MariaDB学习(三)-group by、having、子查询(嵌套查询)、关联关系(等值联连接、内连接、外连接)、表设计、JDBC连接及使用
-
分组查询可以将某个字段相同值得数据划分为一组,以组为单位进行统计查询
-
查询每一种工作的平均工资
select job,avg(sal) from emp group by job;
-
查询每个部门的平均工资
select deptId,avg(sal) from emp group by deptId;
-
查询每种工作的人数
select job,count(*) from emp group by job;
-
查询每个部门工资大于2000的人数
select deptId,count(*) from emp where sal>2000 group by deptId;
-
查询平均工资最高的部门编号
select deptId from emp group by deptId order by avg(sal) desc limit 0,1;
-
select job from emp group by job order by count(*) desc limit 0,1;
having
-
where后面只能写普通字段的条件,不能写聚合函数条件
-
having关键字 和 group by分组查询 结合使用 ,写在group by的后面
-
聚合函数条件写在having 后面
-
查询每个部门的平均工资,只查询平均工资高于2000的数据
select deptId,avg(sal) from emp group by deptId having avg(sal)>2000;
select deptId,avg(sal) a from emp group by deptId having a>2000;
-
查询每种工作的人数,只查询人数大于1的工作名称和人数.
select job,count(*) c from emp group by job having c>1;
-
查询每个部门的工资总和,只查询有领导的员工,并且要求工资总和高于5400
select deptId,sum(sal) s from emp where manager is not null group by deptId having s>5400;
-
查询每个部门的平均工资,只查询工资在1000到3000之间的,并且过滤掉平均工资低于2000的部门信息
select deptId,avg(sal) a from emp where sal between 1000 and 3000 group by deptId having a>=2000;
-
查询每种工作的人数要求人数大于1个,并且只查询1号部门和2号部门的员工, 按照人数降序排序
select job,count(*) c from emp where deptId in(1,2) group by job having c>1 order by c desc;
-
查询高于2000工资人数最多的工作
select job from emp where sal>2000 group by job order by count(*) desc limit 0,1;
子查询(嵌套查询)
-
将一条SQL语句嵌入到另外一条SQL语句中, 当做查询条件的值
-
查询工资高于1号部门平均工资的员工信息
-
查询1号部门的平均工资
select avg(sal) from emp where deptId=1;
-
查询工资高于上面结果的员工信息
select * from emp where sal>(select avg(sal) from emp where deptId=1);
-
查询工资最高的员工信息
select * from emp where sal=(select max(sal) from emp);
-
查询工资高于2号部门最低工资的员工信息
select * from emp where sal>(select min(sal) from emp where deptId=2);
-
查询和孙悟空相同工作的员工信息
select * from emp where job=(select job from emp where name='孙悟空') and name!='孙悟空';
-
查询最低工资员工的同事们的信息(同事指同一部门)
select min(sal) from emp;
select deptId from emp where sal=(select min(sal) from emp);
select * from emp where deptId=(select deptId from emp where sal=(select min(sal) from emp)) and sal!=(select min(sal) from emp);
或
select * from emp where deptId=(select deptId from emp order by sal limit 0,1) and sal!=(select min(sal) from emp);
关联关系
-
创建表时, 表和表之间存在的业务关系
-
有哪几种关系?
-
一对一: 有AB两张表,A表中的一条数据对应B表中的一条数据, 同时B表中的一条数据也对应A表中的一条.
-
一对多:有AB两张表,A表中的一条数据对应B表中的多条数据, 同时B表中的一条数据对应A表中的一条.
-
多对多:有AB两张表,A表中的一条数据对应B表中的多条数据, 同时B表中的一条数据也对应A表中的多条.
-
-
表和表之间如何建立关系?
