Map(HashMap)性能分析
1.基础概念
定义:Map是一个集合,一种依照键(key)存储元素的容器,键(key)很像下标,在List中下标是整数。在Map中键(key)可以是任意类型的对象。Map中不能有重复的键(Key),每个键(key)都有一个对应的值(value)。
-
Map中的元素是两个对象,一个对象作为键,一个对象作为值。即:一个键(key)和它对应的值(value)构成map集合中的一个元素。
-
键不可以重复,但是值可以重复。
-
Map本身是一个接口,要使用Map需要通过子类进行对象实例化。
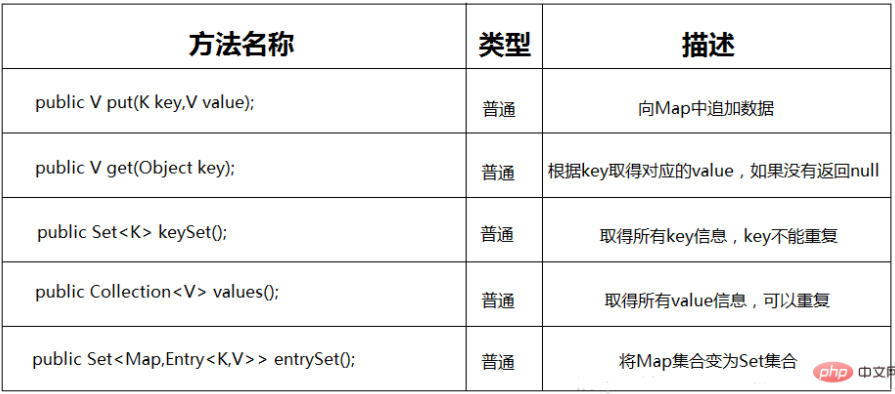
在Map接口中有如下常用方法:
测试代码:
public static void main(String[] args) {
Map<Integer, String> map = new HashMap<>();
map.put(1, "A");
map.put(1, "A+");
map.put(2, "B");
map.put(3, "C");
System.out.println(map);
System.out.println(map.get(2)); //根据key取得value
System.out.println(map.get(10)); //找不到返回null
//取得Map中所有key信息
Set<Integer> set = map.keySet();
Iterator<Integer> iterator = set.iterator();
while(iterator.hasNext()) {
System.out.println(iterator.next());
}
}
注意:
-
key值不允许重复,如果重复,则会把对应value值更新;
-
key和value都允许为null,key为null有且只有一个。
-
HashMap原理:在数据量小的(JDK1.8后阈值为8)时候,HashMap是按照链表的模式存储的;当数据量变大之后,为了进行快速查找,会将这个链表变为红黑树(均衡二叉树)来进行保存,用hash来进行查找。(https://m.php.cn/article/419725.html)
Map接口的常用子类有如下四个:HashMap、HashTable、TreeMap、ConcurrentHashMap。
Map相关的集合都是为查找而生的,根据一个关键字(key)找到相关的数据(Value),根据key找value,HashMap是天下第一快!
2.HashMap性能分析
HashMap是map的最常用实现类,具有极佳的查询性能,根据key找到value特别快。
-
根据序号找数据:使用Array、ArrayList
-
根据key找到数据:使用Map
性能测试: 创建3个HashMap, 分别添加10000、100000、1000000 组数据,添加时候,保留其中的一个key 测试,3个集合中找到这个key对应的数据,分别查询该key获取对应数据需要的时间.
