "常值",
"start_offset": 10,
"end_offset": 12,
"type": "CN_WORD",
"position": 8
},
{
"token": "值得",
"start_offset": 11,
"end_offset": 13,
"type": "CN_WORD",
"position": 9
},
{
"token": "去",
"start_offset": 13,
"end_offset": 14,
"type": "CN_CHAR",
"position": 10
},
{
"token": "的",
"start_offset": 14,
"end_offset": 15,
"type": "CN_CHAR",
"position": 11
}
]
}
Response code: 200 (OK); Time: 103ms; Content length: 945 bytes
(2)"analyzer":"ik_smart"分词器
### 必须写三个#做分割符, 中文分词功能测试
POST http://localhost:9200/_analyze
Content-Type:application/json
{
"text":"我觉得北京天安门是非常值得去的",
"analyzer":"ik_smart"
}
输出结果:
POST http://localhost:9200/_analyze
HTTP/1.1 200 OK
content-type: application/json; charset=UTF-8
{
"tokens": [
{
"token": "我",
"start_offset": 0,
"end_offset": 1,
"type": "CN_CHAR",
"position": 0
},
{
"token": "觉得",
"start_offset": 1,
"end_offset": 3,
"type": "CN_WORD",
"position": 1
},
{
"token": "北京",
"start_offset": 3,
"end_offset": 5,
"type": "CN_WORD",
"position": 2
},
{
"token": "天安门",
"start_offset": 5,
"end_offset": 8,
"type": "CN_WORD",
"position": 3
},
{
"token": "是非",
"start_offset": 8,
"end_offset": 10,
"type": "CN_WORD",
"position": 4
},
{
"token": "常",
"start_offset": 10,
"end_offset": 11,
"type": "CN_CHAR",
"position": 5
},
{
"token": "值得",
"start_offset": 11,
"end_offset": 13,
"type": "CN_WORD",
"position": 6
},
{
"token": "去",
"start_offset": 13,
"end_offset": 14,
"type": "CN_CHAR",
"position": 7
},
{
"token": "的",
"start_offset": 14,
"end_offset": 15,
"type": "CN_CHAR",
"position": 8
}
]
}
Response code: 200 (OK); Time: 637ms; Content length: 711 bytes
比较两个分词器,对同一句中文的分词结果 :
-
ik_smart不会对这句话进行重复的分词,分词量少,查询速度快,但是分词不够详细;
-
ik_max_word会对这句话进行重复的分词,分词量大,查询速度相对慢,但分词很详细。
实际开发中根据业务需求选择使用,达内知道项目使用ik_smart进行中文分词。
7.ES保存数据的结构
数据库软件使用数据库\表\行\列保存数据,那么ES软件的数据结构是什么样的呢?
一个ES服务可以创建多个index(索引),index相当于数据库中的表。每一个index(索引)又可以创建多个document(文档),document相当于数据库中的一行,document文档一般以json格式的数据保存到ES。
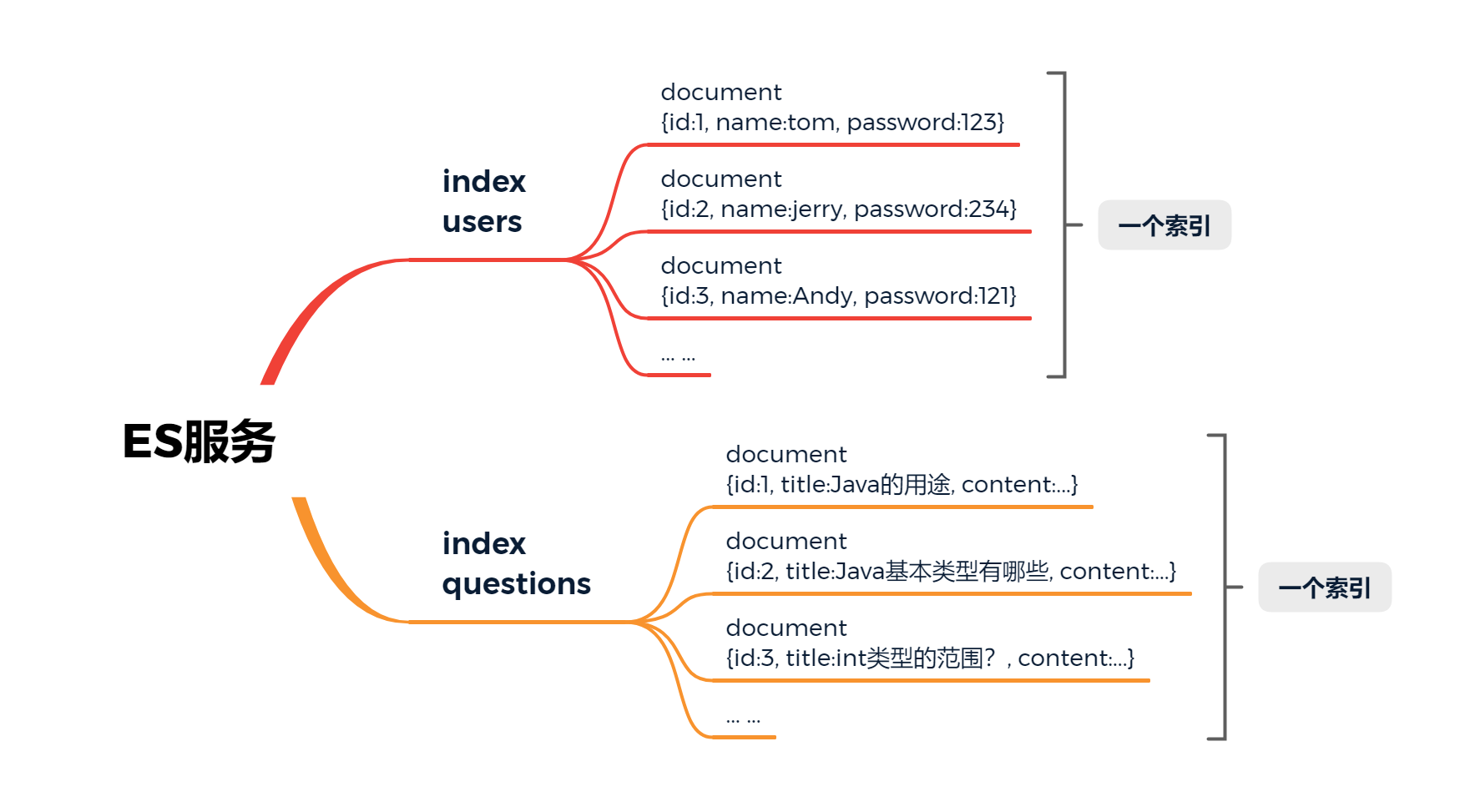
明确ES数据结构后,我们可以对它进行增删改查操作。
