JavaSE02_Day04(下)-WbServer项目(七):自定义空请求异常、XML解析(定义、格式、作用、解析方案及案例演示)
一、WebServer项目
1.1 版本七:自定义异常来解决空请求问题
Http协议允许客户端发送一个空请求,也就是客户端与服务端断开连接的时候,实际上并没有发送任何的内容,但是我们所书写的代码是要对请求进行解析,那么这就会导致解析产生异常,不能正确的拆分出三部分内容。当我们解析请求的时候,如果发现发过来的是一个空请求,我们将异常最终抛给ClientHandler类,并且ClientHandler在接收这个异常后就不做任何的处理,直接断开连接。
步骤1:在http包下自定义一个异常类EmptyRequestException(空请求异常)
package cn.tedu.http;
/**
* 自定义异常类
* 用于解决浏览器发送空请求问题
* @author cjn
*
*/
public class EmptyRequestException extends Exception{
/**
* Java的序列化机制是通过在运行时判断类的serialVersionUID来验证版本一致性的。
* 原因:在进行反序列化时,JVM会把传来的字节流中的serialVersionUID与本地实体
* 类中的serialVersionUID进行比较,如果相同则认为是一致的,便可以进行反序列化,
* 否则就会报序列化版本不一致的异常
*/
private static final long serialVersionUID = 1L;
/*
* source -> generate constructors from superClass
* 生成EmptyRequestException类的构造器,
* 并且把重载的构造器一并都生成,
* 在构造器的内部调用超类中的构造器方法
*/
public EmptyRequestException() {
super();
}
public EmptyRequestException(String message, Throwable cause, boolean enableSuppression,
boolean writableStackTrace) {
super(message, cause, enableSuppression, writableStackTrace);
}
public EmptyRequestException(String message, Throwable cause) {
super(message, cause);
}
public EmptyRequestException(String message) {
super(message);
}
public EmptyRequestException(Throwable cause) {
super(cause);
}
}
步骤2:在HttpRequest类中进行请求行解析时,如果发现是一个空请求,那么咱们直接抛出自定义异常,并将其抛给构造方法,再经构造方法抛给ClientHandler类。

步骤3:在ClientHandler类中的run方法中添加一个空请求的异常捕获,以达到当实例化HttpRequest出现空请求后,跳过其他所有处理操作的目的。

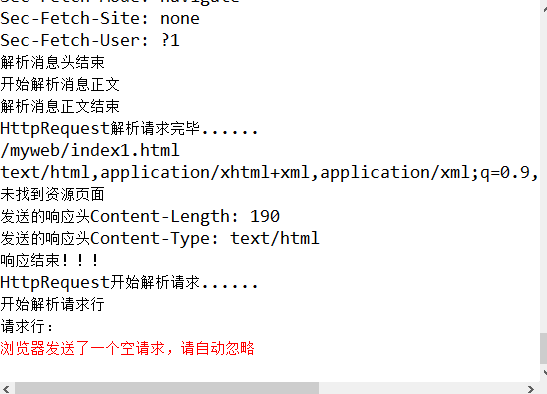
调试过程:在浏览器分别输入http://localhost:8888/myweb/index.html和http://localhost:8888/myweb/index1.html页面,分别响应index页面和404页面,说明正确!