测试代码:
package list;
import java.util.HashMap;
import java.util.UUID;
/**
* 测试HashMap查询性能
*/
public class Demo07 {
public static void main(String[] args) {
HashMap<String,Integer> map1 = new HashMap<>();
HashMap<String,Integer> map2 = new HashMap<>();
HashMap<String,Integer> map3 = new HashMap<>();
String key = null;//3个集合中都有的key
for (int i = 0; i < 1000000; i++) {
String uuid = UUID.randomUUID().toString();//保证key唯一
if (i==9999)
key = uuid;//作为共有的key
if(i<10000){
map1.put(uuid,i);
}
if(i<100000){
map2.put(uuid,i);
}
map3.put(uuid,i);
}
long t1 = System.nanoTime();
Integer value1 = map1.get(key);
long t2 = System.nanoTime();
Integer value2 = map2.get(key);
long t3 = System.nanoTime();
Integer value3 = map3.get(key);
long t4 = System.nanoTime();
System.out.println("map1.get("+key+")="+value1+",耗时:"+(t2-t1));
System.out.println("map2.get("+key+")="+value2+",耗时:"+(t3-t2));
System.out.println("map3.get("+key+")="+value3+",耗时:"+(t4-t3));
}
}
输出结果:
map1.get(05ea1c58-5781-4554-a849-f19ebbfce38e)=9999,耗时:606782 注意:里面包含了创建变量的时间,本质上三个map时间相当
map2.get(05ea1c58-5781-4554-a849-f19ebbfce38e)=9999,耗时:1642
map3.get(05ea1c58-5781-4554-a849-f19ebbfce38e)=9999,耗时:821
结论:
-
HashMap查询性能和存储的数据量无关
-
每次查询数据都非常快,查询速度和数组中根据下标找到数据的性能相当!(HashMap底层仍是数组)
何时使用: 凡是需要进行查找的时候,尽量使用HashMap(尽量不用for:循环8次以内速度比较快,之后变慢)
3.HashMap原理分析
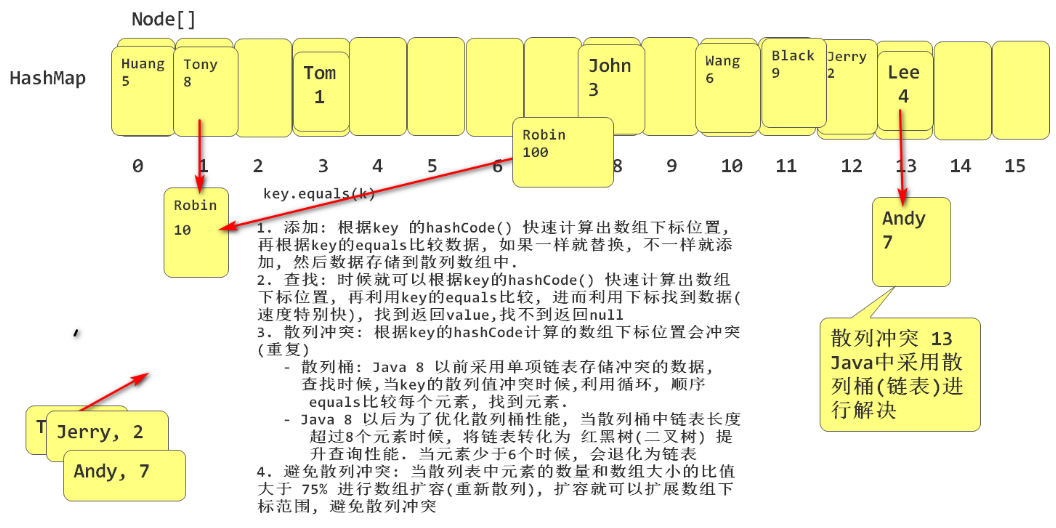
概要的说: HashMap内部利用了数组下标找到数据特别快的特点,将数据存储到数组中,查找时根据key快速计算出数组下标位置,直接找到数据。
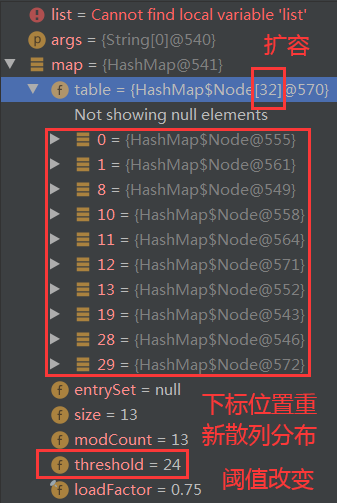
利用Debug分析HashMap的结构:
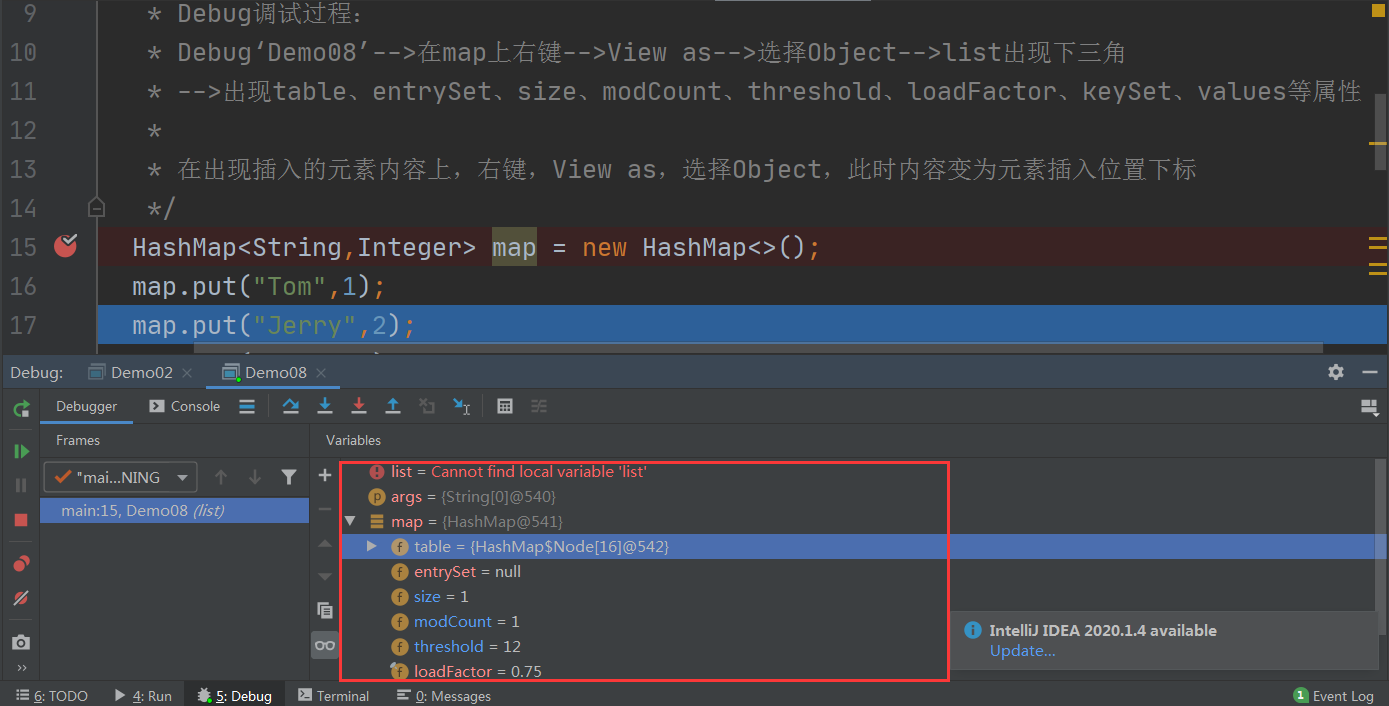
其中:
-
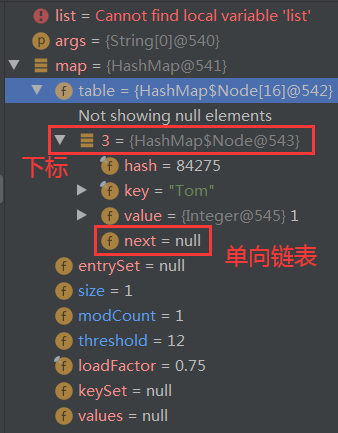
table可以查看插入元素的详细信息:插入元素在数组中的下标、hash、key、value、next(正常情况下为null,该下标位置存储多个元素时,变成散列桶(以单向链表形式存储),此时发生散列冲突,不再为null)

-
entrySet:存储键值对形式的集合
-
size:元素个数
-
modCount
-
threshold:阈值,HashMap初始长度为16,当元素个数超过阈值12(16*0.75=12)进行扩容,依次为16的倍数,32、64、128、...