-
通过一个单独的字段指向另外一张表的主键
-
一对一的关系: 有AB两张表,在任意一张表中添加字段指向另外一个表的主键
-
一对多的关系: 有AB两张表,在一对多的关系中,多的一端添加一个单独字段指向另外一张表的主键
-
多对多的关系: 有AB两张表 还需要创建一个单独的关系表,里面两个字段分别指向另外两张表的主键
-
1.关联查询
-
同时查询多张表数据的查询方式称为关联查询
-
有三种关联查询的方式:
-
等值连接
-
内连接
-
外连接
-
2.等值连接
-
格式: select 字段信息 from A,B where 关联关系 and 条件;
-
查询工资高于2000的员工的姓名,工资以及对应的部门名
select e.name,sal,d.name from emp e,dept d where e.deptId=d.id and sal>2000;
-
查询 有领导并且和销售相关工作的员工姓名,工作,部门名和部门地点
select e.name,job,d.name,loc from emp e,dept d where e.deptId=d.id and manager is not null and job like '%销售%';
3.内连接
-
等值连接和内连接查询到的数据是一样的 都是两个表的交集数据,只是书写格式不一样
-
格式: select 字段信息 from A join B on 关联关系 where 条件
-
查询工资高于2000的员工的姓名,工资以及对应的部门名
select e.name,sal,d.name from emp e join dept d on e.deptId=d.id where sal>2000;
-
查询 有领导并且和销售相关工作的员工姓名,工作,部门名和部门地点
select e.name,job,d.name,loc from emp e join dept d on e.deptId=d.id where manager is not null and job like '%销售%';
4.外连接
-
查询一张表的全部和另外一张表的交集数据,使用外连接
-
格式: select 字段信息 from A left/right join B on 关联关系 where 条件
-
查询所有员工姓名和对应的部门名
insert into emp(name,sal) values('灭霸',88);
select e.name,d.name from emp e left join dept d on e.deptId=d.id;
-
查询所有部门名对应的员工姓名和工资
select d.name,e.name,sal from emp e right join dept d on e.deptId=d.id;
5.关联查询总结
-
如果需要查询的数据时两个表的交集数据,使用等值连接或内连接(推荐)
-
如果查询的是一张表的全部和另外一张表的交集使用外连接
表设计
-
举例: 实现一个微博网站
-
需要保存的数据: 用户名,密码,昵称,注册时间,注册地,性别,手机号,微博正文,微博附件,点赞量,浏览量,发布时间,发布地址,评论正文,点赞量,评论时间
-
分析上面的数据需要创建几张表,并且考虑表和表之间的关系
-
用户表:id,用户名,密码,昵称,注册时间,注册地,性别,手机号
-
微博表:id,微博正文,微博附件,点赞量,浏览量,发布时间,发布地址,用户id
-
评论表:id,评论正文,点赞量,评论时间,用户id, 微博id
-
-
JDBC
-
Java DataBase Connectivity: Java数据库连接, 学习JDBC主要学习的就是如何在Java代码中执行SQL语句
-
JDBC是Sun公司提供的一套通过Java连接数据库的API(Application Programma Interface 应用程序编程接口)
-
为什么使用JDBC?
-
如果没有JDBC接口, 每个数据库厂商都有可能定义自己一套全新的方法(做的事儿是一样的但是方法名可能不一样),这样对于Java程序员而言需要学习几套不同的方法, 为了避免这种情况出现,Sun公司定义了JDBC接口,将方法名固定, 让各个数据库厂商根据此方法名写各自的实现类, 这样java程序员只需要遵循JDBC的标准写代码,就算将来换数据库,代码也不用变 ,因为各个数据库厂商提供的方法名是一样的.