运行结果中出现的空请求信息:
二、XML解析
2.1 XML定义
可扩展标记语言(Extensible Markup Language),标准通用标记语言的子集,简称XML,是一种用于标记电子文件使其具有结构性的标记语言。 在电子计算机中,标记指计算机所能理解的信息符号,通过此种标记,计算机之间可以处理包含各种的信息比如文章等。它可以用来标记数据、定义数据类型,是一种允许用户对自己的标记语言进行定义的源语言。 它非常适合万维网传输,提供统一的方法来描述和交换独立于应用程序或供应商的结构化数据。是Internet环境中跨平台的、依赖于内容的技术,也是当今处理分布式结构信息的有效工具。早在1998年,W3C就发布了XML1.0规范,使用它来简化Internet的文档信息传输。
可扩展标记语言与Access,Oracle和SQL Server等数据库不同,数据库提供了更强有力的数据存储和分析能力,例如:数据索引、排序、查找、相关一致性等,可扩展标记语言仅仅是存储数据。事实上它与其他数据表现形式最大的不同是:可扩展标记语言极其简单,这是一个看上去有点琐细的优点,但正是这点使它与众不同。
XML的简单易于在任何应用程序中读/写数据,这使XML很快成为数据交换的唯一公共语言,虽然不同的应用软件也支持其他的数据交换格式,但不久之后它们都将支持XML,那就意味着程序可以更容易的与Windows、Mac OS、Linux以及其他平台下产生的信息结合,然后可以很容易加载XML数据到程序中并分析它,并以XML格式输出结果。
XML有两个先驱:SGML和HTML,这两个语言都是非常成功的标记语言,但是都有一些与生俱来的缺陷。XML正是为了解决它们的不足而诞生的。
2.1.1 SGML
早在Web未发明之前,SGML(Standard Generalized Markup Language,标准通用标记语言)就已存在,正如它的名称所言,SGML是国际上定义电子文件结构和内容描述的标准。SGML具有非常复杂的文档结构,主要用于大量高度结构化数据的访问和其他各种工业领域,在分类和索引数据中非常有用。 虽然SGML的功能很强大,但是它不适用于Web数据描述,而且SGML软件的价格非常昂贵;另外,SGML十分庞大,既不容易学,又不容易使用,在计算机上实现也十分困难:不仅如此,几个主要的浏览器厂商都明确拒绝支持SGML,这无疑是SGML在网上传播遇到的最大障碍。鉴于这些因素,Web的发明者——欧洲核子物理研究中心的研究人员,根据当时(1989年)的计算机技术,发明并推出了HTML。
2.1.2 HTML
1989年,HTML诞生,它抛弃了SGML复杂庞大的缺点,继承了SGML的很多优点。HTML最大的特点是简单性和跨平台性。HTML是一种界面技术,它只使用了SGML中很少的一部分标记,例如HTML 4.0中只定义了70余种标记。为了便于在计算机上实现,HTML规定的标记是固定的,即HTML语法是不可扩展的。HTML这种固定的语法使它易学易用,在计算机上开发HTML的浏览器也十分容易。正是由于HTML的简单性,使得基于HTML的Web应用得到了极大的发展。
2.1.3 XML的产生
随着Web应用的不断发展,HTML的局限性也越来越明显地显现了出来,如HTML无法描述数据、可读性差、搜索时间长等。人们又把目光转向SGML,再次改造SGML使之适应现在的网络需求。随着先辈的努力,1998年2月10日,W3C(World Wide Web Consortium,万维网联盟)公布XML 1.0标准,XML诞生了。 XML最初的设计目的是为了EDI(Electronic Data Interchange,电子数据交换),确切地说是为EDI提供一个标准数据格式。当前的一些网站内容建设者们已经开始开发各种各样的XML扩展,比如数学标记语言MathML、化学标记语言CML等。此外,一些著名的IT公司,如Oracle、IBM以及微软等都积极地投入人力与财力研发XML相关软件与服务支持,这无疑确定了XML在IT产业的重要地位。
2.1.4 特征
XML具有以下特点:
(1) XML可以从HTML中分离数据
即能够在HTML文件之外将数据存储在XML文档中,这样可以使开发者集中精力使用HTML做好数据的显示和布局,并确保数据改动时不会导致HTML文件也需要改动,从而方便维护页面。XML也能够将数据以“数据岛”的形式存储在HTML页面中,开发者依然可以把精力集中到使用HTML格式化和显示数据上。