-
loadFactor:载荷系数,默认为0.75
-
keySet:存储键值形式的集合
-
values:存储值形式的集合
总结:
-
添加:根据key的hashCode()(内含散列算法)快速计算出数下标位置,将数据存储到散列数组中。
-
查找:根据key的hashCode()快速计算出数组下标位置,进而利用下标找到数据(速度特别快)。
-
散列冲突:根据key的hashCode()计算的数组下标位置发生冲突(重复)
-
散列桶:Java 8以前采用单向链表存储冲突的数据。查找时,当key的散列值发生冲突时,利用循环,顺序利用equals比较每个元素,找到元素,找不到返回null
-
Java 8以后为了优化散列桶性能,当散列桶中链表长度超过8个元素的时候,将链表转化为红黑树(二叉树),以提高查询性能;当元素个数少于6个的时候,会退化为链表。
-
-
避免散列冲突:当散列表中元素的数量和数组大小的比值大于0.75(loadFactor)时,进行数组扩容,重新散列,扩容后就可以扩展数组下标范围,避免散列冲突。
4.关于hashCode方法
-
hashCode() :Java为了支持散列表算法,在Object类上定义的一个方法,此方法的用途就为HashMap计算散列值。
-
hashCode() 方法的默认值, 是Java自动分配的串号,不是内存地址,也不是对象地址;
-