-
1.如何使用JDBC
-
创建一个maven工程,在pom.xml中添加mysql驱动的依赖(驱动实际上就是JDBC方法的实现类) ,添加后IDEA自动加载相关jar包
<dependencies>
<!-- 连接MySQL数据库的依赖 -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.15</version>
</dependency>
</dependencies>
加载成功后的jar包:
-
在工程上单击右键新建一个module,不用再次添加mysql组件依赖。
-
在该module下的src---main---java下新建包,创建类,进行代码的编写。
2.执行SQL语句对象Statement
-
execute(sql) :可以执行任意SQL语句, 但是推荐执行表相关的SQL (创建、删除表的操作等)
-
executeUpdate(sql) :执行增、删、改相关SQL语句
-
ResultSet rs = executeQuery (sql) :执行查询相关SQL语句
3.测试案例:连接数据库并执行SQL语句
(1)execute创建表
package cn.tedu;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.SQLException;
import java.sql.Statement;
/**
* 利用JDBC进行数据库连接
* 实现功能:创建jdbct1表
*/
public class Demo01 {
public static void main(String[] args) throws SQLException {
//1.获取数据库连接,抛出SQL异常到主方法
//注意:MySQL数据库默认端口3306,由于电脑同时安装了MySQL和MariaDB两款软件,端口号不能相同
// 以后使用MySQL软件端口号为3306,MariaDB软件端口号为3307
Connection conn = DriverManager.getConnection(
"jdbc:mysql://localhost:3307/newdb3?" +
"characterEncoding=utf8&" +
"serverTimezone=Asia/Shanghai",
"root","root");
//2.创建执行SQL语句的对象
Statement s = conn.createStatement();
//3.执行SQL语句
s.execute("create table jdbct1(id int)");
//4.关闭资源
conn.close();
System.out.println("执行完毕!");
}
}
(2)executeUpdate在表中插入数据
package cn.tedu;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.SQLException;
import java.sql.Statement;
/**
* 利用JDBC进行数据库连接
* 实现功能:在emp表下添加数据
*/
public class Demo03 {
public static void main(String[] args) throws SQLException {
//1.获取数据库连接,抛出SQL异常到主方法
//注意:MySQL数据库默认端口3306,由于电脑同时安装了MySQL和MariaDB两款软件,端口号不能相同
// 以后使用MySQL软件端口号为3306,MariaDB软件端口号为3307
Connection conn = DriverManager.getConnection(
"jdbc:mysql://localhost:3307/newdb3?" +
"characterEncoding=utf8&" +
"serverTimezone=Asia/Shanghai",
"root","root");
//2.创建执行SQL语句的对象
Statement s = conn.createStatement();
//3.执行SQL语句
s.executeUpdate("insert into emp(name) values('刘德华')");
//4.关闭资源
conn.close();
System.out.println("执行完毕!");
}
}
(3)executeQuery查询数据
package cn.tedu;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;
/**
* 利用JDBC进行数据库连接
* 实现功能:查询数据
*/
public class Demo02 {
public static void main(String[] args) throws SQLException {
//1.获取数据库连接,抛出SQL异常到主方法
//注意:MySQL数据库默认端口3306,由于电脑同时安装了MySQL和MariaDB两款软件,端口号不能相同
// 以后使用MySQL软件端口号为3306,MariaDB软件端口号为3307
Connection conn = DriverManager.getConnection(
"jdbc:mysql://localhost:3307/newdb3?" +
"characterEncoding=utf8&" +
"serverTimezone=Asia/Shanghai",
"root", "root");
//2.创建执行SQL语句的对象
Statement s = conn.createStatement();
//3.执行查询的SQL语句,返回结果为ResultSet结果集,里面装着查询回来的数据
ResultSet rs = s.executeQuery("select name,sal from emp");
//4.遍历结果集对象,rs.next()返回布尔值,表示时候有下一条数据,同时游标向下移动
while (rs.next()) {
//获取当前游标指向的数据
String name = rs.getString("name");
double sal = rs.getDouble("sal");