(2) XML可用于交换数据
基于XML可以在不兼容的系统之间交换数据,计算机系统和数据库系统所存储的数据有多种形式,对于开发者来说,最耗时间的工作就是在遍布网络的系统之间交换数据。把数据转换为XML格式存储将大大减少交换数据时的复杂性,还可以使这些数据能被不同的程序读取。
(3) XML可应用于B2B中
例如在网络中交换金融信息, 目前XML正成为遍布网络的商业系统之间交换信息所使用的主要语言,许多与B2B有关的完全基于XML的应用程序正在开发中。
(4)利用XML可以共享数据
XML数据以纯文本格式存储,这使得XML更易读、更便于记录、更便于调试,使不同系统、不同程序之间的数据共享变得更加简单。
(5) XML可以充分利用数据
XML是与软件、硬件和应用程序无关的,数据可以被更多的用户、设备所利用,而不仅仅限于基于HTML标准的浏览器。其他客户端和应用程序可以把XML文档作为数据源来处理,就像操作数据库一样,XML的数据可以被各种各样的“阅读器”处理。
(6) XML可以用于创建新的语言
比如,WAP和WML语言都是由XML发展来的。WML(Wireless Markup Language,无线标记语言)是用于标识运行于手持设备上(比如手机)的Internet程序的工具,它就采用了XML的标准。
总之,XML使用一个简单而又灵活的标准格式,为基于Web的应用提供了一个描述数据和交换数据的有效手段。但是,XML并非是用来取代HTML的。HTML着重如何描述将文件显示在浏览器中,而XML与SGML相近,它着重描述如何将数据以结构化方式表示。
2.1.5 格式
XML文件格式是纯文本格式,在许多方面类似于HTML,XML由XML元素组成,每个XML元素包括一个开始标记<,一个结束标记>以及两个标记之间的内容,例如,可以将XML元素标记为价格、订单编号或名称。标记是对文档存储格式和逻辑结构的描述。在形式上,标记中可能包括注释、引用、字符数据段、起始标记、结束标记、空元素、文档类型声明( DTD)和序言。
具体规则如下:
1、必须有声明语句。
XML声明是XML文档的第一句,其格式如下: <?xml version="1.0" encoding="utf-8"?>
2、注意大小写
在XML文档中,大小写是有区别的。“A”和“a”是不同的标记。注意在写元素时,前后标记的大小写要保持一致。最好养成一种习惯,或者全部大写,或者全部小写,或者大写第一个字母,这样可以减少因为大小写不匹配而产生的文档错误。
3、XML文档有且只有一个根元素
良好格式的XML文档必须有一个根元素,就是紧接着声明后面建立的第一个元素,其他元素都是这个根元素的子元素,根元素完全包括文档中其他所有的元素。根元素的起始标记要放在所有其他元素的起始标记之前;根元素的结束标记要放在所有其他元素的结束标记之后。
4、属性值使用引号
在HTML代码里面,属性值可以加引号,也可以不加。但是XML规定,所有属性值必须加引号(可以是单引号,也可以是双引号,建议使用双引号),否则将被视为错误。
5、所有的标记必须有相应的结束标记
在HTML中,标记可以不成对出现,而在XML中,所有标记必须成对出现,有一个开始标记,就必须有一个结束标记,否则将被视为错误。
6、所有的空标记也必须被关闭
空标记是指标记对之间没有内容的标记,比如“”等标记。在XML中,规定所有的标记必须有结束标记。
2.1.6 与HTML区别
(1)可扩展性方面:
HTML不允许用户自行定义他们自己的标识或属性,而在XML中,用户能够根据需要自行定义新的标识及属性名,以便更好地从语义上修饰数据。
(2)结构性方面:
HTML不支持深层的结构描述,XML的文件结构嵌套可以复杂到任意程度,能表示面向对象的等级层次。
(3)可校验性方面:
HTML没有提供规范文件以支持应用软件对HTML文件进行结构校验,而XML文件可以包括一个语法描述,使应用程序可以对此文件进行结构校验。
2.2 XML文件格式
2.3 作用
使用XML可以进行对数据的存储,也可以进行传输数据。
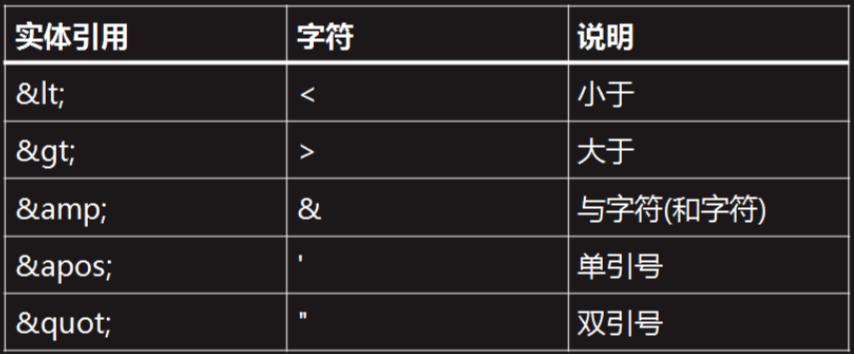
2.4 特殊字符
2.5 CDATA段
格式:< ! [CDATA [内容] ] >