hashCode() 方法建议:在重写equals方法的时候,要一起重写hashCode()
-
当两个对象equals 比较相等的时候, 它们的hashCode()必须一样
-
当两个对象equals 比较不等的时候,它们的hashCode()尽可能不同
-
如果不遵守上述规则,HashMap将出现各种奇葩故障!
-
-
开发工具都提供了非常方便的重写equals/hashCdoe方法的工具
-
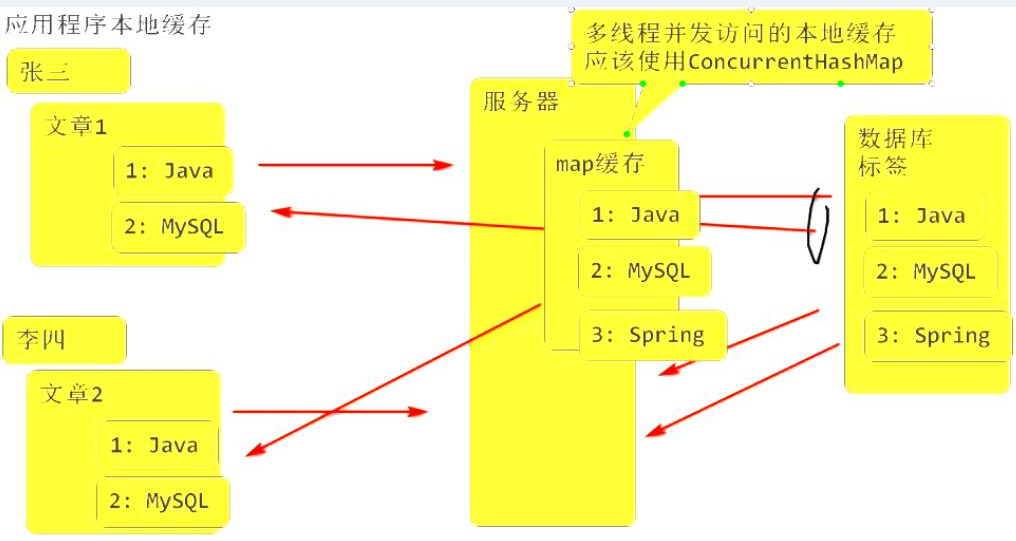
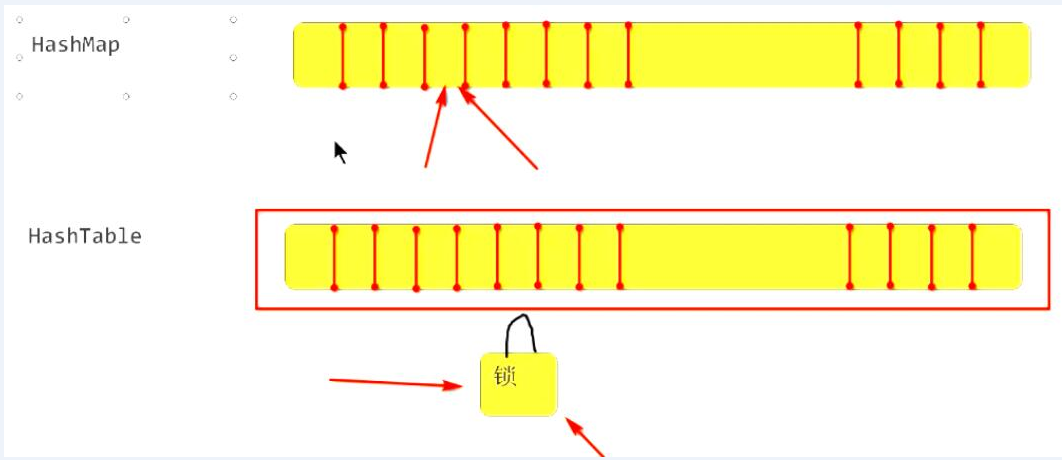
HashMap 是非线程安全的Map集合, 不适合多线程并发使用!
-
老式线程安全
-
HashTable 是线程安全的Map集合(整体上锁)
-
Collections.synchronizedMap() 可以将HashMap包装为线程安全的集合
-
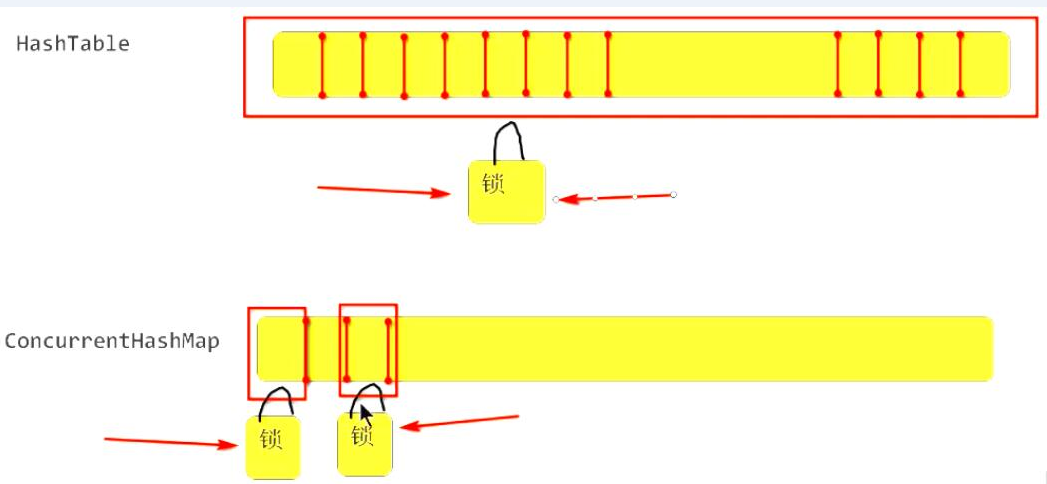
HashTable 和 Collections.synchronizedMap() 都是将所有方法进行同步处理, 并发访问会互斥, 性能慢!
-
-
ConcurrentHashMap, 提供细粒度的锁(上多个锁), 保证线程安全的情况下,提高了并发访问性能.(Concurrent: 并发)
-
多线程并发访问的本地缓存,应该使用ConcurrentHashMap