// String name = rs.getString(1);//对应上面查询内容的第一个字段
// double sal = rs.getDouble(2);//对应上面查询内容的第二个字段
System.out.println(name + ":" + sal);
}
//4.关闭资源
conn.close();
System.out.println("执行完毕!");
}
}
4.优化: 创建工具类DBUtils封装连接数据库的方法
package cn.tedu;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.SQLException;
/**
* 创建工具类DBUtils封装连接数据库的方法
*/
public class DBUtils {
public static Connection getConnection() throws SQLException {
//获取数据库连接,抛出SQL异常到方法
//注意:MySQL数据库默认端口3306,由于电脑同时安装了MySQL和MariaDB两款软件,端口号不能相同
// 以后使用MySQL软件端口号为3306,MariaDB软件端口号为3307
Connection conn = DriverManager.getConnection(
"jdbc:mysql://localhost:3307/newdb3?" +
"characterEncoding=utf8&" +
"serverTimezone=Asia/Shanghai",
"root","root");
return conn;
}
}
5.测试类
package cn.tedu;
import java.sql.Connection;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;
/**
* 调用数据库连接工具类DBUtils进行数据连接
* 实现功能:查询数据
*/
public class Demo04 {
public static void main(String[] args) {
try(
//1.获取工具类中的连接,自动关闭conn连接
//如果报错 alt+回车 选择set language level to 7
Connection conn = DBUtils.getConnection();
){
//2.创建执行SQL语句的对象
Statement s = conn.createStatement();
//3.执行查询的SQL语句,返回结果为ResultSet结果集,里面装着查询回来的数据
ResultSet rs = s.executeQuery("select name,sal from emp");
//4.遍历结果集对象,rs.next()返回布尔值,表示时候有下一条数据,同时游标向下移动
while(rs.next()){
//获取当前游标指向的数据
String name = rs.getString("name");
double sal = rs.getDouble("sal");
// String name = rs.getString(1);//对应上面查询内容的第一个字段
// double sal = rs.getDouble(2);//对应上面查询内容的第二个字段
System.out.println(name + ":" + sal);
}
} catch (SQLException e) {
e.printStackTrace();
}
}
}
报错:将Connection conn = DBUtils.getConnection();放到try()后报错
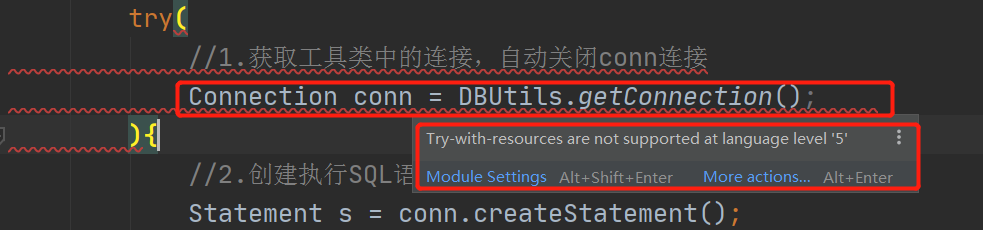
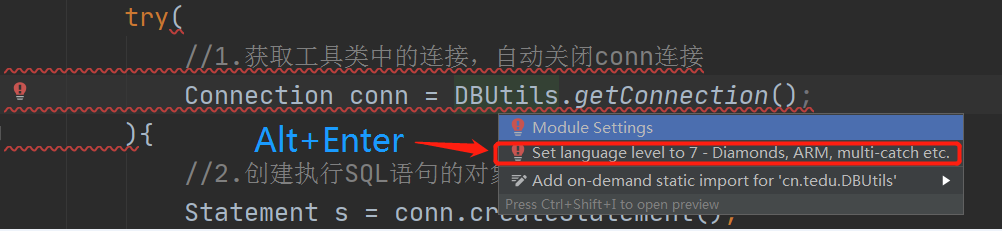
解决办法:在报错行上Alt+Enter,选择set language level to 7,等待加载完成即可
晚课任务:
1.任务1:
创建maven工程 jdbc02
把MySQL依赖添加到pom.xml
创建DBUtils
Demo01.java 创建hero表 有id,name,type字段
Demo02.java 插入 1,诸葛黑,法师 2,孙尚臭,射手
Demo03.java 查询hero表里面的英雄名和类型 在控制台输出
2.任务2:
1. 查询人数最多的工作名称及人数
select job,count(*) c from emp
group by job order by c desc limit 0,1;
2. 查询每种工作的平均工资取前三种
select job,avg(sal) a from emp
group by job order by a desc limit 0,3;
3. 查询每种工作的人数,只查询3个人以内的工作
select job,count(*) c from emp group by job having c<3;
4. 查询最高工资的部门有多少人
select max(sal) from emp;
select deptId from emp where sal=(select max(sal) from emp);
select count(*) from emp where deptId=(select deptId from emp where sal=(select max(sal) from emp));
或
select deptId,count(*) from emp where deptId=(select deptId from emp order by sal desc limit 0,1);
5. 查询工资高于2000的每个员工的姓名,工资和对应的部门名
select e.name,sal,d.name
from emp e join dept d on e.deptId=d.id
where sal>2000;
6. 查询所有的部门名和对应的员工姓名和工资
select d.name,e.name,sal
from emp e right join dept d on e.deptId=d.id;