作用:避免特殊字符读取错误,可直接将内容输入到CDATA[ ]中。
<![CDATA[ 伏尔泰说过一<句著名的话,不>经巨大的困难,不会有伟大<>的事业。这启发了我. 小白老师的发"生,到底"需要如何做到,不小白''老师的发生,又&会如何产生。]]>
2.6 XML解析
获取XML文件中的内容
2.7 XML解析的方案
-
DOM:速度较慢,可以修改元素的内容;
-
SAX:速度较快,不可以修改元素的内容。
2.8 DOM4J的依赖导入
下载jar包或复制代码:
-
推荐【官方仓库】:https://mvnrepository.com/
-
不推荐【阿里仓库,查找麻烦】:https://maven.aliyun.com/mvn/view
<!-- dom4j 1.6.1 -->
<dependency>
<groupId>dom4j</groupId>
<artifactId>dom4j</artifactId>
<version>1.6.1</version>
</dependency>
在pom.xml文件中添加dom4j组件依赖:
注意:要加一对标签<dependencies></dependencies>,添加后工具自动加载相关jar包
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>cn.tedu</groupId>
<artifactId>webserver01</artifactId>
<version>0.0.1-SNAPSHOT</version>
<dependencies>
<!-- https://mvnrepository.com/artifact/dom4j/dom4j -->
<dependency>
<groupId>dom4j</groupId>
<artifactId>dom4j</artifactId>
<version>1.6.1</version>
</dependency>
</dependencies>
</project>
2.9 XML文件解析案例
新建emp.xml文件:
2.10 相关API
-
获取根节点: Element getRootElement();
-
获取当前标签的所有子元素
-
List elements();
-
List elements(String name);//获取指定标签的子元素
-
-
获取标签名称 :String getName();
-
-
获取标签中的文本内容
-
String getText();
-
String elementText();//一般用这个
-
2.11 案例演示
Emp类:
package xml;
/**
* 用于解析XML文件,获取文件中的员工信息的存储
* @author cjn
*
*/
public class Emp {
//参数信息
private String name;
private Integer age;
private String gender;
private Double sal;
/**
* 定义无参构造、有参构造方法
* 声明get、set方法
* 重写toString、equals方法
*/
public Emp(){}
public Emp(String name, Integer age, String gender, Double sal) {
super();
this.name = name;
this.age = age;
this.gender = gender;
this.sal = sal;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Integer getAge() {
return age;
}
public void setAge(Integer age) {
this.age = age;
}
public String getGender() {
return gender;
}
public void setGender(String gender) {
this.gender = gender;
}
public Double getSal() {
return sal;
}
public void setSal(Double sal) {
this.sal = sal;
}